今天,我们发布了 torchchat 库,展示了如何在笔记本电脑、桌面和移动设备上无缝且高效地运行 Llama 3、3.1 和其他大型语言模型。
在我们之前的博客文章中,我们展示了如何使用原生 PyTorch 2 以优异的性能运行LLMs。Torchchat 在此基础上扩展了更多目标环境、模型和执行模式。此外,它还提供了导出、量化、评估等重要功能,以易于理解的方式提供端到端的故事,为那些想要构建本地推理解决方案的人提供了便利。
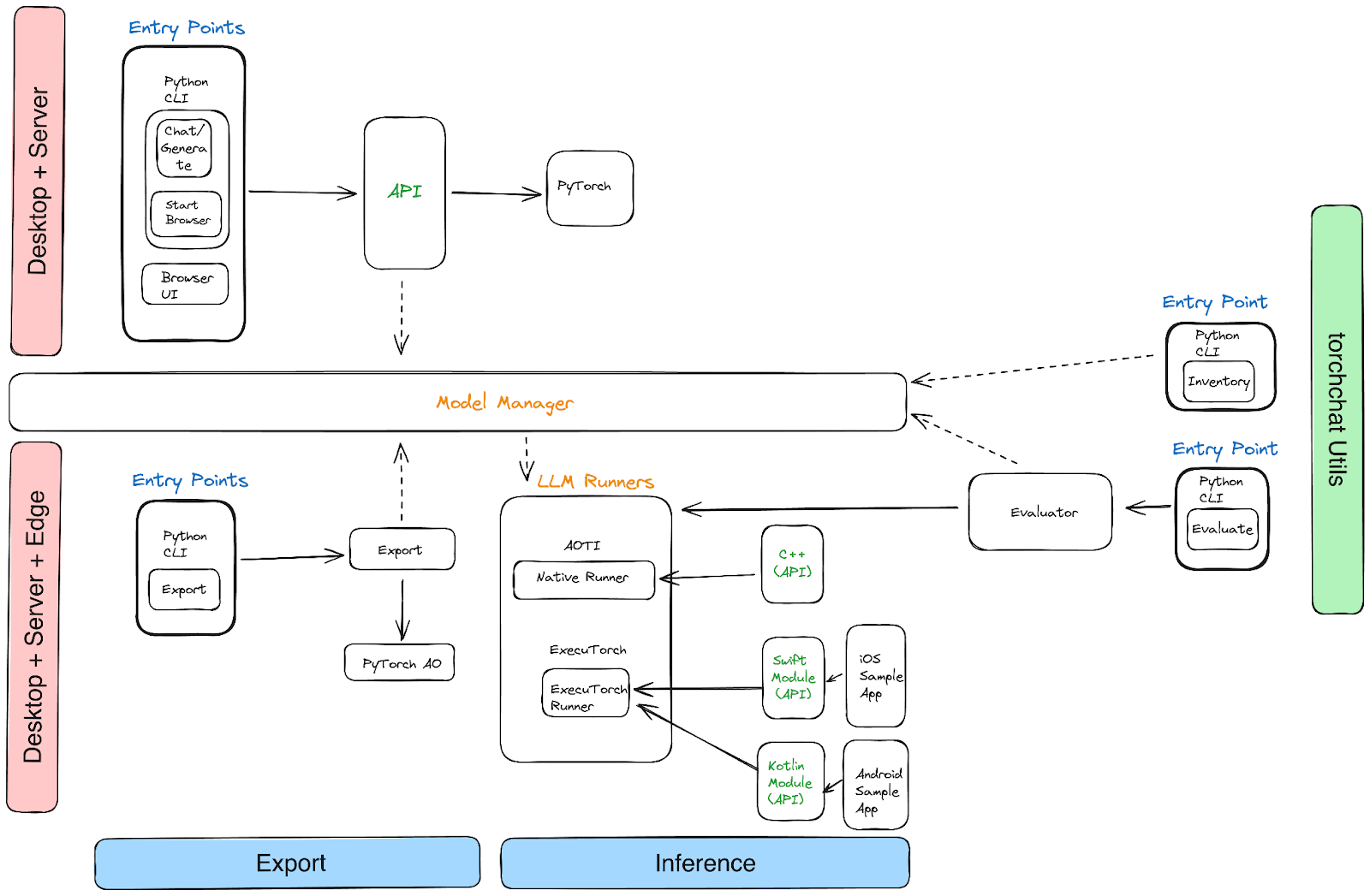
您将发现该项目分为三个区域:
- Python:Torchchat 提供了一个 REST API,可以通过 Python CLI 调用或通过浏览器访问。
- C++:Torchchat 使用 PyTorch 的 AOTInductor 后端生成桌面友好的二进制文件
- 移动设备:Torchchat 使用 ExecuTorch 导出用于设备推理的.pte 二进制文件
性能
下表跟踪了 torchchat 在 Llama 3 上的性能,针对各种配置。
Llama 3.1 的数字即将推出。
Llama 3 8B 在 Apple MacBook Pro M1 Max 64GB 笔记本上运行
| 模式 | DType | Llama 3 8B 每秒 Tokens |
| 架构编译 | float16 | 5.84 |
| int8 | 1.63 | |
| int4 | 3.99 | |
| 臂 AOTI | float16 | 4.05 |
| int8 | 1.05 | |
| int4 | 3.28 | |
| MPS 渴望 | float16 | 12.63 |
| int8 | 16.9 | |
| int4 | 17.15 |
Llama 3 8B Instruct 在 Linux x86 和 CUDA 上
英特尔® 至强® 铂金 8339HC CPU @ 1.80GHz,配备 180GB 内存 + A100 (80GB)
| 模式 | 数据类型 | 羊驼 3 8B Tokens/Sec |
| x86 编译 | bfloat16 | 2.76 |
| int8 | 3.15 | |
| int4 | 5.33 | |
| CUDA 编译 | bfloat16 | 83.23 |
| int8 | 118.17 | |
| int4 | 135.16 |
Llama3 8B Instruct 在移动端
Torchchat 在三星 Galaxy S23 和 iPhone 上使用 4 位 GPTQ 通过 ExecuTorch 实现了>8T/s。
结论
我们鼓励您克隆 torchchat 仓库,试一试,探索其功能,并在我们继续赋能 PyTorch 社区在本地和受限设备上运行LLMs的同时,分享您的反馈。让我们共同挖掘生成 AI 和LLMs在任意设备上的全部潜力。请提交您遇到的问题,因为我们仍在快速迭代。我们还邀请社区在广泛领域做出贡献,包括额外的模型、目标硬件支持、新的量化方案或性能改进。祝您实验愉快!