最近,我们展示了如何使用 FSDP 和选择性激活检查点技术,在 A100 GPU 上训练 7B 模型,实现了 57%的 MFU(模型浮点运算利用率)。我们还展示了如何训练一个高质量的模型,并将其开源为 Granite 7B 基础模型,在 Hugging Face Hub 上以 Apache v2.0 许可证发布。
我们继续利用 torch.compile 来提高 GPU 的利用率。通过使用 torch.compile 和我们之前工作的选择性激活检查点技术,我们在 A100 GPU 上实现了 7B 模型的 68% MFU!torch.compile 在各种模型大小上提高了训练 MFU 10%到 23%。
本文分为三个部分:(1)使用 torch.compile 训练时解决的挑战,(2)编译与不编译的数值一致性,(3)MFU 报告。
我们开源了所有代码,并在 fms-fsdp 仓库中进行了更新。我们还在与 Meta 的 PyTorch 团队合作,将这些贡献给新发布的 torch titan 仓库以进行预训练。
使用 torch.compile 的挑战
torch.compile 是一种图编译技术,可以提高 GPU 利用率。关于 torch compile 的工作原理,我们建议读者参考最近的 PyTorch 论文和相关教程。使 torch.compile 表现良好的关键挑战是(或消除)图断开。我们最初从 Meta 提供的 Llama 实现开始,但编译它导致了太多的图断开,从而降低了训练吞吐量。
模型架构的几个部分需要修复,其中最重要的是位置嵌入层(RoPE)。典型的 RoPE 实现使用复数,这在测试时的 torch.compile 中不受支持。我们使用 einops 实现了 RoPE,同时保持了与原始模型架构实现的兼容性。我们必须正确缓存频率,以避免在 RoPE 实现中出现图断开。
编译 FSDP 模型确实会导致图断裂,但 Meta 的 PyTorch 团队正在努力解决这个问题。然而,截至 PyTorch 2.3 版本,这些图断裂发生在 FSDP 单元边界,并不会显著影响吞吐量。
当使用自定义内核时,我们需要通过将内核的 API 暴露给 torch.compile 来包装每个内核。这涉及到指出哪些参数被就地修改,如何修改,以及它们的返回值将基于输入具有什么形状和步长。在我们的案例中,SDPA Flash 注意力已经适当集成,我们能够使该内核与 torch.compile 一起工作,没有出现图断裂。
我们还注意到,当将数据量从 2T 增加到 6T 个标记时,数据加载器变成了瓶颈。一个关键原因是,我们之前在数据加载器中天真地实现了文档打乱,让每个工作器维护一个打乱后的文档指针列表。
随着数据集的扩大,这些指针列表增长到每个工作者数以万计的条目。在如此规模下维护指针列表变得成本高昂,以至于 CPU 竞争限制了我们的训练吞吐量。我们重新实现了文档洗牌,不再使用任何指针列表,而是使用线性同余发生器。线性同余发生器是一种伪随机数生成算法,它通过人口中的随机游走来提供不重复的采样。
我们利用同样的想法,从有序到洗牌的文档索引生成隐式双射映射。这使得我们可以将那些令人烦恼的数以万计的指针列表缩减为一个整数状态,用于线性同余发生器。这消除了 80%的瓶颈,并显著提升了我们的性能。我们将专门撰写一篇博客,详细介绍我们高效的预训练数据加载器的所有细节。
torch.compile 和 torch.no-compile 的数值对称性
我们之前在训练时观察到编译和未编译选项存在兼容性问题,其中之一与 SDPA 的使用有关。在 Meta 和 IBM 的 PyTorch 团队之间经过几天的紧张调试后,我们成功实现了 PyTorch 编译和未编译模式之间的兼容性。为了记录和验证这种兼容性,我们选取了一个 1.4B 大小的 mini-Llama 模型架构,并在四种变体中对其进行训练,达到 100B 个标记——无编译、无激活检查点编译、选择性激活检查点编译和完整激活检查点编译。
下面我们绘制了这些选项的损失曲线和梯度范数:
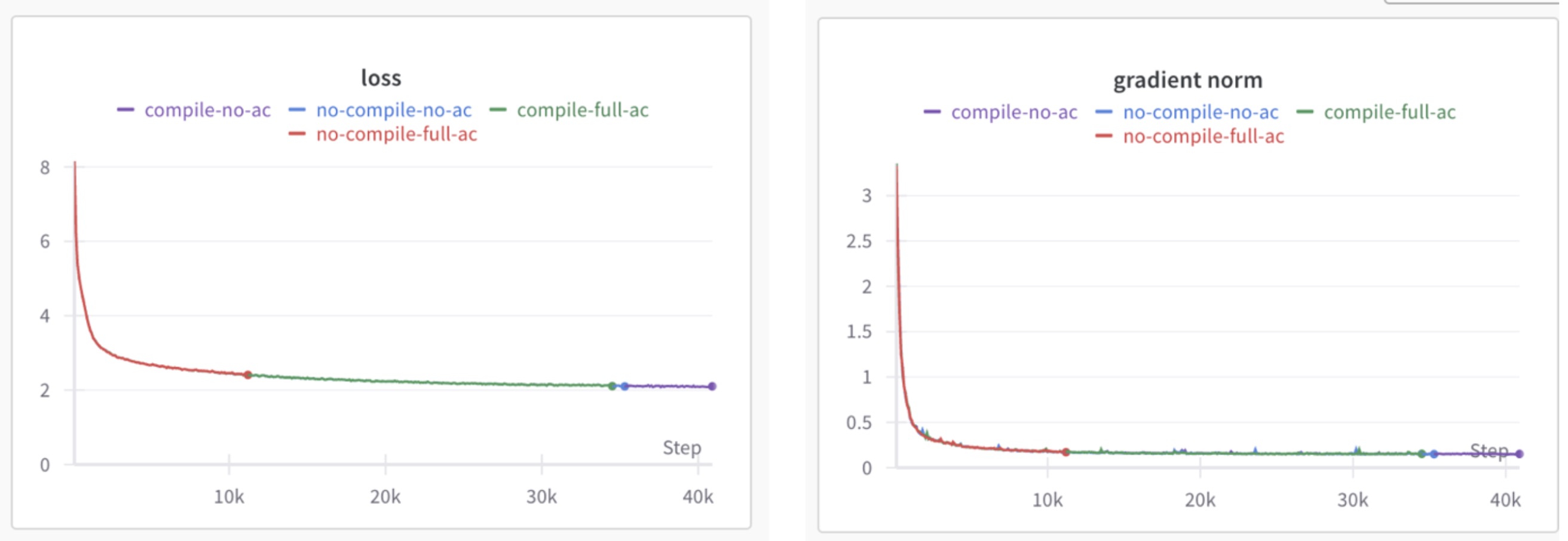
图 1:各种编译选项的损失曲线和梯度范数
