与 Linux 相比,PyTorch 在 Windows 上的 CPU 性能较低一直是重大问题。导致这种性能差异的因素有很多。通过我们的调查,我们确定了 Windows 上 CPU 性能不佳的几个原因:Windows 默认 malloc 内存分配器的低效以及 Windows 平台上缺乏 SIMD 向量优化。在本文中,我们展示了 PyTorch 在 Windows 上的 CPU 性能如何从之前的版本中提升,以及截至 PyTorch 2.4.1 的最新状态。
PyTorch 2.1.2 及以后版本的内存分配优化
在 PyTorch 2.1.2 之前的版本中,PyTorch 依赖于操作系统的默认 malloc 函数进行内存分配。与 Linux 平台上的 malloc 实现机制相比,Windows 平台的默认 malloc 内存分配效率较低,导致内存分配时间增加,性能降低。为了解决这个问题,我们将默认的 Windows malloc 替换为 mimalloc,这是微软开发的一个更高效的内存分配器。这个更新包含在 PyTorch 2.1.2 及以后的版本中,显著提高了 PyTorch 在 Windows 上的 CPU 性能,如图 1.1 所示。
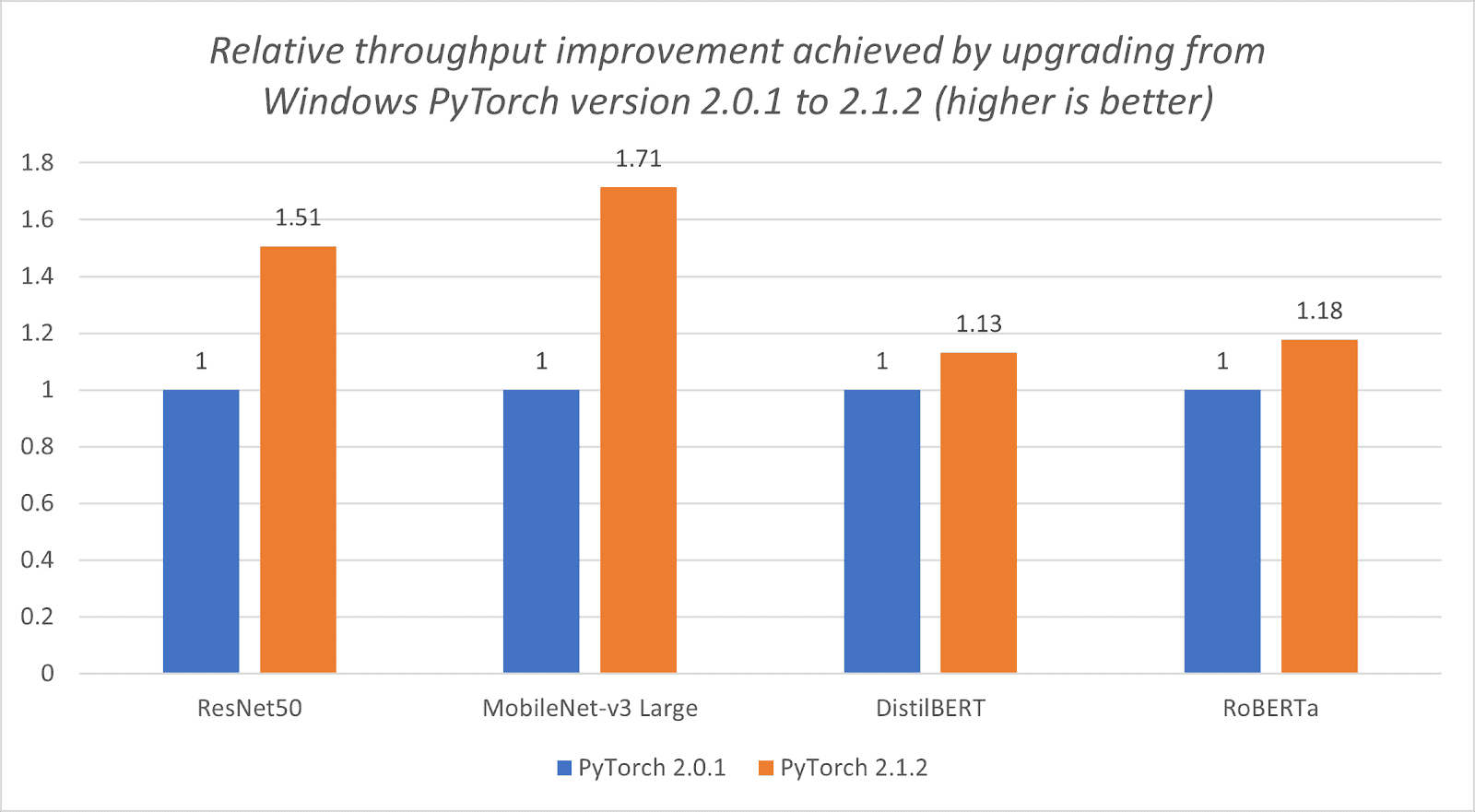
基于 Windows 内存分配优化的 PyTorch CPU 性能提升
