TLDR:我们展示了在 A100 GPU 上对 float32 Vision Transformers 应用块稀疏性在 MLP 模块权重上,实现了高达 1.46 倍的速度提升,同时精度下降不到 2%的令人鼓舞的结果。这种方法可能适用于包括大型语言模型在内的其他类型的 transformers。我们的实现和复现结果的基准测试可在 https://github.com/pytorch-labs/superblock 找到。
引言
PyTorch 对实现块稀疏矩阵乘法的 CUDA 内核进行了大量改进。PyTorch 的最新更新可以使大型矩阵乘法形状在稀疏级别上比密集基线提高高达 4.8 倍的速度。
在本文中,我们展示了在视觉 Transformer(ViTs)中应用块稀疏性于 MLP(多层感知器)层的线性权重上的令人鼓舞的结果,并在 A100 Nvidia GPU 上展示了端到端模型的速度提升。
作为回顾,块稀疏性是对预定大小的块中的权重进行稀疏化,而不是对单个元素进行稀疏化。这种特定的稀疏模式很有趣,因为它可以通过快速稀疏内核进行 GPU 加速。有关不同稀疏模式之间的差异或关于稀疏性的更多信息,请查看 torchao。

不同类型稀疏性的插图。
方法
我们的方法可以分为两个不同的步骤:
- 从头开始训练模型,使用块稀疏掩码子网。
- 将这些掩码折叠到我们的权重中,以加速推理。
下面我们解释我们的训练和推理步骤。
训练
