作为 PyTorch 2.0 版本的发布内容,将“Better Transformer”项目(在 PyTorch 中称为加速 Transformer)的加速实现( torch.nn.functional.scaled_dot_product_attention )原生集成到 PyTorch 中。此实现利用了 FlashAttention 和内存高效注意力融合内核,并支持训练和推理。
我们还发布了一个笔记本,展示了此集成的示例
在观察到扩散模型推理速度提升了 20-30% 后,我们继续实现了与 🤗 Transformers 模型的集成,通过 🤗 Optimum 库。与之前对编码器模型的集成类似,此集成用使用 torch.nn.functional.scaled_dot_product_attention 的有效实现替换了 Transformers 中的模块。使用方法如下:
from optimum.bettertransformer import BetterTransformer
from transformers import AutoModelForCausalLM
with torch.device(“cuda”):
model = AutoModelForCausalLM.from_pretrained(“gpt2-large”, torch_dtype=torch.float16)
model = BetterTransformer.transform(model)
# do your inference or training here
# if training and want to save the model
model = BetterTransformer.reverse(model)
model.save_pretrained(“fine_tuned_model”)
model.push_to_hub(“fine_tuned_model”)
以下是我们关于 torch.nn.functional.scaled_dot_product_attention 的发现总结:
- 在给定的硬件上训练时,最有效的是调整更大的模型、序列长度或批量大小。
- 训练期间在 GPU 上的内存占用节省从 20%到 110%以上。
- 训练期间的加速从 10%到 70%不等。
- 推理过程中的加速从 5%到 20%不等。
- 对于小头尺寸,独立使用时,速度提升可达 3 倍,内存节省高达 40 倍(取决于序列长度)。
你可能会对内存节省和速度提升的广泛范围感到惊讶。在这篇博客文章中,我们讨论了我们的基准测试,其中这个特性表现出色,以及未来 PyTorch 版本中的改进。
在 transformers 的下一个版本中,你只需安装正确的 optimum 版本并运行:
model = model.to_bettertransformer()
使用 BetterTransformer API 转换您的模型。您现在就可以通过从源代码安装 transformers 来尝试这个功能。
使用🤗 Transformers 进行基准测试和用法
torch.nn.functional.scaled_dot_product_attention 可用于任何使用标准注意力机制的架构,并替换了样板代码:
# native scaled_dot_product_attention is equivalent to the following:
def eager_sdpa(query, key, value, attn_mask, dropout_p, is_causal, scale):
scale_factor = 1 / math.sqrt(Q.size(-1)) if scale is None else scale
attn_mask = torch.ones(L, S, dtype=torch.bool).tril(diagonal=0) if is_causal else attn_mask
attn_mask = attn_mask.masked_fill(not attn_mask, -float('inf')) if attn_mask.dtype==torch.bool else attn_mask
attn_weight = torch.softmax((Q @ K.transpose(-2, -1) * scale_factor) + attn_mask, dim=-1)
attn_weight = torch.dropout(attn_weight, dropout_p)
return attn_weight @ V
在🤗 Optimum 与 Transformers 模型的集成中,目前支持以下架构:gpt2、gpt-neo、gpt-neox、gptj、t5、bart、codegen、pegasus、opt、LLaMA、blenderbot、m2m100。您预期这个列表将在不久的将来扩展!
