引言
在最近的 PyTorch 大会上,Arm 强调了其技术的广泛影响,从云端到边缘,强调其致力于无缝地将先进的 AI 计算能力提供给全球数百万开发者。

在演示过程中,强调了 Arm 承担着巨大的责任,即无摩擦地为 2000 万以上的开发者和数十亿用户提供先进的 AI 计算功能。实现这一点需要与软件和硬件合作伙伴的广泛生态系统中的关键软件合作。
仅几个月前,Arm 推出了 Arm Kleidi,这是一套开发者启用技术和资源,旨在推动 ML 堆栈的技术协作和创新。这包括 KleidiAI 软件库,它提供优化的软件例程,当集成到 XNNPACK 等关键框架中时,可以为 Arm Cortex-A CPU 上的开发者实现自动 AI 加速。
今天,我们兴奋地宣布 AI 开源社区的一个新里程碑,Arm 通过 XNNPACK 将 KleidiAI 集成到 ExecuTorch 中,进一步拉近了实现这一愿景的距离:提升 AI 在 Arm 移动 CPU 上的工作负载性能!
感谢 Arm 和 Meta 的工程团队的合作努力,AI 开发者现在可以部署量化后的 Llama 模型,这些模型在搭载 i8mm 指令集扩展的 Arm Cortex-A v9 CPU 上运行速度可提升高达 20%。
更令人兴奋的消息是,ExecuTorch 团队已正式发布 Beta 版本!
这标志着我们合作的一个重要里程碑。在这篇博客中,我们热切地分享关于 ExecuTorch 功能、新的 Meta Llama 3.2 模型、每块整数 4 位量化以及在某些 Arm CPU 上记录的令人印象深刻的性能的更多细节。值得注意的是,我们在三星 S24+设备上使用量化的 Llama 3.2 1B 模型在预填充阶段达到了每秒 350 个 token 的速度,如下面的截图所示。
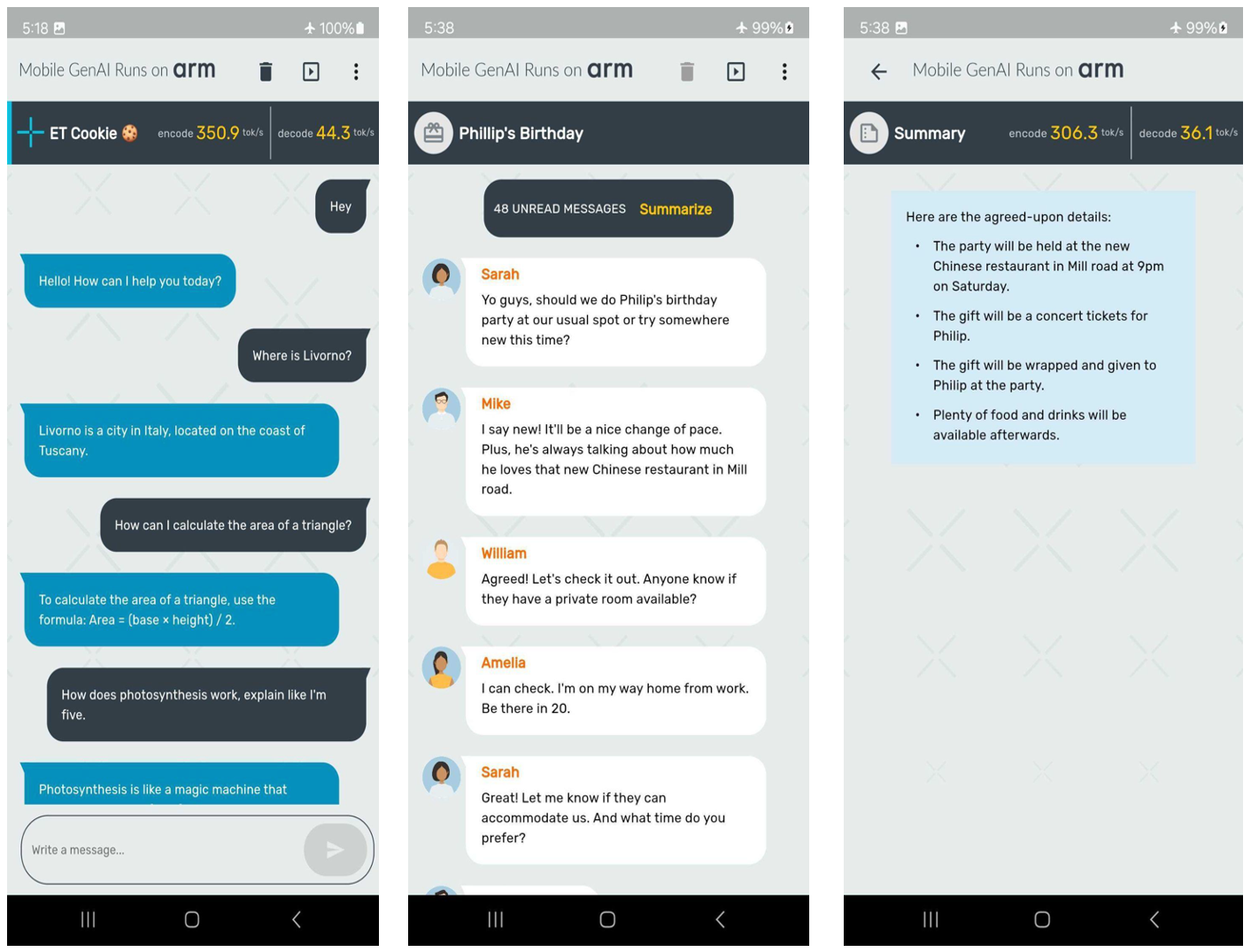
现在,让我们深入了解前述图像中展示的演示创建的关键组件。首先:新的 Llama 3.2 模型!
Meta Llama 3.2
