概述
在本文中,我们展示了如何通过减少内存使用和优化线程池策略来优化基于 LibTorch 的推理引擎,以最大化吞吐量。我们将这些优化应用于音频数据模式识别引擎,例如音乐和语音识别或声纹识别。本文中讨论的优化可以将内存使用减少 50%,并将推理的端到端延迟减少 37.5%。这些优化适用于计算机视觉和自然语言处理。
音频识别推理
音频识别(AR)引擎可以用于识别和识别声音模式。例如,从音频记录中识别鸟类的种类和物种,区分音乐和歌手的声音,或检测异常声音,表明建筑物存在安全隐患。为了识别感兴趣的声音,AR 引擎通过 4 个阶段处理音频:
- 文件验证:AR 引擎验证输入音频文件。
- 特征提取:从音频文件中的每个片段中提取特征。
- 推理:LibTorch 使用 CPU 或加速器进行推理。在我们的案例中,使用弹性云计算(EC2)实例上的英特尔处理器。
- 后处理:后处理模型解码结果并计算分数,这些分数用于将推理输出转换为标签或转录。
在这 4 个步骤中,推理是最耗计算资源的,可能占用整个管道处理时间的 50%。这意味着在此阶段进行的任何优化都会对整个管道产生重大影响。
并发优化音频识别引擎并不简单。
我们对这个处理管道的目标是通过处理将音频段提取为标签或转录。输入数据是一个由多个短声音段(图 1 中的 S1 到 S6)组成的音频文件。输出数据对应于按时间戳排序的标签或转录。
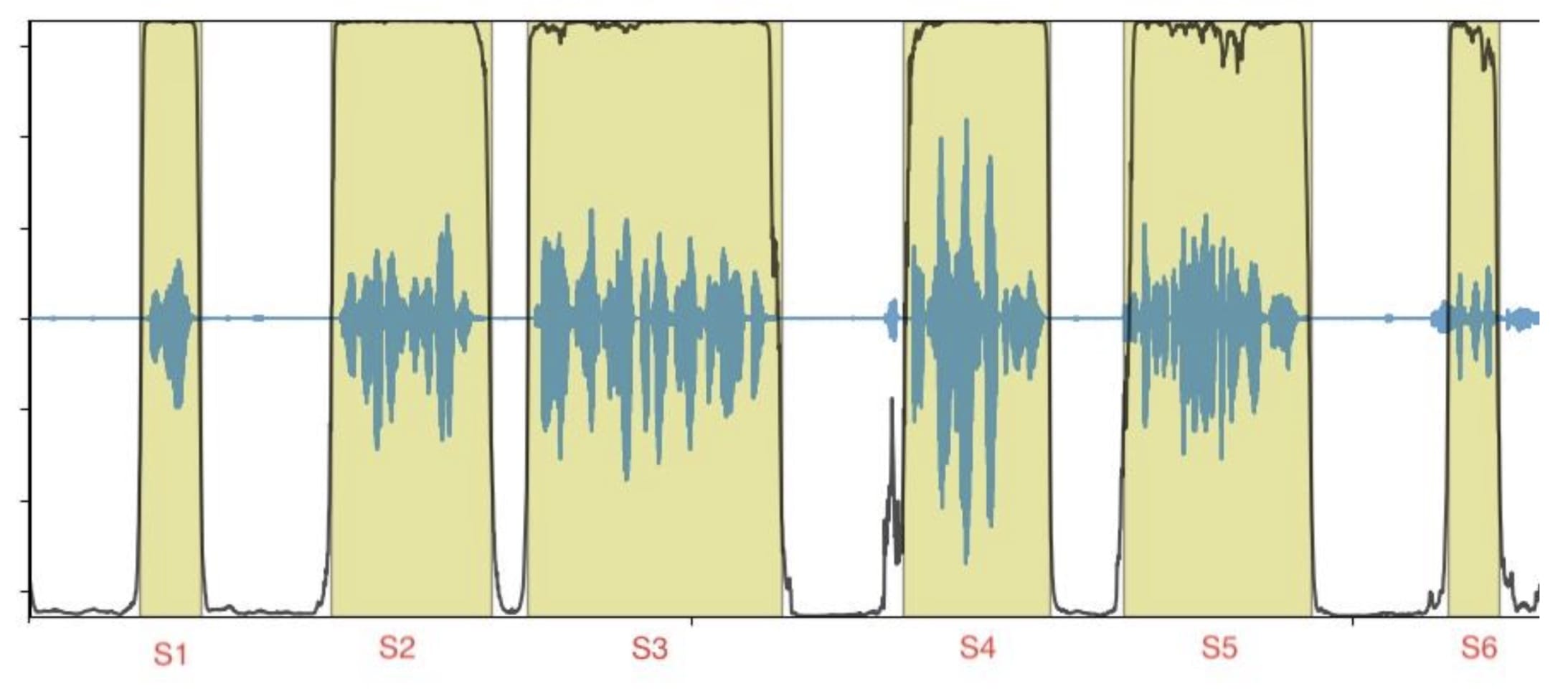
图 1:带有段落边界的示例音频文件
每个段落都可以独立处理,并且可以按顺序处理。这为并行处理段落以及优化整体推理吞吐量和最大化资源利用率提供了机会。
在单个实例上实现并行化可以通过多线程(pThreads、std::threads、OpenMP)或多进程。与多进程相比,多线程的优势在于可以使用共享内存。它使开发者能够通过在线程间共享数据来最小化数据在各个线程之间的重复;在我们的案例中(图 2 中的 AR 模型)。此外,减少内存允许我们通过增加引擎线程的数量来运行更多的管道并行,从而利用我们的 Amazon EC2 实例(在我们的案例中是 c5.4xlarge,它提供 16 个 vCPU)。