去年,IBM 研究院开始与我们合作,将完全分片数据并行(FSDP)技术应用于其大型基础模型。他们对 FSDP 技术感兴趣,因为它是 PyTorch 原生支持,可以用于在 IBM 云上扩展其分布式训练工作。
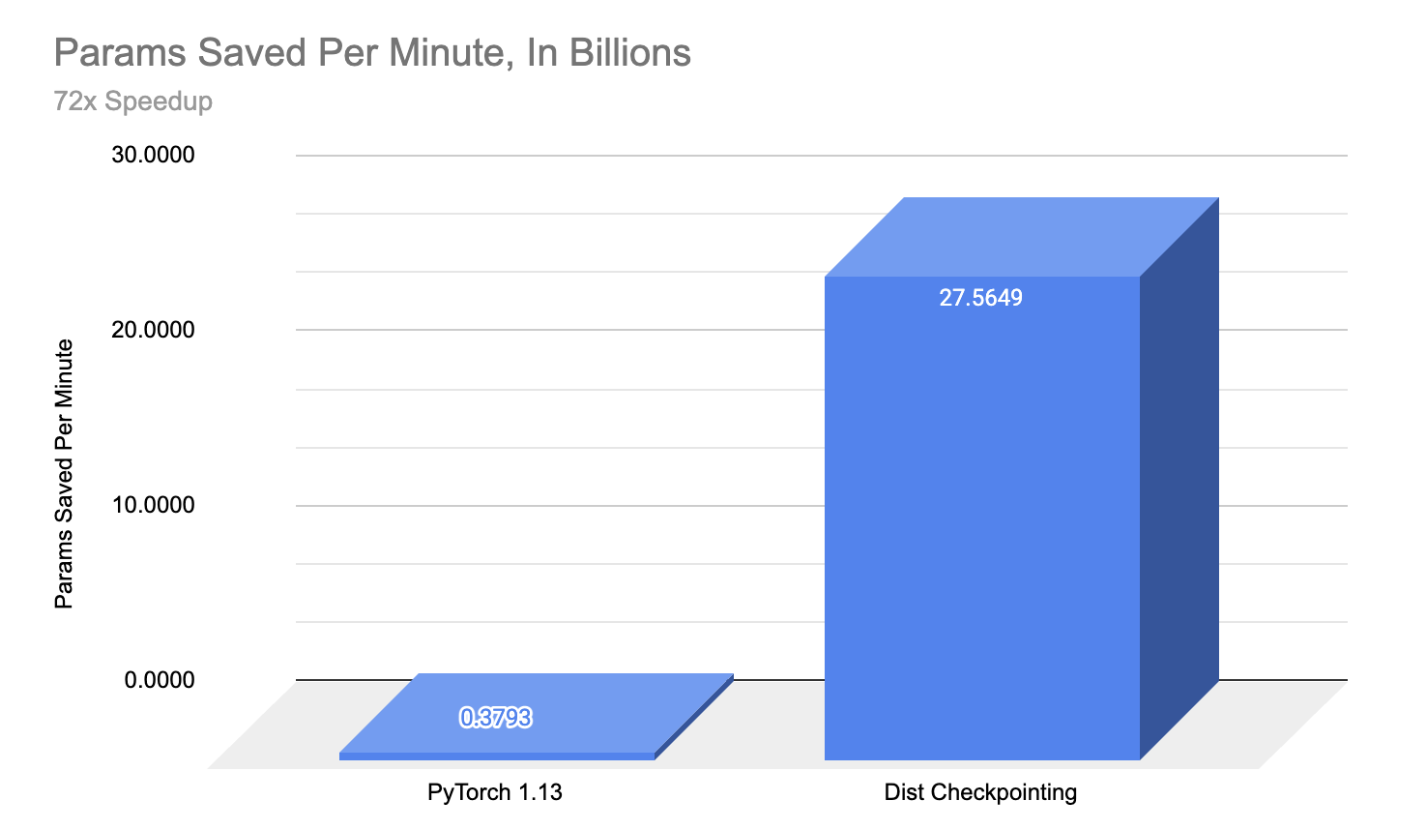
我们很高兴地宣布,与 IBM 合作,我们在大型模型(比原始 PyTorch 1.13 保存速度提高 72 倍)的检查点加速、模型和优化器检查点扩展到 30B 参数以及使用 FSDP + 分布式检查点在 S3 后端实现云优先训练方面取得了显著成果。
什么是分布式检查点?
