nvFuser 是为 NVIDIA GPU 设计的深度学习编译器,它自动即时编译快速灵活的内核,以可靠地加速用户的网络。它通过在运行时生成快速的定制“融合”内核,为在 Volta 及后续 CUDA 加速器上运行的深度学习网络提供显著的加速。nvFuser 专门设计来满足 PyTorch 社区的独特需求,并支持具有不同形状和步长的动态输入的多种网络架构和程序。在这篇博客文章中,我们将介绍 nvFuser 及其当前的使用方法,展示它在 HuggingFace 和 TIMM 模型上获得的显著性能提升,并展望 nvFuser 在 PyTorch 1.13 及以后的未来。如果您想了解更多关于融合如何提高深度学习网络训练速度的细节和原因,请参阅我们之前在 GTC 2022 和 GTC 2021 上关于 nvFuser 的演讲。nvFuser 依赖于 PyTorch 操作的图表示来优化和加速。由于 PyTorch 具有急切执行模型,用户运行的 PyTorch 操作不能作为一个整体程序直接被像 nvFuser 这样的系统优化。 因此,用户必须使用建立在 nvFuser 之上的系统,这些系统能够捕获用户程序并将它们转换为 nvFuser 可以优化的形式。这些高级系统然后将捕获的操作传递给 nvFuser,以便 nvFuser 可以优化用户脚本在 NVIDIA GPU 上的执行。有三个系统用于捕获、翻译并将用户程序传递给 nvFuser 进行优化:
- TorchScript jit.script
