TL;DR:我们展示了使用 PyTorch 和 FairScale 的 FullyShardedDataParallel(FSDP)API 编写大型视觉 Transformer 模型的方法。我们讨论了我们在 GPU 集群上扩展和优化这些模型的技术。这项平台扩展工作的目标是实现规模化的研究。本博客不讨论模型精度、新的模型架构或新的训练方法。
1. 引言
最新视觉研究[1, 2]表明,模型扩展是一个有希望的研究方向。在本项目中,我们旨在使我们的平台能够训练大规模视觉 Transformer(ViT[3])模型。我们展示了在 FAIR 视觉平台上将可训练的最大的 ViT 从 1B 扩展到 120B 参数的工作。我们使用 PyTorch 编写了 ViT,并利用了其在 GPU 集群上进行大规模、分布式训练的支持。
在本博客的剩余部分,我们将首先讨论主要挑战,即可扩展性、优化和数值稳定性。然后我们将讨论如何通过包括数据并行和模型并行、自动混合精度、内核融合和 bfloat16 等技术来应对这些挑战。最后,我们将展示我们的结果并得出结论。
2. 主要挑战
2.1 可扩展性
关键的可扩展性挑战是高效地将模型操作和状态分片到多个 GPU 上。一个 100B 参数的模型仅参数就需要大约 200GB 的 RAM,假设使用 fp16 表示。因此,将模型放在单个 GPU 上(A100 最多有 80GB RAM)是不可能的。因此,我们需要一种方法来高效地将模型的数据(输入、参数、激活和优化器状态)分片到多个 GPU 上。
这个问题的另一个方面是在不显著改变训练方案的情况下进行扩展。例如,某些表示学习方案使用高达 4096 的全局批量大小,超过这个范围我们开始看到准确度下降。如果不使用某种形式的张量或管道并行性,我们无法扩展到超过 4096 个 GPU。
2.2 优化
关键的优化挑战是在扩展模型参数数量和浮点运算次数的同时保持高 GPU 利用率。当我们扩展模型到每秒万亿次浮点运算甚至更高时,我们的软件堆栈开始遇到瓶颈,这些瓶颈会超线性增加训练时间并降低加速器的利用率。我们可能需要数百或数千个 GPU 才能运行单个实验。提高加速器利用率可以显著降低成本并提高车队利用率。这使我们能够资助更多项目并并行运行更多实验。
2.3 数值稳定性