从一个未初始化的视觉 Transformer 开始,我们在输出投影线性层、两个线性层(即 FFN,前馈网络)的权重以及最终的线性分类层上应用随机可训练的掩码,这些掩码具有指定的块大小和稀疏度级别。训练期间的向前传递遵循超掩码方法,因为每个掩码都使用基于稀疏度要求的调整阈值转换为二进制图,例如,如果我们想要 80%的稀疏度,我们将自动调整阈值以保留顶部 20%的权重。掩码是<块大小> x <块大小>元素的方形,其中<块大小>是一个超参数。权重的优先级取决于训练的掩码值或分数。我们将每个层的二进制掩码与权重相乘以稀疏化模型。
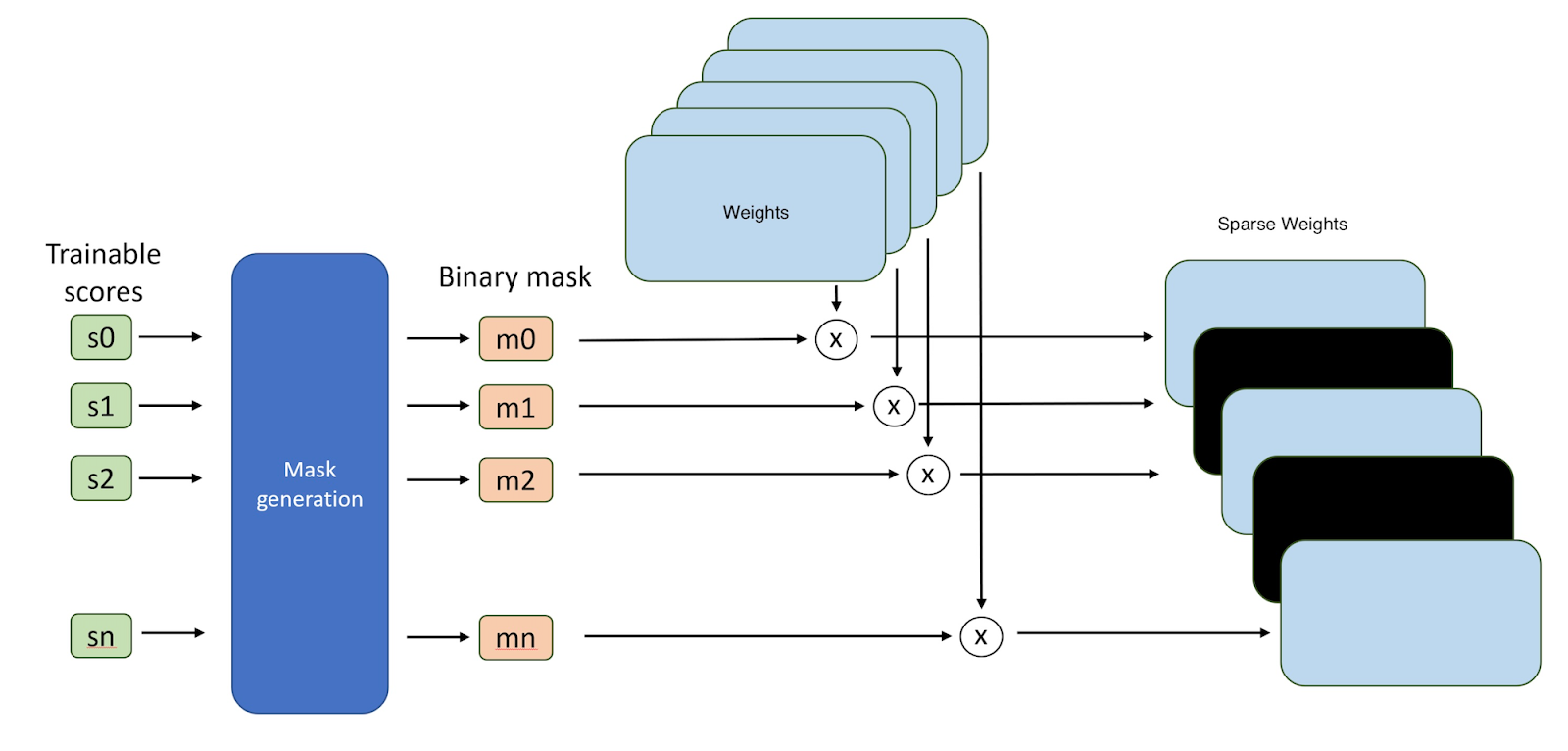
超掩码稀疏化方法的示意图。
推理
训练完成后,可以通过与掩码相乘将密集权重转换为稀疏权重,并存储用于推理。在此阶段,尽管权重有很高的零值比例,但它们仍然以密集格式存储。我们使用 PyTorch 的 to_sparse_bsr() API 将权重转换为仅存储非零值及其块索引的块稀疏表示(BSR)格式。这一步骤只需执行一次,结果可以缓存以供运行时使用。
在运行时,无需对代码进行任何更改。我们只需将任何输入张量传递给模型,当调用稀疏化线性层的 forward()函数时,PyTorch 会负责调用针对块稀疏权重的优化矩阵乘法。这适用于 A100 以及 H100 NVIDIA GPU。
结果:微基准测试
为了从性能角度验证块稀疏性的可行性,我们首先使用这个简单的脚本运行了一系列微基准测试。使用 ViT-b 的线性形状,我们比较了在改变权重矩阵的稀疏程度和块大小时,我们块稀疏内核在单个线性层上的加速情况。