图 1.1:从 Windows PyTorch 版本 2.0.1 升级到 2.1.2 所实现的相对吞吐量提升(数值越高越好)。
图表显示,随着 PyTorch 2.1.2 的发布,Windows 平台上的 CPU 性能得到了显著提升。不同模型的提升程度各不相同,这可以归因于它们执行的操作和相应的内存访问模式的不同。虽然 BERT 模型表现出适度的性能提升,但 ResNet50 和 MobileNet-v3 Large 等模型则受益于更为明显的改进。
在高性能 CPU 上,内存分配成为性能瓶颈。这也是为什么解决这个问题导致了如此显著的性能提升。
如下图表所示,我们可以看到 PyTorch 在 Windows 平台上的 CPU 性能可以得到显著提升。然而,与 Linux 平台相比,仍然存在明显的差距。PyTorch CPU Windows 版本中缺乏向量化优化是造成性能差距的关键因素。
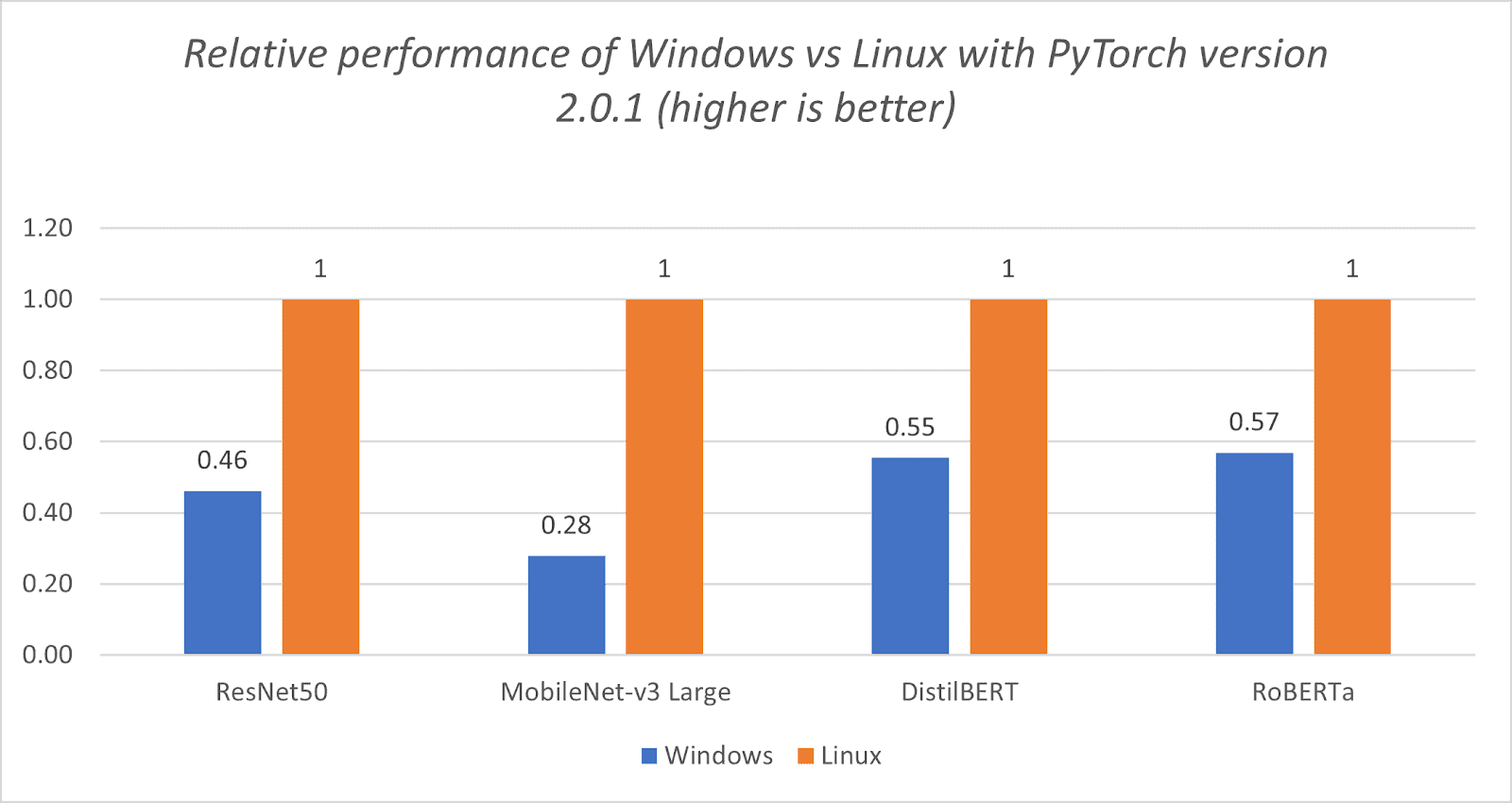
PyTorch 2.0.1 在 Windows 与 Linux 上的性能对比
图 1.2:Windows 与 Linux 在 PyTorch 2.0.1 版本下的相对性能(数值越高越好)。
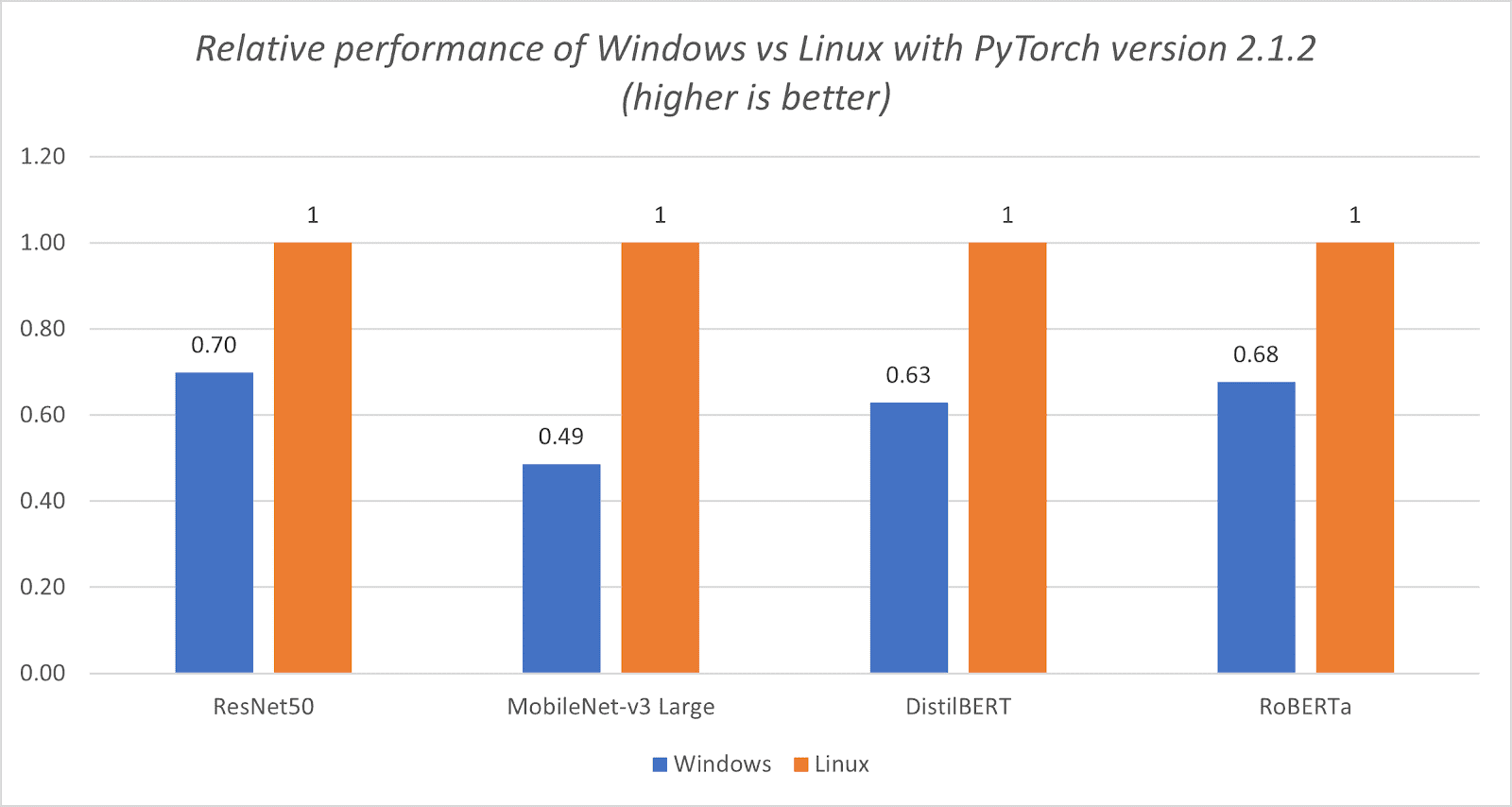
PyTorch 2.1.2 版本下的 Windows 与 Linux 性能对比
