引言
近年来,模型规模的扩展已成为一个有前景的研究领域。在自然语言处理领域,语言模型从数亿参数(BERT)发展到数百亿参数(GPT-3),在下游任务上取得了显著的改进。大型语言模型的扩展定律也已在业界得到广泛研究。在视觉领域,社区也转向了基于 Transformer 的模型(如视觉 Transformer、掩码自编码器)等。很明显,单个模态——文本、图像、视频——都从最近的规模改进中获得了巨大利益,并且框架迅速适应以容纳更大的模型。
同时,多模态在图像-文本检索、视觉问答、视觉对话和文本到图像生成等任务中的研究变得越来越重要,这些任务在现实世界应用中得到了广泛关注。训练大规模多模态模型是自然而然的下一步,我们已经在这一领域看到了一些努力,例如 OpenAI 的 CLIP、Google 的 Parti 和 Meta 的 CM3。
在本文中,我们通过一个案例研究展示了如何使用 PyTorch Distributed 技术将 FLAVA 扩展到 10B 参数。FLAVA 是一个视觉和语言基础模型,可在 TorchMultimodal 中使用,在单模态和多模态基准测试中均表现出竞争力。我们还在本文中提供了相关的代码链接。运行扩展 FLAVA 示例脚本的说明可以在此找到。
扩展 FLAVA 概述
FLAVA 是一个基础的多模态模型,由基于 transformer 的图像和文本编码器组成,随后是基于 transformer 的多模态融合模块。它在单模态和多模态数据上进行了预训练,并使用了一系列损失函数。这包括掩码语言、图像和多模态建模损失,这些损失要求模型从其上下文中重建原始输入(自监督学习)。它还使用图像文本匹配损失,在正负对齐的图像-文本对上进行,以及 CLIP 风格的对比损失。除了多模态任务(如图像-文本检索)之外,FLAVA 在单模态基准测试(NLP 的 GLUE 任务和视觉的图像分类)上也表现出竞争力的性能。