为了验证原生缩放点积注意力的好处,我们进行了推理和训练基准测试,结果如下所示。
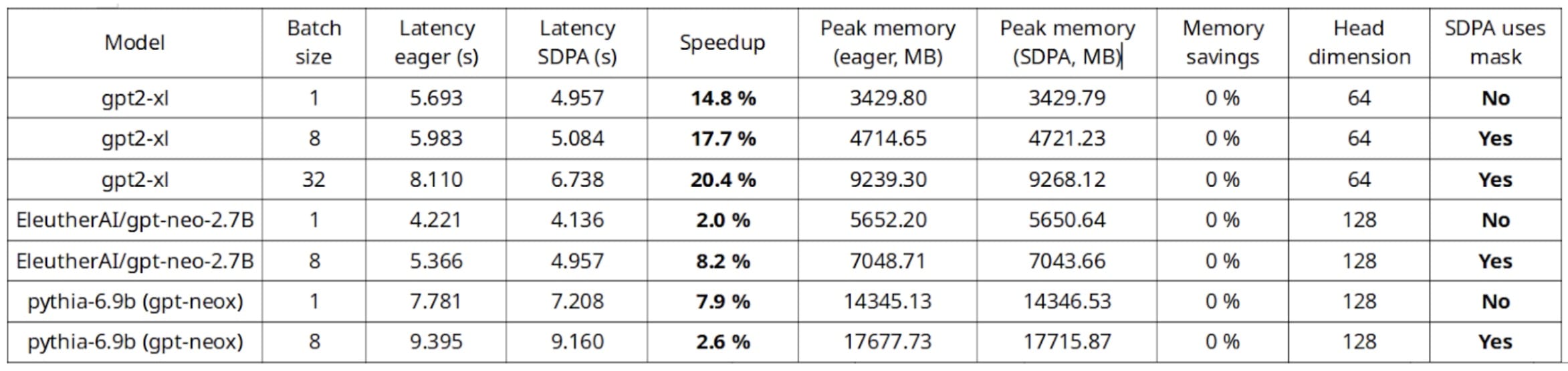 在单个 A10G GPU 上进行的推理基准测试,AWS g5.4xlarge 实例
在单个 A10G GPU 上进行的推理基准测试,AWS g5.4xlarge 实例
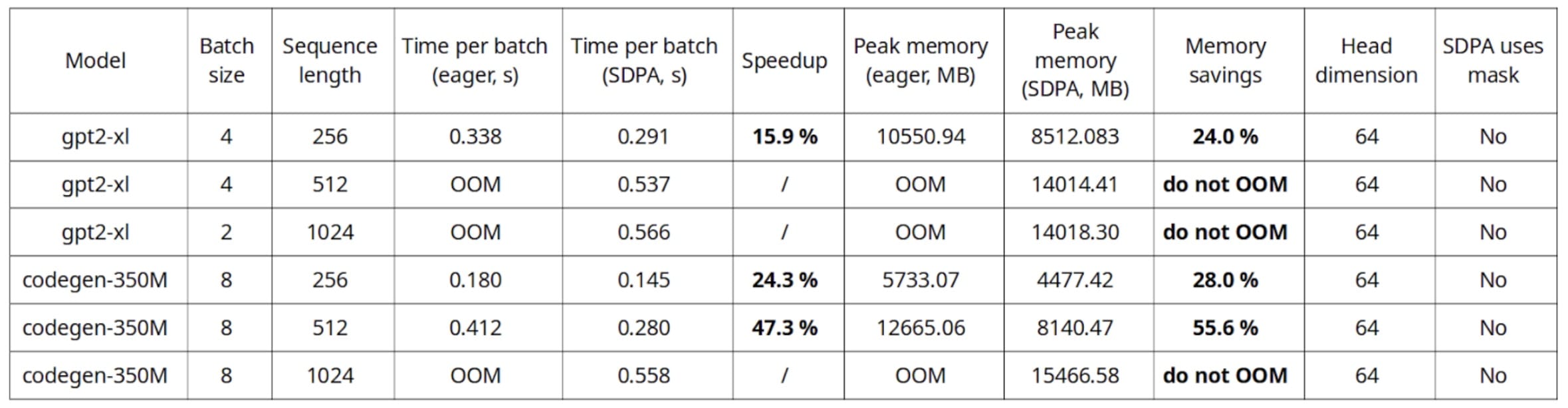 在单个 A10G GPU 上进行的训练基准测试,AWS g5.4xlarge 实例
在单个 A10G GPU 上进行的训练基准测试,AWS g5.4xlarge 实例
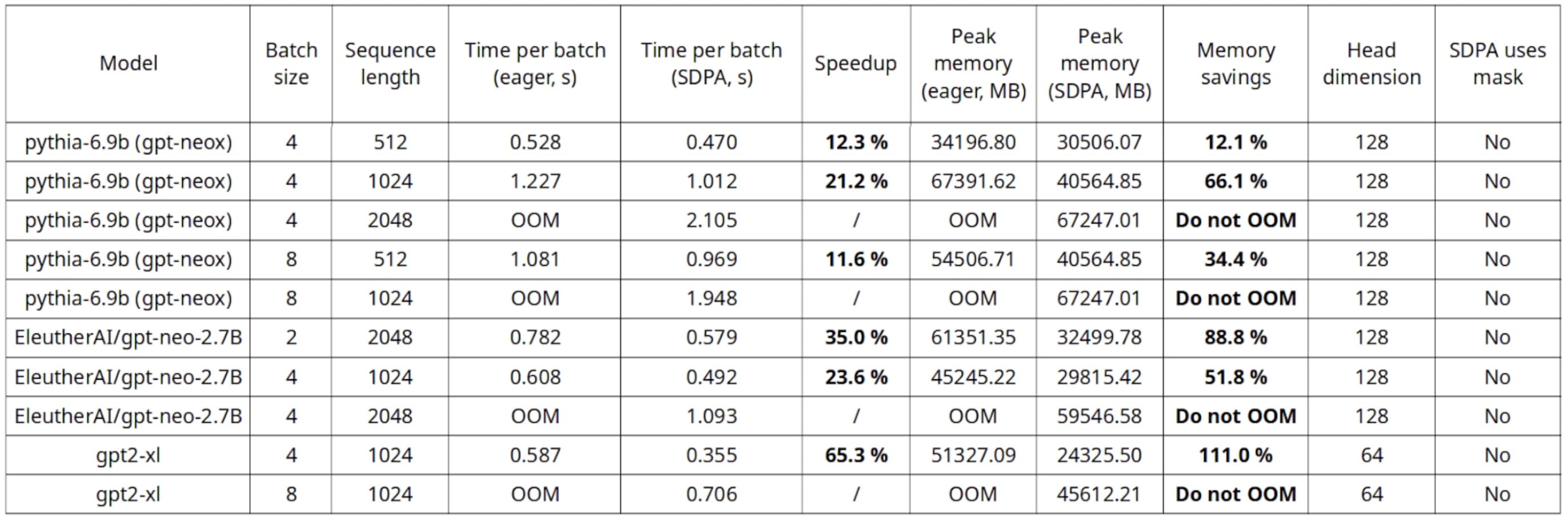 在单个 A100-SXM4-80GB,Nvidia DGX 上进行的训练基准测试
在单个 A100-SXM4-80GB,Nvidia DGX 上进行的训练基准测试
在这个基准测试中,最有趣的发现是,本机 SDPA 允许使用更长的序列长度和批量大小,而不会遇到内存不足的问题。此外,在推理过程中可以看到高达 20%的速度提升,在训练过程中甚至更高。
如训练基准测试所示,较小的头部维度可以带来更高的速度提升和内存节省,我们将在下一节中讨论这一点。
该实现还支持多 GPU 设置,这得益于🤗 Accelerate 库通过传递 device_map=”auto” 到 from_pretrained 方法。以下是使用两个 A100-SXM4-80GB 进行训练的一些结果。
 使用🤗 Accelerate 库在两个 A100-SXM4-80GB、Nvidia DGX 上进行训练的基准测试
使用🤗 Accelerate 库在两个 A100-SXM4-80GB、Nvidia DGX 上进行训练的基准测试
注意,一些内核只支持 sm_80 计算能力(这是 A100 GPU 的那个),这限制了在广泛硬件上的可用性,特别是如果头部维度不是 2 的幂时。例如,截至 PyTorch 2.0.0 版本在训练期间,opt-2.7b(headim=80)和 gpt-neox-20b(headdim=96)无法调度使用 flash attention 的内核,除非在 A100 GPU 上运行。未来可能会开发出更好的内核:https://github.com/pytorch/pytorch/issues/98140#issuecomment-1518101895
