PyTorch Profiler v1.9 已发布!本次新版本的目标(之前的 PyTorch Profiler 版本)是为您提供最新的工具,帮助诊断和修复机器学习性能问题,无论您是在一台或多台机器上工作。目标是针对耗时和/或内存消耗最大的执行步骤,并可视化 GPU 和 CPU 之间的工作负载分布。
下面是即将发布的五个主要功能的总结:
- 分布式训练视图:这有助于您了解分布式训练作业消耗了多少时间和内存。当您将训练模型分割成并行运行的节点时,许多问题都会发生,因为它可能是一个黑盒。整体模型目标是加速模型训练。这个分布式训练视图将帮助您诊断和调试单个节点中的问题。
- 内存视图:此视图可帮助您更好地理解内存使用情况。此工具将帮助您通过显示程序运行过程中的活动内存分配来避免著名的“内存不足”错误。
- GPU 利用率可视化:此工具可帮助您确保 GPU 得到充分利用。
- 云存储支持:Tensorboard 插件现在可以读取来自 Azure Blob 存储、Amazon S3 和 Google Cloud Platform 的配置文件数据。
- 跳转到源代码:此功能允许您可视化堆栈跟踪信息并直接跳转到源代码。这有助于您根据配置文件结果快速优化和迭代代码。
PyTorch 性能分析工具入门
PyTorch 包含一个名为“PyTorch Profiler”的性能分析功能。PyTorch Profiler 教程可在此处找到。
要为您的 PyTorch 代码进行性能分析,您必须:
$ pip install torch-tb-profiler
import torch.profiler as profiler
With profiler.profile(XXXX)
评论:
• 关于 CUDA 和 CPU 性能分析,请参阅下文:
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