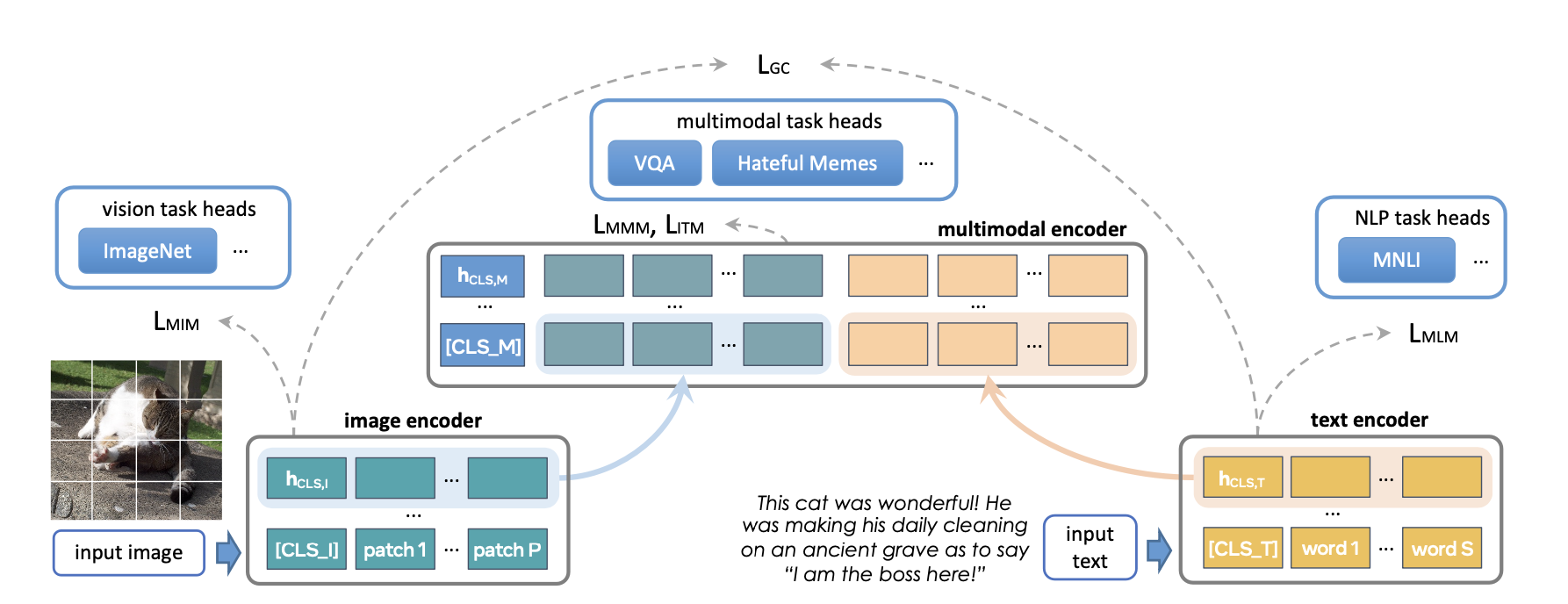
原始 FLAVA 模型有约 3.5 亿个参数,使用 ViT-B16 配置(来自视觉 Transformer 论文)作为图像和文本编码器。多模态融合 transformer 遵循单模态编码器,但层数减半。我们探讨了将每个编码器的大小增加到更大的 ViT 变体。
扩展的另一个方面是增加增加批量大小的能力。FLAVA 利用对比损失在批内负样本上,这通常从大批次中受益(如在此研究中所示)。当操作接近由可用 GPU 内存量确定的可能最大批次大小时,通常也能实现最大的训练效率或吞吐量(也请参阅实验部分)。
下表显示了我们在实验中尝试的不同模型配置。我们还在实验部分确定了每个配置能够适应内存的最大批次大小。
| 近似模型参数 | 隐藏层大小 | MLP 大小 | 头部 | 单模态层 | 多模态层 | 模型大小(fp32) |
|---|---|---|---|---|---|---|
| 350M(原始) | 768 | 3072 | 12 | 12 | 6 | 1.33GB |
| 900M | 1024 | 4096 | 16 | 24 | 12 | 3.48GB |
| 1.8B | 1280 | 5120 | 16 | 32 | 16 | 6.66GB |
| 2.7B | 1408 | 6144 | 16 | 40 | 20 | 10.3GB |
| 4.8B | 1664 | 8192 | 16 | 48 | 24 | 18.1GB |
| 10B | 2048 | 10240 | 16 | 64 | 40 | 38GB |
优化概述
PyTorch 提供了多种原生技术来高效扩展模型。在以下章节中,我们将介绍其中一些技术,并展示如何将这些技术应用于将 FLAVA 模型扩展到 100 亿参数。
分布式数据并行