Flash Attention,内存高效注意力与数学差异
原生的 scaled_dot_product_attention 依赖于三种可能的后端实现:flash attention、内存高效注意力以及所谓的数学实现,它为所有 PyTorch 平台提供硬件中立的回退方案。
当给定问题大小的融合内核可用时,将使用 flash-attention 或内存高效注意力,从而有效地降低内存占用,例如在内存高效注意力的情况下,O(N)的内存分配是在 GPU 全局内存上进行的,而不是传统急切注意力实现的 O(N^2)。使用 flash 注意力时,预计内存访问(读取和写入)次数将减少,因此可以提供速度提升和内存节省。
“math”实现只是使用 PyTorch 的 C++ API 的一个实现。值得注意的是,在这个实现中,为了数值稳定性,查询和键张量是分别缩放的,因此启动了两个 aten::div 操作,而不是在可能只包含此数值稳定性优化的急切实现中只启动一个操作。
头维度对速度提升和内存节省的影响
在基准测试中,我们发现随着头维度的增加,速度提升/内存增益有所下降。这对于一些架构,如 EleutherAI/gpt-neo-2.7B,其头维度相对较大为 128,或者 EleutherAI/gpt-j-6B(及其派生模型 PygmalionAI/pygmalion-6b),其头维度为 256(实际上由于头维度过大,目前尚未使用融合内核)来说,是一个问题。
这种趋势可以在下面的图表中看到,其中 torch.nn.scaled_dot_production 独立基准测试与上述急切实现进行了比较。此外,我们使用 torch.backends.cuda.sdp_kernel 上下文管理器强制使用分别的数学、闪存注意力和内存高效注意力实现。
 使用内存高效注意力 SDP 内核(仅前向),A100
使用内存高效注意力 SDP 内核(仅前向),A100
 使用数学(不带 dropout),A100
使用数学(不带 dropout),A100
 使用不带 dropout 的闪存注意力 SDP 内核(A100)
使用不带 dropout 的闪存注意力 SDP 内核(A100)
 使用内存高效的注意力 SDP 内核(不带 dropout)(A100)