关键的稳定性挑战在于避免在大规模情况下出现数值不稳定和发散。我们在实验中观察到,当模型大小、数据、批大小、学习率等规模扩大时,训练不稳定会变得严重且难以处理。视觉 Transformer 即使在较低的参数阈值下也面临着训练不稳定的问题。例如,我们发现即使在混合精度模式下,不使用强大的数据增强,训练 ViT-H(仅有 6300 万参数)也具有挑战性。我们需要研究模型属性和训练方法,以确保模型能够稳定训练并收敛。
3. 我们的解决方案
图 1 展示了我们针对每个挑战的解决方案。
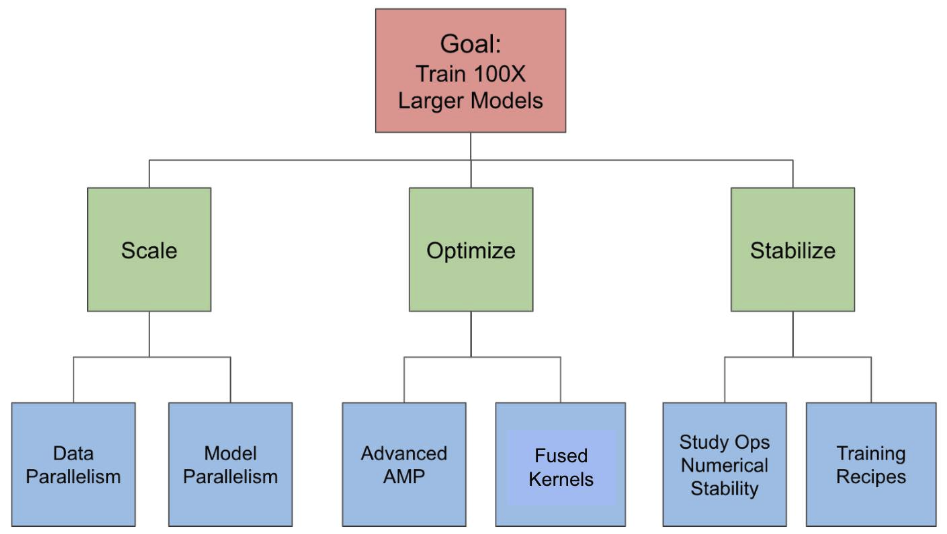
3.1 使用数据并行和模型并行解决扩展挑战
我们应用各种形式的数据和模型并行性,以在 GPU 内存中适应非常大的模型。
我们使用 FairScale 的基于 PyTorch 的 FullyShardedDataParallel (FSDP) API [4],将参数、梯度和优化器状态分散到多个 GPU 上,从而减少了每个 GPU 的内存占用。这个过程包括以下三个步骤:
-
步骤 1:我们将整个模型封装在一个 FSDP 实例中。这将在前向传播的末尾分割模型参数,并在前向传播的开始处收集参数。这使得我们能够将参数规模从 15 亿增加到 45 亿,扩展了约 3 倍。
-
步骤 2:我们尝试将单个模型层分别封装在独立的 FSDP 实例中。这种嵌套封装通过分割和收集单个模型层的参数而不是整个模型的参数,进一步减少了内存占用。在这种模式下,峰值内存由 GPU 内存中的独立封装的 transformer 块决定,而不是整个模型。
-
步骤 3:我们使用激活检查点来减少激活的内存消耗。它保存输入张量,并在正向传播过程中丢弃中间激活张量。这些张量在反向传播过程中重新计算。
此外,我们还尝试了模型并行技术,如流水线并行[5],这使我们能够在不增加批处理大小的情况下扩展到更多的 GPU。
3.2 使用高级 AMP 和内核融合解决优化挑战
高级 AMP
自动混合精度(AMP)[6]训练是指使用比 FP32 或默认精度更低的位数来训练模型,同时仍然保持精度。我们实验了以下三个级别的 AMP:
-
AMP O1:这指的是混合精度训练,其中权重在 FP32,而一些操作在 FP16。在 AMP O1 中,可能影响精度的操作仍然在 FP32,不会被自动转换为 FP16。
-
AMP O2:这指的是混合精度训练,但 FP16 的权重和操作比 O1 更多。权重不会隐式地保持在 FP32,而是转换为 FP16。维护一个 FP32 精度的主权重副本,这是优化器使用的。如果我们想将归一化层权重保持在 FP32,则需要显式使用层包装来确保这一点。
-