- 该系统直接解析注释过的 Python 脚本的部分,将其翻译成自己的表示形式,表示用户正在做什么。然后,该系统对其图应用自己的自动微分版本,并将后续前向和反向图的段落传递给 nvFuser 进行优化。
- FuncTorch
- 这个系统不会直接查看用户的 Python 脚本,而是插入一个机制来捕获正在运行的 PyTorch 操作。我们称这种捕获系统为“跟踪程序获取”,因为我们正在跟踪已经执行的操作。FuncTorch 不执行自己的自动微分,它只是直接跟踪 PyTorch 的 autograd 以获取反向图。
- TorchDynamo
- TorchDynamo 是建立在 FuncTorch 之上的另一种程序获取机制。TorchDynamo 解析用户脚本生成的 Python 字节码,以便选择要使用 FuncTorch 跟踪的部分。TorchDynamo 的好处在于,它能够将装饰器应用于用户的脚本,有效地隔离应该发送给 FuncTorch 的部分,这使得 FuncTorch 更容易成功跟踪复杂的 Python 脚本。
这些系统可供用户直接交互,同时 nvFuser 自动且无缝地优化用户代码的性能关键区域。这些系统自动将解析后的用户程序发送到 nvFuser,以便 nvFuser 可以:
- 分析在 GPU 上运行的运算操作
- 规划这些操作的并行化和优化策略
- 将这些策略应用于生成的 GPU 代码中
- 运行时编译生成的优化 GPU 函数
- 在后续迭代中执行这些 CUDA 内核
