声音-视觉语音识别(AV-ASR,或 AVSR)是从音频和视觉流中转录文本的任务,由于其抗噪声能力而近年来吸引了大量研究关注。迄今为止的大多数工作都集中在开发非流式 AV-ASR 模型;对流式 AV-ASR 的研究非常有限。
我们开发了一个基于 TorchAudio 的紧凑型实时语音识别系统,TorchAudio 是一个用于音频和信号处理的 PyTorch 库。它可以在不访问云的情况下,在笔记本电脑上本地运行,并具有高精度。今天,我们正在以宽松的开源许可(BSD-2-Clause 许可)发布实时 AV-ASR 配方,以促进音频-视觉模型在语音识别方面的进一步研究。
这项工作是我们 AV-ASR 研究方法的一部分。该方法的一个有希望的方面是它能够自动标注大规模的视听数据集,这有助于训练更准确、更鲁棒的语音识别系统。此外,这项技术具有在智能设备上运行的潜力,因为它实现了这些设备推理所需的延迟和内存效率。
未来,语音识别系统有望在众多领域发挥作用。AV-ASR 的主要应用之一是提高在嘈杂环境中的 ASR 性能。由于视觉流不受声学噪声的影响,将其整合到视听语音识别模型中可以补偿 ASR 模型性能下降。我们的 AV-ASR 系统具有服务于语音识别以外的多种目的的潜力,例如文本摘要、翻译甚至文本到语音转换。此外,在特定场景下,仅使用 VSR 可能很有用,例如不允许说话的会议,以及需要公共对话隐私的情况下。
AV-ASR
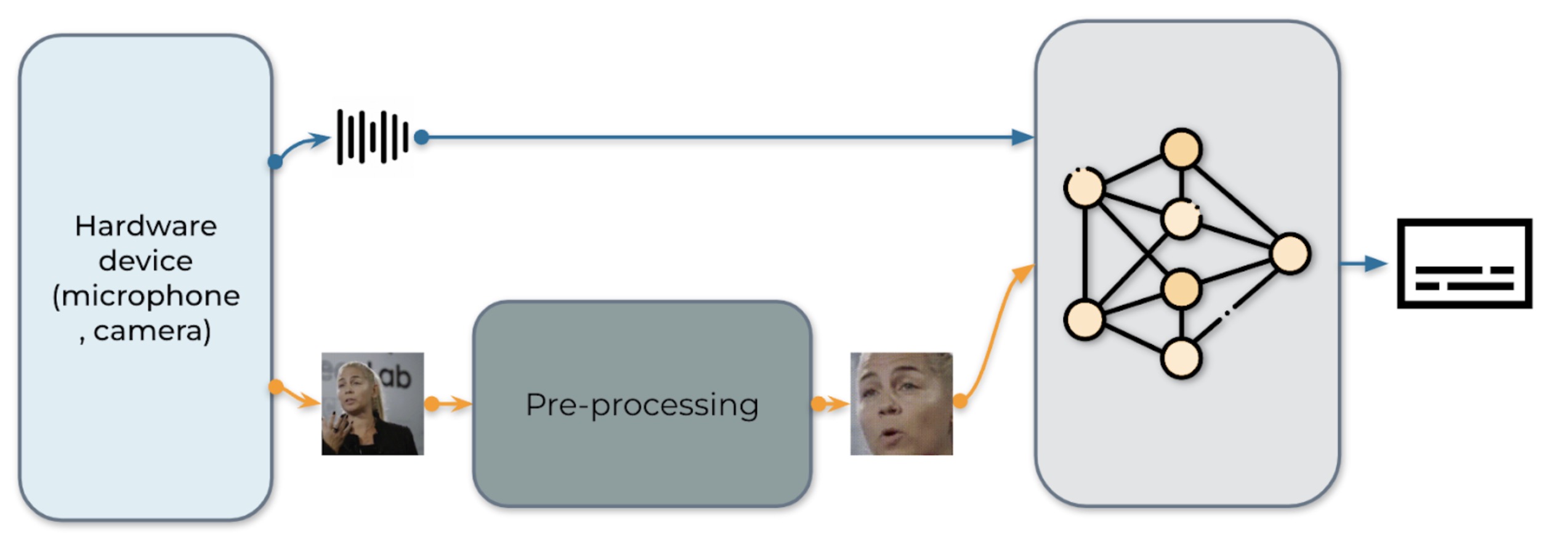
图 1:视听语音识别系统的流程
我们在图 1 中展示了我们的实时 AV-ASR 系统。它由三个组件组成,即数据收集模块、预处理模块和端到端模型。数据收集模块包括硬件设备,如麦克风和摄像头。其作用是从现实世界中收集信息。一旦收集到信息,预处理模块就会定位并裁剪人脸。接下来,我们将原始音频流和预处理后的视频流输入到我们的端到端模型中进行推理。
数据收集
我们使用 torchaudio.io.StreamReader 从流媒体设备输入捕获音频/视频,例如笔记本电脑上的麦克风和摄像头。一旦收集到原始视频和音频流,预处理模块就会定位并裁剪人脸。需要注意的是,在流媒体过程中,数据会立即被删除。
预处理
在将原始流输入我们的模型之前,每个视频序列都必须经过特定的预处理程序。这包括三个关键步骤。第一步是进行人脸检测。随后,每个单独的帧都会与一个参考帧对齐,通常称为平均人脸,以规范帧之间的旋转和尺寸差异。预处理模块中的最后一步是从对齐的人脸图像中裁剪人脸区域。我们想明确指出,我们的模型输入的是原始音频波形和人脸像素,没有任何进一步的预处理,如人脸解析或关键点检测。预处理程序的示例见表 1。