• 使用 profiler.record_function(“$NAME”):允许为函数块添加一个装饰器(与名称关联的标签)
• 在 profiler.profile 下,Profile_memory=True 参数允许您分析 CPU 和 GPU 内存占用情况
使用 PyTorch Profiler 可视化 PyTorch 模型性能
分布式训练
深度学习领域的最新进展认为大型数据集和大型模型具有价值,这需要你将模型训练扩展到更多的计算资源。分布式数据并行(DDP)和 NVIDIA 集体通信库(NCCL)是 PyTorch 中广泛采用的加速深度学习训练的范式。
在本版 PyTorch Profiler 中,现在支持使用 NCCL 后端的 DDP。
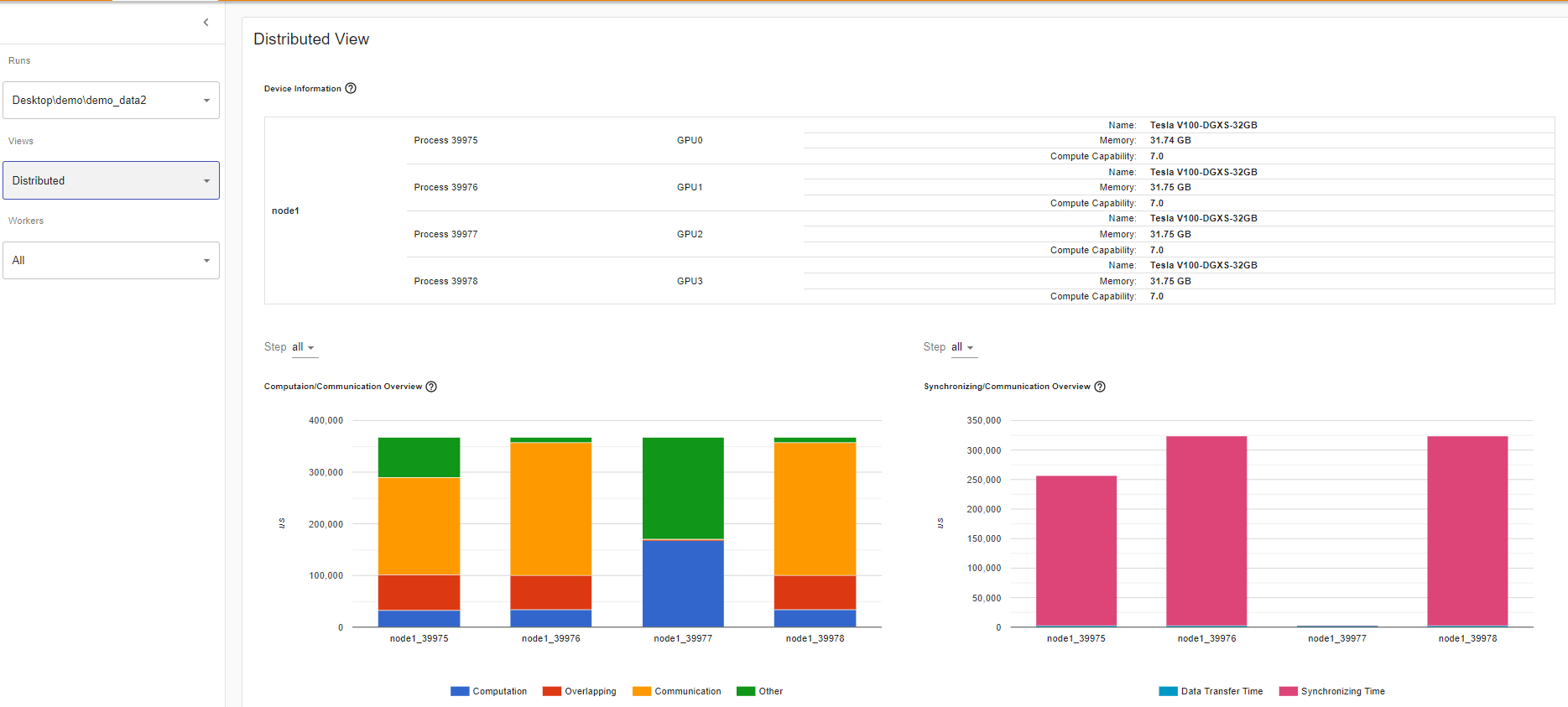
计算与通信概述
在计算/通信概览下的分布式训练视图中,您可以观察到每个工作节点以及工作节点之间[负载均衡器](https://en.wikipedia.org/wiki/Load_balancing_(computing)节点的计算到通信比,该比是按粒度测量的。
场景 1:
如果一个工作节点的计算和重叠时间远大于其他节点,这可能会表明工作负载平衡存在问题或该工作节点是落后者。计算是 GPU 上内核时间总和减去重叠时间。重叠时间是计算期间通过交错通信节省的时间。重叠时间越多,表示计算和通信之间的并行性越好。理想情况下,计算和通信完全重叠。通信是总通信时间减去重叠时间。下面的示例图像显示了该场景在 Tensorboard 上的显示方式。
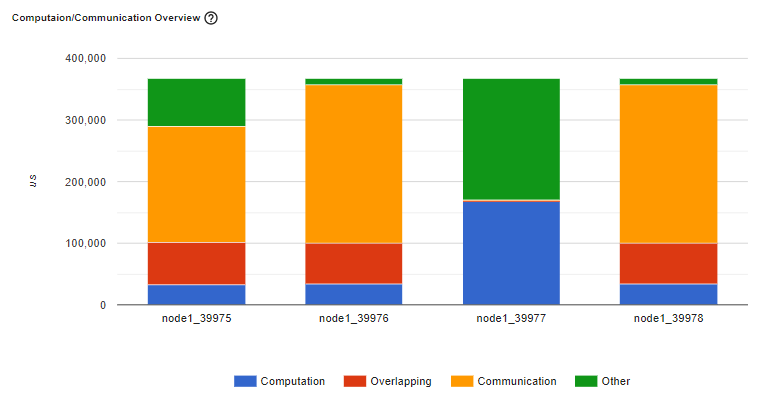
图:落后者示例
场景 2:
如果批次大小较小(即每个工作者的计算量较少)或要传输的数据量较大,计算与通信的比例也可能较小,这在性能分析器中表现为低 GPU 利用率和长时间等待。这种计算/通信视图将允许您诊断代码以减少通信,通过采用梯度累积来减少通信,或者通过增加批次大小来降低通信比例。DDP 通信时间取决于模型大小。批次大小与模型大小无关。因此,增加批次大小可能会使计算时间更长,并使计算与通信比例更大。
同步/通信概述
在同步/通信视图中,您可以观察到通信的效率。这是通过减去步骤时间、计算和通信时间来实现的。同步时间是等待和与其他工作者同步的总通信时间的一部分。同步/通信视图包括初始化、数据加载器、CPU 计算等。从这个视图中可以得出一些见解,例如,总通信中有多少比例真正用于交换数据,以及等待其他工作者数据的空闲时间是多少。
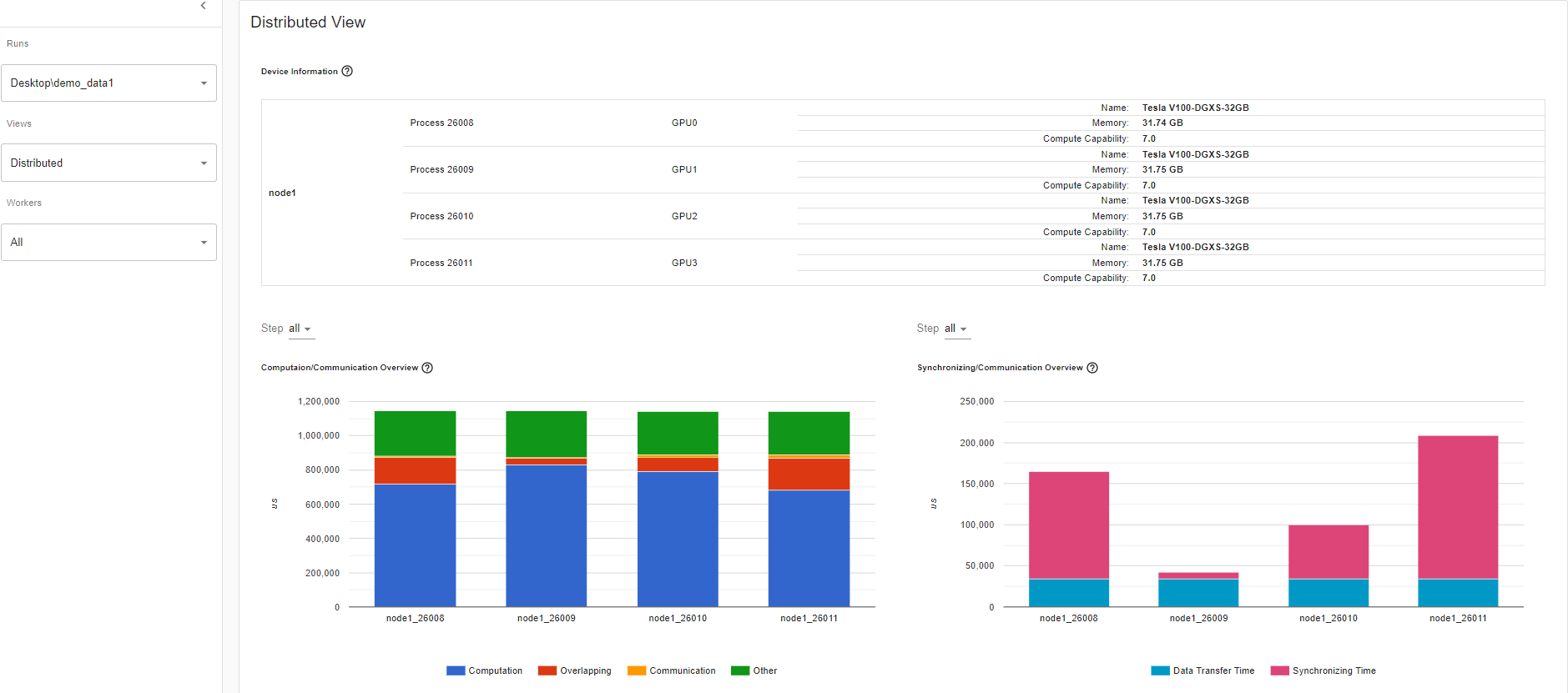
例如,如果存在不均衡的工作负载或拖沓问题,您将能够在同步/通信视图中识别出来。这个视图将显示几个工作者的等待时间比其他人更长。

上面的表格视图允许您查看每个节点中所有通信操作的详细统计信息。这使您可以看到正在调用哪些操作类型,每个操作被调用的次数,每个操作传输的数据大小等。
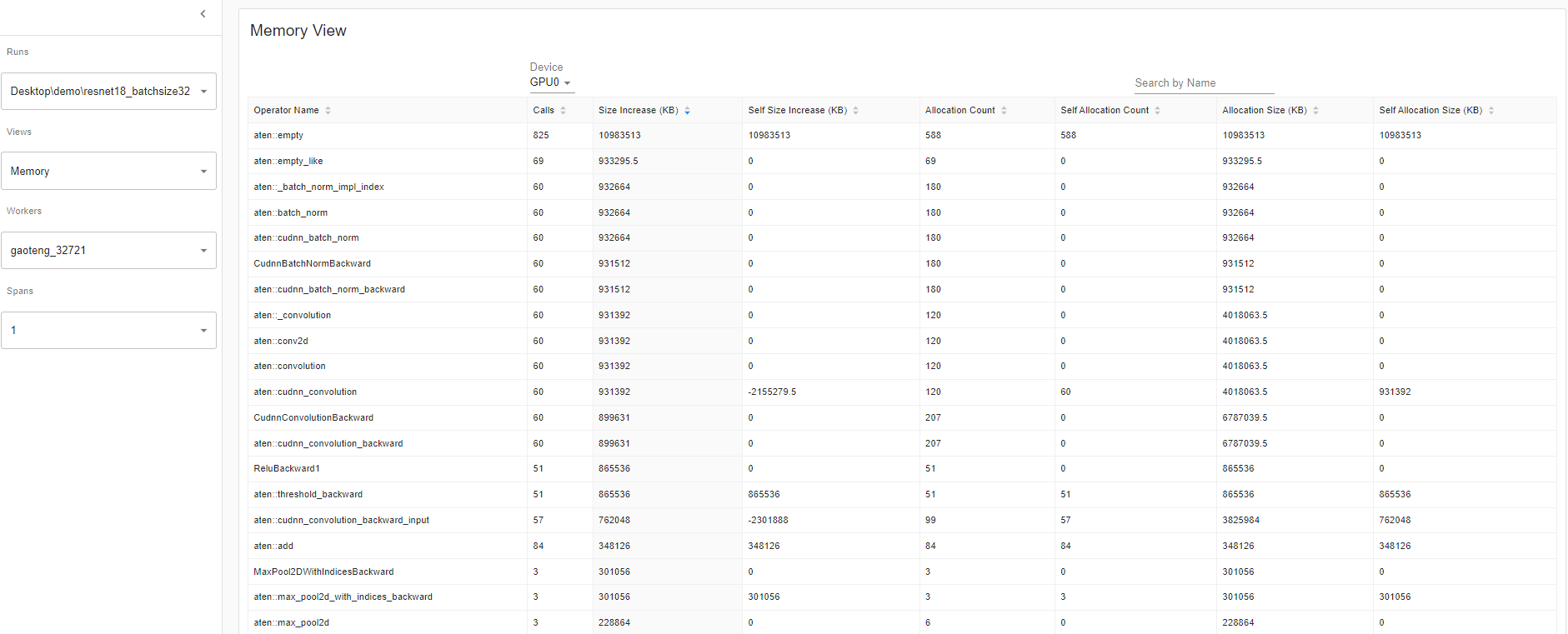
内存视图:
这个内存视图工具可以帮助您了解模型中操作员的硬件资源消耗。在操作员级别理解时间和内存消耗,可以让你解决性能瓶颈,从而让你的模型执行得更快。在有限的 GPU 内存大小下,优化内存使用可以:
- 允许更大的模型,这可能会在末端任务上更好地泛化。
- 允许更大的批量大小。更大的批量大小可以增加训练速度。
分析器记录分析器间隔期间的所有内存分配。选择“设备”将允许您查看每个操作员在 GPU 端或主机端的内存使用情况。您必须启用 profile_memory=True 以生成以下内存数据,如图所示。
With torch.profiler.profile(
Profiler_memory=True # this will take 1 – 2 minutes to complete.