从理论上讲,我们预计我们的 AR 引擎的硬件利用率将更高,吞吐量也将更高。
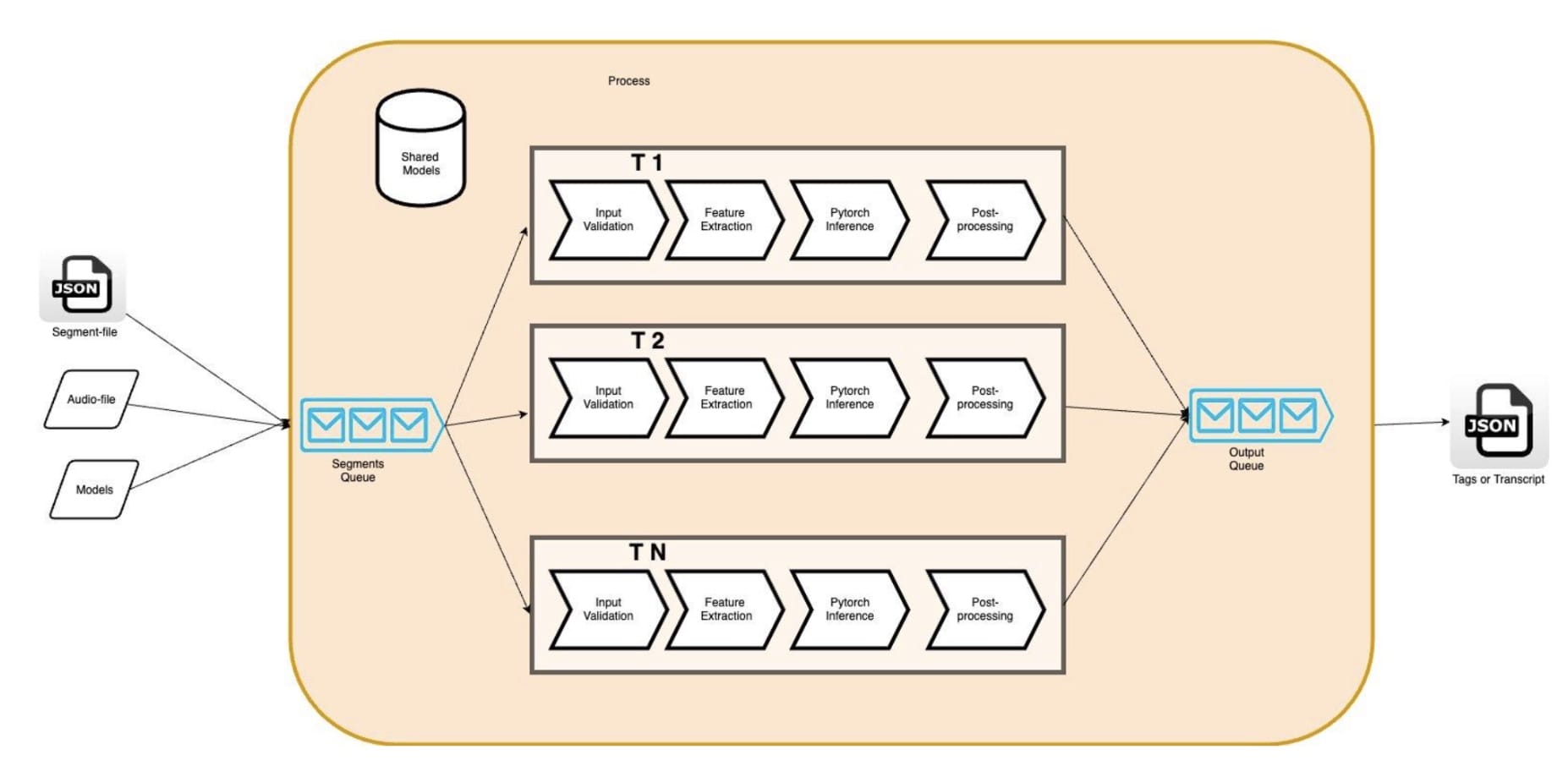
图 2:多线程 AR 引擎
但是我们发现这些假设是错误的。事实上,我们发现增加应用程序的线程数会导致每个音频段的端到端延迟增加,并且会导致引擎吞吐量下降。例如,将并发从 1 个线程增加到 5 个线程,导致延迟增加了 4 倍,这相应地降低了吞吐量。实际上,指标显示在管道中,仅推理阶段的延迟就比单线程基线高 3 倍。
使用分析器,我们发现 CPU 自旋时间增加,这可能是由于 CPU 过载订阅,影响了系统和应用程序的性能。鉴于我们对应用程序多线程实现的控制,我们决定深入研究堆栈,以识别与 LibTorch 默认设置的潜在冲突。
深入探讨 LibTorch 的多线程及其对并发的影响
LibTorch 在 CPU 上的并行推理实现基于全局线程池。实现示例包括跨操作和操作内并行,可以根据模型特性进行选择。在两种情况下,都可以设置每个线程池中的线程数以优化延迟和吞吐量。