Meta 最近宣布了首个轻量级量化 Llama 模型,这些模型旨在在流行的移动设备上运行。Meta 为 Llama 3.2 1B 和 3B 模型量化使用了两种技术:量化感知训练(QAT)与 LoRA 适配器(QLoRA),以及 SpinQuant,这是一种最先进的训练后量化方法。量化模型使用 PyTorch 的 ExecuTorch 框架作为推理引擎,以 Arm CPU 作为后端进行了评估。
这些指令调整的模型在保持原始 1B 和 3B 模型的质量和安全性的同时,实现了 2-4 倍的加速,平均模型大小减少了 56%,平均内存占用减少了 41%,与原始 BF16 格式相比。
在这篇博客文章中,我们将展示我们在实验中观察到的性能改进。
ExecuTorch
ExecuTorch 是一个专为在设备上部署 AI 模型而设计的 PyTorch 原生框架,它增强了隐私性并降低了延迟。它支持部署最前沿的开源 AI 模型,包括 Llama 系列模型以及 Segment Anything 和 Seamless 等视觉和语音模型。
这为边缘设备,如智能手机、智能眼镜、VR 头盔和智能家居摄像头等,打开了新的可能性。传统上,将 PyTorch 训练的 AI 模型部署到资源有限的边缘设备一直具有挑战性且耗时,通常需要转换为其他格式,这可能导致错误和性能不佳。硬件和边缘生态系统中多样的工具链也降低了开发者的体验,使得通用解决方案变得不切实际。
ExecuTorch 通过提供可组合组件来解决这些问题,包括核心运行时、操作库和委托接口,该接口允许可移植性以及可扩展性。模型可以使用 torch.export()导出,生成与 ExecuTorch 运行时本机兼容的图,能够在大多数带有 CPU 的边缘设备上运行,并可扩展到 GPU 和 NPU 等专用硬件以增强性能。
与 Arm 合作,ExecuTorch 现在利用 Arm KleidiAI 库中优化的低比特矩阵乘法内核,通过 XNNPACK 提高设备上大型语言模型(LLM)推理性能。我们还要感谢 Google 的 XNNPACK 团队对这一努力的支持。
在本文中,我们将关注 ExecuTorch 中可用的这一集成。
