随着发达国家如美国道路每年变化高达 15%,Mapillary 通过将任何摄像头的图像结合成世界的 3D 可视化,满足了保持地图更新的日益增长的需求。Mapillary 的独立和协作方法使任何人都能收集、分享和使用街景图像,以改善地图、发展城市和推进汽车行业。
今天,全世界的人们和组织已经为 Mapillary 的使命贡献了超过 6 亿张图片,该使命是通过图片帮助人们了解世界各地的场所,并使这些数据可供客户和合作伙伴使用,包括世界银行、HERE 和丰田研究院。
Mapillary 的计算机视觉技术以前所未有的方式为地图带来智能,增加了我们对世界的整体理解。Mapillary 在所有图像上以规模运行最先进的语义图像分析和基于图像的 3D 建模。在这篇文章中,我们讨论了 Mapillary Research 的最近两项工作及其在 PyTorch 中的实现——无缝场景分割[1]和原地激活 BatchNorm[2],分别生成全景分割结果和在训练过程中节省高达 50%的 GPU 内存。
无缝场景分割
Github 项目页面:https://github.com/mapillary/seamseg/
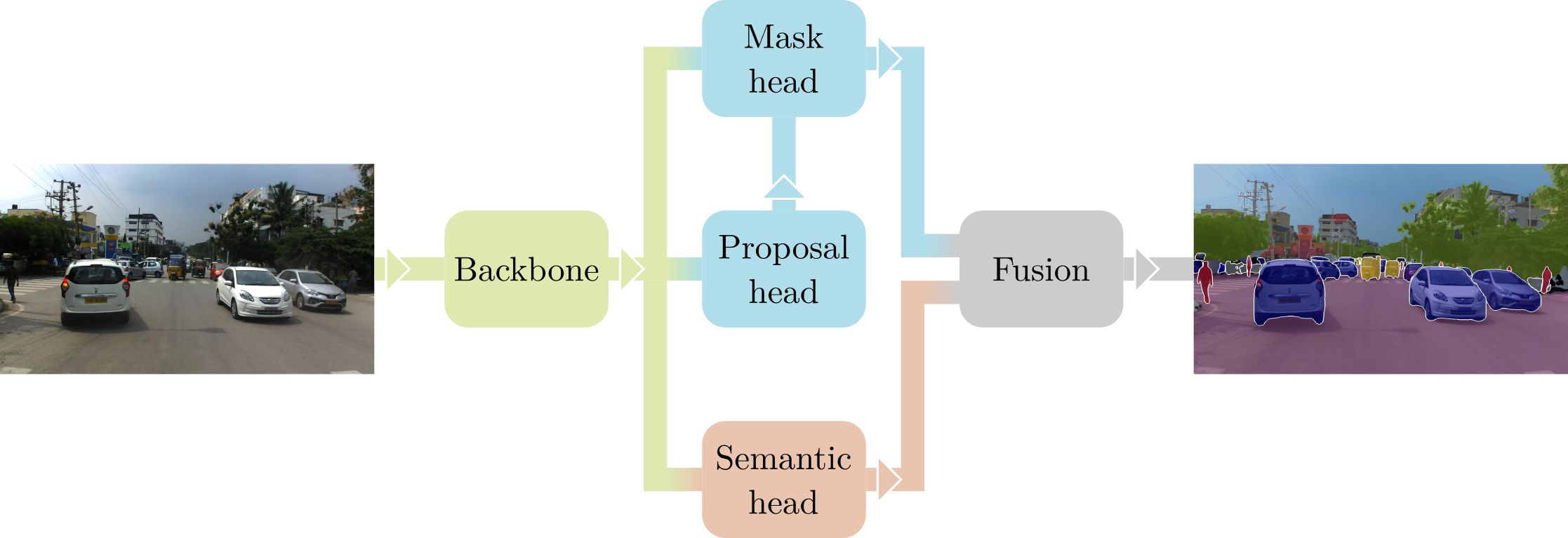
无缝场景分割的目标是从图像中预测一个“全景”分割[3],即每个像素都被分配一个类别 ID,在可能的情况下,还有一个实例 ID 的完整标记。像许多处理实例检测和分割的现代 CNN 一样,我们采用了 Mask R-CNN 框架[4],使用 ResNet50 + FPN[5]作为骨干网络。该架构分为两个阶段:首先,“提案头”在图像上选择一组可能包含对象的候选边界框(即提案);然后,“掩码头”专注于每个提案,预测其类别和分割掩码。这个过程输出的结果是“稀疏”的实例分割,仅覆盖图像中包含可计数对象的区域(例如汽车和行人)。