分布式训练的常见起点是数据并行。数据并行将模型复制到每个工作节点(GPU)上,并将数据集分配给各个工作节点。不同的工作节点并行处理不同的数据分区,并在更新模型权重之前同步它们的梯度(通过 all-reduce)。下图展示了数据并行处理单个示例的流程(正向、反向和权重更新步骤):
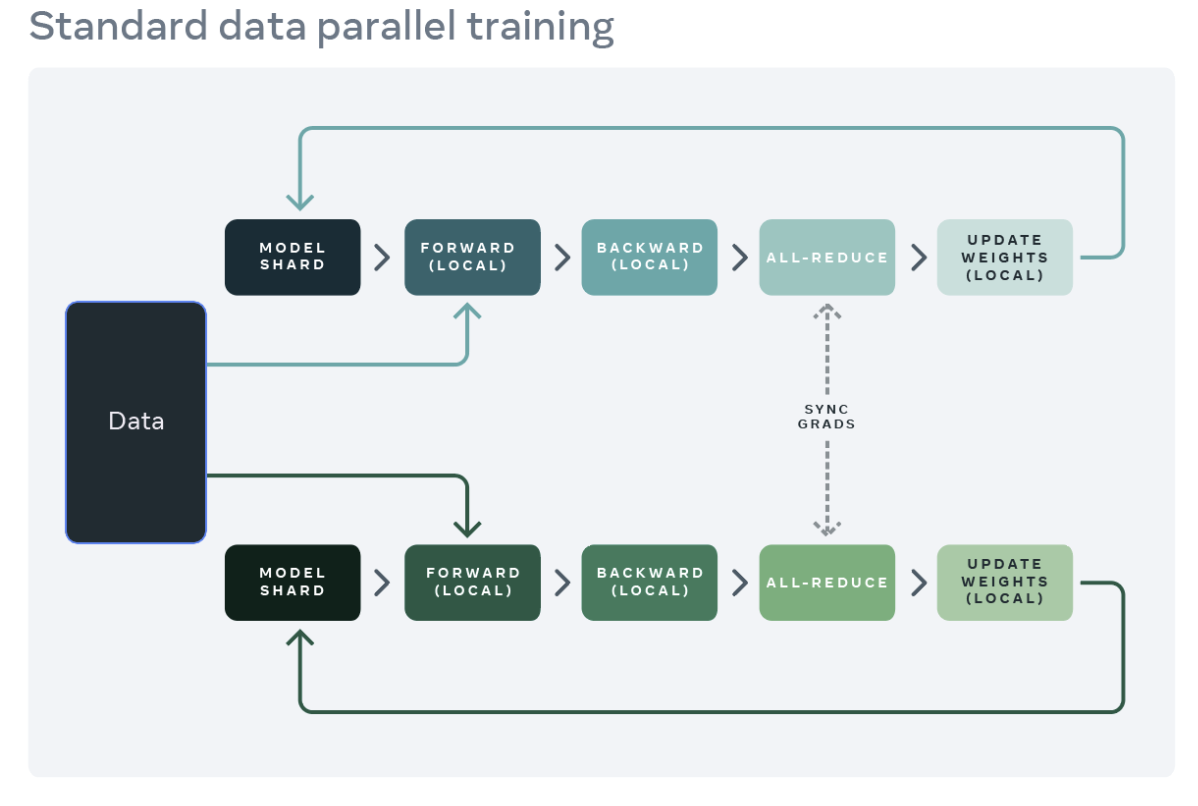
来源:https://engineering.fb.com/2021/07/15/open-source/fsdp/
PyTorch 提供了原生的 API,即 DistributedDataParallel(DDP),以实现数据并行,它可以作为一个模块包装器使用,如下所示。请参阅 PyTorch 分布式文档以获取更多详细信息。
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://maskerprc.github.io/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])
全分片数据并行
GPU 训练应用内存使用大致可以分为模型输入、中间激活(用于梯度计算)、模型参数、梯度和优化器状态。放大模型通常会增加这些元素。使用 DDP 放大模型可能会导致内存不足问题,因为当单个 GPU 内存不足时,它会在所有工作者上复制参数、梯度和优化器状态。
为了减少这种复制并节省 GPU 内存,我们可以将模型参数、梯度和优化器状态分片到所有工作者中,每个工作者只管理一个分片。这种技术是由微软开发的 ZeRO-3 方法推广的。PyTorch 原生实现此方法的是 FullyShardedDataParallel (FSDP) API,作为 PyTorch 1.12 的 beta 功能发布。在模块的前向和反向传播过程中,FSDP 根据需要将模型参数解分片以进行计算(使用 all-gather),并在计算后重新分片。它使用 reduce-scatter 集体操作来同步梯度,以确保分片梯度全局平均。以下详细说明了包装在 FSDP 中的模型的前向和反向传播流程:
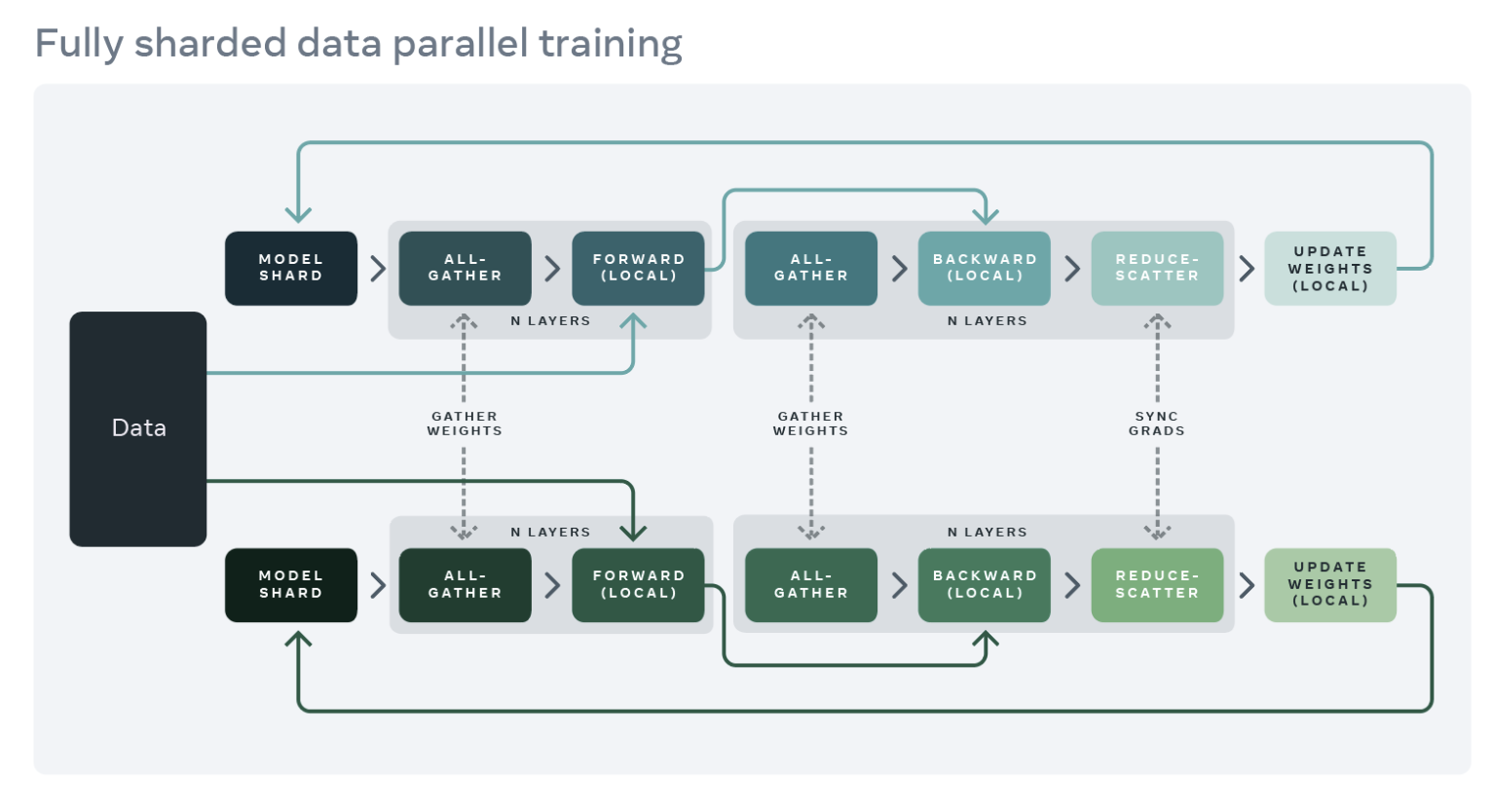
来源:https://engineering.fb.com/2021/07/15/open-source/fsdp/
要使用 FSDP,模型的子模块需要用 API 包装以控制特定子模块何时分片或解分片。FSDP 提供了一个自动包装 API(请参阅 auto_wrap_policy 参数),可以直接使用,以及几个包装策略和编写自定义策略的能力。
以下示例演示了将 FLAVA 模型与 FSDP 包装。我们指定自动包装策略为 transformer_auto_wrap_policy 。这将分别将单个 Transformer 层( TransformerEncoderLayer )、图像 Transformer( ImageTransformer )、文本编码器( BERTTextEncoder )和多模态编码器( FLAVATransformerWithoutEmbeddings )包装为单独的 FSDP 单元。这使用递归包装方法以实现高效的内存管理。例如,在单个 Transformer 层的正向或反向传播完成后,其参数将被丢弃,从而释放内存,减少峰值内存使用。
FSDP 还提供了一些可配置的选项来调整应用程序的性能。例如,在我们的用例中,我们展示了新 limit_all_gathers 标志的使用,该标志可以防止过早地收集所有模型参数,从而减轻应用程序的内存压力。我们鼓励用户尝试使用此标志,这可能会提高具有高活跃内存使用率的应用程序的性能。
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)