全 FP16:这指的是全 FP16 训练,其中权重和操作都在 FP16。由于收敛问题,FP16 对于训练来说具有挑战性。
我们发现使用 FP32 封装的 LayerNorm 的 AMP O2 在保证准确性的同时,性能最佳。
核融合
- 为了减少 GPU 内核启动开销并增加 GPU 工作粒度,我们使用 xformers 库[7]进行了内核融合实验,包括融合 dropout 和融合层归一化。
3.3 通过研究操作数值稳定性和训练方案来解决稳定性挑战
BFloat16 在一般情况下的使用,但 LayerNorm 需要在 FP32 模式下
bfloat16 (BF16) [8] 浮点格式提供了与 FP32 相同的动态范围,同时内存占用与 FP16 相同。我们发现,我们可以使用与 FP32 相同的超参数在 BF16 格式下训练模型,无需特殊参数调整。然而,我们发现为了使训练收敛,我们需要将 LayerNorm 保持为 FP32 模式。
3.4 最终训练方案
最终训练方案的总结。
- 将外部模型包裹在 FSDP 实例中。在正向传播后启用参数分片。
- 将单个 ViT 块包裹在激活检查点、嵌套 FSDP 包裹和参数展平中。
- 启用混合精度模式(AMP O2)并使用 bfloat16 表示。以 FP32 精度保持优化器状态以增强数值稳定性。
- 将归一化层(如 LayerNorm)包裹在 FP32 中以提高数值稳定性。
- 通过将矩阵维度保持为 8 的倍数来最大化 Nvidia TensorCore 的利用率。更多详情请查看 Nvidia Tensor Core 性能指南。
4. 结果
在本节中,我们展示了 ViT 在三种类型任务上的扩展结果:(1)图像分类,(2)目标检测,(3)视频理解。我们的关键结果是,在应用所讨论的扩展和优化技术后,我们能够在这些视觉任务上训练大规模的 ViT 骨干网络。这使得视觉研究能够以更大的规模进行。我们将模型训练到收敛,以验证即使在所有优化之后,我们也能保持当前的基线。图 2、3、4 中的共同趋势是,我们能够在 128 个 A100 GPU 上以小于 4 小时的 epoch 时间训练高达 25B 参数的模型。60B 和 120B 模型训练速度相对较慢。
图 2 展示了图像分类的扩展结果。它绘制了使用 128 个 A100-80GB GPU 在 ImageNet 上训练 ViT 的 epoch 时间,并展示了不同模型大小。
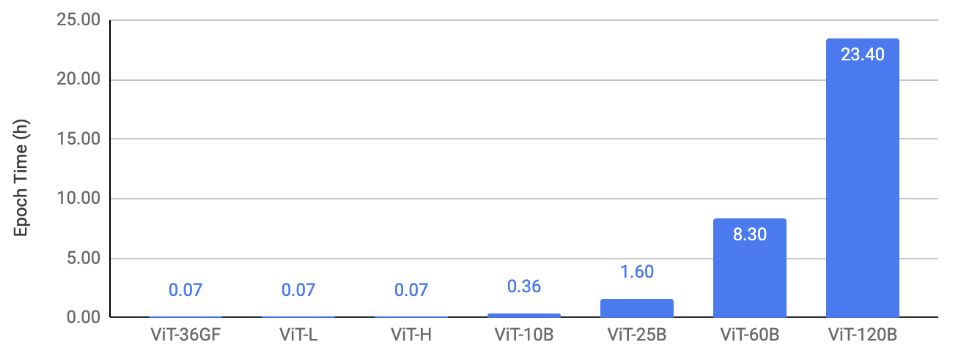
图 2:图像分类缩放结果。