需要注意的是,nvFuser 目前还不支持所有 PyTorch 操作,并且还有一些场景正在 nvFuser 中积极改进,相关讨论在此。然而,nvFuser 今天已经支持了许多深度学习性能关键操作,并且支持的操作数量将在后续的 PyTorch 版本中增加。nvFuser 能够为其支持的操作生成高度专业化和优化的 GPU 函数。这意味着 nvFuser 能够为新的 PyTorch 系统如 TorchDynamo 和 FuncTorch 提供动力,将 PyTorch 所知名的可扩展性与无与伦比的性能相结合。
nvFuser 性能
在介绍如何使用 nvFuser 之前,本节将展示 nvFuser 为来自 HuggingFace Transformers 和 PyTorch Image Models (TIMM)存储库的各种模型提供的训练速度提升,并讨论当前 nvFuser 性能中的差距,这些差距目前正在开发中。本节中所有性能数据均使用 NVIDIA A100 40GB GPU 获取,并使用 FuncTorch 单独或与 TorchDynamo 结合使用。
HuggingFace Transformer 性能基准
当与另一个重要优化(稍后详述)结合使用时,nvFuser 可以显著加速 HuggingFace Transformers 的训练。性能提升如图 1 所示,在流行的 HuggingFace Transformer 网络子集上,性能提升范围在 1.12x 到 1.50x 之间。
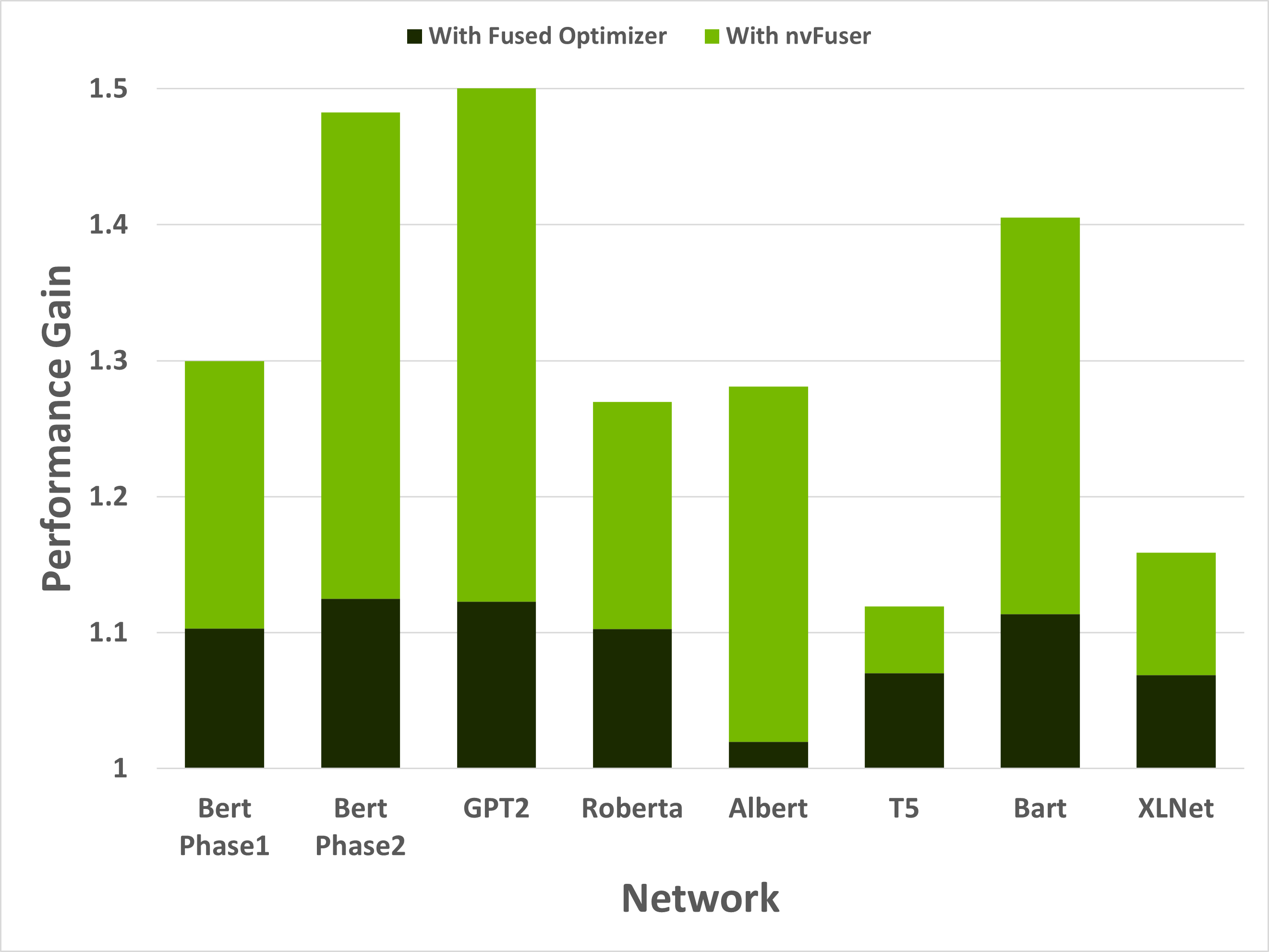