激活检查点
如上所述,中间激活、模型参数、梯度和优化器状态共同影响着整体 GPU 内存使用。FSDP 可以通过后三者减少内存消耗,但不会减少激活所消耗的内存。激活所使用的内存会随着批大小或隐藏层数的增加而增加。激活检查点是一种技术,通过在反向传播过程中重新计算激活而不是将它们保存在特定检查点模块的内存中来减少这种内存使用。例如,我们对 2.7B 参数模型应用激活检查点后,观察到正向传播后的峰值活跃内存减少了约 4 倍。
PyTorch 提供了一个基于激活检查点的 API 包装器。特别是, checkpoint_wrapper 允许用户将单个模块包装在检查点中,而 apply_activation_checkpointing 允许用户指定一个策略来包装具有检查点的整体模块中的模块。这两个 API 可以应用于大多数模型,因为它们不需要对模型定义代码进行任何修改。然而,如果需要更细粒度的检查点段控制,例如在模块中检查特定函数,则可以利用功能 torch.utils.checkpoint API,尽管这需要修改模型代码。以下是将激活检查点包装器应用于单个 FLAVA 转换器层(标记为 TransformerEncoderLayer )的示例。有关激活检查点的详细描述,请参阅 PyTorch 文档中的说明。
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
将激活检查点包装 FLAVA 转换器层和将整体模型包装在 FSDP 中(如上所示)一起使用,我们能够将 FLAVA 扩展到 10B 参数。
实验
