概述
INT8 量化是一种强大的技术,可以加速在 x86 CPU 平台上进行深度学习推理。通过将模型的权重和激活的精度从 32 位浮点数(FP32)降低到 8 位整数(INT8),INT8 量化可以显著提高推理速度并减少内存需求,同时不牺牲精度。
在本文中,我们将讨论 PyTorch 中针对 x86 CPU 的 INT8 量化的最新进展,重点关注新的 x86 量化后端。我们还将简要介绍 PyTorch 2.0 导出(PT2E)和 TorchInductor 的新量化路径。
X86 量化后端
在 PyTorch 中,当前推荐的量化方法是 FX。在 PyTorch 2.0 之前,x86 CPU 上的默认量化后端(也称为 QEngine)是 FBGEMM,它利用 FBGEMM 性能库来实现性能提升。在 PyTorch 2.0 版本中,引入了一个名为 X86 的新量化后端来替代 FBGEMM。与原始 FBGEMM 后端相比,x86 量化后端通过利用 FBGEMM 和 Intel® oneAPI 深度神经网络库(oneDNN)内核库的优势,提供了改进的 INT8 推理性能。
X86 后端带来的性能优势
为了衡量新 X86 后端的性能优势,我们使用第 4 代英特尔® 至强® 可扩展处理器在 69 个流行的深度学习模型(如图 1-3 所示)上进行了 INT8 推理。结果显示,与 FP32 推理性能相比,性能提升了 2.97 倍,而使用 FBGEMM 后端时,速度提升了 1.43 倍。下方的图表显示了与 FBGEMM 后端相比,每个模型的性能提升速度。
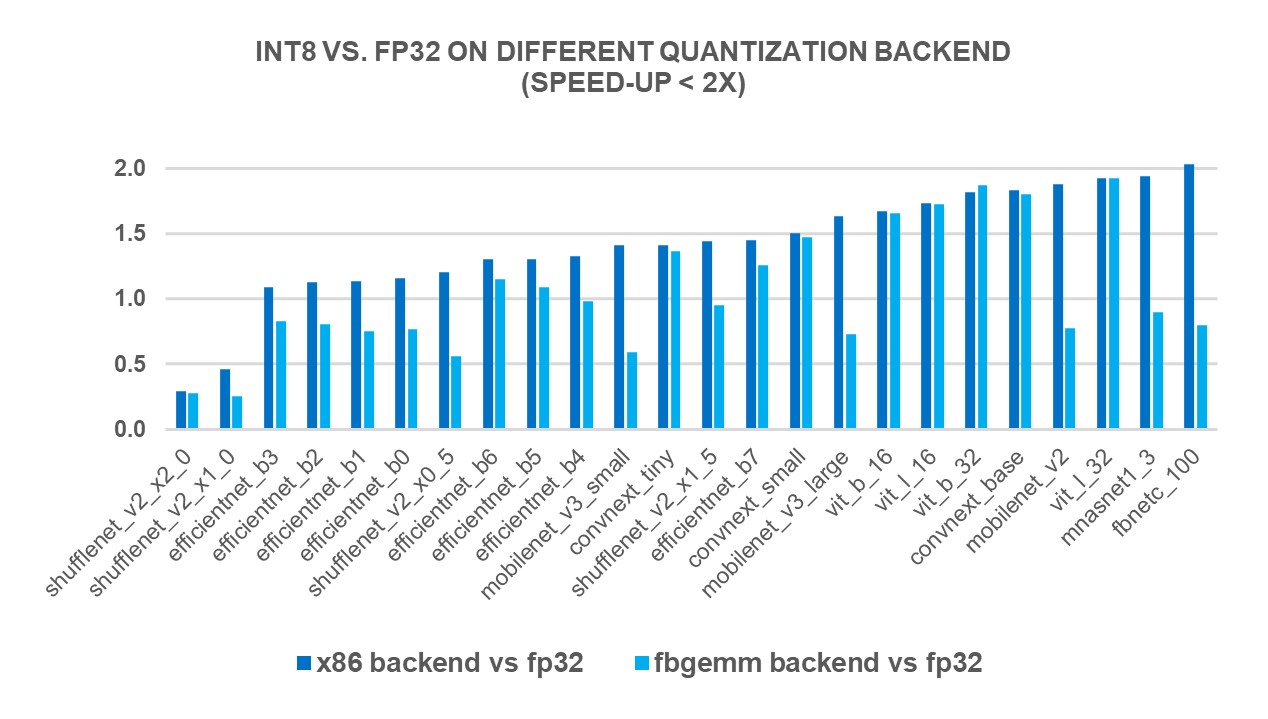
图 1:使用 x86 后端性能提升小于 2 倍的模型 1
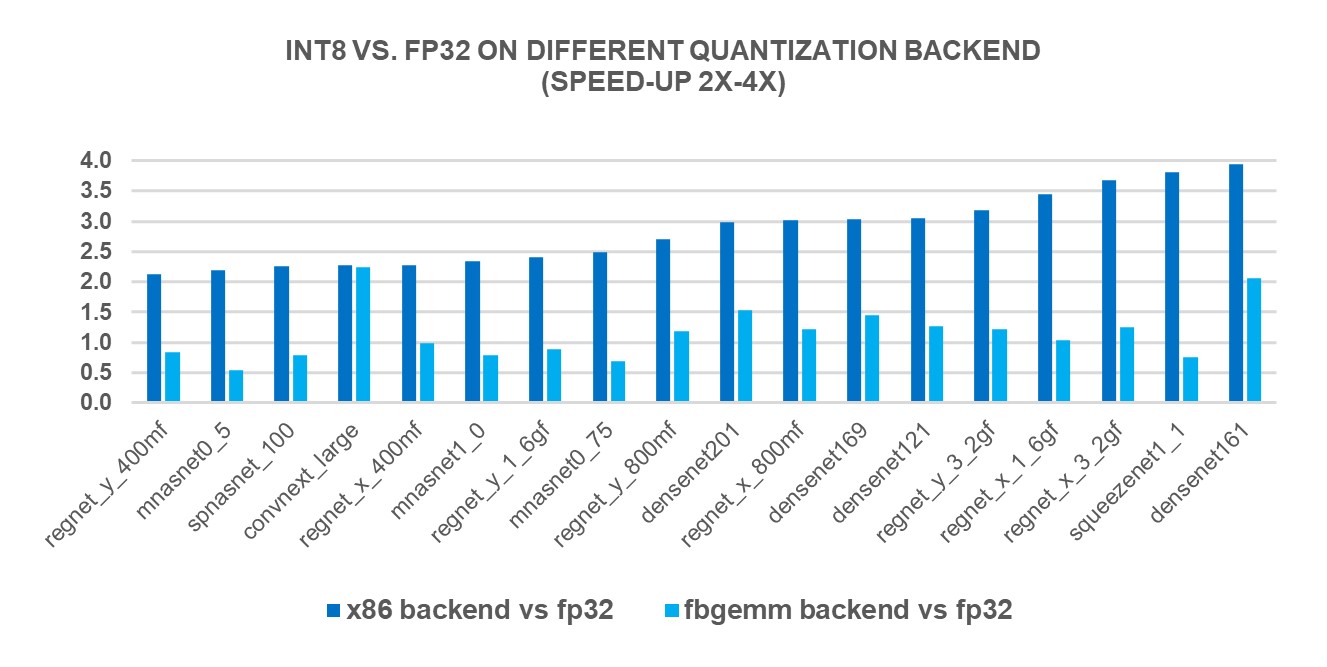
图 2:使用 x86 后端性能提升 2 倍至 4 倍的模型 1
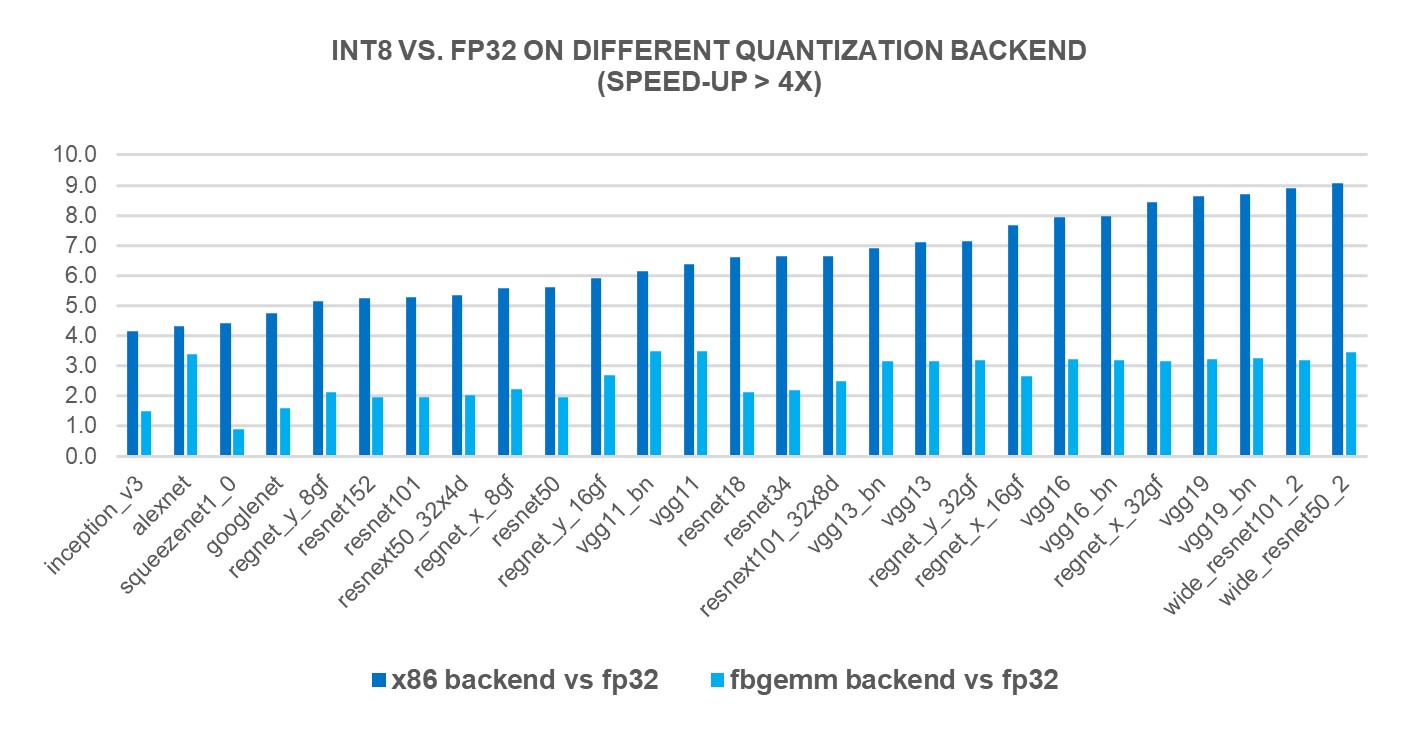
图 3:使用 x86 后端具有超过 4 倍性能提升的模型 1
x86 后端的使用