分布式检查点(Distributed Checkpointing)是 PyTorch 的本地解决方案,用于保存和加载来自多个 rank 的 PyTorch 模型和优化器状态,同时支持在重新加载之间动态更改世界大小。
PyTorch 分布式检查点(Distributed Checkpoint,简称 DCP)API 在 PyTorch 1.13 版本中引入,并在 PyTorch 2.0 版本中作为官方原型功能包含。
分布式检查点与 torch.save()和 torch.load()在几个重要方面有所不同:
- DCP 会为每个检查点生成多个文件,每个 rank 至少有一个文件。
- DCP 在原地操作,意味着模型应首先分配其数据,然后分布式检查点将使用存储。
从 1.13 到 2.0 的一个主要改进是增加了对 FSDP 模型的 sharded_state_dict 支持,这使得对更大尺寸的模型进行检查点保存成为可能,同时增加了负载时重新分片的支持。负载时重新分片允许在一个集群拓扑结构中保存,并在另一个集群中加载。这一特性被高度请求,因为它允许在单个集群上运行训练作业,保存,然后在具有不同世界大小的不同集群上继续。
另一个主要变化是我们将存储层与检查点规划层解耦,并分别实现了两层的接口。随着这一变化,用户现在可以指定他们的 state_dict 在检查点规划阶段应该如何分块或转换。此外,可定制的存储层可以轻松适应不同的后端。
关于分布式检查点包的更多信息,请在此处查看。
在生产中使用 IBM 实现高性能分布式检查点
IBM 在 Think 2023 年大会上宣布推出其 watsonx.ai 平台,该平台用于企业级基础模型的开发和部署。该平台基于混合云,支持多种模态的应用场景,如自然语言处理、时间序列、天气、化学、表格数据和网络安全,模型规模从数亿到数十亿参数不等。模型架构包括视觉 Transformer、多模态 RoBERTa 风格特征提取器,以及类似于 T5、GPT 和 Llama 的大型生成语言模型。
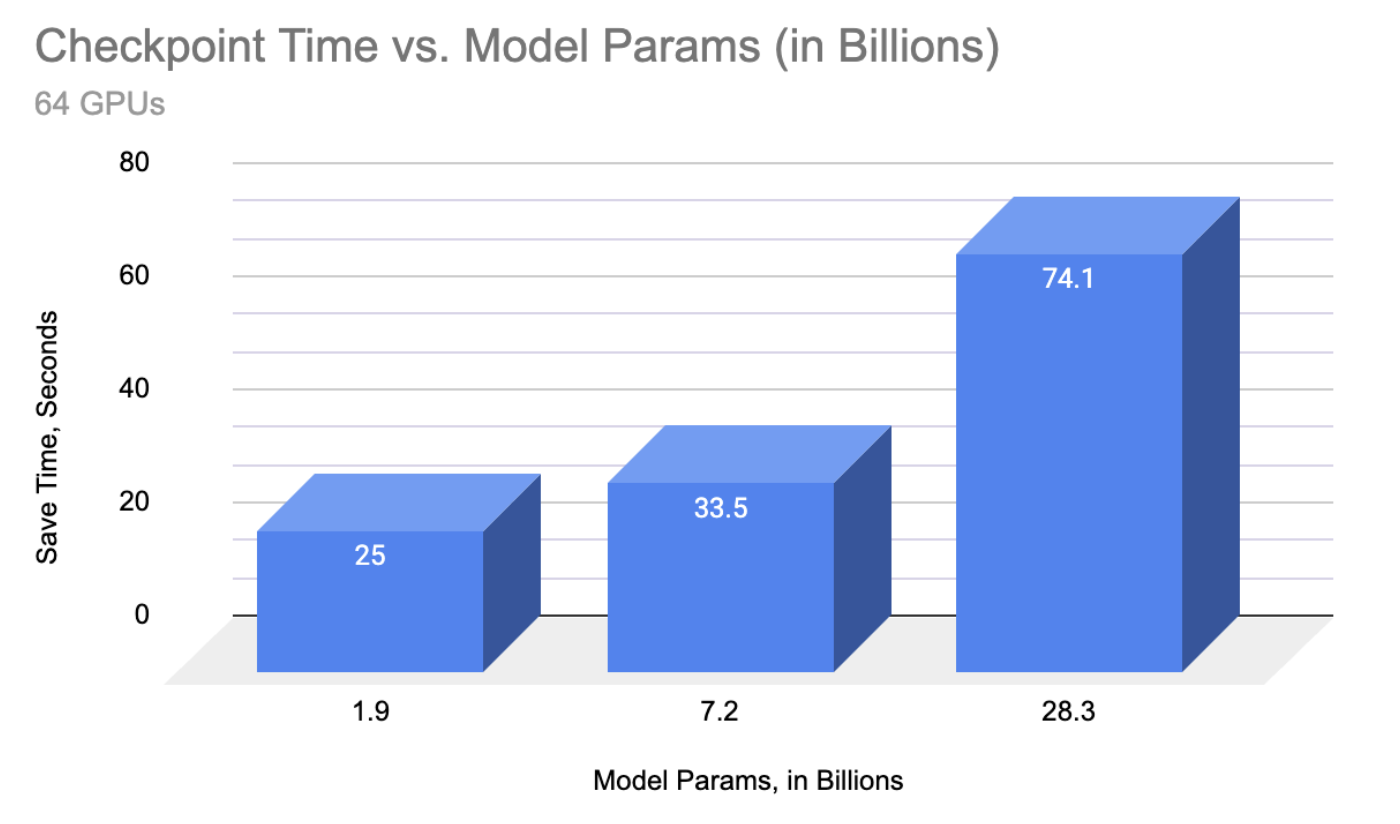
截至今天,IBM 已启用 T5 风格架构高达 11B 参数的检查点,以及解码器架构(GPT 风格)高达 30B。