图 1.3:Windows 与 Linux 在 PyTorch 2.1.2 版本下的相对性能(数值越高越好)。
PyTorch 2.4.1 及以后版本中的向量化优化
在 PyTorch 2.4.1 之前,PyTorch 的 Windows 构建版本缺少 SIMD 向量化优化功能,而 Linux 构建版本利用这一功能提高了性能。这种差异是由于 SLEEF 库在 Windows 上的集成问题,该库是一个用于评估基本函数的 SIMD 库,向量化了 libm 和 DFT,对于高效的三角函数计算至关重要。通过与 ARM 和 Qualcomm 的工程师合作,这些挑战得到了解决,使得 SIMD 能够集成到 Windows 版本的 PyTorch 中。因此,PyTorch 2.4.1 更新显著提高了 Windows 上 PyTorch 的 CPU 性能,如图 2.1 所示。
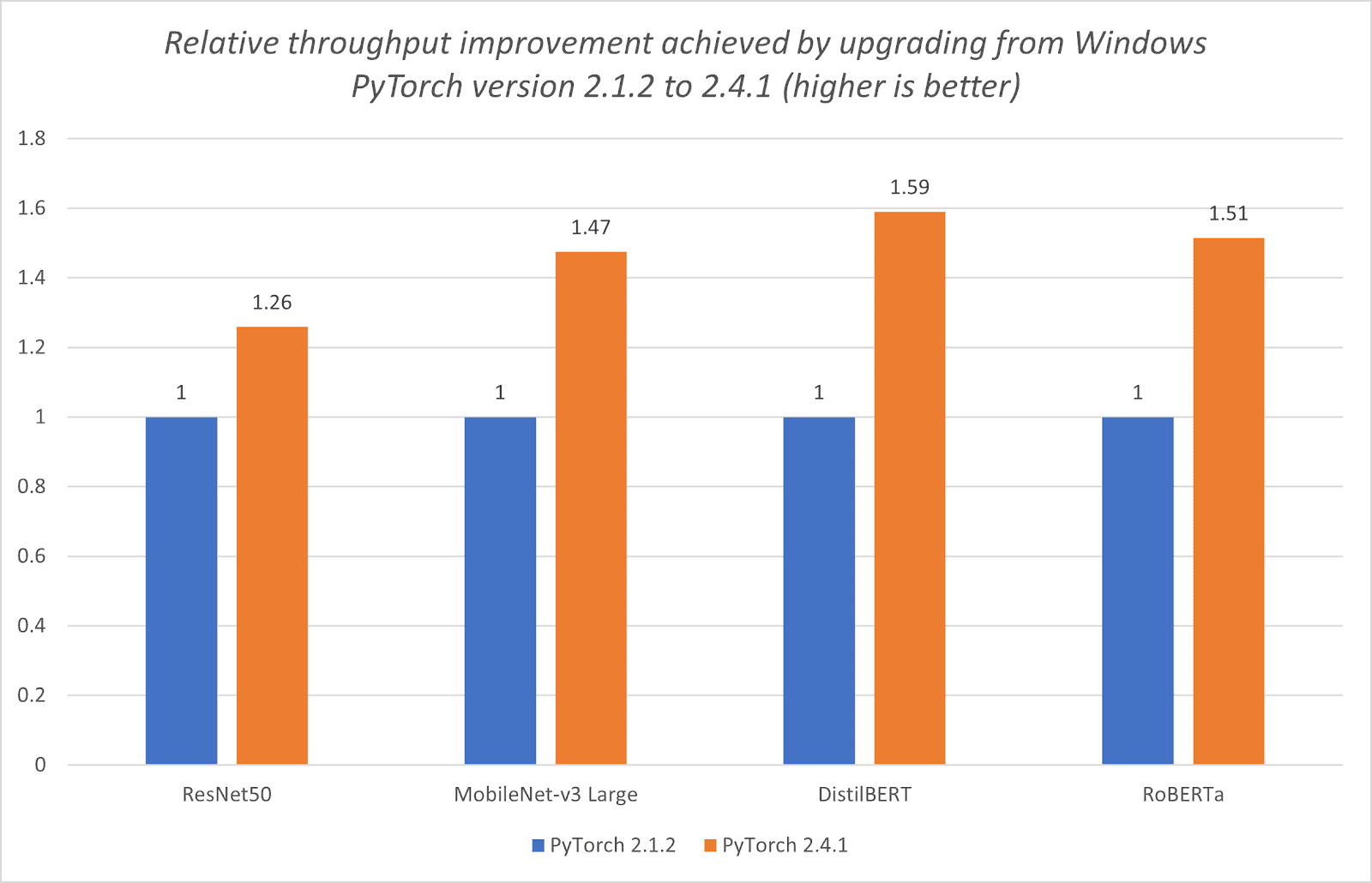
Windows 上 PyTorch CPU 性能提升与向量化优化
图 2.1:从 PyTorch CPU 版本 2.1.2 升级到 2.4.1 所实现的相对吞吐量提升(数值越高越好)。
如下图表所示,我们可以看到 Windows 上 PyTorch CPU 的性能已经达到了 Linux 上的水平。

Windows 与 Linux 在 PyTorch 2.4.1 上的性能比较
