领英:Shivam Sahni, Byron Hsu, Yanning Chen
Meta:Ankith Gunapal, Evan Smothers
本文探讨了将自定义的 Triton 内核 Liger Kernel 与 torch.compile 集成,以增强使用 torchtune 进行大型语言模型微调(LLMs)的性能。torchtune 是一个 PyTorch 原生库,提供了模块化的构建块和可定制的微调配方,其中包括 torch.compile 对各种LLMs的支持,而 Liger Kernel 提供了优化的 Triton 内核,以提高训练效率并减少内存使用。集成涉及修改 torchtune 的 TransformerDecoder 模块,以绕过线性层计算,使 Liger Fused Linear Cross Entropy Loss 能够处理前向投影权重。在 NVIDIA A100 实例上进行的实验表明, torch.compile 在吞吐量和内存效率方面优于 PyTorch Eager,Liger Kernel 进一步减少了峰值内存分配,并允许更大的批量大小。结果表明,在批量大小为 256 时,峰值内存减少了 47%,而 meta-llama/Llama-3.2-1B 的吞吐量略有增加,证实了集成效果显著,且不影响损失曲线。
火炬调优简介
torchtune 是一个专为微调设计的 PyTorch 原生库,它提供了可组合和模块化的构建块以及微调配方,这些配方可以轻松定制以适应您的用例,正如本博客中将要展示的那样。
torchtune 提供:
- PyTorch 实现了来自 Llama、Gemma、Mistral、Phi 和 Qwen 模型家族的流行模型架构
- 全局微调、LoRA、QLoRA、DPO、PPO、QAT、知识蒸馏等可破解的训练食谱
- 基于最新 PyTorch API 的即用型内存效率、性能提升和扩展,包括
torch.compile - 易于配置训练、评估、量化或推理食谱的 YAML 配置
- 内置对许多流行数据集格式和提示模板的支持
Liger 内核简介
Liger 内核是一个开源库,包含优化的 Triton 内核,旨在提高大型语言模型训练的效率和可扩展性(LLMs)。它专注于内核级别的优化,如操作融合和输入分块,与 HuggingFace 等现有实现相比,在训练吞吐量和 GPU 内存使用方面实现了显著的改进。通过一行代码,Liger 内核可以提高训练吞吐量 20%,并减少内存使用 60%。
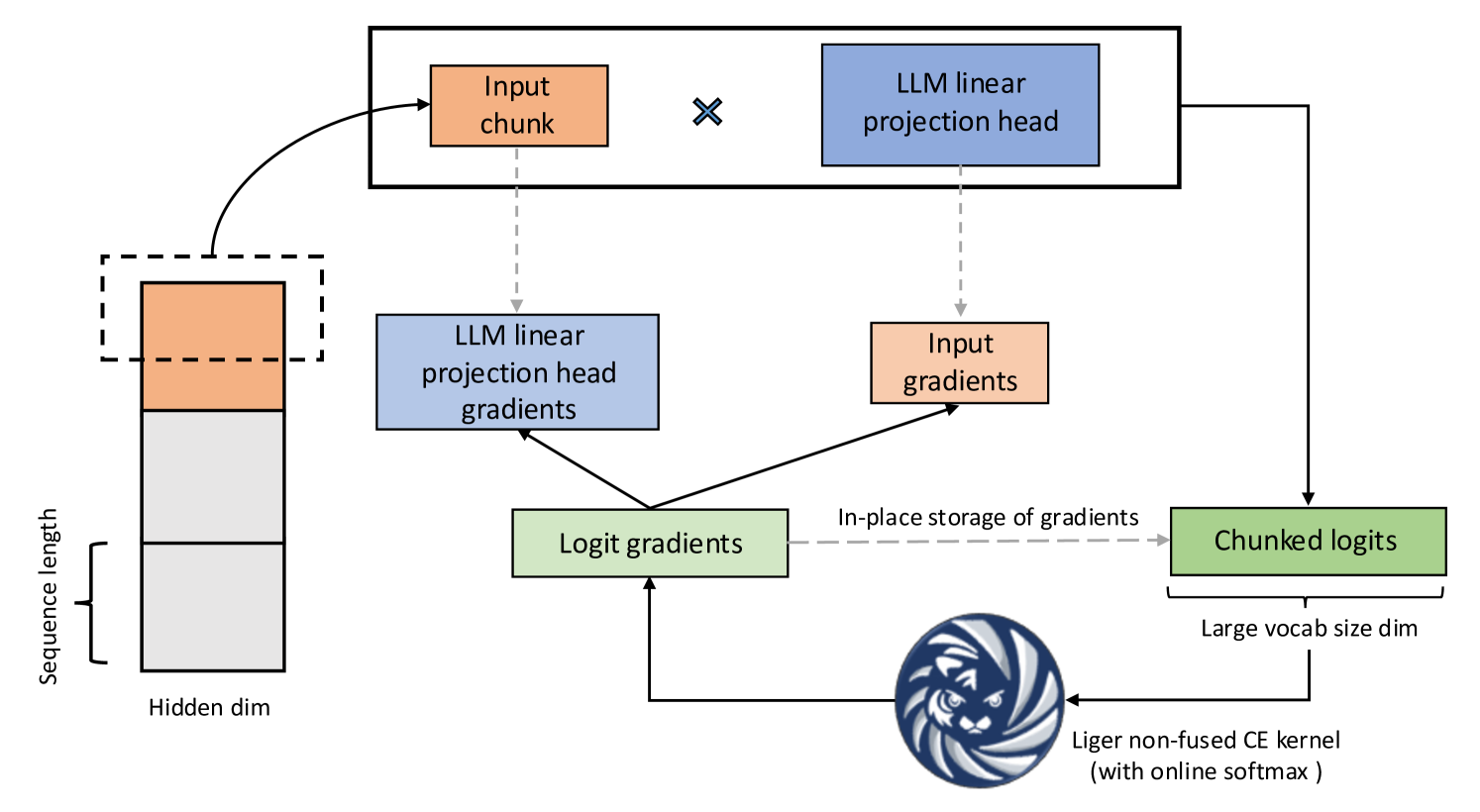
图 1:融合线性交叉熵
Liger 内核性能提升的大部分来自融合线性交叉熵(FLCE)损失,其核心思想如下:
在LLMs中,词汇量显著增加,导致交叉熵(CE)损失计算过程中的 logit 张量很大。这个 logit 张量消耗了过多的内存,导致训练瓶颈。例如,当以 8 个批次大小和 4096 个序列长度进行训练时,256k 的词汇量会导致 16.8GB 的 logit 张量。FLCE 内核将计算分解成更小的块,从而减少内存消耗。
下面是如何工作的:
- 通过折叠批次大小和序列长度维度,将 3D 隐藏状态展平为 2D 矩阵。
- 对分块隐藏状态依次应用线性投影头。
- 使用 Liger CE 内核计算部分损失并返回分块 logits 梯度。
- 推导分块隐藏状态梯度并累积投影头梯度。
