近期研究表明,大型模型训练将有助于提高模型质量。在过去 3 年里,模型规模从具有 1.1 亿参数的 BERT 增长到具有一万万亿参数的 Megatron-2,增长了 1 万倍。然而,训练大型 AI 模型并不容易——除了需要大量的计算资源外,软件工程复杂性也是一个挑战。PyTorch 一直在努力构建工具和基础设施,使其更容易。
PyTorch 分布式数据并行是可扩展深度学习的基础,因为它具有鲁棒性和简单性。然而,它要求模型适合一个 GPU。最近的方法,如 DeepSpeed ZeRO 和 FairScale 的完全分片数据并行,通过将模型参数、梯度优化器状态分片到数据并行工作器,同时保持数据并行的简单性,使我们能够打破这一障碍。
在 PyTorch 1.11 版本中,我们添加了对完全分片数据并行(FSDP)的原生支持,目前作为原型功能提供。其实现大量借鉴了 FairScale 版本,同时带来了更简洁的 API 和额外的性能提升。
在 AWS 上进行的 PyTorch FSDP 扩展测试显示,它可以扩展到训练具有 1T 参数的密集模型。我们的实验中实现的性能达到了 AWS 集群上每 A100 GPU 84 TFLOPS 的 GPT 1T 模型和每 A100 GPU 159 TFLOPS 的 GPT 175B 模型。启用 CPU 卸载后,原生 FSDP 实现也显著提高了与 FairScale 原始版本相比的模型初始化时间。
在未来的 PyTorch 版本中,我们将允许用户在 DDP、ZeRO-1、ZeRO-2 和 FSDP 数据并行版本之间无缝切换,以便用户可以使用统一的 API 通过简单的配置来训练不同规模的模型。
FSDP 是如何工作的
FSDP 是一种数据并行训练,但与传统数据并行不同,它将所有这些状态(参数、梯度、优化器状态)分片到数据并行工作进程中,并且可以选择将分片后的模型参数卸载到 CPU 上。
下图展示了 FSDP 如何为 2 个数据并行进程工作:
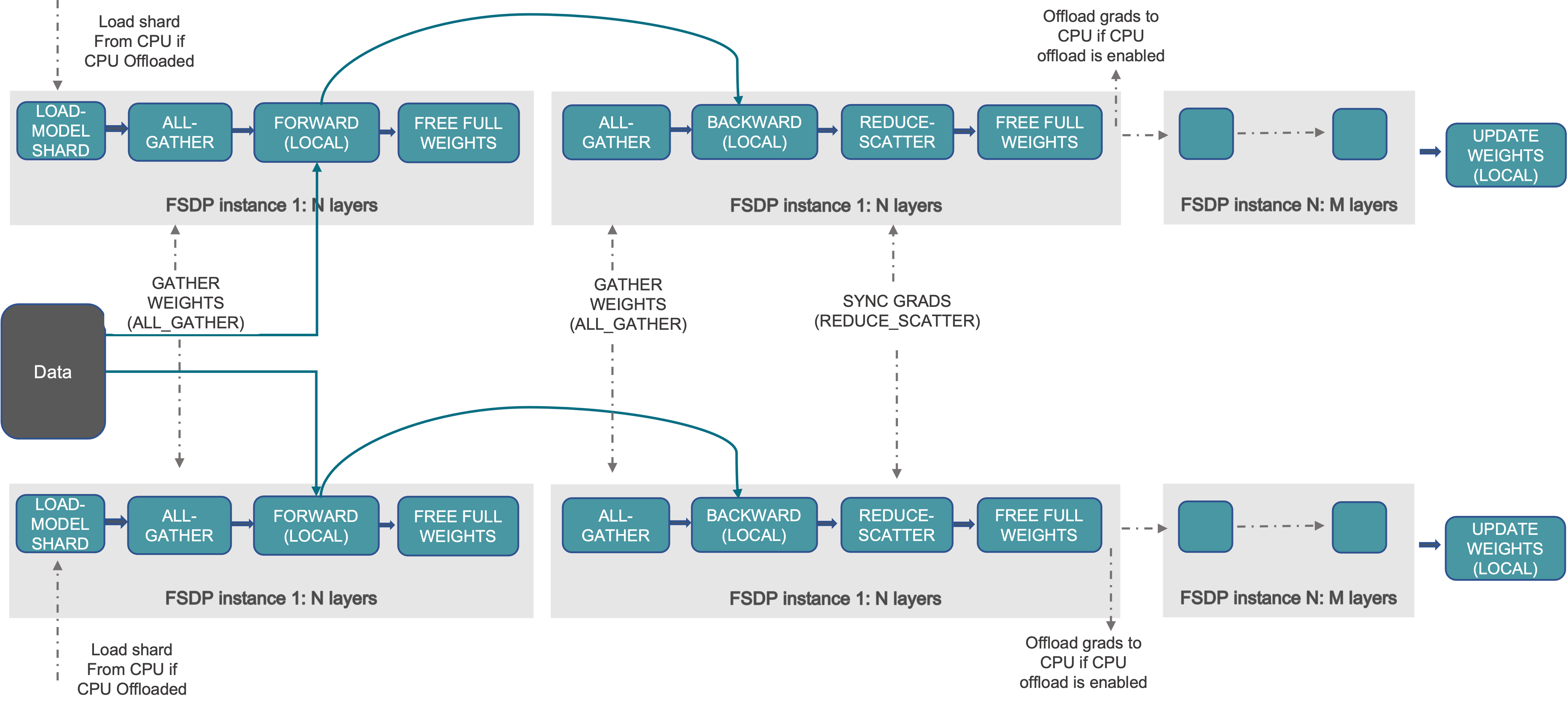
图 1. FSDP 工作流程
通常,模型层以嵌套的方式用 FSDP 包装,这样在正向或反向计算过程中,只需要将单个 FSDP 实例中的层参数收集到单个设备上。收集到的完整参数将在计算后立即释放,释放的内存可以用于下一层的计算。通过这种方式,可以节省峰值 GPU 内存,从而可以将训练扩展到使用更大的模型大小或更大的批量大小。为了进一步提高内存效率,当实例在计算中不活跃时,FSDP 可以将参数、梯度、优化器状态卸载到 CPU 上。
在 PyTorch 中使用 FSDP
使用 PyTorch FSDP 包装模型有两种方式。自动包装是 DDP 的即插即用替代品;手动包装需要对模型定义代码进行最小更改,并能够探索复杂的分片策略。
自动包装
模型层应以嵌套方式使用 FSDP 进行包装,以节省峰值内存并实现通信和计算的叠加。最简单的方法是自动包装,它可以作为 DDP 的即插即用替代品,而无需更改其余代码。
fsdp_auto_wrap_policy 参数允许指定一个可调用的函数,以递归地使用 FSDP 包装层。PyTorch FSDP 提供的 default_auto_wrap_policy 函数会递归地包装参数数量大于 100M 的层。您可以根据需要提供自己的包装策略。自定义包装策略的示例可以在 FSDP API 文档中查看。
此外,可以可选地配置 cpu_offload,当这些参数在计算中不被使用时,将包装的参数卸载到 CPU。这可以在数据在主机和设备之间传输的开销的代价下进一步提高内存效率。