图 2.2:使用 PyTorch 版本 2.4.1 的 Windows 与 Linux 相对性能(数值越高越好)。
结论
从 PyTorch 2.0.1 到 PyTorch 2.4.1,Windows 与 Linux 在 CPU 性能上的差距一直在不断缩小。我们比较了不同版本下 Windows 的 CPU 性能与 Linux 的 CPU 性能之比,结果如下所示。
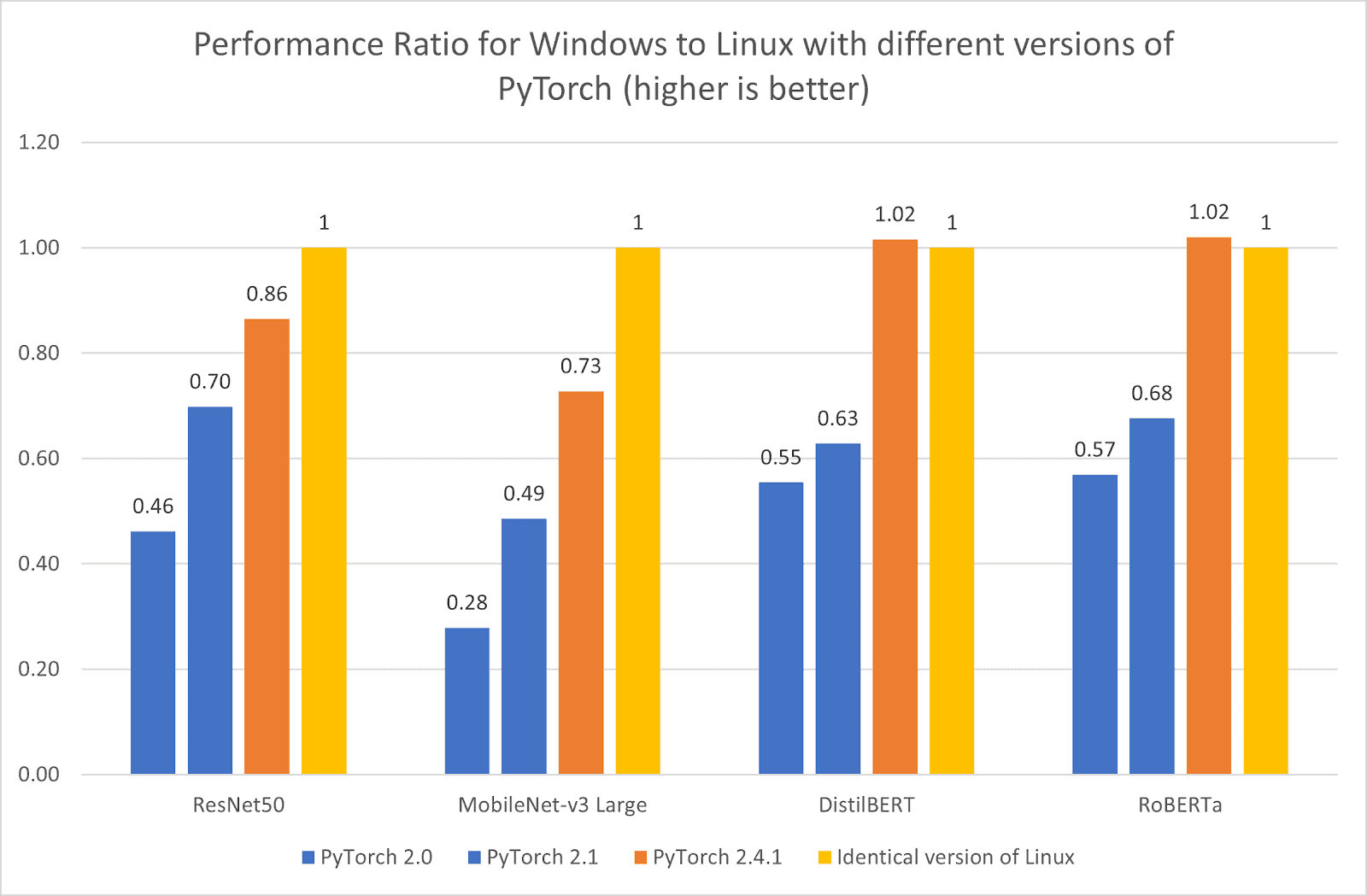
Windows 与不同版本 PyTorch 的 Linux 性能对比
图 3:不同版本 PyTorch 在 Windows 和 Linux 上的性能比(越高越好)。
图表显示,在 PyTorch 2.4.1 版本中,Windows 上的 CPU 性能几乎与 Linux 上的性能相当,在某些模型上甚至超过了 Linux。例如,在 DistillBERT 和 RoBERTa 模型的情况下,Windows 与 Linux 的 CPU 性能比达到了显著的 102%。然而,某些模型,包括 MobileNet-v3,仍然显示出性能差异。英特尔工程师将继续与 Meta 工程师合作,以减少 PyTorch CPU 在 Windows 和 Linux 之间的性能差距。
如何利用优化
在 Windows 上从官方仓库安装 PyTorch CPU 2.4.1 或更高版本,您可能会自动体验到内存分配和向量化的性能提升。