为了完善我们提出的无缝场景分割的全面方法,我们在 Mask R-CNN 中增加了一个第三阶段。该“语义头”从相同的骨干网络出发,对整个图像进行密集的语义分割,同时也考虑了不可数或无定形的类别(例如道路和天空)。最后,使用简单的非极大值抑制算法将掩码头和语义头的输出融合,以生成最终的全面预测。关于实际网络架构、使用的损失函数和底层数学的详细信息,可以在我们 CVPR 2019 论文的项目网站上找到[1]。
尽管有几个版本的 Mask R-CNN 已经公开,包括用 Caffe2 编写的官方实现,但在 Mapillary,我们决定从头开始使用 PyTorch 构建无缝场景分割,以便对整个流程有完全的控制和理解。在这个过程中,我们遇到了几个主要难题,并不得不想出一些创造性的解决方案,接下来我们将描述这些方案。
处理可变大小的张量
某些设置全景分割网络与传统 CNN 区别的是可变大小的数据普遍存在。事实上,我们处理的大多数数量都无法用固定大小的张量轻松表示:每张图像包含不同数量的对象,提案头可以为每张图像生成不同数量的提案,图像本身也可以有不同的尺寸。虽然这本身并不是问题——可以逐个处理图像——但我们仍然希望尽可能利用批处理级别的并行性。此外,在多个 GPU 上执行分布式训练时, DistributedDataParallel 期望其输入是批处理、均匀大小的张量。
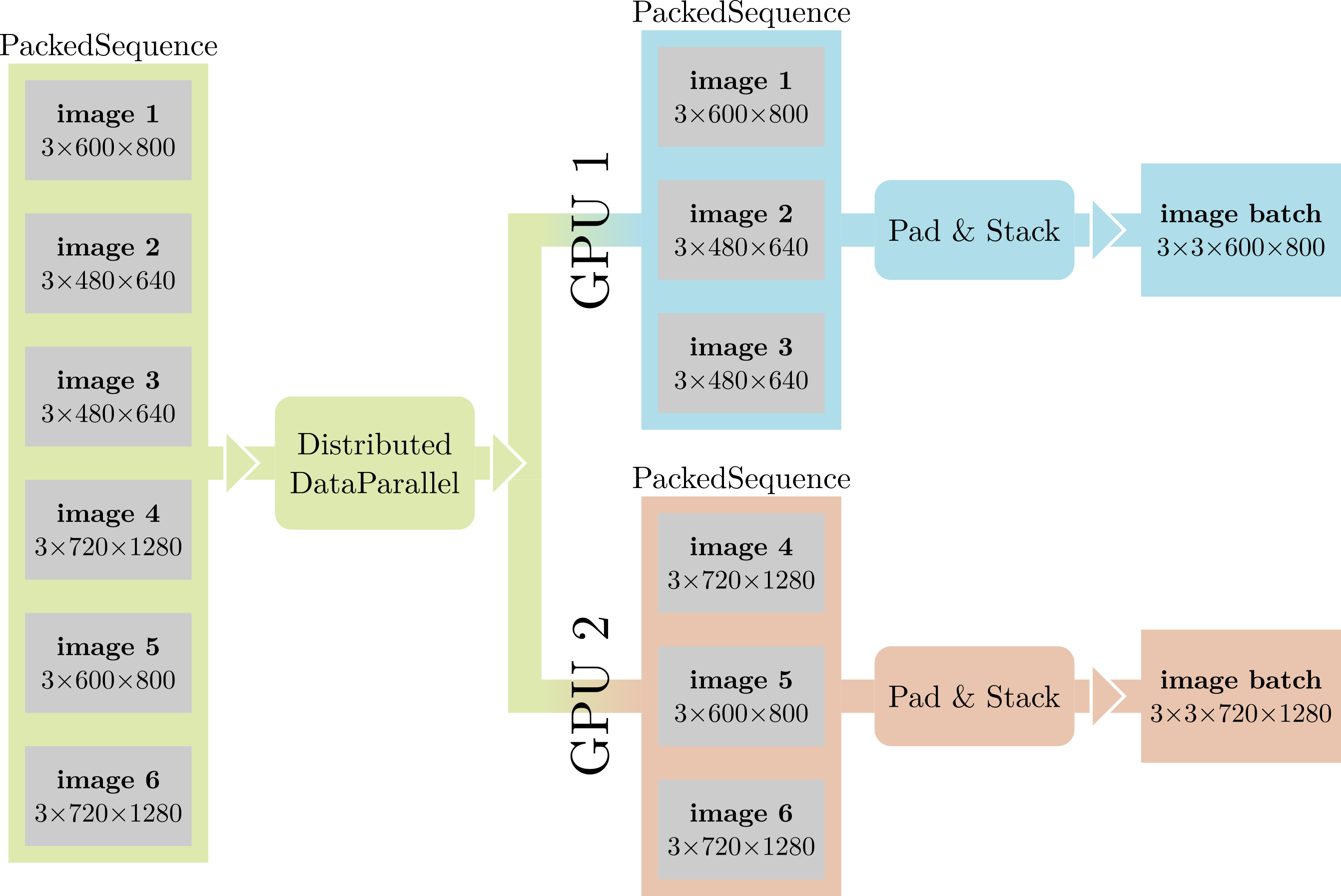
我们解决这些问题的方案是将每个可变大小的张量批次包裹在 PackedSequence 中。 PackedSequence 不过是一个被美化的张量列表类,将其内容标记为“相关”,确保它们具有相同的类型,并提供有用的方法,例如将所有张量移动到特定的设备上等。当执行轻量级操作时,这些操作在批处理级并行化下不会快很多,我们只需在 PackedSequence 的内容上迭代一个 for 循环。当性能至关重要时,例如在网络主体中,我们只需将 PackedSequence 的内容连接起来,根据需要添加零填充(如 RNN 中具有可变长度输入的情况),并跟踪每个张量的原始维度。