为了测试 LibTorch 的并行默认实现设置是否对我们的推理延迟有反作用,我们在 16 核 vCPU 的机器上运行了一个实验,使用时长为 35 分钟的音频文件,保持 LibTorch 的线程间常数为 1(因为我们的模型没有利用跨操作线程池)。我们收集了如图 3 和 4 所示的数据。
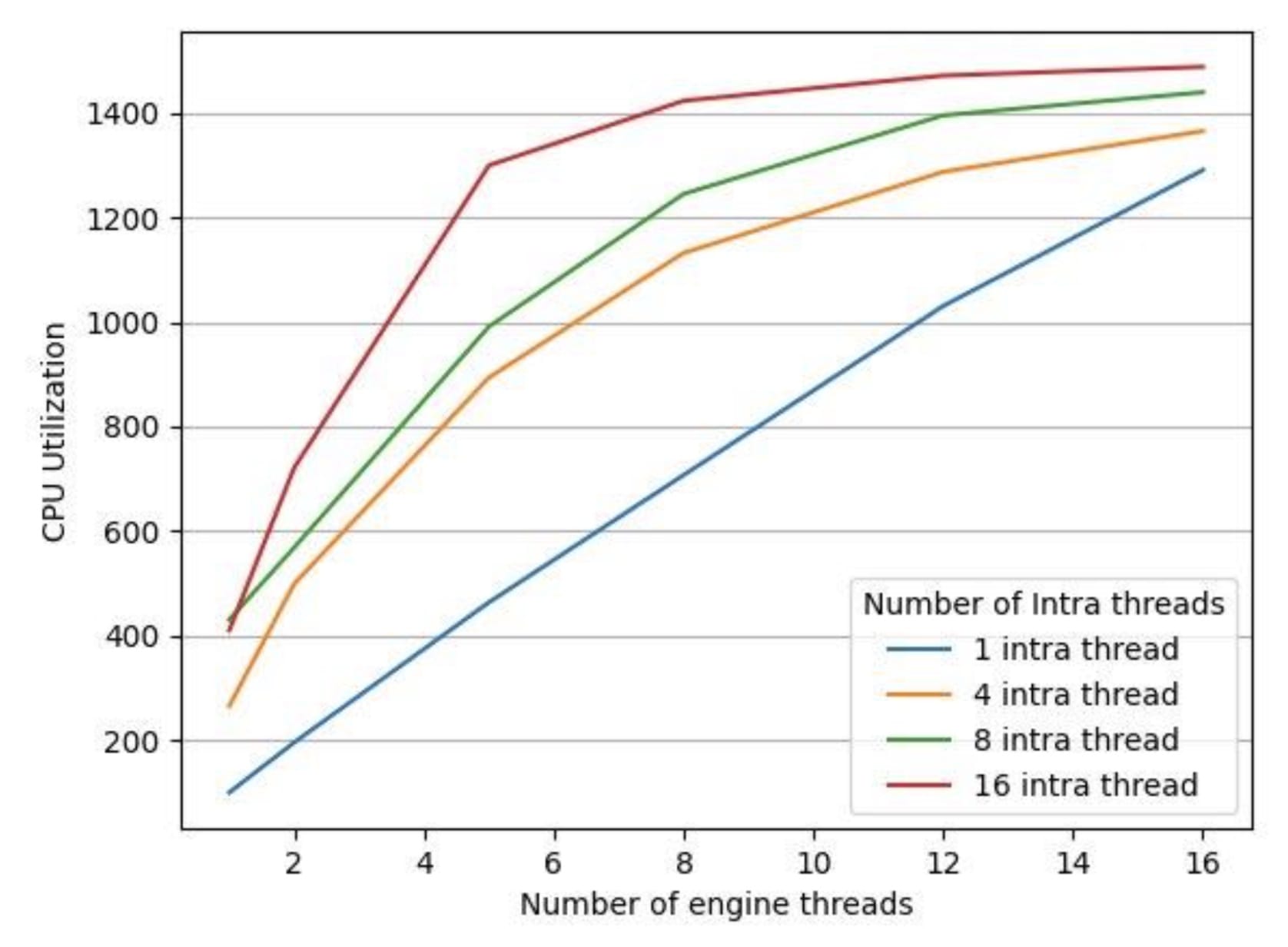
图 3:不同引擎线程数下的 CPU 利用率
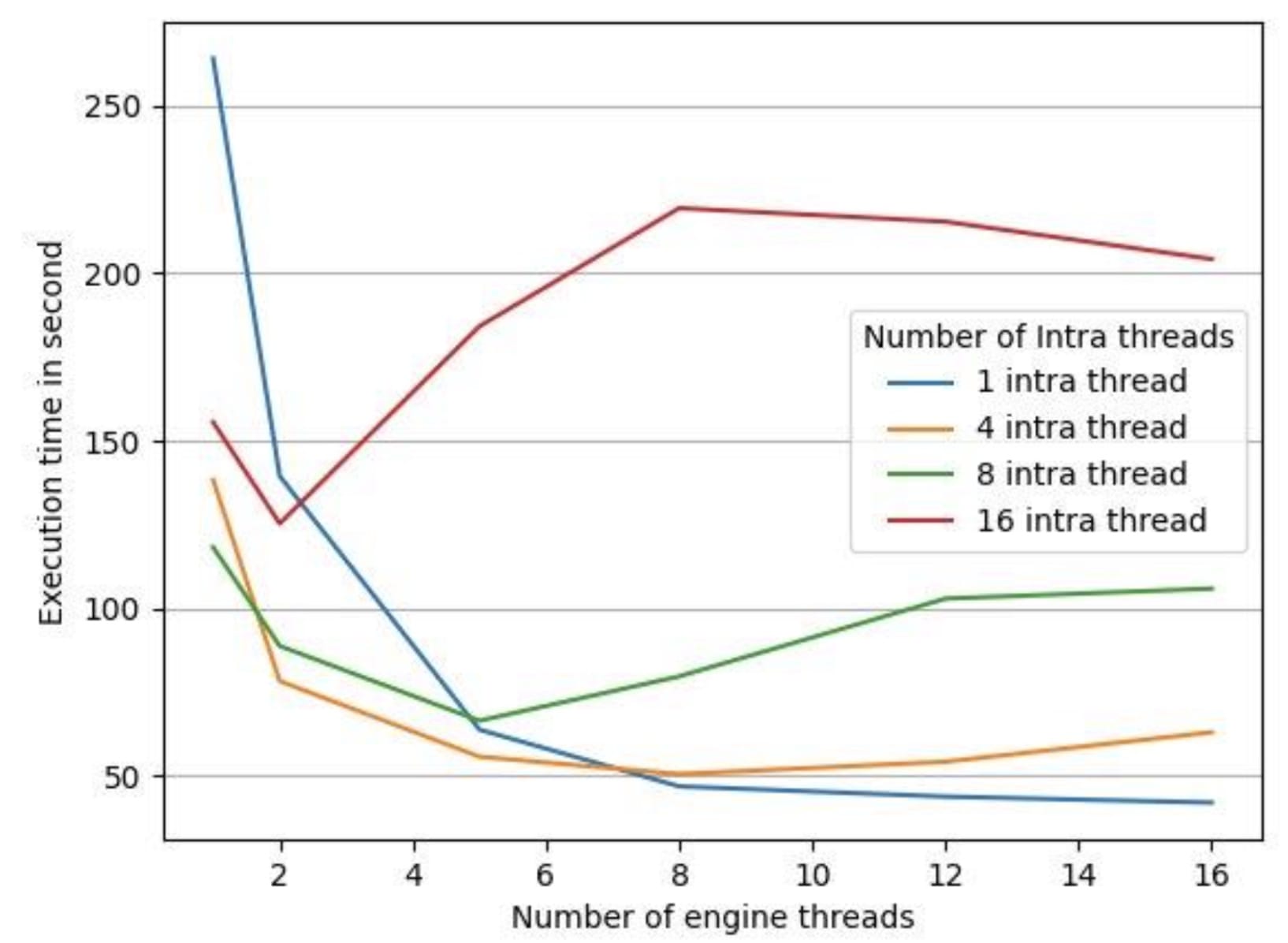
图 4:不同引擎线程数下的处理时间
图 4 中的执行时间是指处理给定音频文件所有片段的端到端处理时间。我们针对 LibTorch 的 intra-threads 有 4 种不同的配置,分别是 1、4、8、16,并且我们为每个 intra-thread 的 LibTorch 配置将引擎线程数从 1 改为 16。正如我们在图 3 中看到的那样,对于所有 LibTorch intra-thread 配置,随着引擎线程数的增加,CPU 利用率也随之增加。但是,正如我们在图 4 中看到的那样,CPU 利用率的增加并没有转化为更低的执行时间。我们发现,在所有情况下,除了一个例外,随着引擎线程数的增加,执行时间也随之增加。唯一的例外是 intra-thread 池大小为 1 的情况。
解决全局线程池问题
使用过多的线程会导致全局线程池性能下降,并引发过度订阅问题。在不禁用 LibTorch 全局线程池的情况下,很难匹配多进程引擎的性能。
禁用 LibTorch 全局线程池就像将 intra-op/inter-op 并行线程数设置为 1 一样简单,如下所示:
at::set_num_threads(1) // Disables the intraop thread pool.
at::set_num_interop_threads(1). // Disables the interop thread pool.