|

|

|

|
| 0. 原始 | 1. 检测 | 2. 对齐 | 3. 种植 |
表 1:预处理流程。
模型
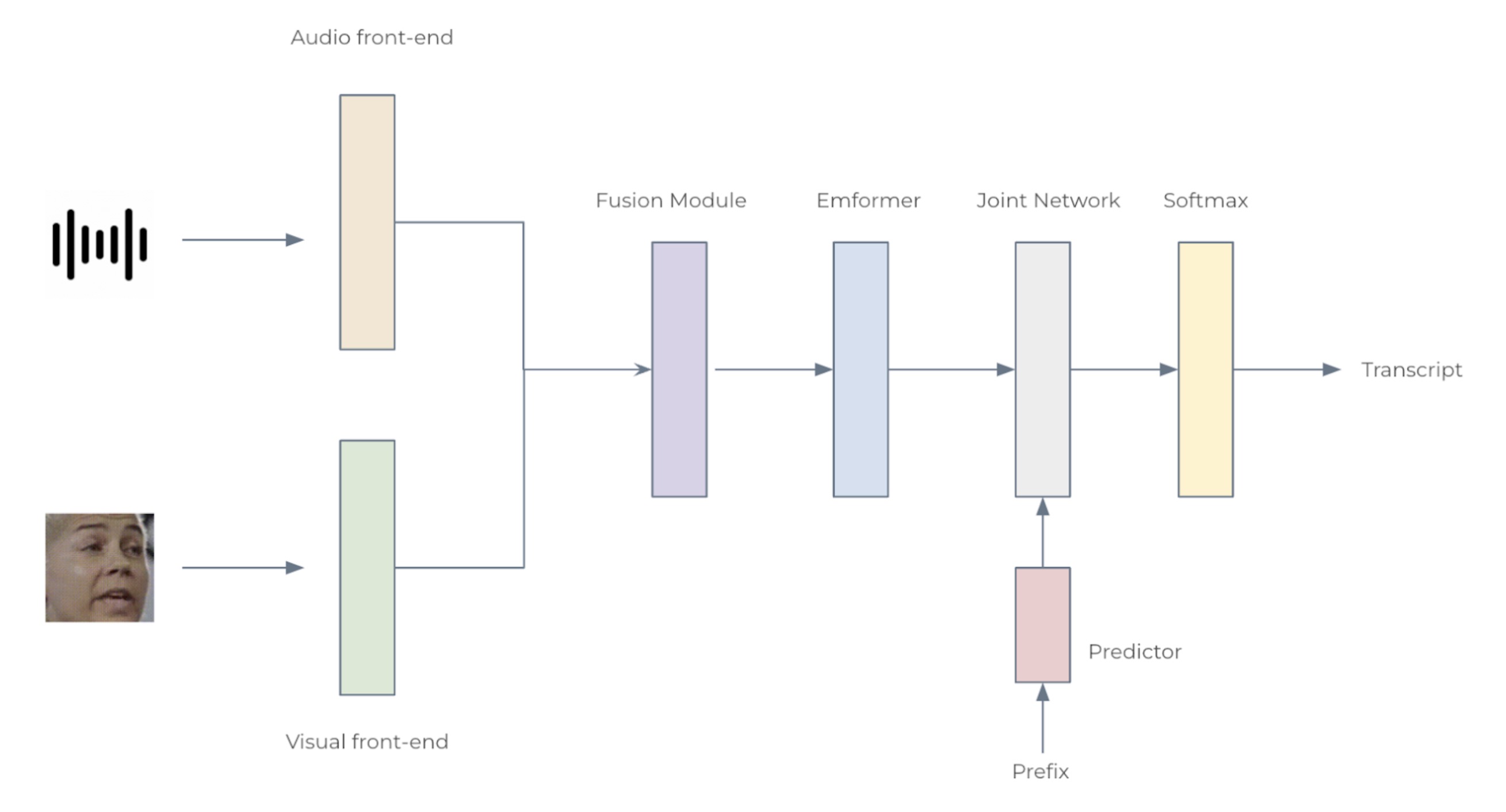
图 2:音频-视觉语音识别系统的架构
我们考虑了两种配置:小型配置包含 12 个 Emformer 块,大型配置包含 28 个,分别有 34.9M 和 383.3M 个参数。每个 AV-ASR 模型由前端编码器、融合模块、Emformer 编码器和转导模型组成。具体来说,我们使用卷积前端从原始音频波形和面部图像中提取特征。这些特征被连接成 1024 维特征,然后通过两层多层感知器和 Emformer 转导模型。整个网络使用 RNN-T 损失进行训练。所提出的 AV-ASR 模型的架构如图 2 所示。
分析
数据集。我们遵循 Auto-AVSR:带有自动标签的音频-视觉语音识别,使用公开可用的音频-视觉数据集进行训练,包括 LRS3、VoxCeleb2 和 AVSpeech。在训练和测试阶段,我们都不使用嘴部 ROI 或面部地标或属性。
与最先进技术的比较。在 LRS3 上的非流式评估结果见表 2。我们的音频-视觉模型算法延迟为 800 毫秒(160ms+1280msx0.5),实现了 1.3%的词错误率(WER),与 AV-HuBERT、RAVEn 和 Auto-AVSR 等最先进的离线模型相当。
| 方法 | 总小时数 | 词错误率(%) |
| ViT3D-CM | 90, 000 | 1.6 |
| AV-HuBERT | 1, 759 | 1.4 |
| RAVEn | 1, 759 | 1.4 |
| AutoAVSR | 3, 448 | 0.9 |
| Ours | 3, 068 | 1.3 |
表格 2:LRS3 数据集上音频-视觉模型的非流式评估结果。
噪声实验。在训练过程中,随机向音频波形注入 16 种不同的噪声类型,包括来自 Demand 数据库的 13 种类型,‘DLIVING’,‘DKITCHEN’,‘OMEETING’,‘OOFFICE’,‘PCAFETER’,‘PRESTO’,‘PSTATION’,‘STRAFFIC’,‘SPSQUARE’,‘SCAFE’,‘TMETRO’,‘TBUS’,‘TCAR’和两种来自语音命令数据库的噪声类型,白噪声和粉红噪声,以及一种来自 NOISEX-92 数据库的噪声类型,嘈杂噪声。从[干净,7.5dB,2.5dB,-2.5dB,-7.5dB]范围内均匀分布地选择 SNR 水平。当使用嘈杂噪声测试时,ASR 和 AV-ASR 模型的结果显示在表格 3 中。随着噪声水平的增加,我们的音频-视觉模型相对于我们的音频模型的优势逐渐增长,表明结合视觉数据可以提高噪声鲁棒性。