致谢
本博客文章中展示的结果是通过英特尔 PyTorch 团队和 Meta 的共同努力实现的。我们想对徐汉、龚炯、朱浩哲、马明飞、王传琪、陈国兵和王艺康表示衷心的感谢。他们的专业知识和奉献精神对于实现此处讨论的优化和性能提升至关重要。感谢社区中的 Pu Jiachen 参与问题讨论并建议使用 mimalloc。我们还想感谢微软为我们提供了如此易于集成且性能出色的 mallocation 库。感谢 Pierre Blanchard、ARM 的 Nathan Sircombe 和 Adobe 的 Alex Reinking 在解决 PyTorch Windows 中集成 sleef 的兼容性问题上的贡献。最后,我们还要感谢徐静、张伟竹和郑昭琼对这篇博客的贡献。
产品和性能信息
表中的配置由 svr-info 收集。2024 年 8 月 30 日英特尔测试。
| 规格 | 配置 1 | 配置 2 |
| 名称 | 联想 ThinkBook 14 G5+ IRH | 联想 ThinkBook 14 G5+ IRH |
| 时间 | 2024 年 8 月 30 日星期五下午 2:43:02 UTC | 2024 年 8 月 30 日星期五下午 2:43:02 UTC |
| 系统 | LENOVO | LENOVO |
| 底板 | LENOVO | LENOVO |
| 机架 | LENOVO | LENOVO |
