大型语言模型(LLM)应用的快速增长与能源需求的快速增长有关。根据国际能源署(IEA)的数据,数据中心电力消耗预计到 2026 年将大致翻倍,主要受 AI 驱动。这归因于大规模LLMs的能量密集型训练需求——然而,AI 推理工作负载的增加也起到了作用。例如,与传统搜索查询相比,单个 AI 推理可能消耗大约 10 倍的能源。
作为开发者,我们直接影响到我们的 AI 解决方案能耗。我们可以做出一些技术决策,帮助我们的 AI 解决方案更加环保可持续。最小化计算以提供 LLM 解决方案不是创建可持续 AI 使用的唯一要求。例如,可能需要系统性的改变,如政策干预,但利用节能解决方案是一个重要的因素,并且是我们可以立即采取的有影响力的干预措施。
话虽如此,最小化您的 LLM 推理云计算需求也有助于降低您的云费用,并使您的应用程序更加节能,创造双赢的局面。在这篇博客中,我们将向您介绍创建 LLM 聊天机器人的步骤,通过优化和部署 PyTorch 上的 Llama 3.1 模型,量化特定架构决策的计算效率优势。
我们将评估什么?
对于这篇博客,我们的目标是创建一个沉浸式幻想故事讲述应用,用户可以通过与生成式 AI 聊天进入幻想世界。第一个地点是邪恶之地,让人们可以扮演角色在翡翠城周围漫步,并实时观察风景和场景。我们将通过聊天机器人和自定义系统提示来实现这一点。
我们将评估LLM在 CPU 上的性能。您可以在这里看到 CPU 与 GPU 推理的优势。一般来说,对于 10B 参数或更少的模型,如 Llama 系列,在云中使用 CPU 进行LLM推理是一个很好的选择。
我们还将使用基于 Arm 的 CPU,特别是 AWS Graviton 系列。根据研究,基于 Arm 的 Graviton3 服务器可以提供内置的 67.6%更低的工作负载碳强度。虽然这项研究基于模拟,但它是一个展示最小化我们应用能源需求的可能性的良好开端。
首先,您将了解如何在 PyTorch 上运行一个简单的LLM聊天机器人,然后探索三种优化应用程序计算效率的技术:
- 模型优化:利用 4 位量化及添加 KleidiAI 内核。
- 简化优化:实现向量数据库以处理常见查询。
- 架构优化:采用无服务器架构。
让我们开始吧。
在 AWS Graviton4 上通过 PyTorch 运行 Llama-3.1
为了最大化能源效率,我们将仅使用支持此 LLM 聊天机器人所需的最小服务器资源。对于这个 Llama-3.1 80 亿参数模型,需要 16 核、64GB RAM 和 50GB 的磁盘空间。我们将使用符合这些规格的 r8g.4xlarge Graviton4 实例,它运行 Ubuntu 24.04。