下面的示例展示了如何使用自动包装来包装 FSDP。
from torch.distributed.fsdp import (
FullyShardedDataParallel,
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
default_auto_wrap_policy,
)
import torch.nn as nn
class model(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(8, 4)
self.layer2 = nn.Linear(4, 16)
self.layer3 = nn.Linear(16, 4)
model = DistributedDataParallel(model())
fsdp_model = FullyShardedDataParallel(
model(),
fsdp_auto_wrap_policy=default_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True),
)
手动包装
通过选择性应用 wrap 到模型的某些部分,手动包装可以用来探索复杂的分片策略。整体设置可以通过 enable_wrap()上下文管理器传递。
from torch.distributed.fsdp import (
FullyShardedDataParallel,
CPUOffload,
)
from torch.distributed.fsdp.wrap import (
enable_wrap,
wrap,
)
import torch.nn as nn
from typing import Dict
class model(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = wrap(nn.Linear(8, 4))
self.layer2 = nn.Linear(4, 16)
self.layer3 = wrap(nn.Linear(16, 4))
wrapper_kwargs = Dict(cpu_offload=CPUOffload(offload_params=True))
with enable_wrap(wrapper_cls=FullyShardedDataParallel, **wrapper_kwargs):
fsdp_model = wrap(model())
使用上述两种方法之一用 FSDP 包装模型后,模型可以像本地训练一样进行训练,如下所示:
optim = torch.optim.Adam(fsdp_model.parameters(), lr=0.0001)
for sample, label in next_batch():
out = fsdp_model(input)
loss = criterion(out, label)
loss.backward()
optim.step()
基准测试结果
我们在 AWS 集群上对 175B 和 1T GPT 模型进行了广泛的扩展测试,使用 PyTorch FSDP。每个集群节点都是一个具有 8 个 NVIDIA A100-SXM4-40GB GPU 的实例,节点间通过 AWS 弹性网络适配器(EFA)以 400 Gbps 的网络带宽连接。
GPT 模型使用 minGPT 实现。用于基准测试的输入数据集是随机生成的。所有实验均在 50K 词汇量、fp16 精度和 SGD 优化器下运行。