人工智能工作负载架构的演进。
在安谋公司,自深度学习浪潮初期起,我们就致力于投资开源项目并推动处理器新技术的进步,专注于使人工智能工作负载高性能且功耗更低。
例如,安谋公司从 Armv8.2-A 架构开始引入了 SDOT 指令,以加速 8 位整数向量的点积运算。这一特性现在广泛应用于移动设备中,显著提高了量化 8 位模型的计算速度。在 SDOT 指令之后,安谋公司又引入了 BF16 数据类型和 MMLA 指令,进一步提升了 CPU 上的浮点数和整数矩阵乘法性能,最近还宣布了可扩展矩阵扩展(SME),标志着机器学习能力的一次重大飞跃。
下图展示了过去十年中安谋 CPU 在人工智能领域持续创新的几个示例:

鉴于 Arm CPU 的广泛应用,AI 框架需要充分利用这些技术在关键操作中最大化性能。认识到这一点,我们看到了分享这些优化软件例程的开源库的需求。然而,我们意识到将新库集成到 AI 框架中面临的挑战,例如对库大小、依赖项和文档的担忧,以及避免给开发者增加额外负担的需求。因此,我们采取了额外措施,从我们的合作伙伴那里收集反馈,确保一个不需要为 AI 开发者添加额外依赖项的平稳集成过程。这一努力导致了 KleidiAI,这是一个开源库,为针对 Arm CPU 的人工智能(AI)工作负载提供优化性能的关键例程。您可以在这里了解更多关于 KleidiAI 的信息。
与 Meta 的 ExecuTorch 团队合作,Arm 为其创新的每块量化 4 位量化方案提供了软件优化,该方案用于加速 Transformer 层 torch.nn.linear 操作中的矩阵乘法内核,适用于 Llama 3.2 量化模型。ExecuTorch 的这种灵活的 4 位量化方案在模型精度和低比特矩阵乘法性能之间取得了平衡,针对设备上的LLMs。
整数 4 位,每块量化
在 KleidiAI 中,我们引入了针对这种新的 4 位整数量化方案(matmul_clamp_f32_qai8dxp_qsi4c32p)优化的微内核
如图所示,这种 4 位量化采用按块策略对权重(右侧矩阵)进行量化,并对激活(左侧矩阵)采用每行 8 位量化:
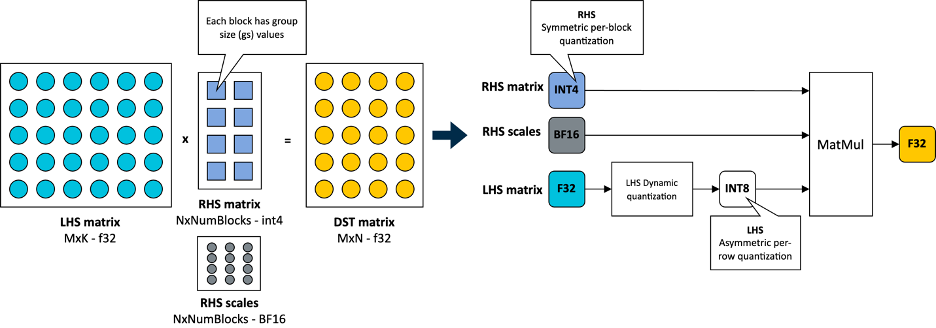
如您在前面图片中所见,权重矩阵中的每个输出特征图(OFM)都被分成了等大小的块(组大小),每个块都存储了一个以 BF16 格式存储的缩放因子。BF16 的优势在于它保持了 32 位浮点数(FP32)格式的动态范围,同时比特大小减半,并且可以通过简单的移位操作轻松转换为 FP32 和从 FP32 转换。这使得 BF16 非常适合节省模型空间、保持精度并确保与缺乏 BF16 硬件加速的设备的向后兼容性。您可以在 Arm 社区博客文章中了解更多关于 BF16 格式的信息。
为了完整性,这个 4 位量化方案和我们在 KleidiAI 中的实现允许用户配置线性权重(RHS)的组大小,使用户能够在模型大小、模型精度和模型性能之间进行权衡,如果模型被用户量化。
到目前为止,我们已经准备好公布在 Arm CPU 上使用 ExecuTorch 运行 Llama 3.2 1B 和 Llama 3.2 3B 时记录的惊人性能。让我们首先回顾我们将用于评估LLM推理性能的指标。
LLM推理的指标
通常,用于评估推理期间LLM性能的性能指标包括:
- 首个 Token 生成时间(TTFT):这衡量了在用户提供提示后生成第一个输出 Token 所需的时间。这种延迟或响应时间对于良好的用户体验非常重要,尤其是在手机上。TTFT 也是提示长度或提示 Token 长度的函数。为了使此指标与提示长度无关,我们在这里使用每秒预填充 Token 数作为代理。这些指标之间的关系是反比的:较低的 TTFT 对应于较高的每秒预填充 Token 数。
- 解码性能:这是每秒生成的平均输出 Token 数,因此以每秒 Token 数报告。它与生成的总 Token 数无关。对于设备上的推理,保持这个值高于用户的平均阅读速度非常重要。
- 峰值运行内存:此指标反映了运行模型所需的 RAM 量,通常以兆字节(MiB)为单位报告,使用上述指标测量的预期性能。鉴于 Android 和 iOS 设备上可用的 RAM 有限,这是设备上LLM部署的关键指标之一。它决定了可以在设备上部署的模型类型。