我们使用 PyTorch 2.3.0.dev20240305+cu121 夜间版在 NVIDIA A100s 上运行,并报告了与密集基线相比的每个稀疏配置的加速。当块大小≥32 或稀疏程度≥0.8 时,我们观察到正加速,而对于 bfloat16,我们观察到较小的加速,通常在块大小 64 和更高稀疏度时。因此,对于模型的端到端加速,我们将在这篇博客中专注于 float32,并将 bfloat16 留待未来研究。
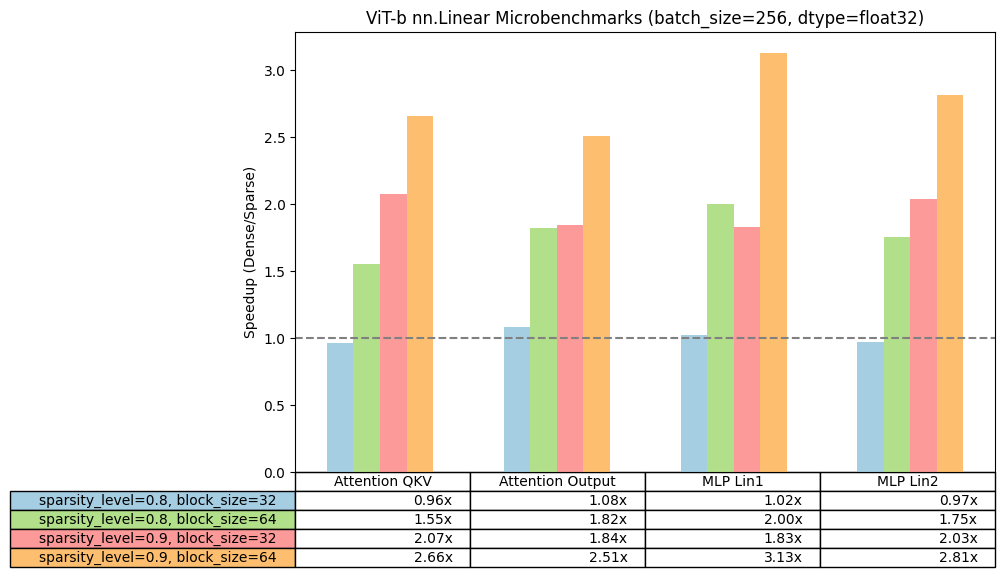
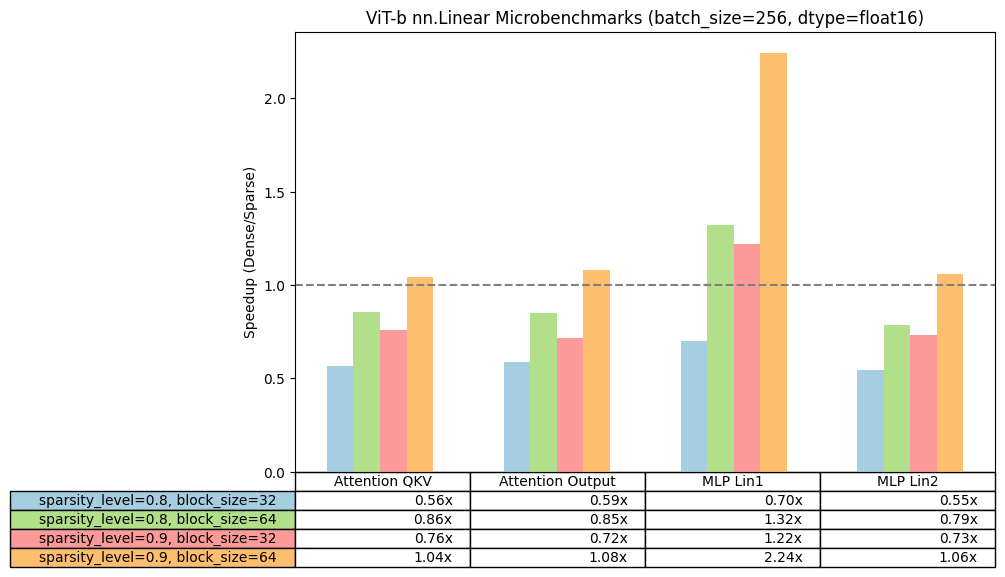
ViT-b-16 线性层的微基准测试结果。
结果:视觉 Transformer
一旦我们确认能够展示比线性层更快的速度提升,我们就专注于在 ViT_B_16 上展示端到端的速度提升。
我们使用标准的 ViT_B_16 配方在 ImageNet 数据集上从头开始训练了这个模型。我们展示了稀疏化 MLP 模块的速度提升,并将输入和输出投影的注意力稀疏化权重留待未来研究。
我们关注了墙钟推理速度提升,重点关注批大小为 256 的情况。我们发现:
- 对于 90%的稀疏度,对于块大小为 16、32 和 64,我们可以分别获得 1.24 倍、1.37 倍和 1.65 倍的速度提升。
- 为了获得加速,块大小为 16、32 和 64 的最小稀疏度分别为 0.86、0.82 和 0.7。因此,正如预期的那样,块大小越大,我们需要的稀疏度就越小。