| CPU 型号 | 第 13 代英特尔(R)酷睿(TM) i7-13700H | 第 13 代英特尔(R)酷睿(TM) i7-13700H |
| 微架构 | 未知英特尔 | 未知英特尔 |
| 插槽 | 1 | 1 |
| 每插槽核心数 | 14 | 14 |
| 超线程技术 | 启用 | 启用 |
| 处理器 | 20 | 20 |
| 英特尔睿频加速技术 | 启用 | 启用 |
| 基础频率 | 2.4GHz | 2.4GHz |
| 全核最大频率 | 4.7GHz | 4.7GHz |
| 最大频率 | 4.8GHz | 4.8GHz |
| NUMA 节点 | 1 | 1 |
| 预取器 | L2 硬件:启用,L2 调整:启用,DCU 硬件:启用,DCU IP:启用 | L2 硬件:启用,L2 调整:启用,DCU 硬件:启用,DCU IP:启用 |
| PPINs | - | - |
| 加速器 | DLB, DSA, IAA, QAT | DLB, DSA, IAA, QAT |
| 已安装内存 | 32GB(8x4GB LPDDR4 7400 MT/s [5200 MT/s]) | 32GB(8x4GB LPDDR4 7400 MT/s [5200 MT/s]) |
| 大页大小 | 2048kb | 2048kb |
| 透明大页 | madvise | madvise |