启动这个 EC2 实例,连接到它,并开始安装需求:
sudo apt-get update
sudo apt install gcc g++ build-essential python3-pip python3-venv google-perftools -y
然后,安装 Torchchat,这是 PyTorch 团队开发的库,它使得 LLMs 能够在多设备上运行:
git clone https://github.com/pytorch/torchchat.git
cd torchchat
python3 -m venv .venv
source .venv/bin/activate
./install/install_requirements.sh
接下来,通过 CLI 安装来自 Hugging Face 的 Llama-3.1-8b 模型。您首先需要在您的 HF 账户上创建一个 Hugging Face 访问令牌。这将下载 16GB 模型到您的实例,可能需要几分钟:
pip install -U "huggingface_hub[cli]"
huggingface-cli login
<enter your access token when prompted>
python torchchat.py export llama3.1 --output-dso-path exportedModels/llama3.1.so --device cpu --max-seq-length 1024
现在您可以运行LLM模型了,添加一个系统提示作为 Wicked 世界中的引导型讲故事者:
LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libtcmalloc.so.4 TORCHINDUCTOR_CPP_WRAPPER=1 TORCHINDUCTOR_FREEZING=1 OMP_NUM_THREADS=16 python torchchat.py generate llama3.1 --device cpu --chat
输入‘y’以进入系统提示,并输入以下提示:
您是幻想冒险应用的引导型讲故事者。将用户沉浸在 Wicked 的迷人世界中,引导他们通过互动的实时体验在翡翠城。描述生动的景象、动态的场景,并让用户参与到感觉生动且反应灵敏的故事讲述中。允许用户做出选择,塑造他们的旅程,同时保持 Wicked 宇宙的神奇氛围。
然后输入您的用户查询:
我穿过翡翠城的大门,抬头望去
输出将显示在屏幕上,生成第一个标记大约需要 7 秒,每秒不到一个标记。
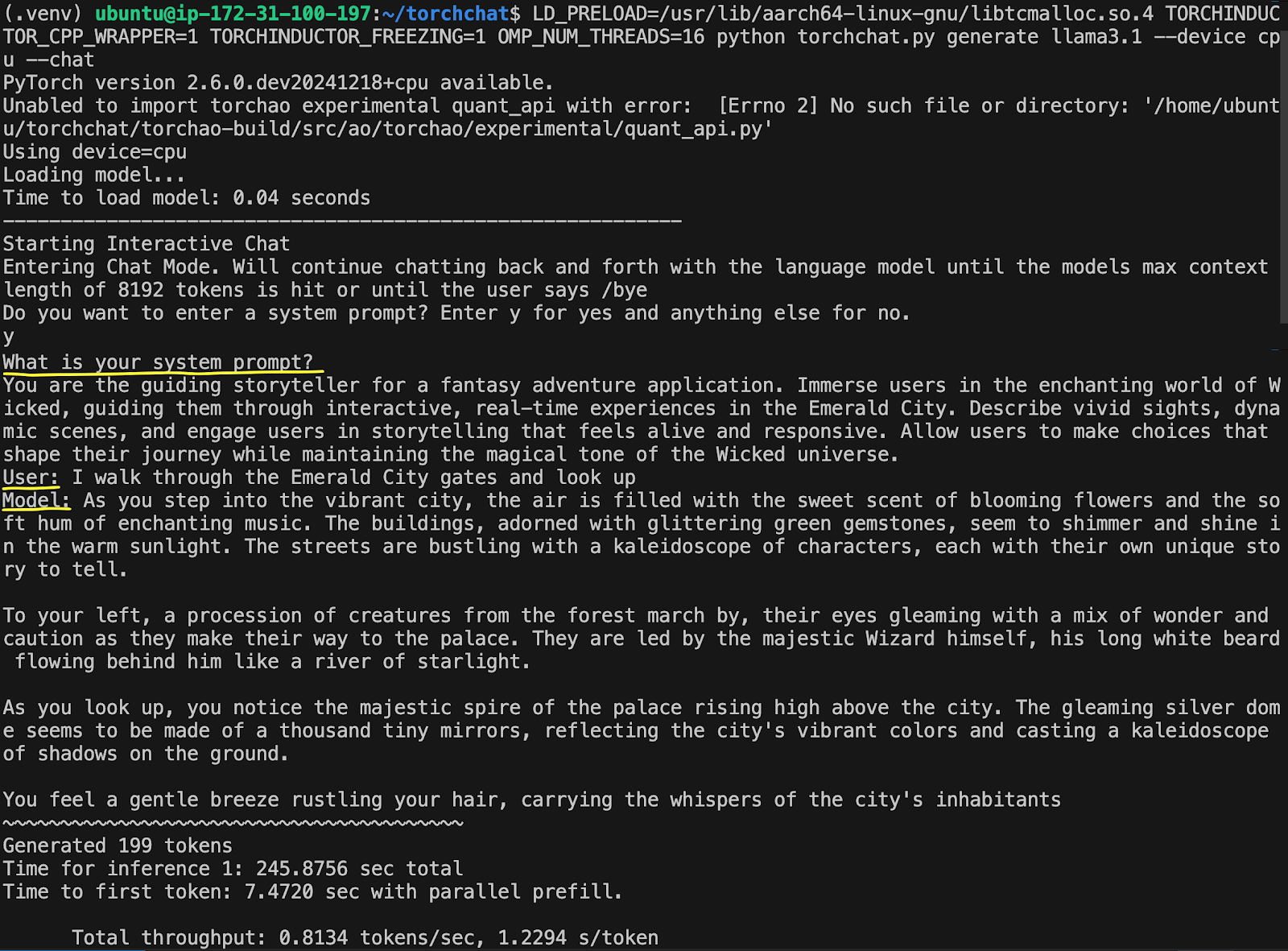