如图 4 所示,当禁用 LibTorch 全局线程池时,测得的最低处理时间。
该方案在多个情况下提高了 AR 引擎的吞吐量。然而,在评估长时间数据集(加载测试中超过 2 小时的音频文件)时,我们发现引擎的内存占用逐渐开始增加。
优化内存使用
我们对系统进行了两小时长音频文件的负载测试,发现观察到的内存增加是多线程 LibTorch 推理中内存碎片化的结果。我们使用 jemalloc 解决了这个问题,jemalloc 是一种强调碎片避免和可扩展并发支持的通用 malloc(3)实现。使用 jemalloc,我们的峰值内存使用量平均下降了 34%,平均内存使用量下降了 53%。
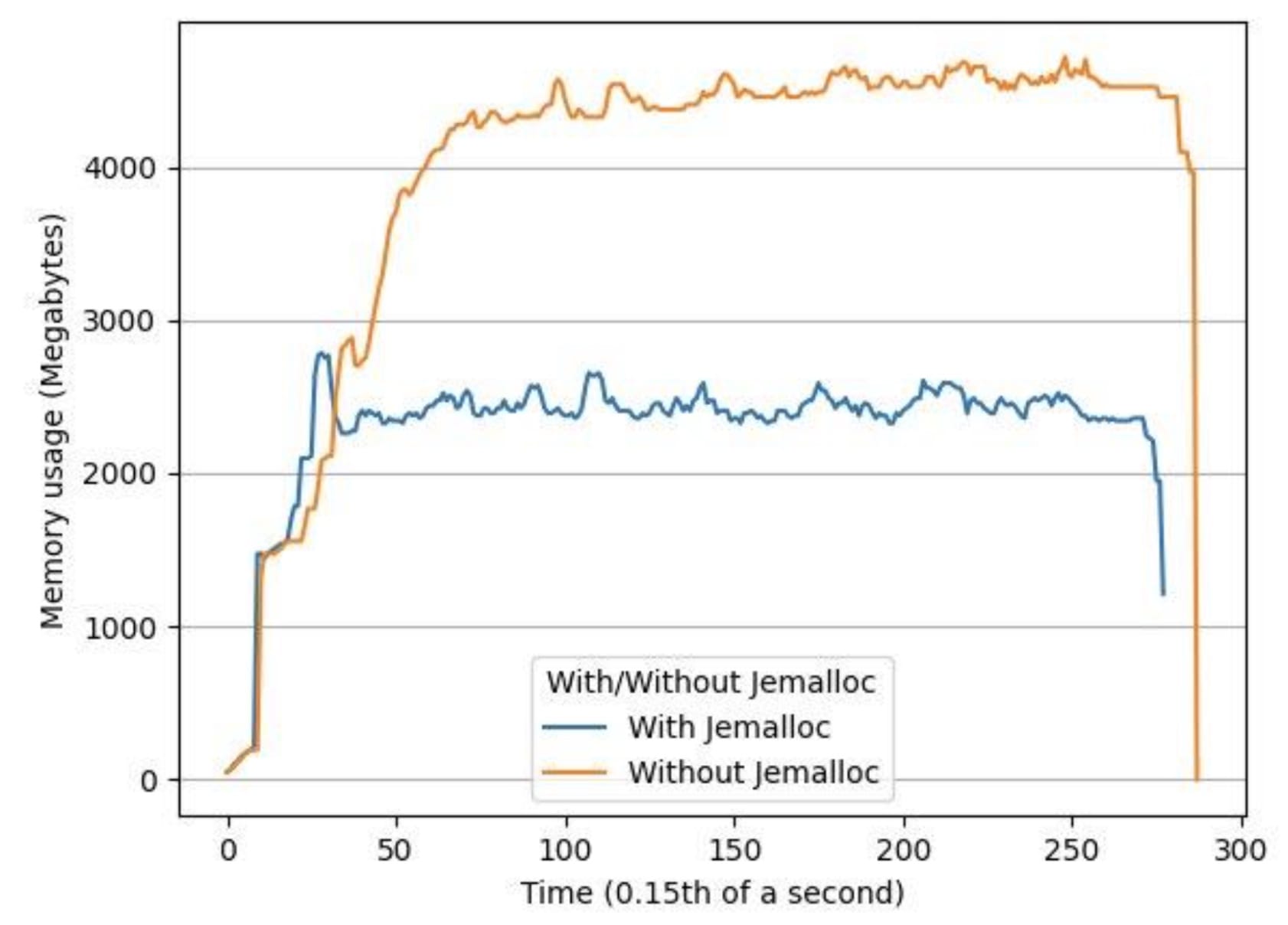
图 5:使用相同输入文件,有 jemalloc 和无 jemalloc 时的内存使用情况随时间的变化
摘要
为了优化基于 LibTorch 的多线程推理引擎的性能,我们建议验证 LibTorch 中是否存在过度订阅问题。在我们的案例中,多线程引擎中的所有线程都共享 LibTorch 的全局线程池,这导致了过度订阅问题。通过将线程数设置为 1 来禁用全局线程池,我们解决了这个问题:我们禁用了互操作和操作内全局线程池。为了优化多线程引擎的内存,我们建议使用 Jemalloc 作为内存分配器工具,而不是默认的 malloc 函数。