默认情况下,在 2.0 版本中,x86 平台上的用户将使用 x86 量化后端,并且在使用默认后端时,他们的 PyTorch 程序将保持不变。或者,用户可以明确指定 x86 作为量化后端。
以下是使用 x86 量化后端的 PyTorch 静态后训练量化的示例代码片段。
import torch
from torch.ao.quantization import get_default_qconfig_mapping
from torch.quantization.quantize_fx import prepare_fx, convert_fx
qconfig_mapping = get_default_qconfig_mapping()
# Or explicity specify the qengine
# qengine = 'x86'
# torch.backends.quantized.engine = qengine
# qconfig_mapping = get_default_qconfig_mapping(qengine)
model_fp32 = MyModel().eval()
x = torch.randn((1, 3, 224, 224), dtype=torch.float)
x = x.to(memory_format=torch.channels_last)
# Insert observers according to qconfig and backend config
prepared_model = prepare_fx(model_fp32, qconfig_mapping, example_inputs=x)
# Calibration code not shown
# Convert to quantized model
quantized_model = convert_fx(prepared_model)
x86 后端的技术细节
根据我们对基准测试模型的性能数据进行评估,我们设计了启发式调度规则,以决定是否调用 oneDNN 或 FBGEMM 性能库来执行卷积或矩阵乘法操作。这些规则是操作类型、形状、CPU 架构信息等的组合。详细的逻辑请在此处查看。更多设计和技术讨论,请参阅请求评论。
