Meta:余红涛,任曼曼,伯特·马赫,肖恩·奈
NVIDIA:朱古斯塔夫,姜舒豪
在过去的几个月里,我们一直在通过 Triton 编译器为 PyTorch 和 Triton 用户启用高级 GPU 功能。我们的一个关键目标是在 NVIDIA Hopper GPU 上引入 warp 专业化支持。今天,我们非常高兴地宣布,我们的努力已经导致完全自动化的 Triton warp 专业化推出,现在将在即将发布的 Triton 3.2 版本中提供给用户,该版本将随 PyTorch 2.6 一起发布。PyTorch 用户可以通过实现用户定义的 Triton 内核来利用此功能。这项工作利用了 NVIDIA 在 Triton 中进行的 warp 专业化的初始实现,我们期待着与社区在未来进行进一步的开发。
warp 专业化(WS)是一种 GPU 编程技术,其中线程块内的 warp(NVIDIA GPU 上的 32 个线程的组)被分配不同的角色或任务。这种方法通过使需要任务区分或协作处理的负载高效执行来优化性能。它通过利用异步执行模型来提高内核性能,其中内核的不同部分由不同的硬件单元管理。这些单元之间的数据通信通过 NVIDIA H100 上的共享内存进行,效率非常高。与统一 warp 方法相比,warp 专业化允许硬件多任务 warp 调度器更有效地运行,最大化资源利用率和整体性能。
以 GEMM 为例,在 H100 GPU 上,典型的统一 warp 方法涉及每个线程块有 8 个 warp 共同计算输出张量的一块。这 8 个 warp 被分为两个 warp 组(WG),每个组通过高效的 warp 组级 MMA(WGMMA)指令合作计算一半的块,如图 1 所示。
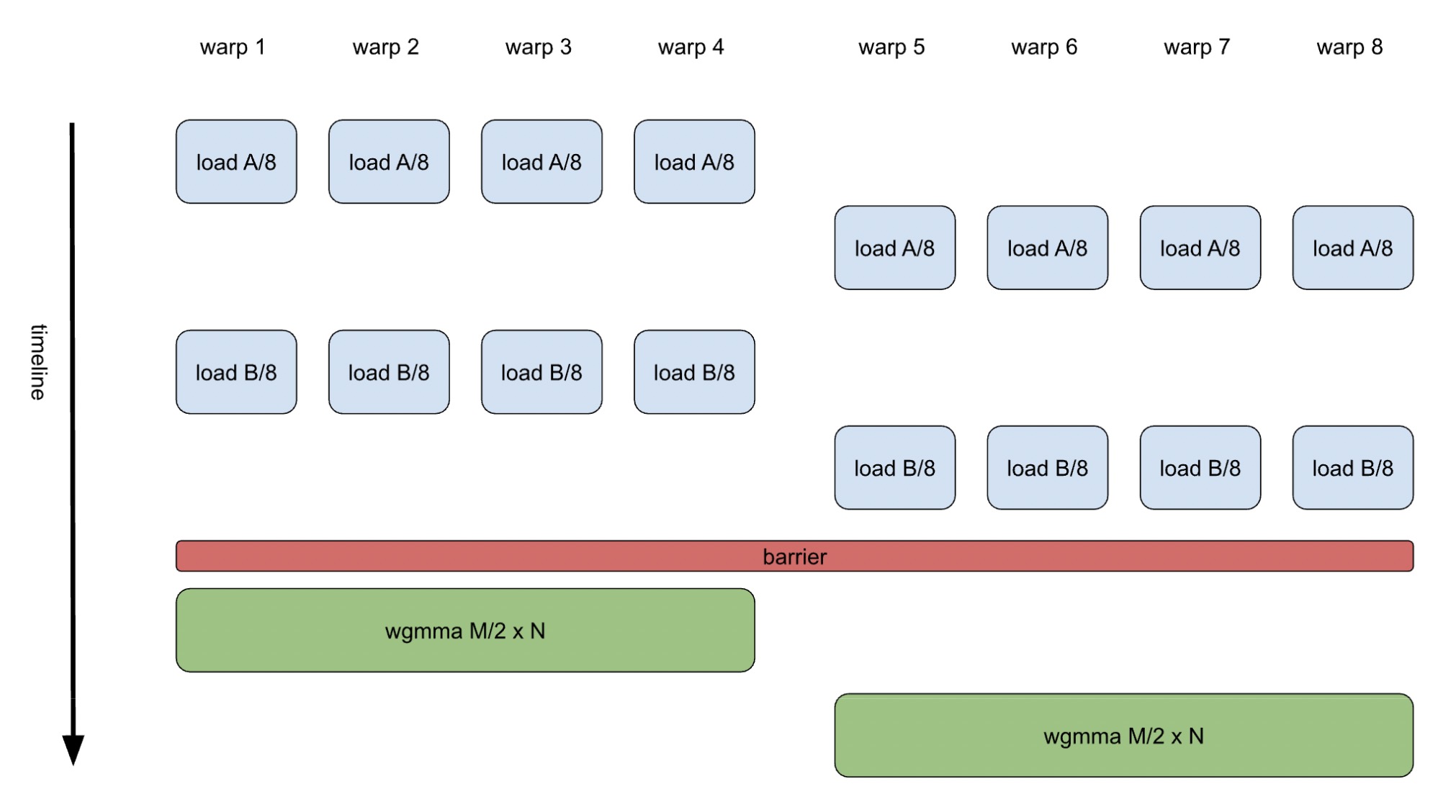