)
重要定义:
• “大小增加”显示所有分配字节数之和减去所有内存释放字节数。
• “分配大小”显示所有分配字节数之和,不考虑内存释放。
• “自身”表示分配的内存不是来自任何子操作符,而是由操作符本身分配。
GPU 指标在时间轴上:
此功能将帮助您调试当一个或多个 GPU 未充分利用时的性能问题。理想情况下,您的程序应具有高 GPU 利用率(目标是 100% GPU 利用率),最小化 CPU 与 GPU 的通信,以及无开销。
概述:概述页面突出显示不同级别(即 GPU 利用率、估计 SM 效率、估计实现占用率)的三个重要 GPU 使用指标的结果。本质上,每个 GPU 都有一堆 SM,每个 SM 都有一堆可以并发执行大量线程的 warps。Warps 执行大量操作,因为数量取决于 GPU。但在高层次上,此 GPU 指标在时间轴上的工具允许您看到整个堆栈,这很有用。
如果 GPU 利用率结果较低,这表明您的模型中可能存在瓶颈。常见原因:
•内核并行度不足(即批量大小低)
•循环调用的小内核。也就是说,启动开销没有得到摊销
•CPU 或 I/O 瓶颈导致 GPU 无法获得足够的工作以保持忙碌
查看概述页面,性能建议部分是您将找到有关如何提高 GPU 利用率的潜在建议的地方。在此示例中,GPU 利用率低,因此性能建议是增加批量大小。根据性能建议,将批量大小从 4 增加到 32,GPU 利用率提高了 60.68%。