PackedSequence 还有助于我们解决上述第二个问题。我们稍微修改 DistributedDataParallel 以识别 PackedSequence 输入,将它们分成大小相等的块,并将内容分布到 GPU 上。
非对称计算图与分布式数据并行
我们网络的另一个可能更为微妙的特性是它可以生成跨 GPU 的非对称计算图。事实上,构成网络的某些模块是“可选的”,也就是说,它们并不总是对所有图像进行计算。例如,当提案头没有输出任何提案时,掩码头根本不会被遍历。如果我们使用多个 GPU 进行训练,这会导致其中一个副本不计算掩码头的梯度。
在 PyTorch 1.1 之前,这会导致崩溃,因此我们必须开发一个解决方案。我们的简单但有效的解决方案是在不需要实际前向传播时计算一个“假的正向传播”,即类似于这样:
def fake_forward():
fake_input = get_correctly_shaped_fake_input()
fake_output = mask_head(fake_input)
fake_loss = fake_output.sum() * 0
return fake_loss
在这里,我们生成一批虚假数据,将其通过掩码头,并返回一个总是将零反向传播到所有参数的损失。
从 PyTorch 1.1 开始,这个解决方案不再需要:通过在构造函数中设置 find_unused_parameters=True , DistributedDataParallel 会被告知识别那些所有副本都没有计算梯度的参数,并正确处理它们。这导致我们的代码库中的一些重大简化!