图 1. 带有统一 warp 的 GEMM K-loop 体
实现干净、易于理解,并且通常表现良好,归功于优雅的软件管道器。管道器的目的是通过在不同的硬件单元上执行非依赖性操作来增强指令级并行性。例如,可以从下一个循环迭代中执行加载操作,同时与当前迭代中的 WGMMA 操作同时执行。然而,这种方法严重依赖于编译器来构建一个指令序列,确保加载和 WGMMA 指令在精确的时机发出。虽然对于涉及有限操作数量的 GEMM 来说这相对简单,但对于更复杂的内核,如闪存注意力,这变得具有显著挑战性。
另一方面,通过将旨在不同硬件单元上同时运行的运算操作分离成独立的 warp,并使用共享内存中的低成本屏障进行高效同步,来应对编程挑战。这使得每个 warp 都有自己的指令序列,多路 warp 调度器使得指令可以连续发布和执行,不会被其他操作中断。图 2 展示了专门化的 GEMM 的示例。
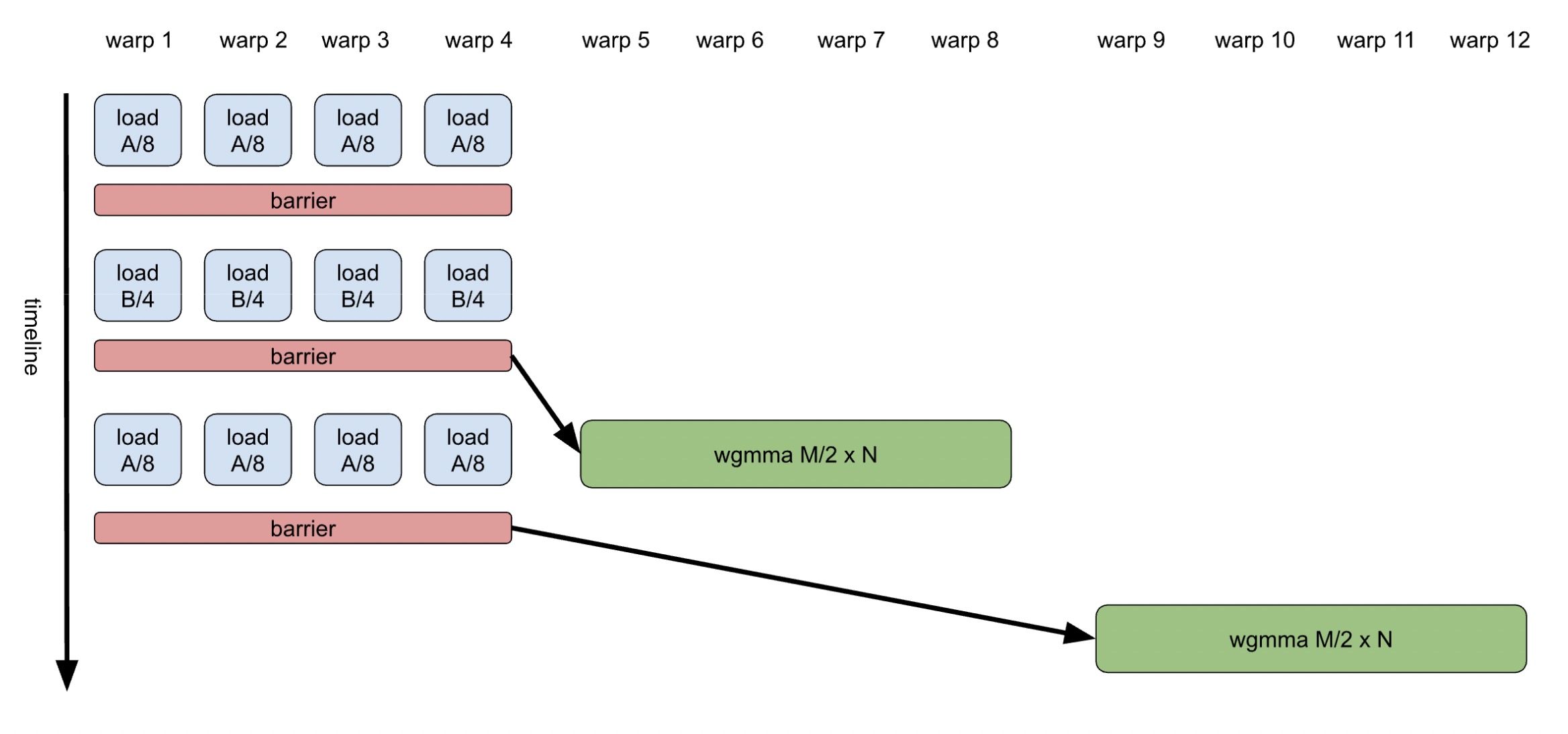
图 2. 专门化 warp 的 GEMM K-loop 体
如何启用 WS
要启用 warp 专业化,用户只需指定两个自动调整标志:num_consumer_groups 和 num_buffers_warp_spec。例如,一个 warp 专业化 GEMM 实现可能如下所示。用户可以通过设置非零值来启用 warp 专业化,该值定义了消费者 warp 组的数量。目前没有设置生产者 warp 组数量的对应标志,因为目前只支持一个生产者。num_buffers_warp_spec 标志指定生产者 warp 组将用于与消费者 warp 组通信的缓冲区数量。在持久 GEMM 教程中提供了一个 warp 专业化内核的工作示例。
@triton.autotune(
configs=[