结果
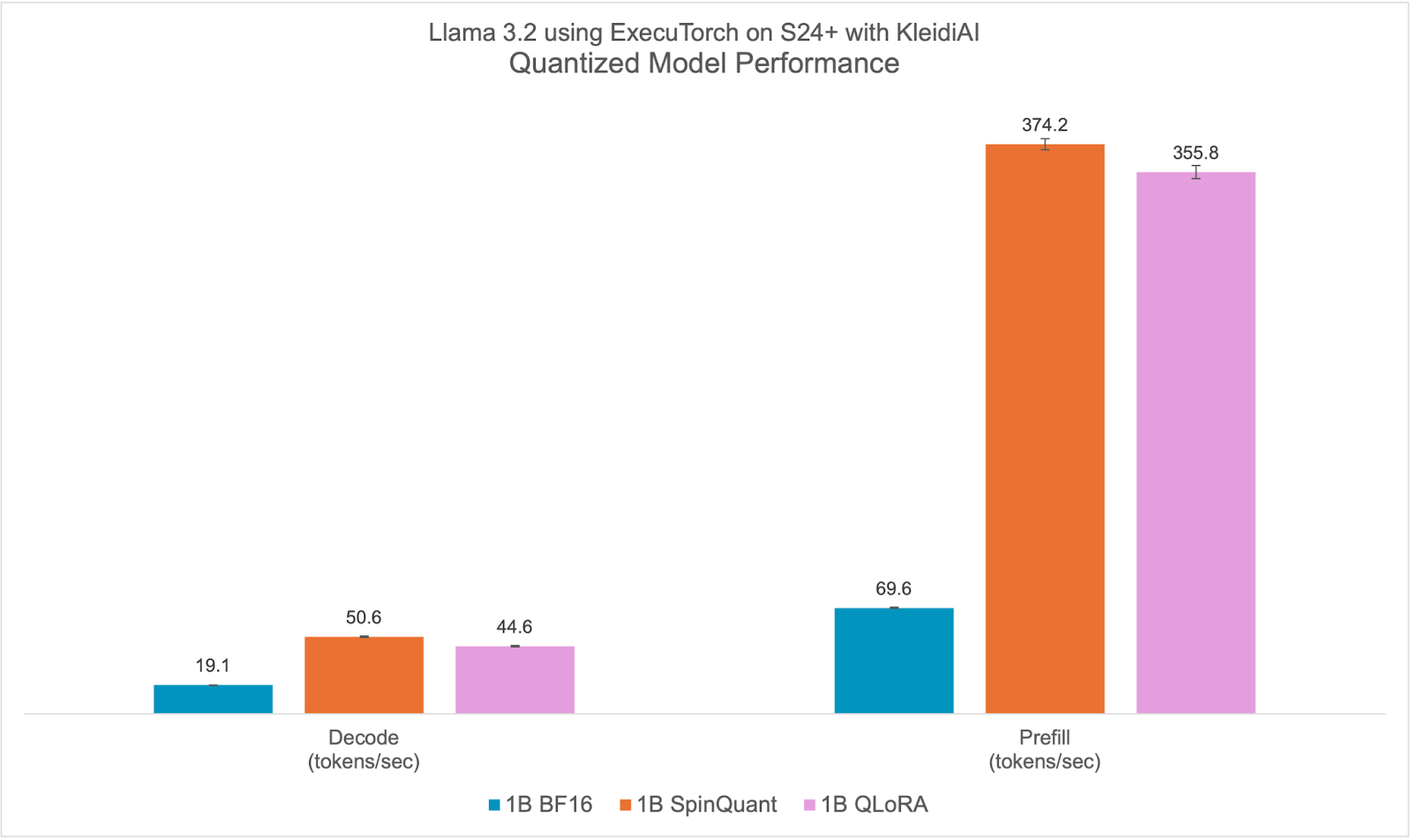
量化后的 Llama 3.2 1B 模型,包括 SpinQuant 和 QLoRA,旨在在具有有限 RAM 的广泛手机上高效运行。在本节中,我们展示了量化后的 Llama 3.2 1B 模型在预填充阶段可以达到每秒 350 个 token 以上,在解码阶段可以达到每秒 40 个 token 以上。这种性能水平足以实现设备上的文本摘要,并使用仅 Arm CPU 提供合理的用户体验。为了更直观地说明这一点,平均来说,50 条未读消息包含大约 600 个 token。以这种性能,响应时间(第一个生成的单词出现在屏幕上的时间)大约为两秒。
我们展示了在运行原生安卓的 Samsung S24+上的测量结果。这些实验使用了 Llama 3.2 1B 参数模型。尽管我们只展示了使用 1B 模型的情况,但 3B 参数模型也可以期待类似的性能提升。实验设置包括进行一次预热运行,序列长度为 128,提示长度为 64,使用 8 个 CPU 中的 6 个,并通过 adb 测量结果。
使用 GitHub 上的 ExecuTorch 主分支,我们首先使用发布的检查点为每个模型生成了 ExecuTorch PTE 二进制文件。然后,使用相同的仓库,我们为 Armv8 生成了 ExecuTorch 运行时二进制文件。在本节的其余部分,我们将比较使用 KleidiAI 构建的二进制文件的不同量化 1B 模型与 BF16 模型的性能。我们还将比较使用 KleidiAI 的二进制文件和无 KleidiAI 的二进制文件之间的量化模型性能提升,以提炼 KleidiAI 的影响。
量化模型性能
Llama 3.2 量化模型,无论是 SpinQuant 还是 QLoRA,在提示预填充和文本生成(解码)方面都显著优于基线 BF16。我们在解码方面观察到 >2 倍的提升,在预填充性能方面观察到 >5 倍的提升。