此外,我们运行了 lm-evaluation-harness,比较了不同基准上的各种模型得分,并观察到编译和未编译之间没有显著差异,如下所示。

图 2:编译与不编译情况下各种基准之间的 lm-evaluation-harness 比较
从所有这些结果中,我们发现所有编译变体与不编译选项相同,从而证明了编译与不编译之间的等价性。
MFU 报告
最后,就像我们之前的博客一样,我们在两个集群上计算了四种不同模型大小的 MFU。一个集群是 128 个 A100 GPU,节点间连接速度为 400 Gbps,另一个集群是 464 个 H100 GPU,节点间连接速度为 3.2 Tbps。我们除了使用之前博客中提到的选择性激活检查点之外,还使用了编译。以下表格中展示了我们的结果。
| 模型大小 | 批处理大小 | MFU 不编译 | MFU 编译 | 百分比提升(%) |
| 7B | 2 | 0.57 | 0.68 | 20 |
| 13B | 2 | 0.51 | 0.60 | 17 |
| 34B | 2 | 0.47 | 0.54 | 15 |
| 70B | 2 | 0.50 | 0.55 | 10 |
表 1:Llama2 模型架构在 128 个 A100 80GB GPU 上,使用 400Gbps 内部节点互连的编译和无编译的 MFU 结果
| 模型大小 | 批处理大小 | MFU 无编译 | MFU 编译 | 百分比增长 |
| 7B | 2 | 0.37 | 0.45 | 21 |
| 13B | 2 | 0.35 | 0.43 | 23 |
| 34B | 2 | 0.32 | 0.38 | 19 |
| 70B | 2 | 0.32 | 0.38 | 19 |
表 2:在 464 个 H100 80GB GPU 上,对于 Llama2 模型架构,使用编译和无编译的结果
我们还在 448 个 GPU 上使用 Llama2 7B 架构进行了内部生产运行。使用编译和选择性激活检查点,全局批大小为 3.7M,我们在 13 天 10 小时内训练了 4T 个标记!
在训练过程中,数据中心冷却系统不得不启动额外的空调,我们的训练团队也因此被提醒,因为我们非常有效地使用了 GPU ☺
从表格 1 和 2 中可以观察到的一个关键点是,MFU 数值并不与模型大小呈线性关系。我们正在积极调查两种可能的解释,一是随着模型大小的增加以及需要启用张量并行以更有效地使用 GPU 时,FSDP 的可扩展性,另一个是批大小,可以进一步增加以获得更好的 MFU。我们计划探索 FSDP v2 和选择性操作检查点,以及张量并行功能,以研究 FSDP 与模型大小的扩展规律。
未来工作
我们计划开始测试即将作为 PyTorch 2.4 一部分发布的 FSDP v2。FSDP2 提供了按参数分片和选择性操作检查点功能,这可能会提供更好的内存-计算权衡。
我们还与 Meta 的 PyTorch 团队合作,评估新的异步检查点功能,该功能可以通过减少写入检查点的时间来进一步提高 GPU 利用率。
我们正在探索将目前用于推理的各种 Triton 内核扩展到执行反向操作,以在仅推理之外获得速度提升。
终于,随着对 fp8 使用的研究逐渐出现,我们计划探索如何利用这种承诺提供 2 倍加速的新数据类型进一步加速模型训练。
致谢
有多个团队参与了达到这一证明点的工作,我们想感谢 Meta 和 IBM 的各个团队。特别是,我们向 Meta PyTorch 分布式和编译器团队以及 IBM 研究团队表示衷心的感谢。
有多个人在实现 torch.compile 与我们的模型数值等价的努力中发挥了重要作用,我们希望承认参与这一努力的关键人物;Meta 的 Animesh Jain 和 Less Wright,以及 IBM 研究的 Linsong Chu、Davis Wertheimer、Brian Vaughan、Antoni i Viros Martin、Mudhakar Srivatsa 和 Raghu Ganti。
特别感谢 Stas Bekman,他为这篇博客提供了大量的反馈,并帮助改进了它。他们的见解在突出优化训练和探索进一步改进的关键方面非常有价值。