IBM 帮助我们认识到,这限制了 DCP 从内存和性能角度的扩展能力。根据他们的建议,我们增强了 FileSystemWriter,以每个 rank 生成单个检查点,以减少读写开销。
使用此选项作为新默认值,DCP 现在在检查点保存期间为每个 rank 创建一个单独的文件,然后在加载时读取参数时进行切片。
通过结合 sharded_state_dict 支持和每个 rank 的单文件写入器,分布式检查点能够将检查点保存时间加速超过 72 倍,相较于原始 PyTorch 1.13 的保存速度,并使超过 15B 参数大小的模型能够实现快速检查点,这在之前会直接超时。
“回顾过去,我们看到的加速效果令人震惊,处理这些模型的训练。我们从在 PyTorch 1.13 中花费近半小时来写入单个 11B 检查点,到能够处理一个 30B 参数的模型,包括优化器和数据加载器状态——这意味着是原始数据的八倍多——只需超过 3 分钟。这对我们工作的稳定性和效率产生了巨大的影响,因为我们扩大到数百个 GPU 进行训练。” ——戴维斯·沃特海默,IBM 研究
IBM 的采用也帮助我们验证和改进了我们的解决方案,在真实世界的大规模训练环境中。例如,IBM 发现 DCP 在单个节点上使用多个 GPU 时表现良好,但在多个节点上使用时出错。
在调查这个问题时,我们意识到我们假设写入 NFS-like 共享文件系统,该系统假设强读后写一致性。具有文件系统 API 的对象存储,如 S3FS,提供最终一致性语义,因此导致在这种设置下的分布式检查点失败。与 IBM 合作,我们发现了这个问题,并通过一行代码的更改进行了修复,并启用了 DCP 的对象存储后端!这种存储方法通常比共享文件系统便宜一个数量级,从而实现了更细粒度的检查点。
寻求合作
如果您有兴趣尝试分布式检查点,请随时联系我们!
如果在尝试时遇到任何问题,您可以在我们的 GitHub 仓库中提交一个 issue。
致谢
没有众多合作者的帮助,这个项目不可能完成。我们想感谢赵艳丽、顾安德鲁、瓦罗汉·瓦玛对 FSDP 的支持。感谢普拉塔姆·达米尼亚、赵军杰、梁旺超对 ShardedTensor 的支持。