图 1:HuggingFace Transformer 存储库中 8 个训练场景的性能提升。深绿色中的首次性能提升是由于将优化器替换为 NVIDIA Apex 熔合 AdamW 优化器。浅绿色是由于添加了 nvFuser。模型分别以批大小和序列长度 [64, 128]、[8, 512]、[2, 1024]、[64, 128]、[8, 512]、[8, src_seql=512, tgt_seql=128]、[8, src_seql=1024, tgt_seql=128] 和 [8, 512] 运行。所有网络均启用自动混合精度 (AMP) 并使用 dtype=float16 运行。
虽然这些加速效果显著,但重要的是要理解 nvFuser(目前)并没有自动化网络快速运行的所有方面。例如,对于 HuggingFace Transformers,使用 NVIDIA 的 Apex 仓库中的 AdamW 融合优化器是重要的,否则优化器会消耗大量运行时间。使用融合的 AdamW 优化器使网络更快,暴露了下一个主要性能瓶颈——内存绑定操作。这些操作通过 nvFuser 进行优化,提供了另一个大的性能提升。启用融合优化器和 nvFuser 后,这些网络的训练速度提高了 1.12 倍到 1.5 倍。HuggingFace Transformer 模型使用 torch.amp 模块运行。(“amp”代表自动混合精度,有关 PyTorch 中混合精度的详细信息,请参阅“关于 PyTorch 中混合精度,每个用户都应该知道什么”博客文章。)