我们注意到 sparse_bsr() API 的一个局限性:层的大小必须是块大小的倍数。由于 ViT 中最后一个 FC 分类层的维度不是块大小的倍数,因此在我们实验中它们没有被转换为 BSR 表示。
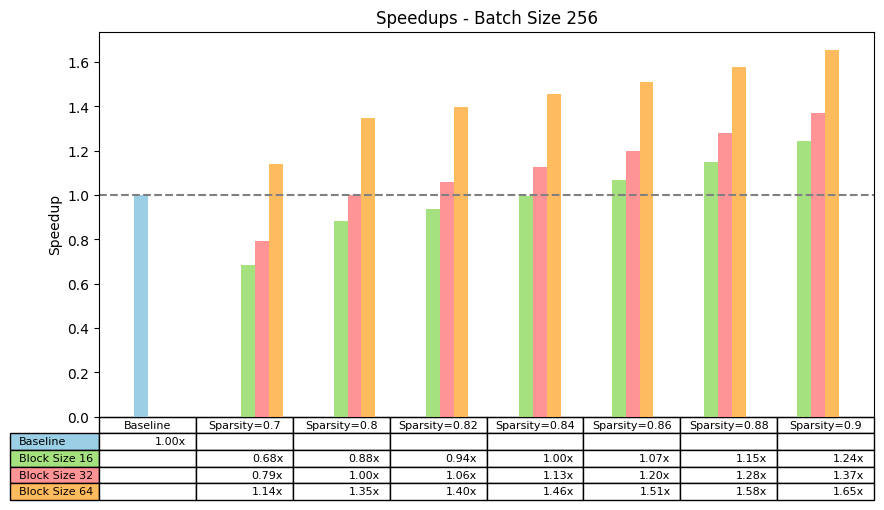
在不同批处理稀疏度和块大小下,对 ViT-b-16 的 MLP 模块进行 256 批处理大小加速。
我们还探索了 90%稀疏度下不同批处理大小的加速。我们观察到,从 16 个批处理大小开始,相对于基线都有加速。虽然较大的块大小在最大的批处理大小下有更大的加速,但获得>1 加速的最小批处理大小对于较小的块大小来说更小。
我们相信,在设备上使用硬件可以针对批量大小为 1 的情况获得加速,因为与服务器 GPU 不同,它们可以在如此小的批量大小下得到充分利用。
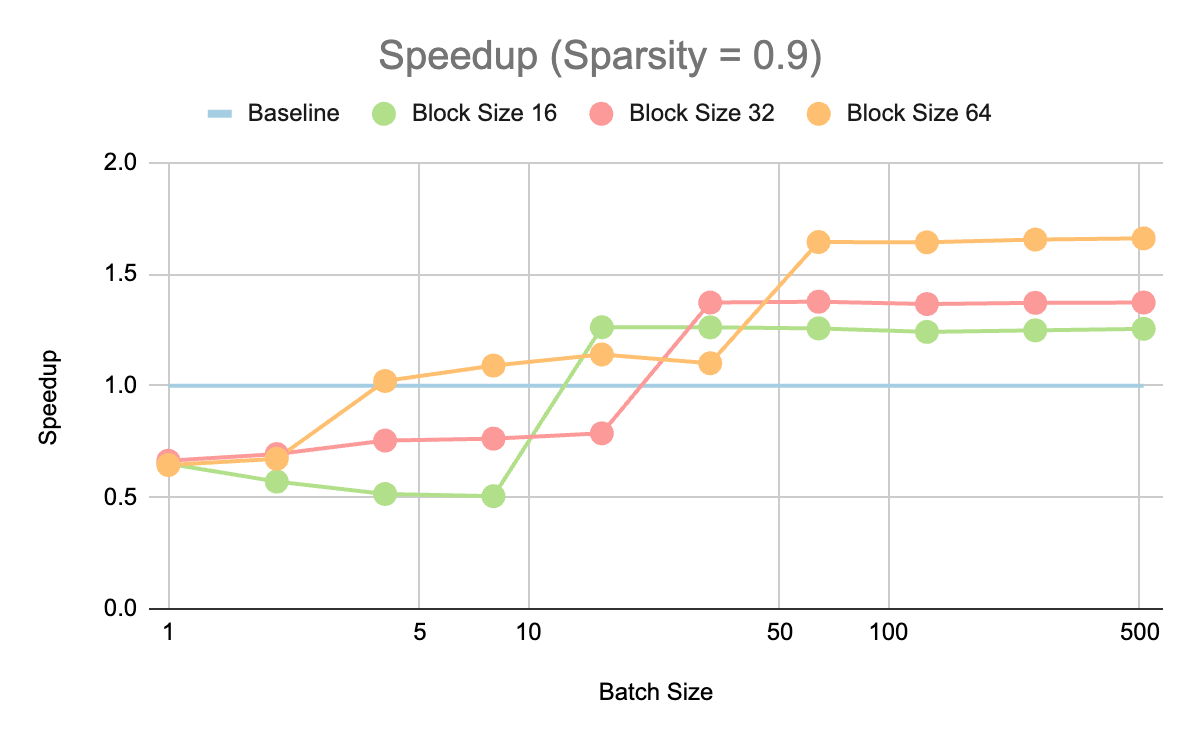
在不同批量大小和块大小下,对 ViT-b-16 的 MLP 模块进行 90%稀疏化后的加速。
观察不同块大小和稀疏度的稀疏化模型在 ImageNet=blurred 测试集上的 Top-1 准确率,我们看到了一些预期结果:
- 稀疏度低(<=70%)对准确率没有明显的下降。
- 稀疏度中等水平(≥80%至<90%)对准确率的影响有限
- 稀疏度较高(≥90%)会移除很多权重,导致准确率显著下降