triton.Config(
{
"BLOCK_SIZE_M": 128,
"BLOCK_SIZE_N": 256,
"BLOCK_SIZE_K": 64,
"GROUP_SIZE_M": 8,
},
num_stages=2,
num_warps=4,
num_consumer_groups=2,
num_buffers_warp_spec=3,
),
],
key=["M", "N", "K"],
)
@triton.jit
def matmul_persistent_ws_kernel(
a_ptr, b_ptr, c_ptr, M, N, K,
stride_am, stride_ak, stride_bk, stride_bn, stride_cm, stride_cn,
BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, BLOCK_K: tl.constexpr,
):
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_M)
num_pid_n = tl.cdiv(N, BLOCK_N)
pid_m = pid // num_pid_m
pid_n = pid % num_pid_n
offs_m = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
offs_n = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
offs_k = tl.arange(0, BLOCK_K)
a_ptrs = a_ptr + (offs_m[:, None] * stride_am + offs_k[None, :] * stride_ak)
b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_n[None, :] * stride_bn)
acc = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_K)):
a = tl.load(a_ptrs)
b = tl.load(b_ptrs)
acc += tl.dot(a, b)
a_ptrs += BLOCK_K * stride_ak
b_ptrs += BLOCK_K * stride_bk
c = acc.to(tl.float16)
c_ptrs = c_ptr + stride_cm * offs_m[:, None] + stride_cn * offs_n[None, :]
tl.store(c_ptrs, c)
内部机制
Warp 专业化使用一系列分层编译器转换和 IR 变换来将用户的非 warp 专业化内核转换为 warp 专业化机器代码。这些包括:
- 任务划分:整个内核根据预定义的启发式算法自动划分为异步任务。编译器确定如何利用一个生产者 warp 组和用户指定的消费者 warp 组数量来执行内核。它为特定的锚定操作分配任务 ID,然后通过异步任务 ID 传播和依赖分析影响剩余操作的任务分配。由于共享内存是所有支持平台之间数据传输最有效的方法,编译器优化任务划分以最小化寄存器溢出到共享内存,确保高效执行。
- 多消费者组的数据分区:在多个消费者组之间高效地分区数据是优化工作负载分配的关键。在 H100 GPU 上,编译器默认尝试沿着