HuggingFace 的 Trainer 中添加了使用 nvFuser 的选项。如果您已安装 TorchDynamo,可以激活它,通过将 torchdynamo = 'nvfuser'传递给 Trainer 类来在 HuggingFace 中启用 nvFuser。 nvFuser 对归一化内核及其在自然语言处理(NLP)模型中常见的相关融合提供了强大的支持,建议用户在他们的 NLP 工作负载中尝试使用 nvFuser。
PyTorch 图像模型(TIMM)基准测试
nvFuser 还可以显著减少 TIMM 网络的训练时间,与急切 PyTorch 相比,可提高 1.3 倍以上,与结合 torch.amp 模块的急切 PyTorch 相比,可提高 1.44 倍以上。图 1 显示了 nvFuser 在不使用 torch.amp 时的加速效果,以及使用 torch.amp 和 NHWC(“通道最后”)和 NCHW(“通道首先”)格式时的加速效果。nvFuser 通过 FuncTorch 跟踪直接集成在 TIMM 中(不使用 TorchDynamo),在运行 TIMM 基准测试或训练脚本时可以通过添加-aot-autograd 命令行参数来使用。
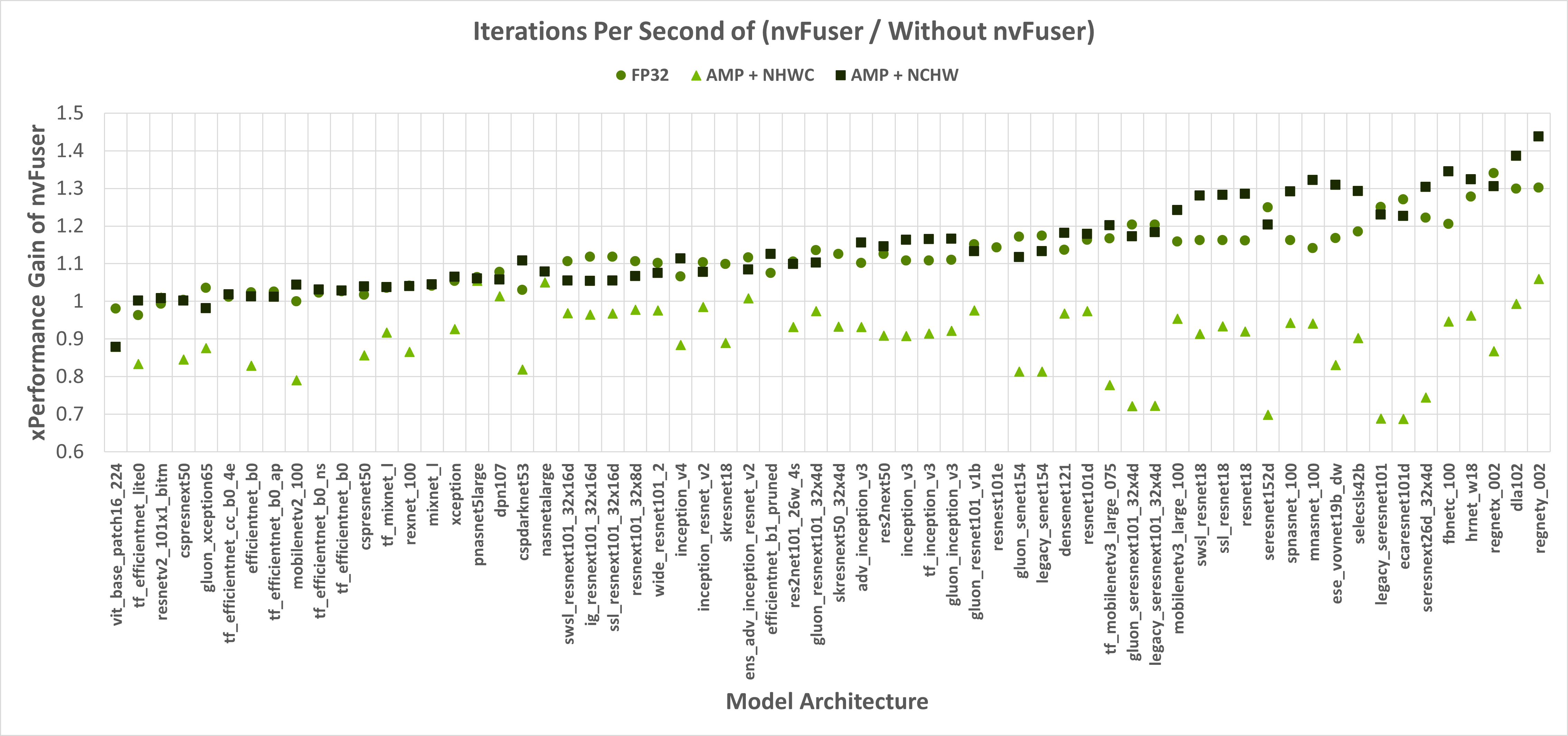
图 1:Y 轴表示 nvFuser 相对于不使用 nvFuser 的性能提升。1.0 的值表示性能无变化,2.0 表示 nvFuser 的速度是两倍,0.5 表示 nvFuser 运行时间是两倍。正方形标记是使用 float16 自动混合精度(AMP)和通道连续输入,圆形标记是 float32 输入,三角形是使用 float16 AMP 和通道最后连续输入。缺失的数据点是由于在跟踪时遇到错误。