我们对上一节中不同优化对系统性能的影响进行了实证研究。在所有实验中,我们使用单个节点上的 8 个 A100 40GB GPU,并运行了 1000 次预训练。所有运行都使用了 PyTorch 的自动混合精度和 bfloat16 数据类型。还启用了 TensorFloat32 格式,以改善 A100 上的 matmul 性能。我们将吞吐量定义为每秒处理的平均项目数(文本或图像)(在测量吞吐量时忽略前 100 次迭代,以考虑预热)。我们将训练留给收敛,并将其对下游任务指标的影响作为一个未来研究的领域。
图 1 显示了每种模型配置和优化的吞吐量,包括本地批大小为 8,以及 1 个节点上可能的最大批大小。对于优化中某个模型变体的数据点缺失表示该模型无法在单个节点上训练。
图 2 显示了每种优化中每个工作者的最大可能批大小。我们观察到以下几点:
- 模型规模扩展:DDP 只能将 350M 和 900M 模型适配到单个节点上。由于内存节省,我们能够训练比 DDP 大 3 倍左右的模型(例如 1.8B 和 2.7B 版本)。将激活检查点(AC)与 FSDP 结合使用,可以训练更大的模型,大约比 DDP 大 10 倍(例如 4.8B 和 10B 版本)。
- 吞吐量:
- 对于较小的模型规模,在批大小为 8 的情况下,DDP 的吞吐量略高于或等于 FSDP,这可以归因于 FSDP 所需的额外通信。当 FSDP 与 AC 结合使用时,吞吐量最低。这是因为 AC 在反向传播期间重新运行检查点的前向传递,以内存节省为代价进行额外的计算。然而,在 2.7B 模型的情况下,FSDP + AC 的实际吞吐量比单独使用 FSDP 更高。这是因为 2.7B 模型在批大小为 8 时,即使接近内存限制,也会触发 CUDA malloc 重试,这往往会减慢训练速度。AC 有助于减轻内存压力,从而避免重试。
- 对于 DDP 和 FSDP+AC,每个模型的吞吐量随着批量大小的增加而增加。对于单独的 FSDP 来说,这在较小的变体中是正确的。然而,对于 1.8B 和 2.7B 参数模型,我们观察到随着批量大小的增加,吞吐量会下降。这可能是由于 PyTorch 的 CUDA 内存管理在内存限制下不得不重试 cudaMalloc 调用和/或运行昂贵的碎片整理步骤以找到处理工作负载内存需求的空闲内存块,这可能导致训练速度减慢。