原地激活批量归一化
Github 项目页面:https://github.com/mapillary/inplace_abn/
大多数研究人员可能会同意,无论他们的研究实验室只有几个还是数千个 GPU,在可用 GPU 资源方面总会有一些限制。在 Mapillary 我们仍然在相对较少的、主要是 12GB Titan X 风格的消费级 GPU 上工作时,我们正在寻找一种解决方案,可以在训练过程中虚拟增强可用内存,这样我们就能在密集标注任务(如语义分割)上获得和推动最先进的结果。原地激活批量归一化使我们能够使用高达 50%更多的内存(计算开销很小),因此它被深度集成到我们所有的当前项目中(包括上面描述的无缝场景分割)。
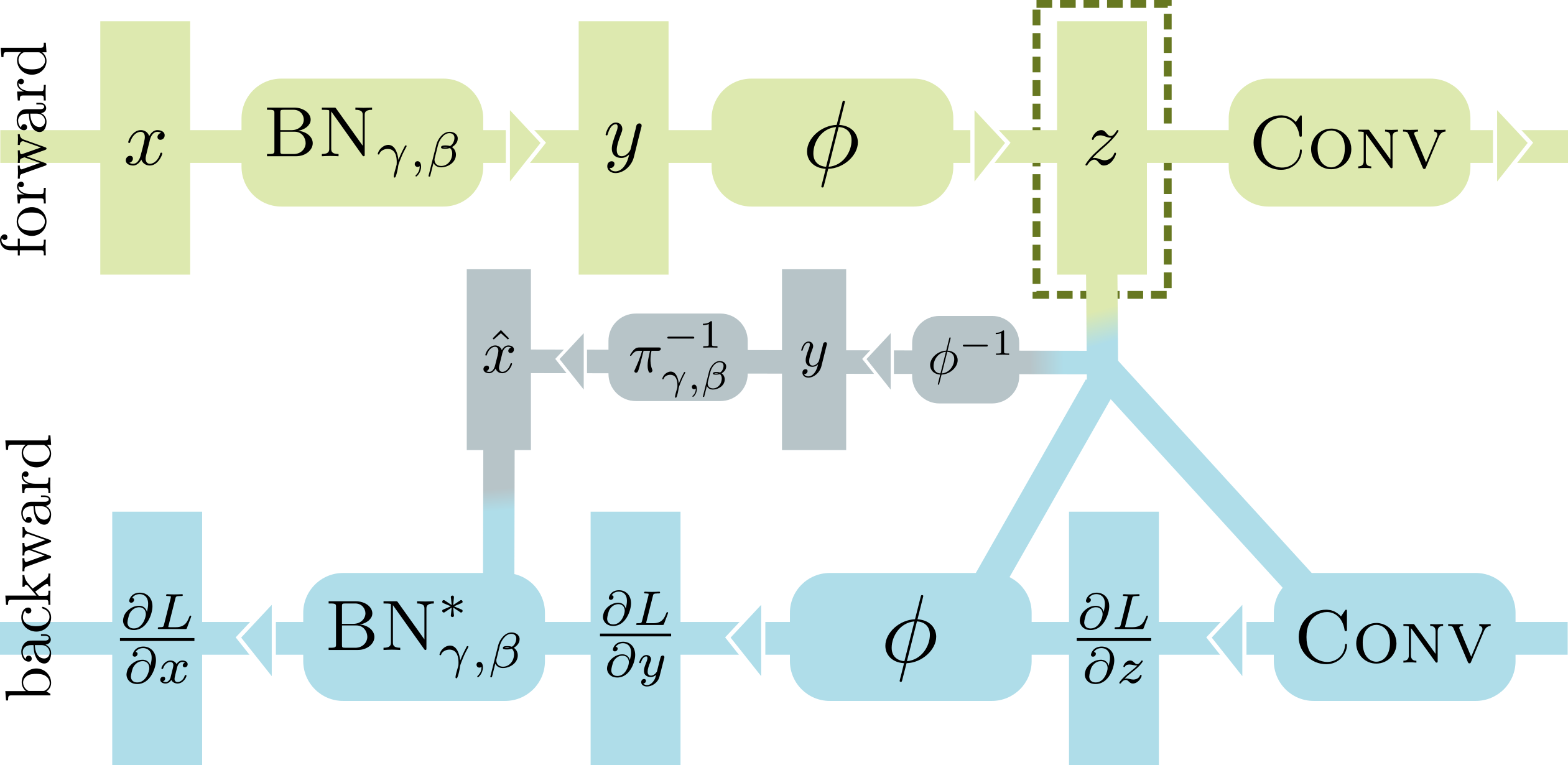
在正向传播过程中处理 BN-激活-卷积序列时,大多数深度学习框架(包括 PyTorch)需要存储两个大缓冲区,即 BN 的输入 x 和 Conv 的输入 z。这是必要的,因为 BN 和 Conv 的反向传播的标准实现依赖于它们的输入来计算梯度。使用 InPlace-ABN 替换 BN-激活序列,我们可以安全地丢弃 x,从而在训练时节省高达 50%的 GPU 内存。为了实现这一点,我们以 BN 的输出 y 来重写 BN 的反向传播,y 反过来通过反转激活函数从 z 重建。
InPlace-ABN 的唯一限制是它需要使用可逆的激活函数,例如 leaky relu 或 elu。除了这一点之外,它可以作为任何网络中 BN+激活模块的直接、即插即用的替代品。我们的原生 CUDA 实现与 PyTorch 的标准 BN 相比,计算开销最小,任何人都可以从这里使用:https://github.com/mapillary/inplace_abn/。
同步 BN 与不对称图和不平衡批次
当在多个 GPU 和/或多个节点上使用同步 SGD 训练网络时,通常的做法是在每个设备上分别计算 BatchNorm 的统计信息。然而,在我们使用语义和全景分割网络的经验中,我们发现跨所有工作者累积均值和方差可以显著提高准确度。这在处理小批量数据时尤其如此,例如在无缝场景分割中,我们使用单个超高清图像进行训练,每个 GPU 一个。
InPlace-ABN 支持在多个 GPU 和多个节点上的同步操作,并且从版本 1.1 开始,这也可以通过标准 PyTorch 库中的 SyncBatchNorm 实现。然而,与 SyncBatchNorm 相比,我们支持一些额外的功能,这对于无缝场景分割尤其重要:不平衡的批量和非对称图。
如前所述,Mask R-CNN 类型的网络自然会引发可变大小的张量。因此,在 InPlace-ABN 中,我们使用此处描述的并行算法的变体来计算同步统计信息,该算法正确地考虑了每个 GPU 可以持有不同数量的样本的事实。PyTorch 的 SyncBatchNorm 目前正在修订以支持这一点,改进的功能将在未来的版本中提供。