| 类型 | ∞ | 10dB | 5 分贝 | 0 分贝 | -5 分贝 | -10 分贝 |
| A | 1.6 | 1.8 | 3.2 | 10.9 | 27.9 | 55.5 |
| A+V | 1.6 | 1.7 | 2.1 | 6.2 | 11.7 | 27.6 |
表 3:在 0.80 秒延迟约束下,针对我们的仅音频(A)和视听(A+V)模型在 LRS3 数据集上的流式评估 WER(%)结果,各种信噪比。
实时因子。实时因子(RTF)是衡量系统高效处理实时任务能力的重要指标。小于 1 的 RTF 值表示系统满足实时要求。我们使用搭载英特尔® 酷睿™ i7-12700 CPU、主频 2.70 GHz 和 NVIDIA 3070 GeForce RTX 3070 Ti GPU 的笔记本电脑来测量 RTF。据我们所知,这是第一个在 LRS3 基准上报告 RTF 的 AV-ASR 模型。小型模型在 CPU 上实现了 2.6%的 WER 和 0.87 的 RTF(表 4),展示了其在设备端实时推理应用中的潜力。
| Model | 设备 | 流式 WER [%] | RTF |
| 大 | GPU | 1.6 | 0.35 |
| 小 | GPU | 2.6 | 0.33 |
| CPU | 0.87 |
表 4:AV-ASR 模型大小和设备对 WER 和 RTF 的影响。请注意,RTF 的计算包括预处理步骤,其中使用 Ultra-Lightweight Face Detection Slim 320 模型生成人脸边界框。
以下出版物中了解更多关于该系统的信息:
- 石,杨杨,王永强,吴春阳,叶清峰,陈俊,张帆,杜克,和李麦克。 “Emformer:基于高效记忆变换器的低延迟流式语音识别声学模型。” 收录于 2021 年 IEEE 国际声学、语音和信号处理会议(ICASSP),第 6783-6787 页。IEEE,2021 年。
- 马平川,亚历山德罗斯·哈利阿索斯,阿德里安娜·费尔南德斯-洛佩斯,陈红丽,斯塔沃斯·彼得里迪斯,玛雅·帕 antic。 “Auto-AVSR:带有自动标签的音频-视觉语音识别。” 收录于 2023 年 IEEE 国际声学、语音和信号处理会议(ICASSP),第 1-5 页。IEEE,2023 年。