使用内存高效的注意力 SDP 内核(不带 dropout)(A100)
我们看到,对于相同的问题规模,无论是推理还是训练,随着头维度的增加,速度提升会降低,例如使用闪存注意力内核时,从 headdim=8 的 3.4 倍降低到 headdim=128 的 1.01 倍。
随着头维度的增大,预期的内存节省也会减少。回想一下标准的注意力计算:
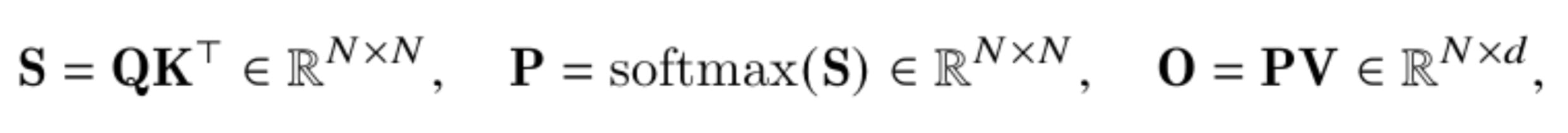
由于中间计算,全局内存占用为 2 * N * N + N * d,在此标准逐步计算中。内存高效的注意力机制建议迭代更新 softmax 重归一化常数,并将其计算移至最后,从而仅分配常数输出内存 N * d。
因此,内存节省率是 2 * N / d + 1,随着头维度的增大而减小。
在闪存注意力机制中,权衡的是 GPU 流式多处理器的头维度 d 和共享内存大小 M,总内存访问次数为 O(N² * d²/M)。因此,内存访问量与头维度呈二次方关系,这与标准注意力机制的线性关系相反。原因是,在闪存注意力机制中,对于较大的头维度 d,键和值 K、V 需要分成更多块以适应共享内存,而每个块又需要加载完整的查询 Q 和输出 O。
因此,闪速注意力的最高加速发生在 d² / M 的比率足够小的情况下。
截至 PyTorch 2.0.0 的当前限制
缺少缩放参数
截至 PyTorch 2.0.0, torch.nn.functional.scaled_dot_product_attention 没有缩放参数,使用默认的隐藏尺寸平方根 sqrt(d_k)。
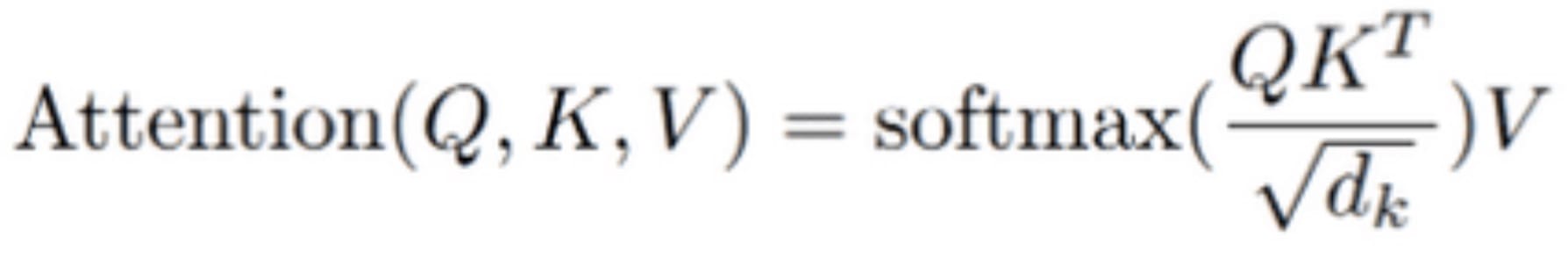
然而,一些架构如 OPT 或 T5 在注意力机制中不使用缩放,而 Pytorch 2.0.0 强制它在 scaled_dot_product_attention 调用之前进行人工缩放。这引入了不必要的开销,因为除了注意力中的不必要除法外,还需要额外的乘法。
此问题的修复已合并到 PyTorch 仓库中。
支持闪存注意力/内存高效注意力以及自定义掩码
截至 PyTorch 2.0.0 版本,当传递自定义注意力掩码时,无法使用闪存注意力或内存高效注意力。在这种情况下, scaled_dot_product_attention 会自动调度到 C++实现。