可以进行更多研究以提高更高稀疏度和更大块大小的准确率。我们希望 PyTorch 中的块稀疏度支持以及本博客中展示的速度提升能够鼓励研究人员探索更精确的稀疏化方法。
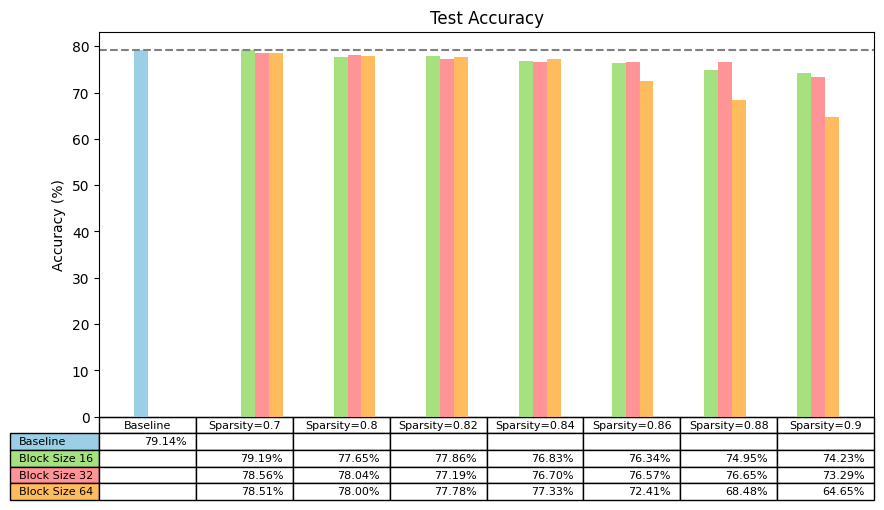
使用 SuperMask 方法在 ImageNet-blurred 上训练 ViT-b-16 的准确率
下一步
我们已经在 float32 精度下展示了块稀疏化 MLP 模块 ViT 的显著加速。为了观察到 bfloat16 上的加速,我们还有更多工作要做,并希望在这方面尽快取得进展。进一步优化视觉 Transformer 和 Transformer 的块稀疏度的可能下一步是:
- 对注意力输入和输出投影执行块稀疏化。
- 在微调期间执行块稀疏化,而不是从头开始训练。
- 对 ViT 的线性算子特定形状(特别是 80%及以下稀疏度)的 matmul 内核进行进一步优化。
- 结合其他优化措施,例如 int8 和 torch.compile()
- 探索其他权重稀疏化算法,例如 Spartan,以提高准确性
- 探索选择要稀疏化的权重(例如,特定的 Transformer 层)
如有疑问或有意为块稀疏化做出贡献,请联系 melhoushi@meta.com!
另外,如果您对稀疏性有广泛的兴趣,请随时联系 @jcaip / jessecai@meta.com,并请来参观 torchao,这是我们正在构建的一个用于架构优化技术(如量化与稀疏性)的社区。