M维度对输入张量A进行分区,使每个消费者组能够独立计算输出张量的一半。这种称为协作分区的策略在大多数情况下都能最大化效率。然而,如果这种分割导致效率低下——例如产生小于原生 WGMMA 指令大小的负载——编译器会动态调整并沿着N维度进行分区。 - 数据流流水线:编译器创建循环共享内存缓冲区,以在多维循环之间流水线化数据流。支持复杂控制流的 Warp 专用流水线。例如,我们的 Warp 专用持久 GEMM 内核使用双层循环,允许生产者在消费者完成前一个输出瓦片的计算时开始获取下一个输出瓦片的数据。
- 我们引入了四种高级 Triton GPU IR (TTGIR)通信操作
:和—ProducerAcquireOp, ProducerCommitOp, ConsumerWaitOp,,用于管理流水线数据流。这些操作支持 TMA 和非 TMA 内存操作。 - 代码分区:每个异步任务被划分为独立的代码区域,并由 warp 组 ID 检查保护。控制依赖关系根据需要复制。
- TTGIR 到 LLVM/PTX 的物化:TTGIR 通信操作被物化为相应的 LLVM/PTX 屏障操作。
性能
warp 专用化释放引入了一系列 Triton 编译器转换,这些转换共同将用户代码转换为 warp 专用内核。这一特性已应用于多个关键内核,包括 Flash Attention 和 FP8 行向 GEMM,实现了 10%到 15%的性能提升。以下,我们突出显示这些高影响内核的最新性能指标。
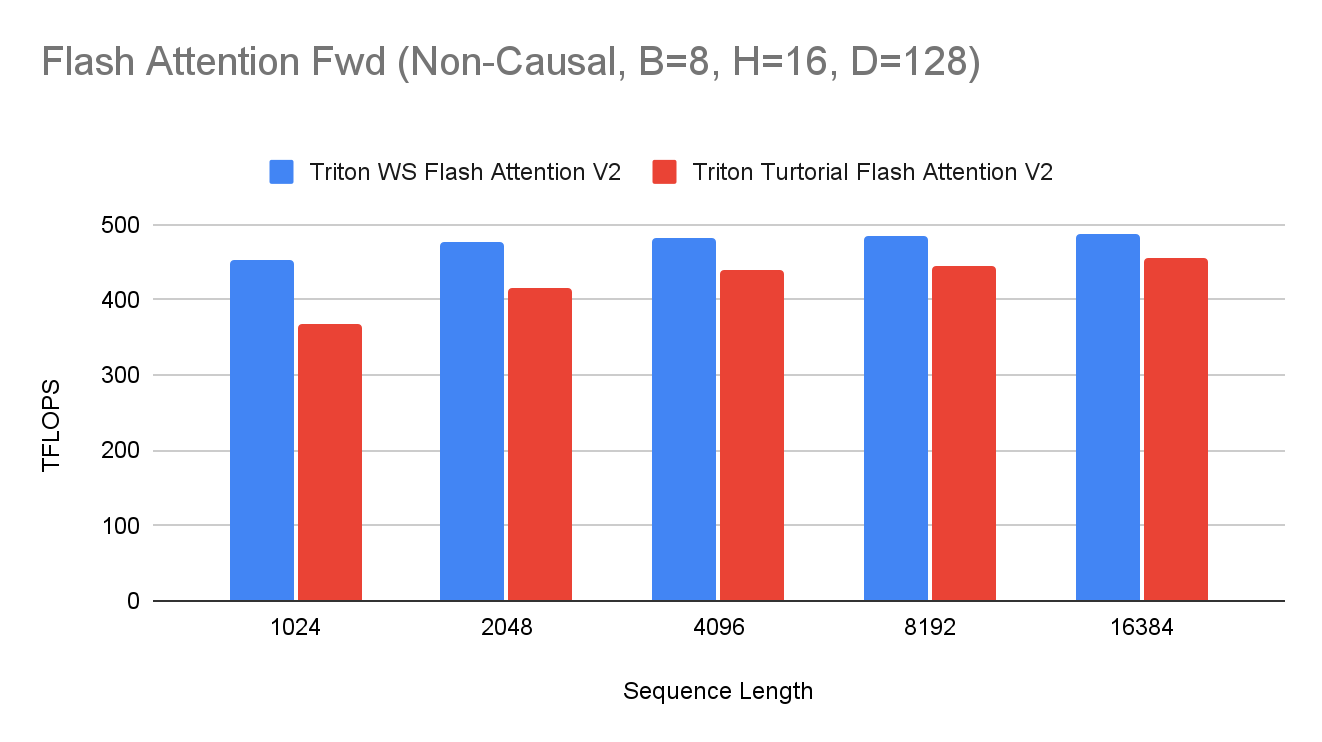
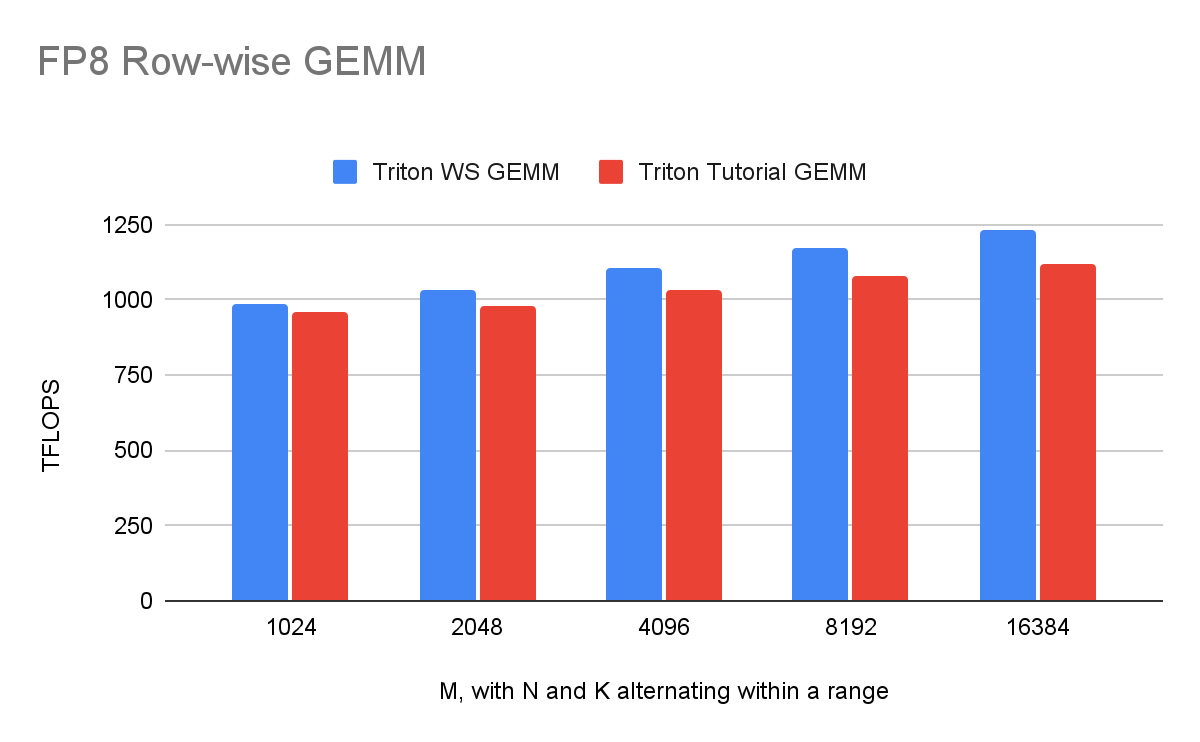
未来工作
展望未来,我们计划通过引入新的功能,如 Ping-Pong 调度、扩展的缓冲区共享支持、改进的 TMA 透明处理以及为即将到来的 NVIDIA 硬件优化的分区启发式算法,进一步强化 Triton 的 warp 专业化支持。