GPU 利用率:在分析器中,GPU 引擎执行工作负载时的步骤间隔时间。利用率百分比越高,越好。仅使用 GPU 利用率来诊断性能瓶颈的缺点是它过于高级和粗糙。它无法告诉你有多少个流多处理器正在使用。请注意,虽然这个指标对于检测空闲期很有用,但高值并不表示 GPU 的高效使用,只是表明它在做任何事情。例如,一个单线程持续运行的内核将获得 100%的 GPU 利用率
估计流多处理器效率(Est. SM 效率)是一个更细粒度的指标,它表示在任何时刻有多少比例的 SM 正在使用。此指标报告了至少有一个活动 warp 在 SM 上运行的时间百分比以及那些停滞的(NVIDIA 文档)。估计 SM 效率也有其局限性。例如,每个块只有一个线程的内核无法充分利用每个 SM。SM 效率并不能告诉我们每个 SM 有多忙,只能说明它们正在做任何事情,这可能包括在等待内存加载结果时停滞。为了保持 SM 忙碌,需要足够的就绪 warp,以便在发生停滞时随时运行。
预计实现占用率(Est. Achieved Occupancy)比 Est. SM 效率和高 GPU 利用率更深一层,用于诊断性能问题。预计实现占用率表示每个 SM 上可以同时激活的 warp 数量。拥有足够数量的活动 warp 通常是实现良好吞吐量的关键。与 GPU 利用率和 SM 效率不同,并不是使这个值尽可能高是目标。一般来说,通过提高这个指标到 15%以上可以获得良好的吞吐量提升。但到了某个点,收益将逐渐减少。例如,如果这个值已经达到 30%,进一步的提升将是不确定的。此指标报告了内核执行周期(NVIDIA 文档)内所有 warp 调度器的平均值。预计实现占用率值越大越好。
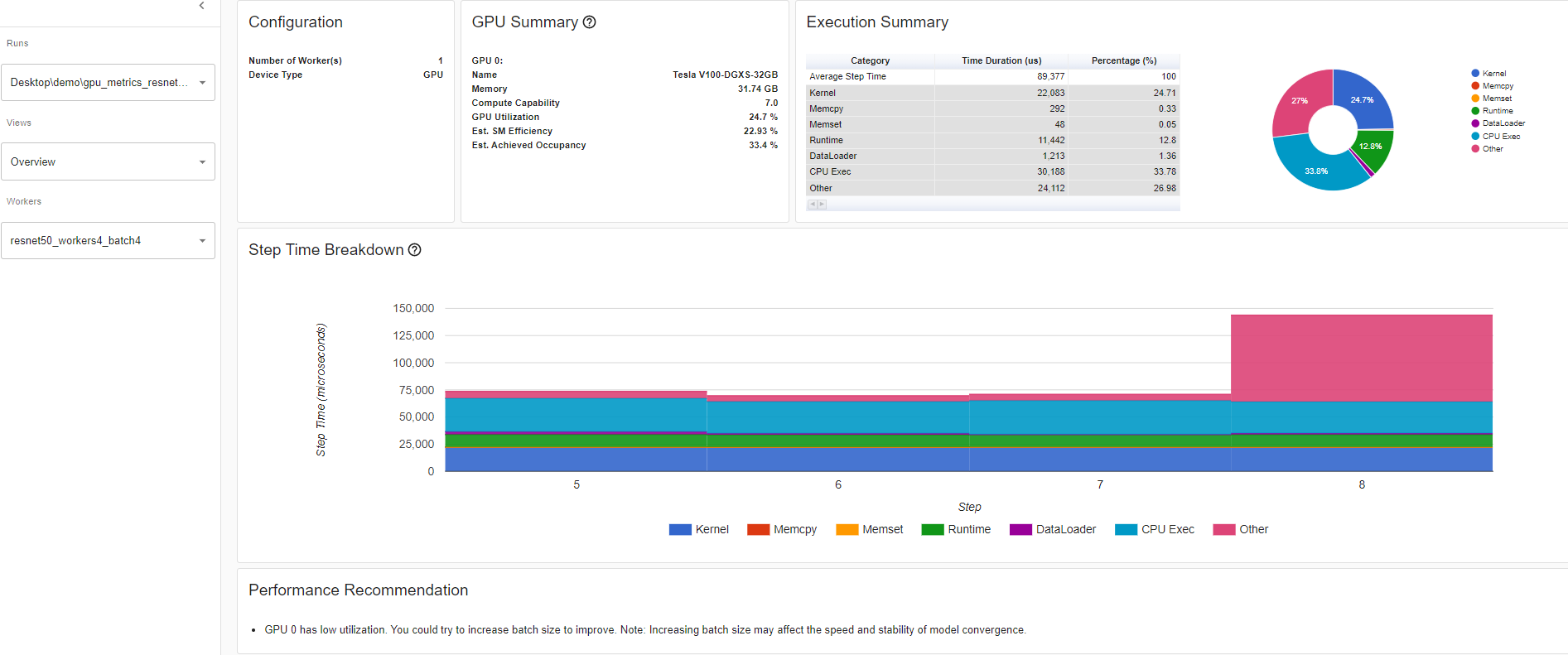
概述详情:Resnet50_batchsize4