这个例子生成了完整的回复花费了 245 秒,即 4 分钟,速度并不快。我们将首先探讨的第一个优化将加快LLM的生成,减少其计算开销。
优化 1:KleidiAI 和量化
从上述基本实现中,可以进行多种优化。最简单快捷的方法是将模型从 FP16 量化到 INT4。这种方法在牺牲一些精度的同时,将模型大小从 16Gb 减少到大约 4Gb,从而提高了推理速度。
另一种常见的优化是利用 TorchAO(Torch 架构优化),这是一个与 TorchChat 无缝协作的 PyTorch 库,通过各种量化和稀疏化方法来提升模型性能。
最后,我们将使用 Arm KleidiAI 优化。这些是用汇编语言编写的微内核,可以显著提高 Arm CPU 上LLM推理的性能。如果您感兴趣,可以了解更多关于 KleidiAI 内核的工作原理。
要实现这些优化,请启动一个新的 EC2 实例,并按照如何使用 PyTorch 运行大型语言模型(LLM)聊天机器人的说明进行操作。准备好后,运行模型并输入与上述相同的系统提示和用户查询。您将获得显著加快推理速度的结果:首次标记小于 1 秒,每秒约 25 个标记。
这将推理时间从 245 秒缩短到大约 10 秒。这使得服务器在空闲和运行功率密集型推理之间花费更多时间,从而减少了功率消耗。在其他条件相同的情况下,这比非优化应用程序更环保。接下来的两种方法超出了模型推理优化的范畴,通过修改解决方案架构来进一步降低计算负载。
优化 2:使用 FAISS 匹配数据库以处理常见问题
如引言所述,模型推理通常比其他搜索技术计算成本更高。如果能够自动响应用户的常见查询而无需执行LLM推理会怎样?使用查询/响应数据库是绕过LLM推理并高效响应的一种选择。对于这个交互式叙事应用程序,可以想象关于特定角色、世界本身以及聊天机器人能做什么和不能做什么的规则等常见问题,这些都可以有预先生成的答案。
然而,传统的精确匹配数据库并不足够,因为用户可以用多种方式表达相同的查询。询问聊天机器人的能力可能会得到相同的答案,但表达方式不同:
- “你有什么能力?”
- “告诉我你能做什么。”
- “我该如何与你互动?”
通过实现语义搜索,通过理解用户的意图将用户的查询与最相关的预生成答案匹配,从而解决了这个问题。FAISS 库是实现语义搜索的一个很好的选择。
这种方法的计算节省取决于三个因素:
- 可以通过语义搜索而不是LLM来服务的用户查询的百分比。
- 运行LLM推理的计算成本。
- 运行语义搜索的计算成本。
节约方程为:
Computational_savings = (% of queries) * (LLM_cost – search_cost).