图 3 展示了目标检测缩放结果。它绘制了在 COCO 上使用不同 ViT 主干训练 ViTDet [9]的每个 epoch 的训练时间,使用了 128 块 A100-80GB GPU。
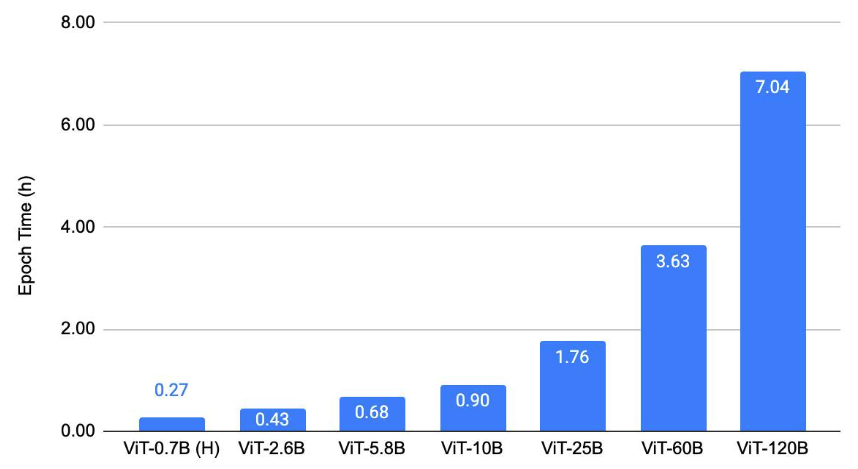
图 3:目标检测缩放结果。
图 4 展示了视频理解缩放结果。它绘制了在 Kinetics 400 [11]上使用 128 块 V100(32 GB)GPU 以 FP32 模式训练 MViTv2 [10]模型的每个 epoch 的训练时间。
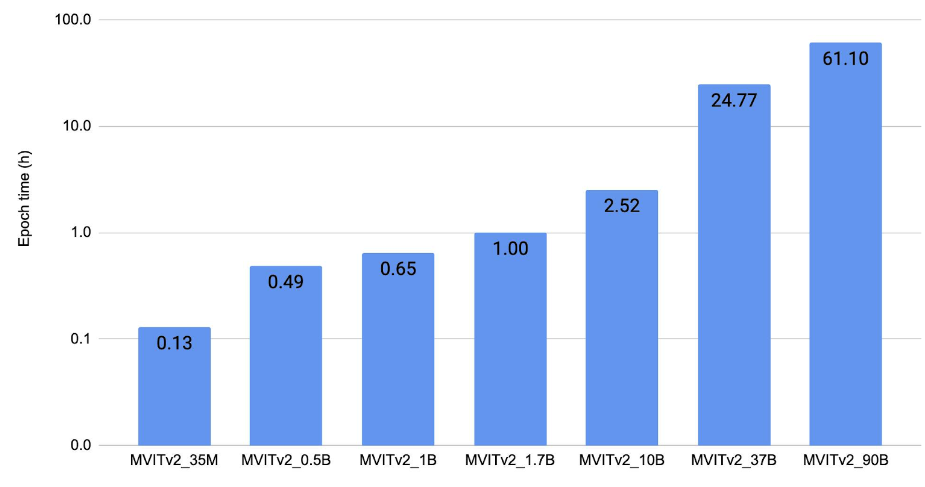
图 4:视频理解扩展结果。
图 5 展示了在图 2 中的 ViT-H 模型上,使用 8 个 A100-40GB GPU 的优化结果。使用了三个版本:(1)基线使用 PyTorch 的 DDP [12]和 AMP O1,(2)FSDP + AMP-O2 +其他优化,(3)FSDP + FP16 +其他优化。这些优化总共将训练速度提高了高达 2.2 倍。
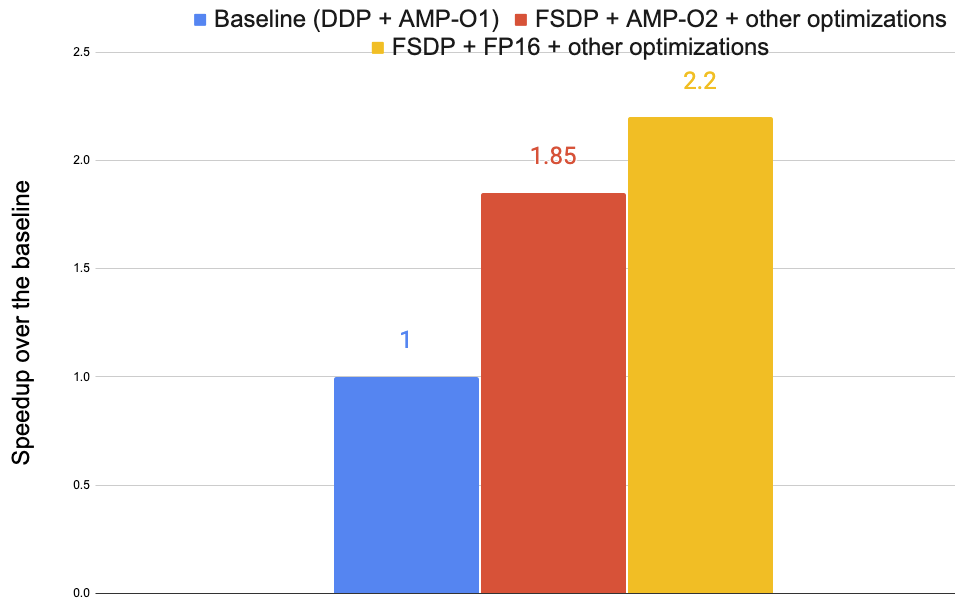
图 5:各种优化带来的训练加速。
5. 结论
我们已经展示了使用 FairScale 的 FullyShardedDataParallel (FSDP) API 与 PyTorch 结合编写大型视觉 Transformer 模型的方法。我们讨论了在 GPU 集群上对这些模型进行扩展和优化的技术。我们希望这篇文章能够激励其他人使用 PyTorch 及其生态系统开发大规模机器学习模型。
参考文献列表
[1] 面具自动编码器是可扩展的视觉学习者
[2] 重新审视视觉感知模型的弱监督预训练
[3] 一张图片等于 16x16 个单词:大规模图像识别的 Transformer
[4] fairscale.nn.FullyShardedDataParallel
[5] PyTorch 中的流水线并行
[6] PyTorch 中的自动混合精度(AMP)
[7] xformers
[8] bfloat16 数值格式
[9] 探索用于目标检测的 Plain Vision Transformer 主干网络
[10] MViTv2:改进的多尺度视觉 Transformer,用于分类和检测
[11] https://www.deepmind.com/open-source/kinetics
[12] 分布式数据并行(DDP)入门