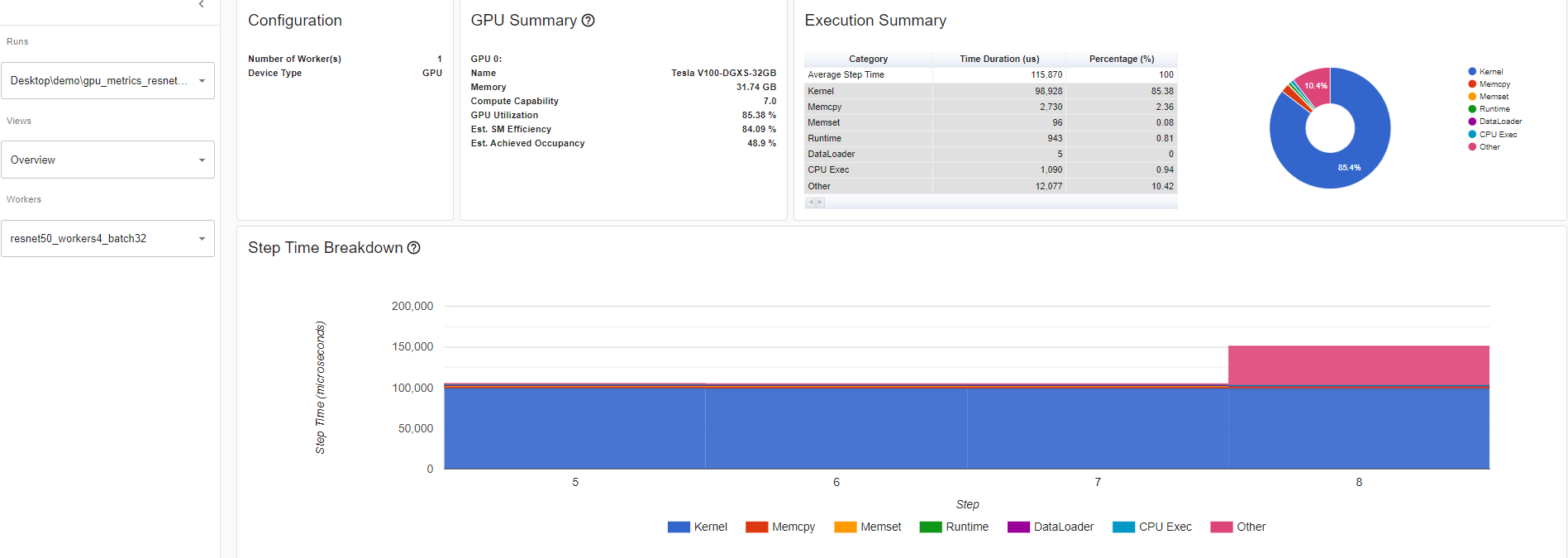
概述详情:Resnet50_batchsize32
内核视图:内核有“每 SM 的块数”和“预计实现占用率”,这是比较模型运行的一个很好的工具。
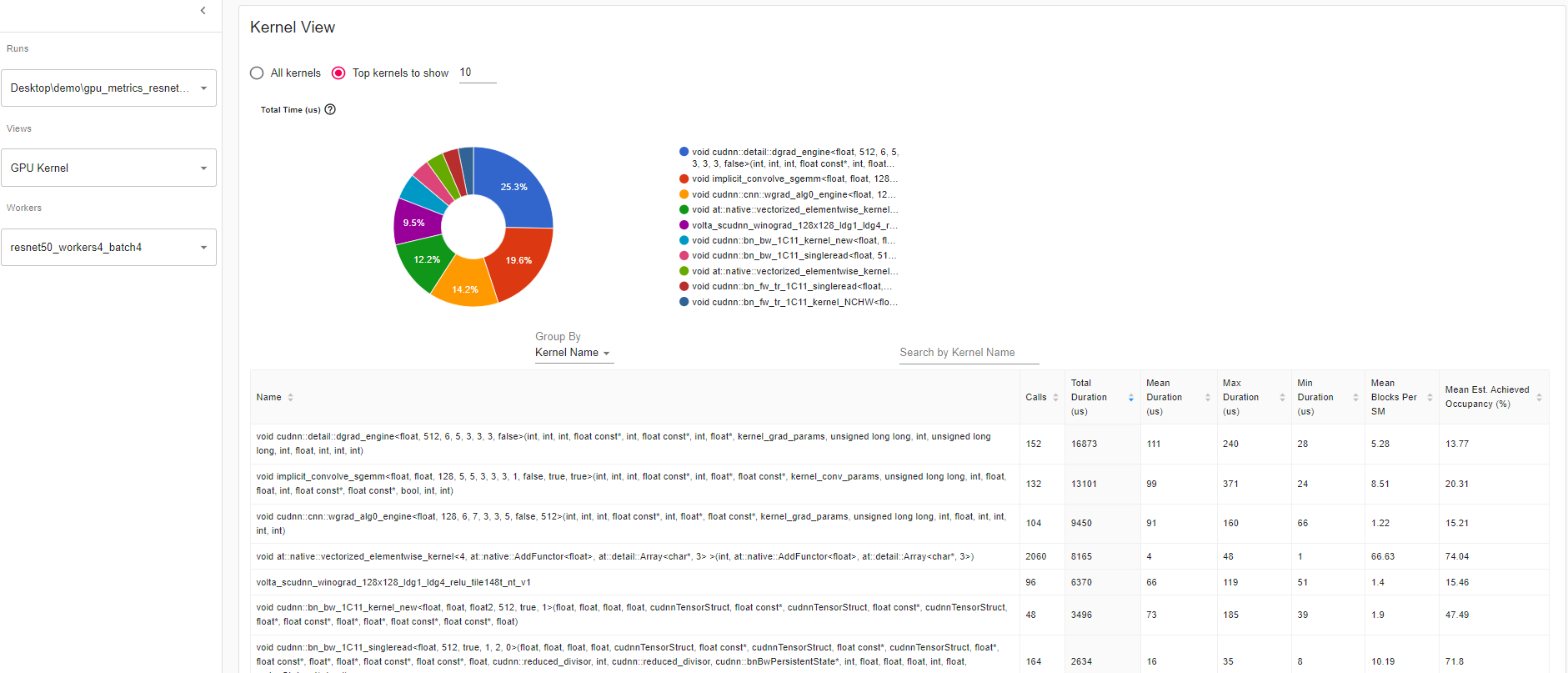
每 SM 平均块数:
每 SM 块数 = 该内核的块数 / 该 GPU 的 SM 数量。如果这个数字小于 1,表示 GPU 多处理器未充分利用。“每 SM 平均块数”是所有该内核名称运行的加权平均值,使用每次运行的持续时间作为权重。
每 SM 平均估计占用率:
估计占用率定义为概述中的内容。“每 SM 平均估计占用率”是所有该内核名称运行的加权平均值,使用每次运行的持续时间作为权重。
跟踪视图 此跟踪视图显示模型中操作器的持续时间以及哪个系统执行了操作。此视图可以帮助您确定高消耗和长时间执行是否由于输入或模型训练引起。目前,此跟踪视图在时间轴上显示 GPU 利用率以及估计的 SM 效率。
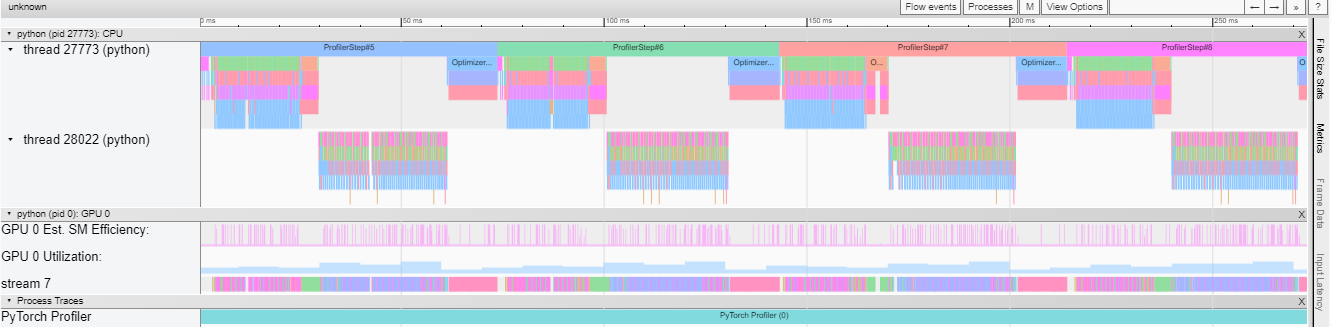
GPU 利用率独立计算,并分为多个 10 毫秒的桶。桶的 GPU 利用率值在 0-100%的时间轴旁边绘制。在上面的示例中,“ProfilerStep5”在线程 28022 繁忙时间内的 GPU 利用率高于“Optimizer.step”之后的利用率。您可以通过放大来调查这是为什么。
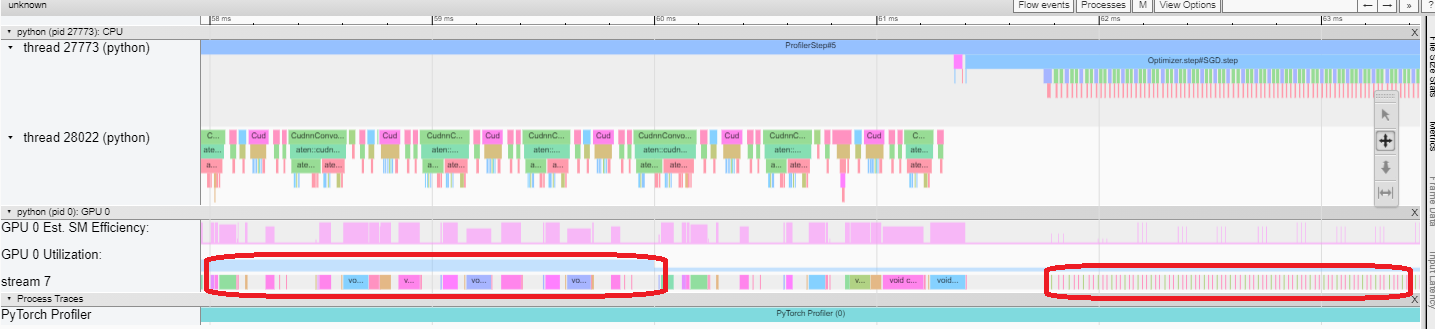
从上面可以看出,前者的内核比后者的内核长。后者的内核执行时间太短,导致 GPU 利用率较低。