运行时使用 float32 精度,nvFuser 在 TIMM 网络上提供 1.12 倍的几何平均(“geomean”)加速,使用 torch.amp 和“channels first”时提供 1.14 倍的 geomean 加速。然而,nvFuser 目前不能加速 torch.amp 和“channels last”训练(.9 倍的 geomean 回归),因此我们建议在这些情况下不要使用它。我们目前正在积极改进“channels last”性能,不久我们将有两个额外的优化策略(用于 channels-last 归一化和快速转置的网格持久优化),我们预计这将提供与“channels first”在 PyTorch 1.13 及以后版本中相当的速度提升。nvFuser 的许多优化也可以帮助推理案例。然而,在 PyTorch 中,当在小型批次大小上运行推理时,性能通常受 CPU 开销限制,nvFuser 无法完全消除或修复。因此,通常推理最重要的优化是在可能的情况下启用 CUDA Graphs。一旦启用 CUDA Graphs,也可以通过 nvFuser 启用融合。推理性能如图 2 和图 3 所示。 推理仅使用 float16 AMP 进行,因为在全 float32 精度下运行推理工作负载是不常见的。
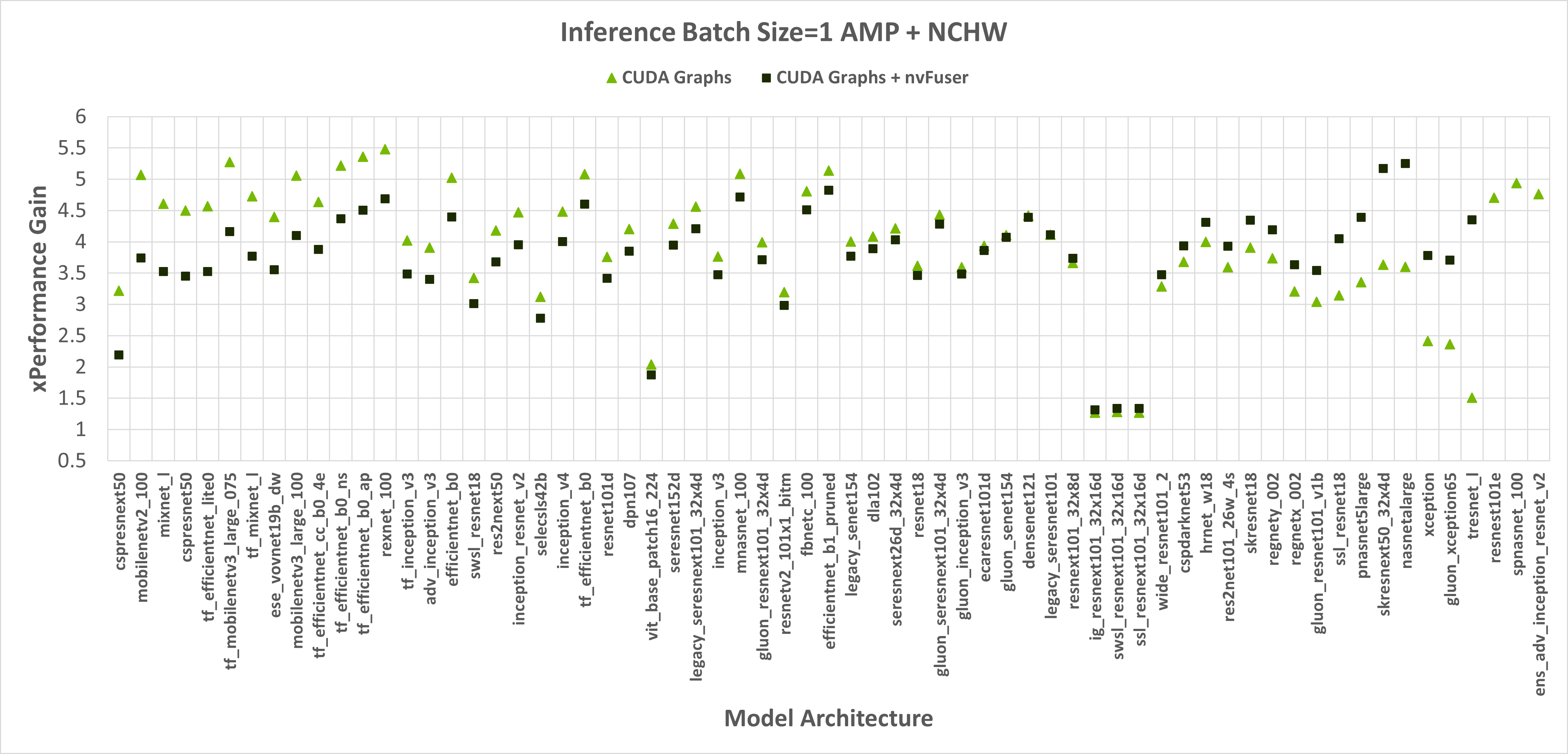
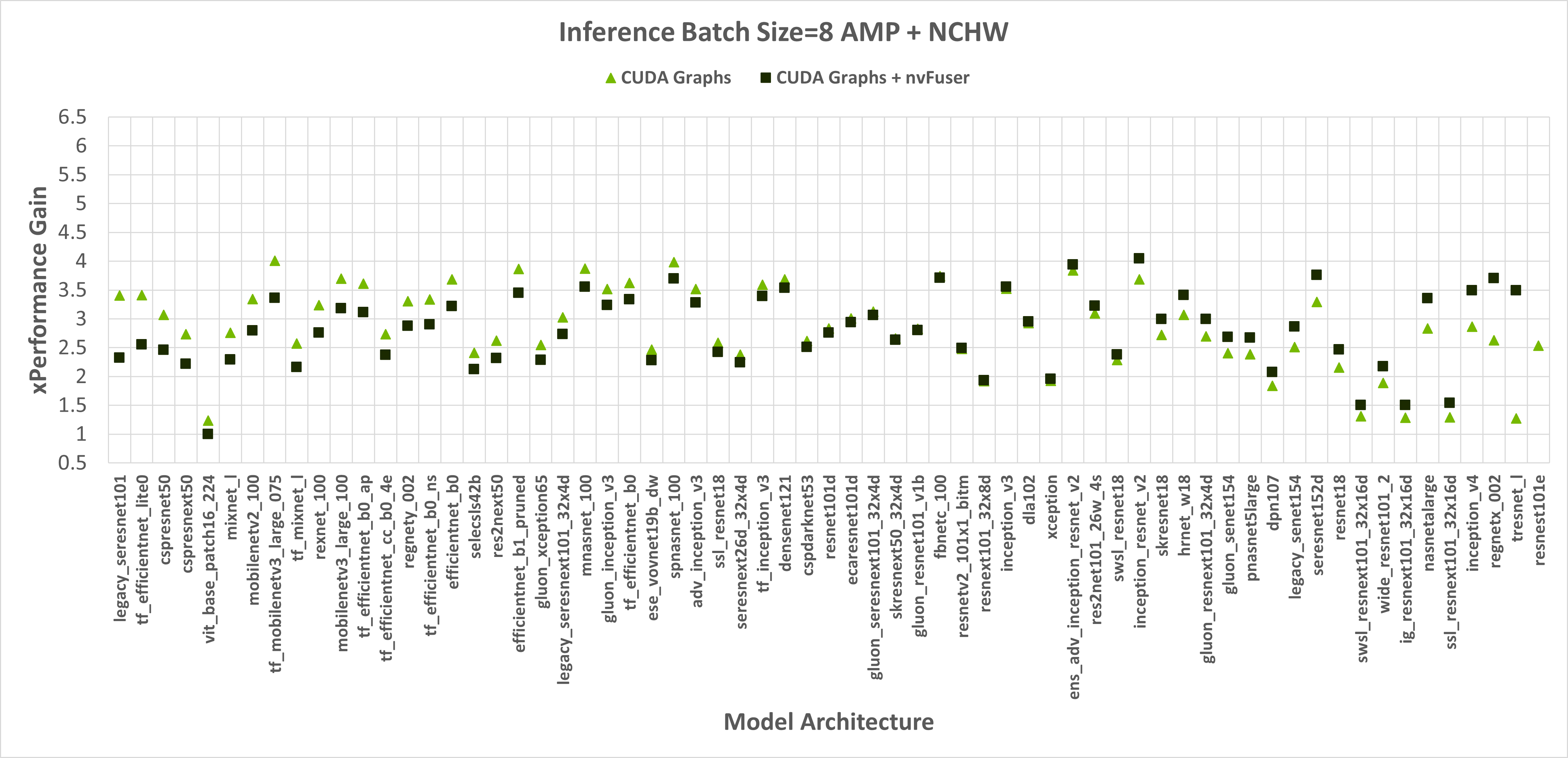
图 2:启用 CUDA Graphs 以及与 nvFuser 结合的 CUDA Graphs 相对于没有 CUDA Graphs 和 nvFuser 的原始 PyTorch 在 TIMM 模型上的性能提升,包括 float16 AMP、通道优先输入以及分别为 1 和 8 的批量大小。CUDA Graphs 的几何平均速度提升为 2.74 倍,CUDA Graphs + nvFuser 为 2.71 倍。nvFuser 提供了最大回归 0.68 倍和最大性能提升 2.74 倍(相对于没有 nvFuser 的 CUDA Graphs)。性能提升是相对于没有 CUDA Graphs 和没有 nvFuser 时 PyTorch 每次迭代的平均时间来衡量的。模型按 nvFuser 提供的额外性能进行排序。
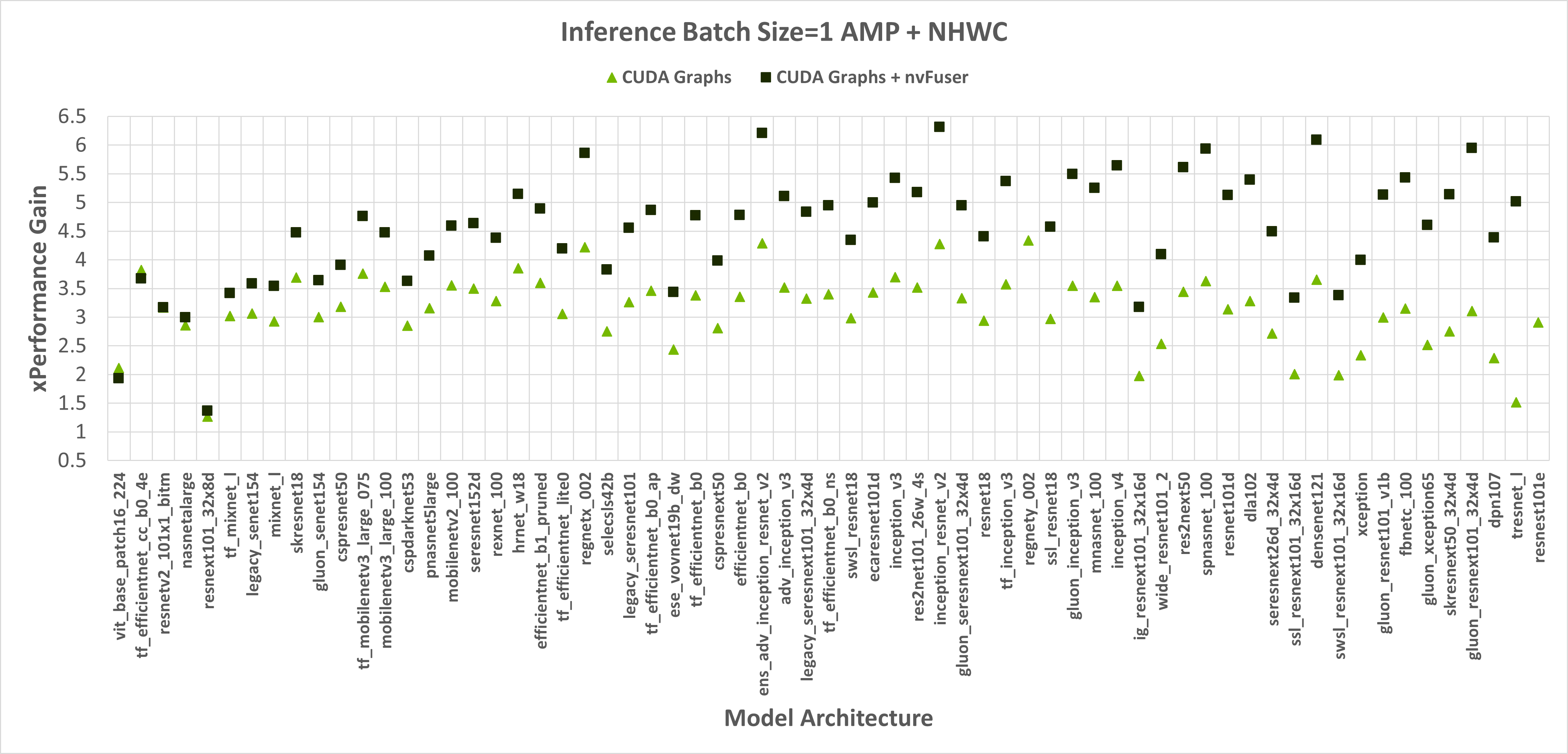
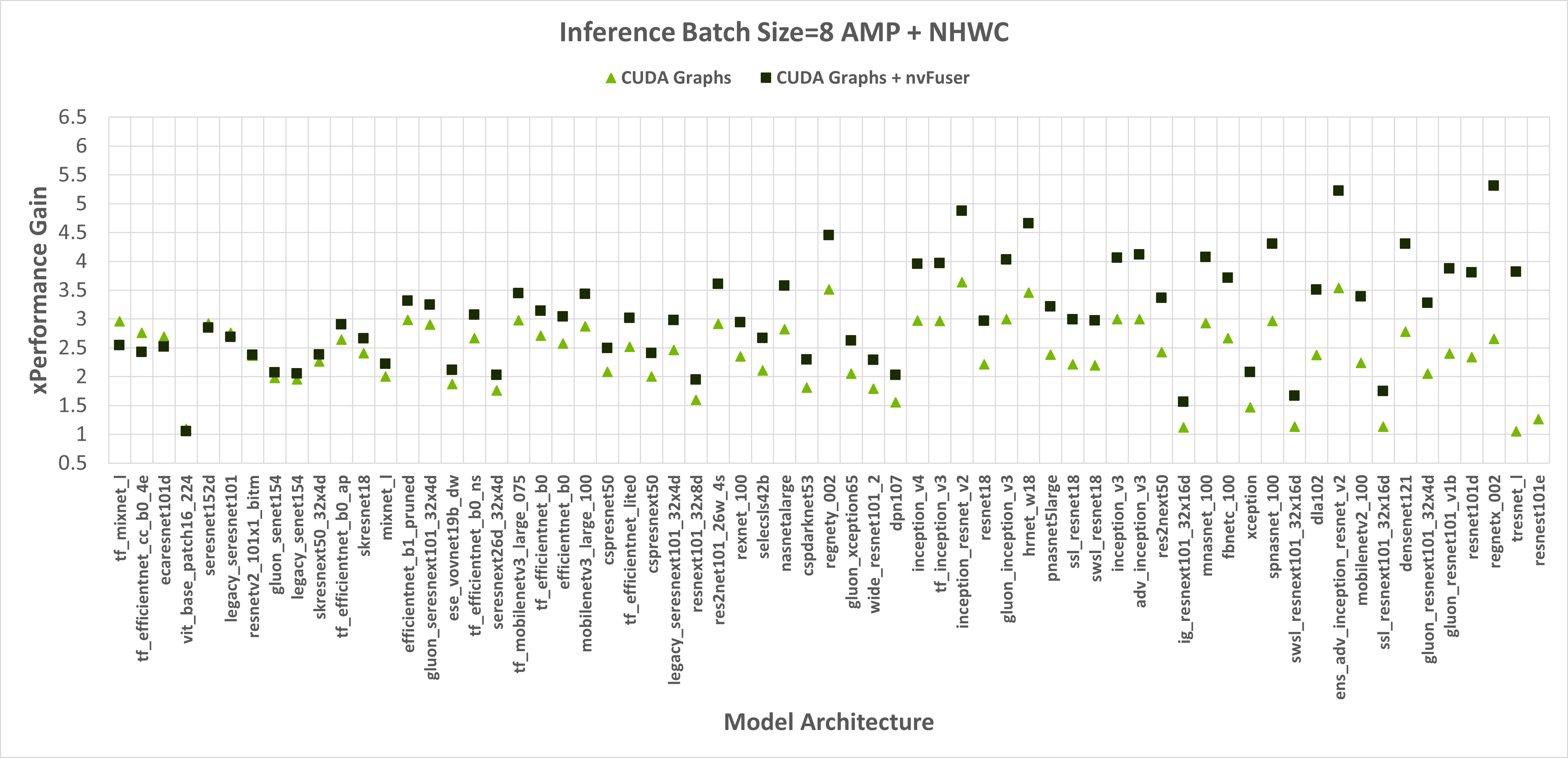
图 3:启用 CUDA Graphs 以及 CUDA Graphs 与 nvFuser 相比,在 TIMM 模型中,使用 AMP、通道最后输入以及 1 和 8 个不同的批处理大小的情况下,与未启用 CUDA Graphs 和 nvFuser 的原始 PyTorch 性能的提升。