| Model | 层数数量 | 隐藏层大小 | 注意力头数 | 模型大小,数十亿参数 |
|---|---|---|---|---|
| GPT 175B | 96 | 12288 | 96 | 175 |
| GPT 1T | 128 | 25600 | 160 | 1008 |
在实验中除了使用 FSDP 的参数 CPU 卸载外,还应用了 PyTorch 中的激活检查点功能进行测试。
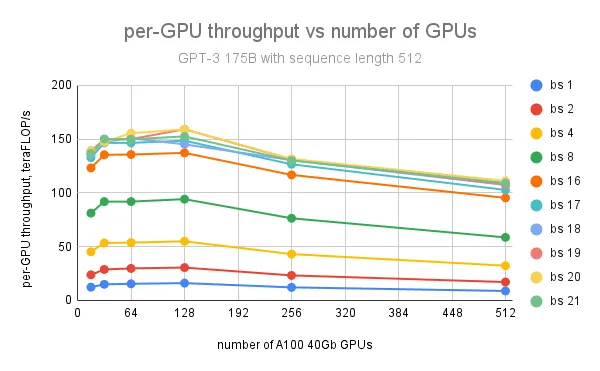
GPT 175B 模型的每张 GPU 最大吞吐量为 159 teraFLOP/s(占 NVIDIA A100 峰值理论性能的 51%,即 312 teraFLOP/s/GPU),在 128 张 GPU 上,通过批量大小为 20 和序列长度为 512 实现;进一步增加 GPU 数量会导致每张 GPU 的吞吐量下降,因为节点间的通信量越来越大。
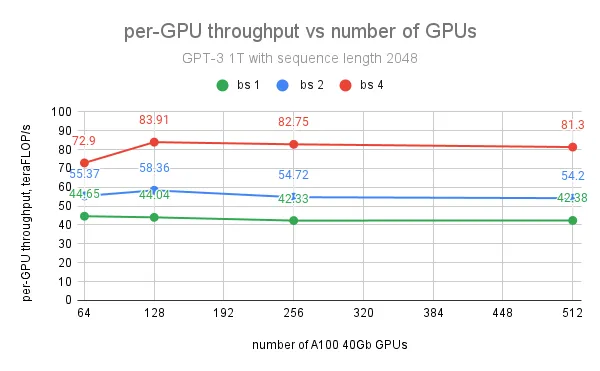
对于 GPT 1T 模型,每张 GPU 的最大吞吐量为 84 teraFLOP/s(占峰值 teraflop/s 的 27%),在 128 张 GPU 上,通过批量大小为 4 和序列长度为 2048 实现。然而,进一步增加 GPU 数量对每张 GPU 的吞吐量影响不大,因为我们观察到 1T 模型训练的最大瓶颈不是通信,而是当 GPU 内存达到极限时缓慢的 CUDA 缓存分配器。使用具有更大内存容量的 A100 80G GPU 将主要解决这个问题,并有助于扩大批量大小以实现更高的吞吐量。
未来工作
在下一个测试版中,我们计划添加高效的分布式模型/状态检查点 API、支持大型模型材料化的元设备以及 FSDP 计算和通信中的混合精度支持。我们还将使在新 API 中切换 DDP、ZeRO1、ZeRO2 和 FSDP 数据并行版本变得更加容易。为了进一步提高 FSDP 性能,还计划减少内存碎片和改进通信效率。
FSDP 两个版本的历史点滴
2021 年初,FairScale FSDP 作为 FairScale 库的一部分发布。随后,我们开始将 FairScale FSDP 集成到 PyTorch 1.11 中,使其成为生产就绪状态。我们已选择性地将 FairScale FSDP 的关键特性集成并重构,重新设计了用户界面,并进行了性能改进。
在不久的将来,FairScale FSDP 将保留在 FairScale 仓库中用于研究项目,而通用且广泛采用的特性将逐步集成到 PyTorch 中,并相应地加固。
同时,PyTorch FSDP 将更加关注生产准备和长期支持。这包括与生态系统的更好集成以及性能、可用性、可靠性、调试性和可组合性的改进。
致谢
我们要感谢 FairScale FSDP 的作者:Myle Ott、Sam Shleifer、Min Xu、Priya Goyal、Quentin Duval、Vittorio Caggiano、Tingting Markstrum、Anjali Sridhar。感谢微软 DeepSpeed ZeRO 团队开发并推广了分片数据并行技术。感谢 Pavel Belevich、Jessica Choi、Sisil Mehta 在不同集群上使用 PyTorch FSDP 进行实验。感谢 Geeta Chauhan、Mahesh Yadav、Pritam Damania、Dmytro Dzhulgakov 支持这项工作并进行了富有洞察力的讨论。