| 自动 NUMA 平衡 | 禁用 | 禁用 |
| NIC | “1. 鹰眼湖 PCH CNVi WiFi 2. 英特尔公司” | “1. 鹰眼湖 PCH CNVi WiFi 2. 英特尔公司” |
| 磁盘 | 美光 MTFDKBA512TFH 500G | 美光 MTFDKBA512TFH 500G |
| BIOS | LBCN22WW | LBCN22WW |
| 微代码 | 16668 | 16668 |
| OS | Windows 11 桌面 | Ubuntu 23.10 |
| 内核 | OS 版本 19045.4412 | 6.5.0-27-通用 |
| TDP | 200 瓦 | 200 瓦 |
| 功耗与性能策略 | 正常省电模式(7) | 正常省电模式(7) |
| 频率控制器 | 性能 | 性能 |
| 频率驱动器 | intel_pstate | intel_pstate |
| 最大 C 状态 | 9 | 9 |
通知和免责声明
性能因使用、配置和其他因素而异。请在性能指数网站上了解更多信息。
性能结果基于配置中显示的测试日期,可能无法反映所有公开可用的更新。请参阅备份以获取配置详细信息。没有任何产品或组件可以绝对安全。您的成本和结果可能会有所不同。英特尔技术可能需要启用硬件、软件或服务激活。
英特尔公司。英特尔、英特尔标志以及其他英特尔商标均为英特尔公司或其子公司的商标。其他名称和品牌可能属于他人所有。