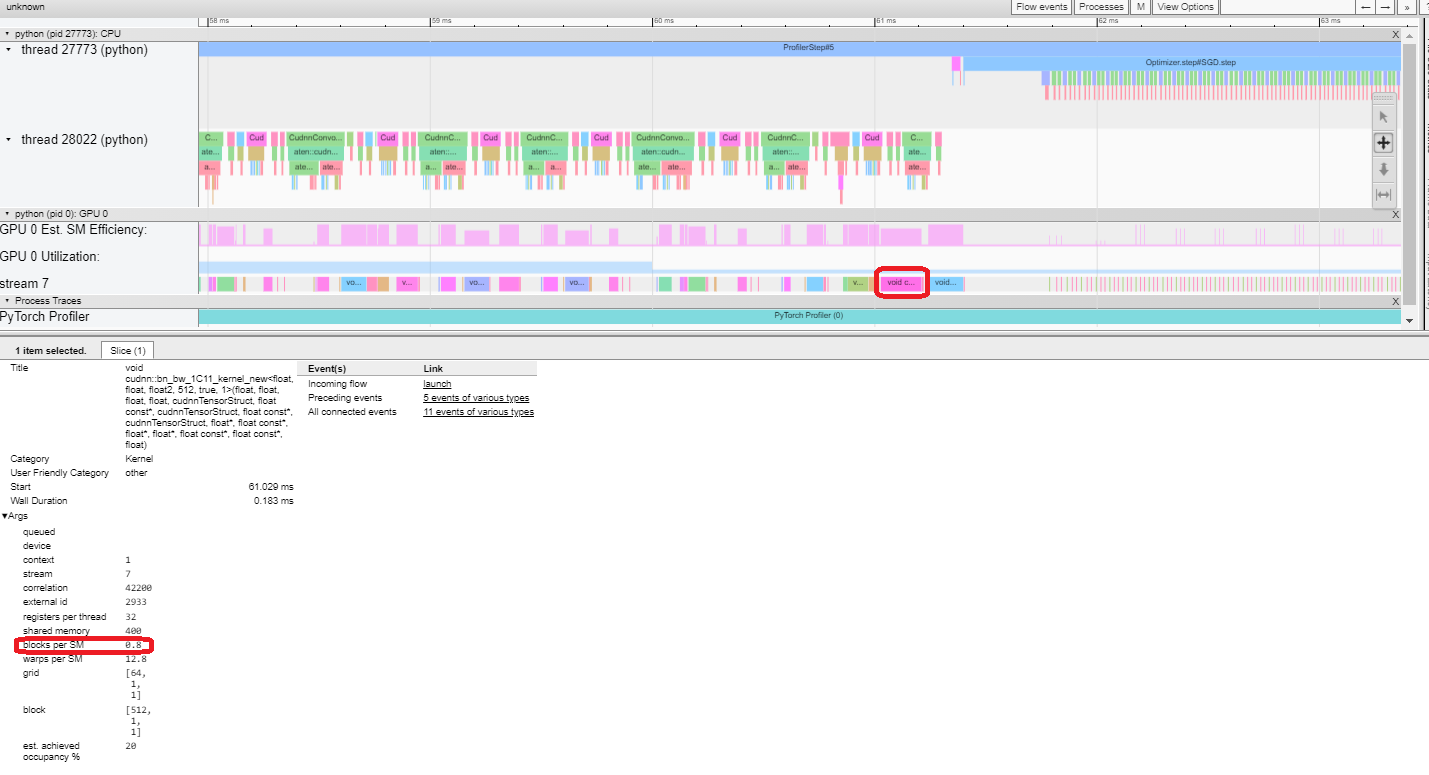
估计的 SM 效率:每个内核都有一个计算出的估计 SM 效率,介于 0-100%之间。例如,下面的内核只有 64 个块,而此 GPU 中的 SM 有 80 个。那么它的“估计 SM 效率”是 64/80,即 0.8。
云存储支持
运行 pip install tensorboard 后,为了通过这些云提供商读取数据,现在可以运行:
torch-tb-profiler[blob]
torch-tb-profiler[gs]
torch-tb-profiler[s3]
pip install torch-tb-profiler[blob] 、 pip install torch-tb-profiler[gs] 或 pip install torch-tb-profiler[S3] 以通过这些云提供商读取数据。更多信息,请参阅此 README。
跳转到源代码:
将 TensorBoard 和 PyTorch Profiler 直接集成到 Visual Studio Code(VS Code)中的巨大好处之一是能够直接从分析堆栈跟踪跳转到源代码(文件和行)。VS Code Python 扩展现在支持 TensorBoard 集成。
仅当 Tensorboard 在 VS Code 中启动时,才能使用“跳转到源代码”功能。如果使用_with_stack=True 进行分析,堆栈跟踪将显示在插件 UI 上。当您从 PyTorch Profiler 中点击堆栈跟踪时,VS Code 将自动打开相应的文件并直接跳转到您感兴趣的代码行进行调试。这允许您根据分析结果和建议快速进行可操作的优化和代码更改。