然而,正如我们所看到的,一些架构需要自定义注意力掩码,例如使用位置偏置的 T5。此外,在批大小大于一且某些输入可能被填充的情况下,也需要传递自定义注意力掩码。对于后者,可以使用 NestedTensor 作为替代方案,SDPA 支持这种方案。
因此,对自定义掩码的有限支持限制了在这些特定情况下 SDPA 的益处,尽管我们希望未来能够扩展支持。
注意,xformers(PyTorch 的 SDPA 部分从中获得灵感)目前支持任意注意力掩码:https://github.com/facebookresearch/xformers/blob/658ebab39545f180a6075385b3897921623d6c3b/xformers/ops/fmha/cutlass.py#L147-L156。HazyResearch 对闪速注意力(flash attention)的实现也支持等效的填充实现,因为它使用累积序列长度数组以及打包的查询/键/值,本质上与 NestedTensor 相似。
总之
使用 torch.nn.functional.scaled_dot_product_attention 是一种免费的优化,它不仅使你的代码更易读,占用更少的内存,而且在大多数情况下速度更快。
虽然 PyTorch 2.0.0 的实现在某些方面仍有小局限性,但推理和训练在大多数情况下已经从 SDPA 中获得了巨大益处。我们鼓励您使用此原生实现,无论是训练还是部署您的 PyTorch 模型,以及🤗 Transformers 模型,只需一行代码即可实现转换!
未来,我们希望将 API 适配,以便用户能够在基于编码器的模型中使用 SDPA。
感谢 Benjamin Lefaudeux、Daniel Haziza 和 Francisco Massa 对头部维度影响方面的建议,以及 Michael Gschwind、Christian Puhrsch 和 Driss Guessous 对博客文章的反馈!
基准复现
本文所展示的基准测试是在 torch==2.0.0、transformers==4.27.4、accelerate==0.18.0 和 optimum==1.8.0 的环境下进行的。
使用推理、训练🤗 Transformers 模型和独立 SDPA 的脚本,可以轻松地重现这些基准测试。