非对称图(如上所述)是创建同步 BatchNorm 实现时必须处理的另一个复杂因素。幸运的是,PyTorch 的分布式组功能允许我们将分布式通信限制为工作进程的子集,轻松排除当前不活跃的进程。唯一缺少的部分是,为了创建分布式组,每个进程都需要知道将参与组的所有进程的 ID,即使不是组的成员的进程也需要调用 new_group() 函数。在 InPlace-ABN 中,我们使用类似此函数的方法来处理它:
import torch
import torch.distributed as distributed
def active_group(active):
"""Initialize a distributed group where each process can independently decide whether to participate or not"""
world_size = distributed.get_world_size()
rank = distributed.get_rank()
# Gather active status from all workers
active = torch.tensor(rank if active else -1, dtype=torch.long, device=torch.cuda.current_device())
active_workers = torch.empty(world_size, dtype=torch.long, device=torch.cuda.current_device())
distributed.all_gather(list(active_workers.unbind(0)), active)
# Create group
active_workers = [int(i) for i in active_workers.tolist() if i != -1]
group = distributed.new_group(active_workers)
return group
每个进程,包括非活动进程,都通过 all_gather 调用将其状态传达给所有其他进程,然后使用共享信息创建分布式组。在实际实现中,我们还包括了对组的缓存机制,因为 new_group() 通常在每个批次中调用过于昂贵。
参考文献列表
[1] 无缝场景分割;洛伦佐·波尔齐,塞缪尔·罗塔·布洛,亚历山大·科洛维奇,彼得·康特希德;计算机视觉与模式识别(CVPR),2019
[2] 基于内存优化的 DNN 训练的 In-place Activated BatchNorm;塞缪尔·罗塔·布洛,洛伦佐·波尔齐,彼得·康特希德;计算机视觉与模式识别(CVPR),2018
[3] 全景分割;亚历山大·基里洛夫,凯明·何,罗斯·吉什克,卡尔滕·罗瑟,皮奥特·多勒;计算机视觉与模式识别(CVPR),2019
[4] Mask R-CNN;何凯明,乔治·基奥夏里,皮奥特·多勒,罗斯·吉里克;国际计算机视觉会议(ICCV),2017
[5] 目标检测中的特征金字塔网络;林忠毅,皮奥特·多勒,罗斯·吉里克,何凯明,巴拉特·哈里哈兰,塞尔日·贝隆吉;计算机视觉与模式识别(CVPR),2017