这种架构在几种情况下是有意义的。一种是如果您的系统有与许多重复问题相关的常见查询。另一种是具有数十万条入站查询的大规模系统,其中小比例的节省可以累积成有意义的改变。最后,如果与搜索成本相比,您的LLM推理计算成本非常高,尤其是在较大的参数模型中。
最终的优化方法是过渡到无服务器架构。
优化 3:无服务器方法
使用无服务器架构的原因有很多,其中之一是只需为活跃的计算时间付费,并消除空闲服务器的成本。空闲服务器需要消耗相当数量的电力来保持运行,在等待时浪费能源。
这种成本效率使其成为一种本质上更环保的架构,因为它减少了浪费的能源消耗。此外,多个应用程序共享底层物理基础设施,提高了资源效率。
要设置自己的无服务器聊天机器人,您首先需要使用包含 Lambda 入口函数 lambda_handler 的 Python 脚本容器化量化后的 Llama-3.1-8b,并使用 TorchChat、TorchAO 和 Arm KleidiAI 优化。一种部署选项是将容器上传到 AWS ECR,并将其附加到 Lambda 函数。然后设置 API Gateway WebSocket 或类似服务,通过 API 与 Lambda 交互。
使用无服务器架构托管LLM有两个显著的局限性,首先是令牌生成速度。回想一下,基于服务器的方案在 KleidiAI 优化下大约每秒可以生成 25 个令牌。无服务器方案的速度慢了一个数量级,我们测量的大约是每秒 2.5 个令牌。这种限制主要源于 Lambda 函数部署到 Graviton2 服务器上。当部署转移到具有更多 SIMD 通道的 CPU,如 Graviton3 和 Graviton4 时,每秒生成的令牌数应该会随着时间的推移而增加。在此处了解 Graviton3 中引入的架构优化,通过 Arm Neoverse-V1 CPU。
这种较慢的速度限制了无服务器LLM架构的可行用例,但在某些情况下,这可以被视为一种优势。在我们的互动叙事用例中,缓慢地揭示信息可以营造出沉浸感,营造期待并模仿实时叙述。其他用例包括:
- 引导冥想应用,缓慢、轻松的词语传递
- 虚拟朋友参与深思的对话,或治疗性的对话。
- 诗歌创作或互动艺术,通过缓慢的呈现方式创造一种沉思的美学。
在适当的应用中,用户可能会从较慢的 token 生成中获得更好的体验。当优先考虑更可持续的解决方案时,限制最终会变成优势。作为一个类比,现代电影常见的批评是过度依赖视觉效果导致故事情节不如老电影引人入胜。VFX 的成本限制意味着老电影不得不创作吸引人的对话,利用熟练的摄影角度和人物定位来完全吸引观众。同样,如果做得周到,专注于可持续的 AI 架构可以带来更吸引人、更沉浸式的体验。
第二个无服务器限制是LLM推理的冷启动时间约为 50 秒。如果实施不当,用户等待 50 秒且没有其他选择时可能会离开应用。您可以通过几个设计技巧在我们的基于 Wicked 的经验中将这一限制转变为一个特性:
- 创建一个“序章体验”,引导用户通过硬编码的问题和答案,为他们即将进入翡翠城做好准备,并收集信息以塑造他们即将到来的体验。
- 将等待时间设为倒计时计时器,展示故事或世界构建的硬编码文本片段。一个角色,如巫师,可以用碎片化的台词与用户沟通,以建立悬念并引导用户进入正确的思维模式。
- 创建一个包含电影或音乐剧音乐的音频简介,以及旋转的视觉效果,将用户带入邪恶世界的氛围中。
跳出思维定势
实施以可持续性为导向的解决方案架构不仅包括优化您的 AI 推理,还超越了这一点。了解用户如何与您的系统交互,并相应地调整您的实现。始终优化每秒快速标记或首次标记的时间将隐藏参与功能的机会。
话虽如此,在可能的情况下,您应该利用简单的优化。使用 TorchAO 和 Arm KleidiAI 微内核是加快您的LLM聊天机器人速度的好方法。通过结合创新解决方案架构并在可能的地方进行优化,您可以构建更多基于LLM的可持续应用程序。祝您编码愉快!