引言
易用性、表达性和调试性是 PyTorch 的核心原则之一。易用性的一个关键驱动因素是 PyTorch 的执行默认是“急切”的,即按操作顺序执行保留了程序的命令式特性。然而,急切执行不提供基于编译器的优化,例如,当计算可以表示为图时的优化。
LazyTensor [1],首次在 PyTorch/XLA 中引入,有助于结合这些看似不同的方法。虽然 PyTorch 的急切执行被广泛使用、直观且易于理解,但懒执行尚未普及。
在本文中,我们将探讨 LazyTensor 系统的一些基本概念,目的是将这些概念应用于理解和调试基于 LazyTensor 的 PyTorch 实现性能。虽然我们将使用 PyTorch/XLA 在 Cloud TPU 上作为探索这些概念的载体,但我们希望这些想法对理解基于 LazyTensors 构建的其他系统也很有用。
LazyTensor
在 PyTorch 中,对张量进行的任何操作默认都会调度为内核或内核组合到底层硬件上。这些内核在底层硬件上异步执行。程序执行不会阻塞,直到获取张量的值。这种方法与大规模并行编程硬件(如 GPU)非常匹配。
LazyTensor 系统的起点是一个自定义的张量类型。在 PyTorch/XLA 中,这种类型称为 XLA 张量。与 PyTorch 的本地张量类型相比,对 XLA 张量进行的操作会被记录到一个 IR 图中。让我们通过一个例子来查看两个张量乘积之和的操作:
import torch
import torch_xla
import torch_xla.core.xla_model as xm
dev = xm.xla_device()
x1 = torch.rand((3, 3)).to(dev)
x2 = torch.rand((3, 8)).to(dev)
y1 = torch.einsum('bs,st->bt', x1, x2)
print(torch_xla._XLAC._get_xla_tensors_text([y1]))
您可以执行这个 colab 笔记本来检查 y1 的结果图。注意,目前还没有进行任何计算。
y1 = y1 + x2
print(torch_xla._XLAC._get_xla_tensors_text([y1]))
运行将继续,直到 PyTorch/XLA 遇到障碍。这个障碍可以是标记 step() API 调用或任何其他强制执行迄今为止记录的图的任何事件。
xm.mark_step()
print(torch_xla._XLAC._get_xla_tensors_text([y1]))
一旦调用 mark_step(),图就会被编译,然后在 TPU 上执行,即张量已经被实体化。因此,现在图简化为一条单行 y1 张量,它包含计算的结果。
编译一次,执行多次
XLA 编译过程提供了优化(例如,操作融合,通过使用 scratch-pad 内存来减少 HBM 压力,参考)并利用底层 XLA 基础设施来优化使用底层硬件。然而,有一个缺点,编译过程代价高昂,即会增加训练步骤的时间。因此,这种方法只有在我们可以编译一次并经常执行时(编译缓存有助于确保相同的图不会被编译多次)才能很好地扩展。
在以下示例中,我们创建一个小型的计算图并计时其执行:
y1 = torch.rand((3, 8)).to(dev)
def dummy_step() :
y1 = torch.einsum('bs,st->bt', y1, x)
xm.mark_step()
return y1
%timeit dummy_step
The slowest run took 29.74 times longer than the fastest. This could mean that an intermediate result is being cached.
10000000 loops, best of 5: 34.2 ns per loop
你会发现最慢的步骤比最快的步骤长得多。这是因为图编译开销,这种开销只针对给定形状的图、输入形状和输出形状发生一次。后续步骤更快,因为不需要再次进行图编译。
这也意味着,当“编译一次,执行多次”的假设不成立时,我们预计会看到性能悬崖。理解何时打破这个假设是理解并优化 LazyTensor 系统性能的关键。让我们看看什么触发了编译。
图编译与执行及 LazyTensor 屏障
我们看到,当遇到 LazyTensor 障碍时,计算图会被编译和执行。LazyTensor 障碍自动或手动引入的情况有三种。第一种是显式调用 mark_step() api,如前例所示。当您使用 MpDeviceLoader 包装您的 dataloader 时,mark_step() 也会在每一步隐式调用(强烈推荐重叠计算和数据上传到 TPU 设备)。xla_model 的 Optimizer 步骤方法也允许隐式调用 mark_step(当您设置 barrier=True 时)。
第二种引入障碍的情况是当 PyTorch/XLA 找到一个没有映射(降低)到等效 XLA HLO 操作的操作。PyTorch 有 2000 多个操作。尽管这些操作中的大多数都是复合的(即可以用其他基本操作表示),但其中一些操作在 XLA 中没有相应的降低。
![]()
当使用没有 XLA 降级的操作时会发生什么?PyTorch XLA 会停止操作记录并切断导致未降级操作的输入的图。然后,这个切断的图被编译并调度执行。执行的结果(物化的张量)从设备发送回主机,然后在主机(cpu)上执行未降级的操作,然后执行下游的 LazyTensor 操作,直到再次遇到屏障。
导致 LazyTensor 屏障的第三种和最后一种情况是,当存在控制结构/语句或另一个需要张量值的方法时。这个语句至少会导致导致张量的计算图执行(如果图已经见过)或导致编译和执行两个图。