Torchtune 的食谱提供开箱即用的 torch.compile 支持。研究表明,利用 torch.compile 与 FLCE 结合可以使 FLCE 速度提高 2 倍。
将 Liger 内核与 torch.compile 和 torchtune 集成。
我们展示了 Liger 内核与 torch.compile & torchtune 的集成,通过运行一个完整的微调配方来做到这一点。为了实现这一集成,我们定义了一个自定义的完整微调配方,以下是更改的详细信息。
CUDA_VISIBLE_DEVICES=0,1,2,3 tune run --nproc_per_node 4 recipes/full_finetune_distributed.py --config llama3_2/1B_full optimizer=torch.optim.AdamW optimizer.fused=True optimizer_in_bwd=False gradient_accumulation_steps=1 dataset.packed=True compile=True enable_activation_checkpointing=True tokenizer.max_seq_len=512 batch_size=128
LCE 内核的一个输入是前向投影权重。torchtune 设计为一个模块化库,具有可组合的块。有一个 TransformerDecoder 块,在该块的末尾,我们将最终隐藏状态通过一个线性层来获取最终输出。由于线性层与 LCE 内核中的 CE 损失相结合,我们为 TransformerDecoder 编写了一个自定义的 forward 函数,其中我们跳过了通过线性层的计算。
在完整的微调配方中,我们用这个自定义方法覆盖了模型的 forward 方法
import types
from liger_kernel.torchtune.modules.transformers import decoder_forward
self._model.forward = types.MethodType(decoder_forward, self._model)
然后,我们将模型的 forward 投影权重传递给 LCE 内核来计算损失
from liger_kernel.transformers.fused_linear_cross_entropy import (
LigerFusedLinearCrossEntropyLoss,
)
# Use LCE loss instead of CE loss
self._loss_fn = LigerFusedLinearCrossEntropyLoss()
# call torch.compile on the loss function
if self._compile:
training.compile_loss(self._loss_fn, verbose=self._is_rank_zero)
# pass the model's forward projection weights for loss computation
current_loss = (
self._loss_fn(
self._model.output.tied_module.weight,
logits,
labels,
)
* current_num_tokens