- 对于只能使用 FSDP(1.8B、2.7B、4.8B)训练的大型模型,实现最高吞吐量的设置是使用 FSDP+AC 扩展到最大批大小。对于 10B,我们观察到较小批大小和最大批大小的吞吐量几乎相等。这可能看起来有些反直觉,因为 AC 会导致计算增加,而将批大小最大化可能会因为接近 CUDA 内存限制而导致昂贵的碎片整理操作。然而,对于这些大型模型,批大小的增加足以抵消这种开销。
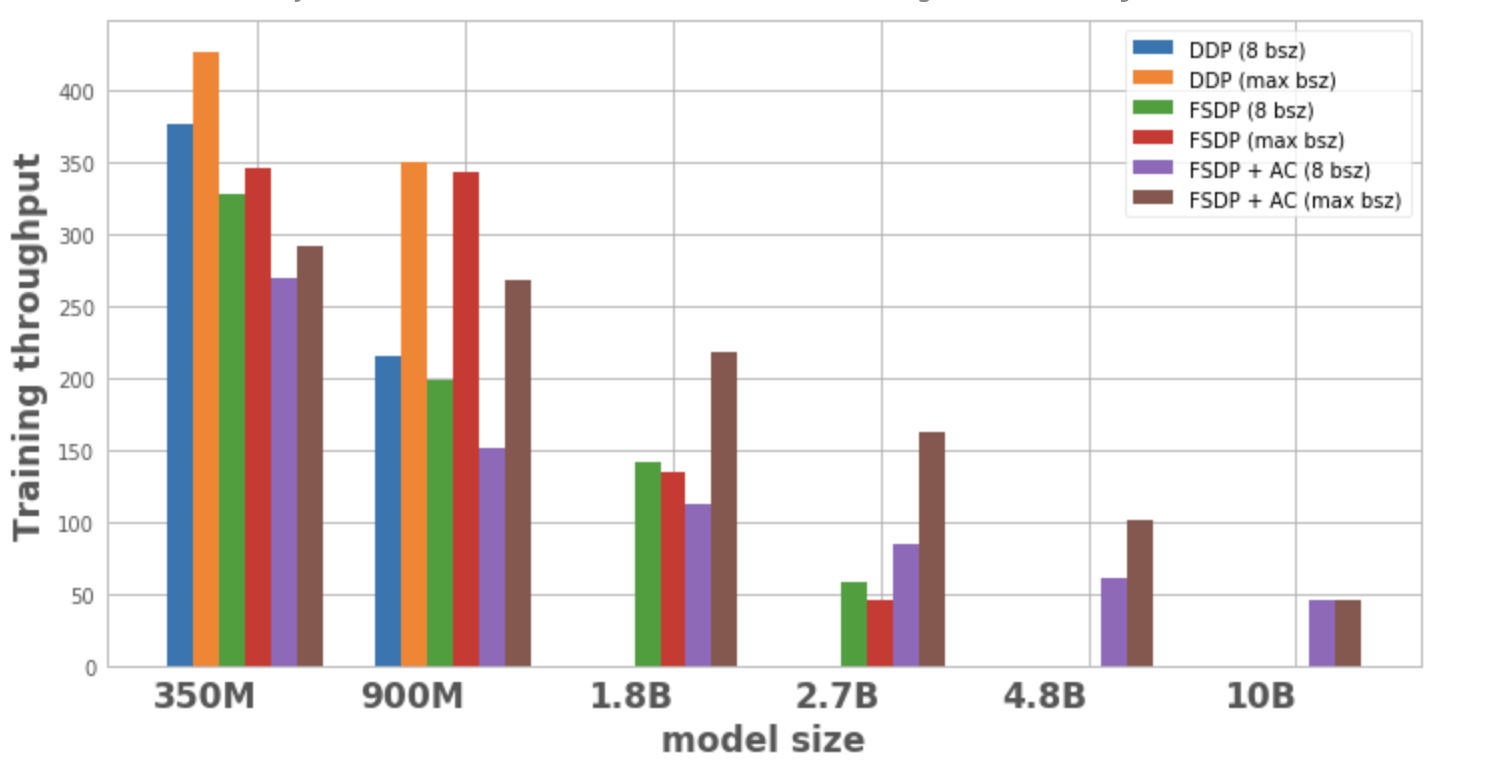
图 1:不同配置下的训练吞吐量
- 批处理大小:与 DDP 相比,FSDP 单独使用可以启用略高的批处理大小。使用 FSDP + AC 可以使批处理大小比 DDP 提高约 3 倍(对于 350M 参数模型)和约 5.5 倍(对于 900M 参数模型)。即使是 10B 参数模型,最大批处理大小也能达到约 20,这相当不错。这实际上使得使用更少的 GPU 就能实现更大的全局批处理大小,这对于对比学习任务特别有用。
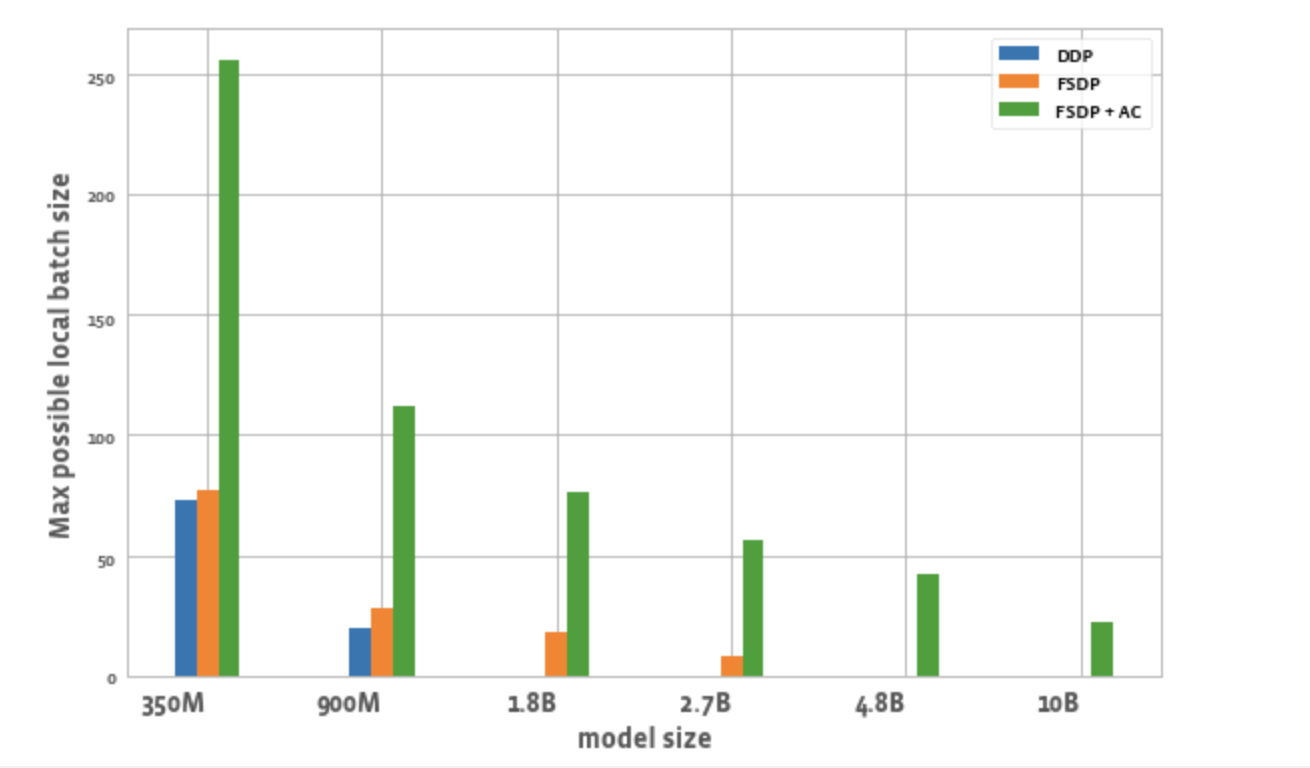
图 2:不同配置下的最大本地批处理大小
结论
随着世界向多模态基础模型发展,模型参数的扩展和高效训练正成为关注的焦点。PyTorch 生态系统旨在通过为研究社区提供不同的工具来加速该领域的创新,这些工具既适用于训练也适用于扩展多模态模型。通过 FLAVA,我们展示了如何扩展模型以实现多模态理解。未来,我们计划添加对其他类型模型的支持,例如多模态生成模型,并展示它们的扩展因子。我们还希望自动化许多这些扩展和内存节省技术(如分片和激活检查点),以减少用户实验以实现所需规模和最大训练吞吐量的需求。