新量化路径下的 PyTorch 2.0 导出下一步
尽管仍远未完成,但一个新的量化路径,PyTorch 2.0 导出(PT2E),正处于早期设计和原型阶段。新的方法计划在未来取代 FX 量化路径。它是建立在 PyTorch 2.0 版本中引入的 TorchDynamo 导出功能的基础之上,该功能用于捕获 FX 图。然后,该图被量化并降低到不同的后端。PyTorch 的新深度学习编译器 TorchInductor 在 x86 CPU 上的 FP32 推理加速方面显示出有希望的结果。我们正在积极工作,使其成为 PT2E 的量化后端之一。我们相信,由于在不同级别上融合的更多灵活性,新的路径将导致 INT8 推理性能的进一步改进。
结论
PyTorch 2.0 版本中引入的 x86 后端在 x86 CPU 平台上展示了显著的 INT8 推理速度提升。与原始 FBGEMM 后端相比,它提供了 1.43 倍的加速,同时保持向后兼容。这一增强可以使得最终用户在程序上几乎无需或仅需最小修改即可受益。此外,一个新的量化路径 PT2E 目前正在开发中,预计将为未来提供更多可能性。
致谢
感谢 Nikita Shulga、Vasiliy Kuznetsov、Supriya Rao 和 Jongsoo Park。我们一起在提升 PyTorch CPU 生态系统道路上迈出了新的一步。
配置
1 AWS EC2 r7iz.metal-16xl 实例(Intel(R) Xeon(R) Gold 6455B,32 核心/64 线程,Turbo Boost 开启,Hyper-Threading 开启,内存:8x64GB,存储:192GB);操作系统:Ubuntu 22.04.1 LTS;内核:5.15.0-1028-aws;批量大小:1;每实例核心数:4;PyTorch 2.0 RC3;TorchVision 0.15.0+cpu,由 Intel 于 2023 年 3 月 77 日测试。可能无法反映所有公开可用的安全更新。