)
完整的代码和说明可以在 GitHub 仓库中找到。
实验与基准测试结果
我们进行了 3 种类型的实验,以展示 Liger 内核与 torch.compile 的集成如何增强 torchtune 的性能。我们在运行 NVIDIA A100 的实例上设置了我们的实验。我们对不同批量大小的LLM meta-llama/Llama-3.2-1B 进行了微调。我们记录了以每秒 token 数表示的吞吐量,并测量了微调期间的峰值内存分配。由于这是一个小型模型,我们只使用了 4 个 A100 GPU 进行基准测试。以下是我们进行的实验:
- 使用 PyTorch eager 将 batch_size 增加为 2 的幂次
- 使用 torch.compile 将 batch_size 以 2 的幂次增加
- 使用 torch.compile & Liger 集成将 batch_size 以 2 的幂次增加
我们注意到,在 PyTorch Eager 中,随着 batch_size 的增加,吞吐量也会增加,直到 batch_size 为 256 时达到 OOM。在 torch.compile 中,对于每个 batch_size,吞吐量都高于 PyTorch Eager。我们观察到,随着 batch_size 的增加,峰值内存分配急剧减少,在 batch_size 为 128 时,峰值内存减少了超过 50%。这导致 torch.compile 能够支持 batch_size 为 256,因此, torch.compile 的整体吞吐量比 PyTorch Eager 高 36%。将 Liger 内核与 torch.compile 集成不会在较低的 batch_size 下降低吞吐量,但随着 batch_size 的增加,我们发现 torchtune 相比 torch.compile 消耗的内存更少。在 batch_size 为 256 时,我们观察到峰值内存分配减少了 47%。这使我们能够使用 torch.compile & Liger 的 batch_size 为 512。我们注意到,与没有自定义 triton 内核的 torch.compile 相比,吞吐量有 1-2%的边际增加。
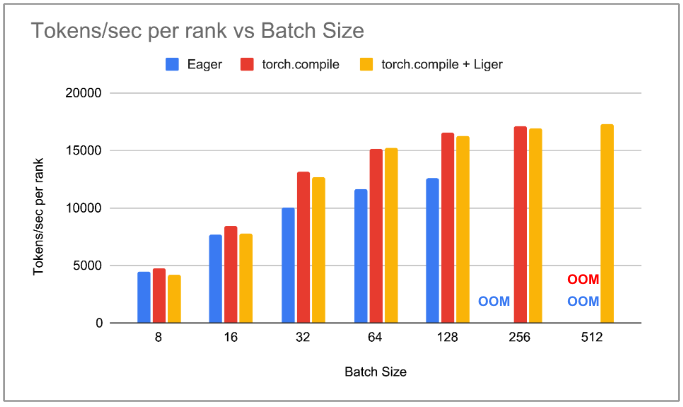
图 2:每个 rank 的 tokens/sec 与 batch_size 的关系图
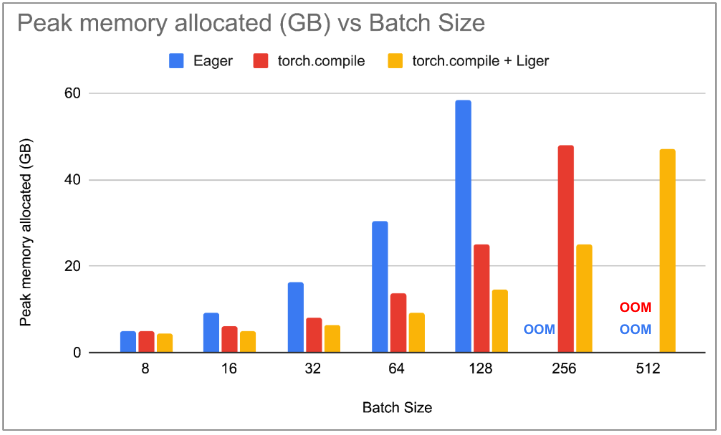
图 3:峰值内存分配与 batch_size 的关系
为了排除 Liger Kernel 与 torchtune 集成可能存在的任何潜在功能问题,我们绘制了有无 Liger 的损失曲线与训练步数的对比图。我们观察到损失曲线没有明显差异。
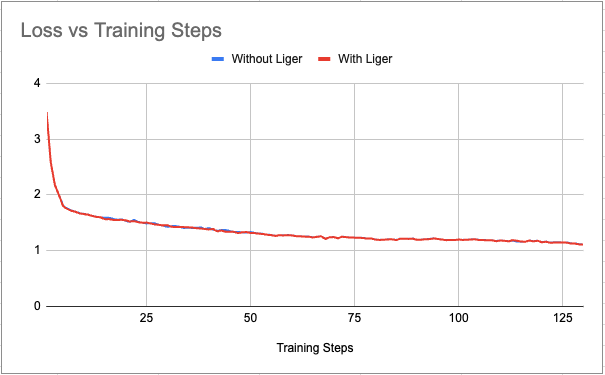
图 4:batch_size=128 时损失与训练步数的绘图
下一步
- 在 torchtune 的 DPO 和知识蒸馏配方中启用 Liger 内核用于 DPO 损失和蒸馏损失。
- 在 torchtune 中支持 Liger 集成以及张量并行训练。
致谢
我们感谢 Hamid Shojanazeri(Meta)、Less Wright(Meta)、Horace He(Meta)和 Gregory Chanan(Meta)在制作这篇博客文章过程中提供的反馈和支持。