CUDA Graphs 的几何平均速度提升为 2.29 倍,CUDA Graphs + nvFuser 为 2.95 倍。nvFuser 提供了最大 0.86 倍的回归和相对于未启用 nvFuser 的 CUDA Graphs 的最大性能提升 3.82 倍(相对于未启用 CUDA Graphs 和 nvFuser 的 PyTorch 平均每次迭代的平均时间)。模型按 nvFuser 提供的额外性能进行排序。
到目前为止,nvFuser 的性能尚未针对推理工作负载进行调整,因此其性能优势在所有情况下并不一致。然而,仍然有许多模型在推理过程中从 nvFuser 中受益显著,我们鼓励用户尝试在推理工作负载中使用 nvFuser,看看您今天是否会受益。nvFuser 在推理工作负载中的性能将在未来得到改善,如果您对 nvFuser 在推理工作负载中的使用感兴趣,请通过 PyTorch 论坛联系我们。
入门指南 - 使用 nvFuser 加速您的脚本
我们创建了一个教程,展示了如何利用 nvFuser 加速标准 Transformer 块的一部分,以及如何使用 nvFuser 定义快速且新颖的操作。nvFuser 仍有一些粗糙的边缘,我们正在努力改进,如本博客文章所述。然而,我们也展示了在 HuggingFace 和 TIMM 等多个网络上的训练速度的显著提升,我们预计在您的网络中,nvFuser 今天就能帮助到您,未来还有更多机会。如果您想了解更多关于 nvFuser 的信息,我们建议您观看 NVIDIA GTC 2022 和 GTC 2021 会议上的我们的演讲。