这种方法的其它例子包括 .item()、isEqual()。一般来说,任何将 Tensor 映射到 Scalar 的操作都会导致这种行为。
动态图
如前文所述,如果多次执行相同形状的图,图编译成本是分摊的。这是因为编译后的图会根据图形状、输入形状和输出形状的哈希值进行缓存。如果这些形状发生变化,将触发编译,而过度的编译将导致训练时间下降。
让我们考虑以下示例:
def dummy_step(x, y, loss, acc=False):
z = torch.einsum('bs,st->bt', y, x)
step_loss = z.sum().view(1,)
if acc:
loss = torch.cat((loss, step_loss))
else:
loss = step_loss
xm.mark_step()
return loss
import time
def measure_time(acc=False):
exec_times = []
iter_count = 100
x = torch.rand((512, 8)).to(dev)
y = torch.rand((512, 512)).to(dev)
loss = torch.zeros(1).to(dev)
for i in range(iter_count):
tic = time.time()
loss = dummy_step(x, y, loss, acc=acc)
toc = time.time()
exec_times.append(toc - tic)
return exec_times
dyn = measure_time(acc=True) # acc= True Results in dynamic graph
st = measure_time(acc=False) # Static graph, computation shape, inputs and output shapes don't change
import matplotlib.pyplot as plt
plt.plot(st, label = 'static graph')
plt.plot(dyn, label = 'dynamic graph')
plt.legend()
plt.title('Execution time in seconds')
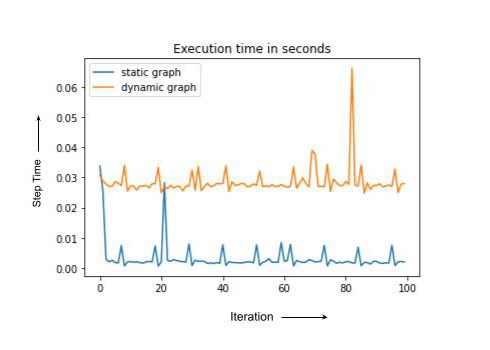
注意,静态和动态情况具有相同的计算量,但动态图每次都会编译,导致总体运行时间更高。在实践中,需要重新编译的训练步骤有时可能慢一个数量级或更慢。在下一节中,我们将讨论一些用于调试训练退化的 PyTorch/XLA 工具。
使用 PyTorch/XLA 分析训练性能
PyTorch/XLA 的剖析包括两个主要组件。首先是客户端剖析。只需将环境变量 PT_XLA_DEBUG 设置为 1 即可启用此功能。客户端剖析指向源代码中的未降低操作或设备到主机传输。客户端剖析还会报告训练过程中是否发生编译过于频繁。您可以在本笔记本中探索 PyTorch/XLA 提供的某些指标和计数器,与剖析器一起使用。
PyTorch/XLA 剖析器提供的第二个组件是内联跟踪注释。例如:
import torch_xla.debug.profiler as xp
def train_imagenet():
print('==> Preparing data..')
img_dim = get_model_property('img_dim')
....
server = xp.start_server(3294)
def train_loop_fn(loader, epoch):
....
model.train()
for step, (data, target) in enumerate(loader):
with xp.StepTrace('Train_Step', step_num=step):
....
if FLAGS.amp:
....
else:
with xp.Trace('build_graph'):
output = model(data)
loss = loss_fn(output, target)
loss.backward()
xm.optimizer_step(optimizer)
注意 start_server API 调用。您在这里使用的端口号与您将用于查看操作跟踪的 tensorboard 剖析器相同的端口号:

操作跟踪与客户端调试功能是一套强大的工具,可以帮助您使用 PyTorch/XLA 调试和优化训练性能。有关剖析器使用的更详细说明,建议读者探索 PyTorch/XLA 性能调试博客系列的第 1 部分、第 2 部分和第 3 部分。
摘要
在本文中,我们回顾了 LazyTensor 系统的基本原理。我们在此基础上使用 PyTorch/XLA 来了解训练性能下降的潜在原因。我们讨论了为什么“编译一次,执行多次”有助于在 LazyTensor 系统中获得最佳性能,以及当这个假设被打破时,为什么训练会变慢。
希望 PyTorch 用户能将这些见解用于他们与 LazyTensor 系统的创新工作。
致谢
感谢我的杰出同事 Jack Cao、Milad Mohammedi、Karl Weinmeister、Rajesh Thallam、Jordan Tottan(谷歌)和 Geeta Chauhan(Meta)的细致审阅和反馈。还要感谢来自谷歌、Meta 和开源社区的 PyTorch/XLA 扩展开发团队,使得 PyTorch 能够在 TPU 上运行。最后,感谢 LazyTensor 论文的作者们,不仅因为他们开发了 LazyTensor,还因为他们撰写了如此易于理解的论文。
参考文献
[ 1] LazyTensor:将即时执行与领域特定编译器相结合