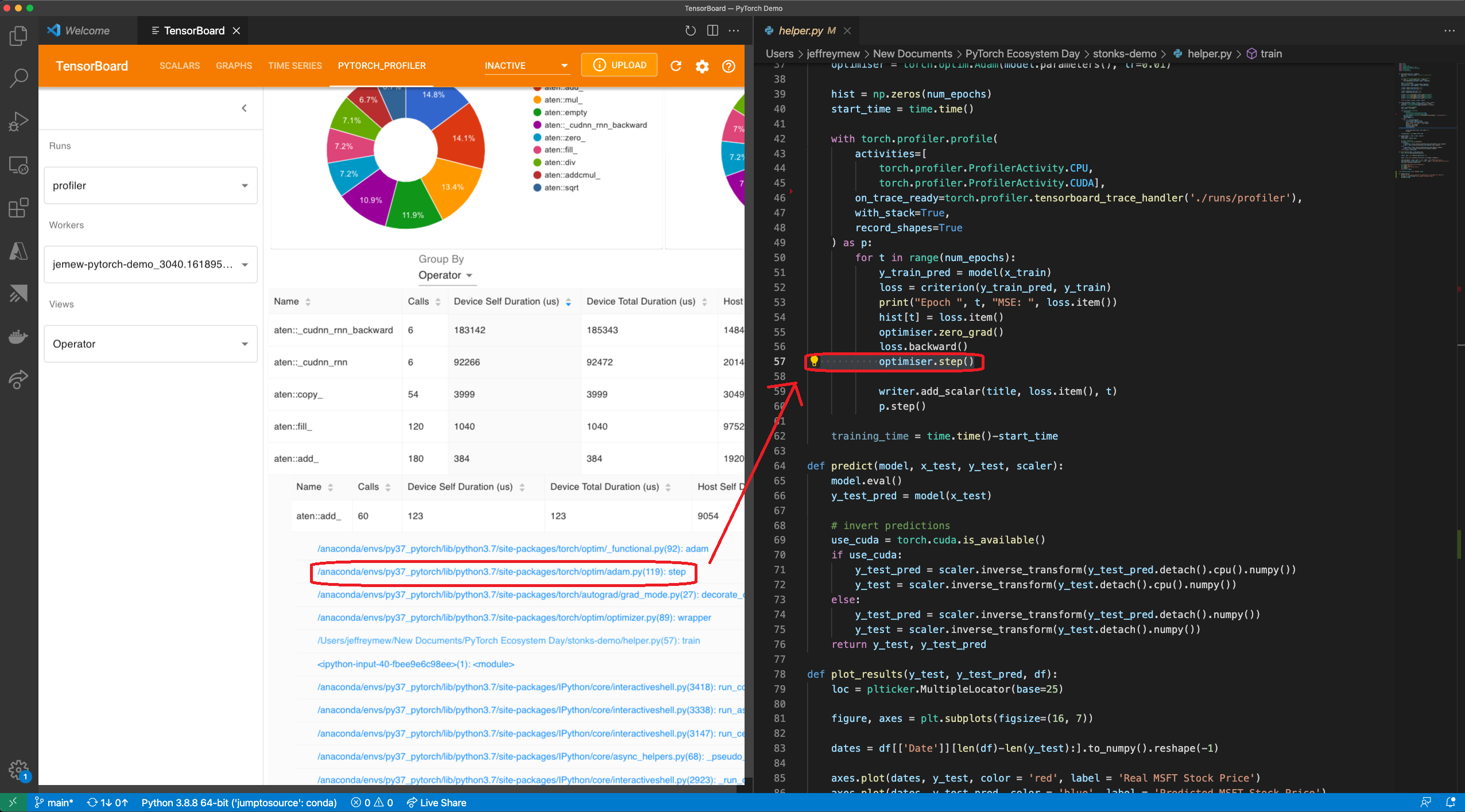
Gify:使用 Visual Studio Code 插件 UI 跳转到源代码
想要了解如何优化批量大小性能,请查看此处的分步教程。PyTorch Profiler 还与 PyTorch Lightning 集成,您只需使用– trainer.profiler=pytorch 标志启动 lightning 训练作业即可生成跟踪。
PyTorch Profiler 的下一步是什么?
您刚刚看到了 PyTorch Profiler 如何帮助优化模型。现在您可以尝试使用 pip install torch-tb-profiler 来优化您的 PyTorch 模型。
期待未来这个教程的高级版本。我们也非常高兴继续为 PyTorch 用户提供最先进的工具来提升机器学习性能。我们很乐意听取您的意见。欢迎在此处提交问题。
想了解 PyTorch Profiler 即将推出的新功能,请关注@PyTorch 在 Twitter 上的动态,并在 pytorch.org 上查看我们的信息。
致谢
作者想感谢以下个人对本作品的贡献。来自 Facebook 方面:Geeta Chauhan、Gisle Dankel、Woo Kim、Sam Farahzad 和 Mark Saroufim。来自微软方面:AI 框架工程师(Teng Gao、Mike Guo 和 Yang Gu)、Guoliang Hua 和 Thuy Nguyen。