此外,量化模型的大小、PTE 文件大小(字节)不到 BF16 模型的一半,2.3 GiB 比 1.1 GiB 小。尽管 int4 的大小是 BF16 的四分之一,但模型中的一些层使用 int8 进行量化,使得 PTE 文件大小比例更大。我们观察到运行时峰值内存占用减少了近 40%,从 BF16 模型的 3.1 GiB 降至 SpinQuant 模型的 1.9 GiB,这是在最大序列长度为 2048 的情况下,以常驻集大小(RSS)测量的。
在全面改进的基础上,新的 Llama 3.2 量化模型非常适合针对 Arm CPU 的设备部署。有关准确性的更多信息,请查看 Meta Llama 3.2 博客。
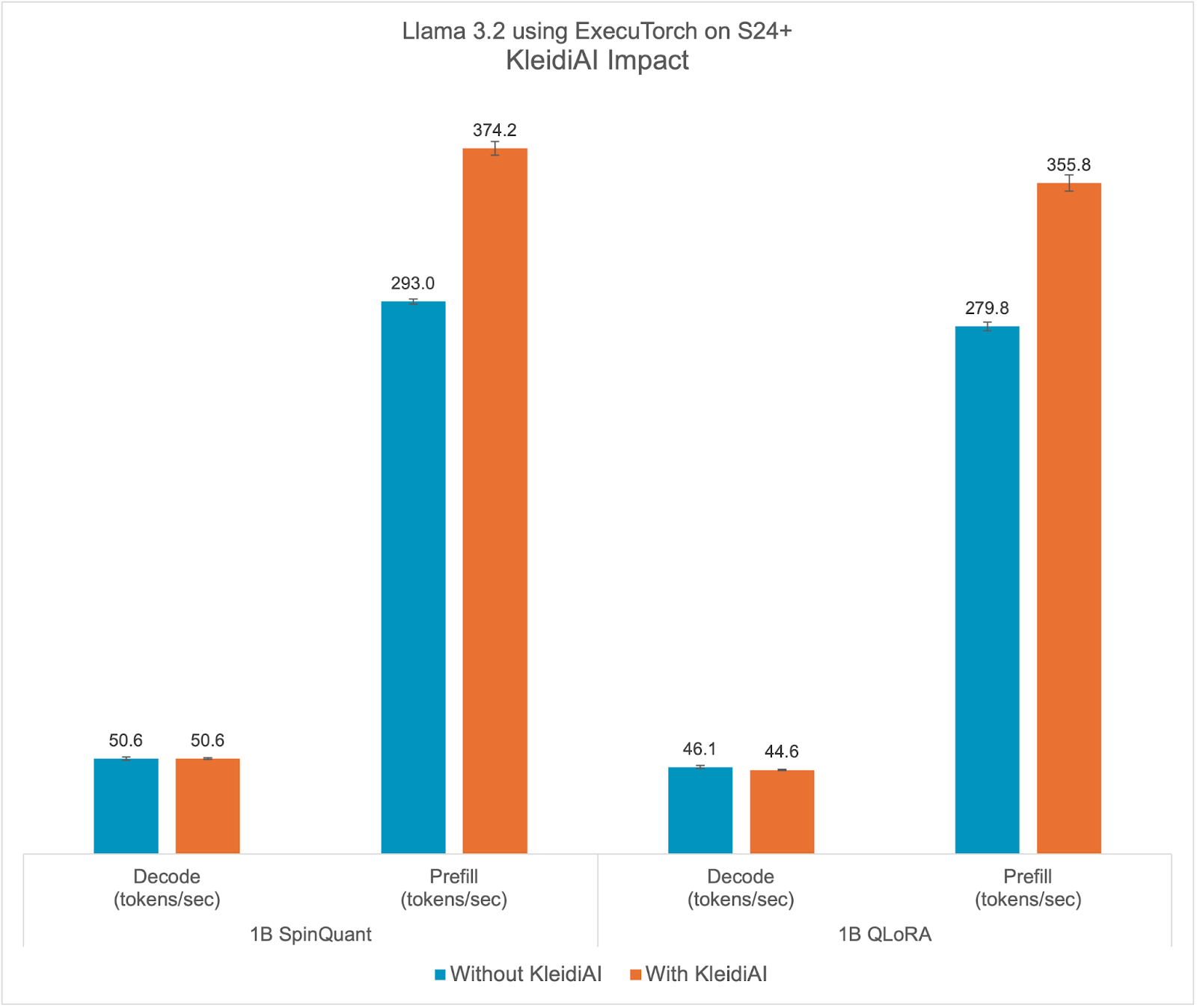
KleidiAI 影响
ExecuTorch 依赖于 Arm KleidiAI 库,为最新的 Arm CPU 提供低比特性能的矩阵乘法内核,这些内核具有先进的 Armv8/9 ISA 特性。这些内核在 ExecuTorch 中用于设备上的量化 Llama 3.2 模型推理。如图所示,与不带 KleidiAI 内核相比,ExecuTorch 在 S24+上实现了平均>20%的预填充性能提升,同时保持了相同的准确性。这种性能优势不仅限于特定模型或设备,预计将惠及所有使用 Arm CPU 上低比特量化矩阵乘法的 ExecuTorch 模型。
为了评估 Kleidi 的影响,我们生成了两个针对 Arm Cortex-A CPU 的 ExecuTorch 运行时二进制文件,并比较了它们的性能。
- 第一个 ExecuTorch 运行时二进制文件是通过 XNNPACK 库使用 Arm KleidiAI 库构建的。
- 第二个二进制文件没有使用 Arm KleidiAI 仓库,而是使用 XNNPACK 库的本地内核构建的。
试试看吧!
想亲身体验性能提升吗?以下是您如何使用 KleidiAI 提供的优化在您的项目中尝试 ExecuTorch 的方法:这里是来自 Arm 的学习路径链接,开始开发您自己的应用程序,使用LLMs ExecuTorch 和 KleidiAI。
我们期待您的反馈!