一种高效的低精度 KV 缓存分组查询注意力解码
引言
生成式 AI 凭借其生成类似人类内容的能力在全球掀起热潮。许多这些生成式 AI 工具由大型语言模型(LLMs)驱动,如 Meta Llama 模型和 OpenAI 的 ChatGPT。LLMs的一个主要挑战是支持大的“上下文长度”(也称为“序列长度”)。上下文长度指的是模型用于理解输入上下文并生成响应的标记数量。较长的上下文长度通常意味着更高的精度和质量。然而,长上下文长度计算和内存密集。这主要是由于以下原因:
- 注意力层的计算复杂度与上下文长度成比例增加(增长率取决于注意力算法)。因此,当使用长上下文长度时,注意力层可以成为瓶颈,尤其是在注意力计算密集的预填充阶段。
- KV 缓存的大小与上下文长度线性增长,因此对内存需求施加了更高的压力,从而减缓了已经内存受限的注意力解码。此外,由于内存容量有限,当 KV 缓存变大时,批处理大小会减少,这通常会导致吞吐量下降。
与上述问题相比,计算复杂度的增长难以解决。解决 KV 缓存大小增长问题的一种方法是用低精度 KV 缓存。根据我们的实验,在 Meta Llama 2 推理的解码阶段,组间 INT4 量化在精度方面与 BF16 KV 缓存相当。然而,尽管在注意力解码层中读取了 4 倍少的数据,我们没有观察到任何延迟改进。这意味着 INT4 注意力在利用宝贵的 HBM 带宽方面比 BF16 注意力低 4 倍效率。
在这篇笔记中,我们讨论了我们对 INT4 GQA(分组查询注意力——我们在LLM推理阶段使用的注意力层)应用的 CUDA 优化,这些优化在 NVIDIA A100 GPU 上提高了其性能,最高可达 1.8 倍,在 NVIDIA H100 GPU 上可达 1.9 倍。
- 优化的 CUDA INT4 GQA 在 A100 上比我们实验中使用的最佳性能的 INT4 Flash-Decoding GQA(上述实验中使用的最佳性能的 INT4 GQA)提高了 1.4x-1.7x,在 H100 上提高了 1.09x-1.3x。
- 优化的 CUDA INT4 GQA 在 A100 上比 BF16 Flash-Decoding GQA 提高了 1.5x-1.7x,在 H100 上提高了 1.4x-1.7x。
背景
GQA for LLM 推理
分组查询注意力(GQA)是多头注意力(MHA)的一种变体,其中每个 KV 缓存头在查询头组之间共享。我们的LLM推理在预填充和解码阶段都采用 GQA 作为注意力层,以减少 KV 缓存的需求。在推理中,我们使用多个 GPU,其中 KV 缓存和查询头在 GPU 之间分布。每个 GPU 运行一个具有单个 KV 头和一组 Q 头的注意力层。因此,从单个 GPU 的角度来看,GQA 组件也可以描述为 MQA(多查询注意力)。
GQA 解码的简化工作流程如图 1 所示。GQA 有三个主要输入:输入查询(表示为 Q )、K 缓存(表示为 K )和 V 缓存(表示为 V )。我们当前的 GQA 推理使用 BF16 对 Q 、 K 和 V 进行操作。
-
Q是一个形状为(B、1、HQ、D)的 4D BF16 张量。 -
K是一个形状为(B、Tmax、HKV、D)的 4D BF16 张量。 -
V是一个形状为(B、Tmax、HKV、D)的 4D BF16 张量。
哪里
-
B是批大小(输入提示的数量) -
HQ是查询头的数量 -
HKV是 KV 头的数量(HQ必须能被HKV整除) -
Tmax是最大上下文长度 -
D是头维度(固定为 128)
GQA 简单来说就是 bmm(softmax(bmm(Q, KT) / sqrt(D)), V) 。这产生一个输出张量(表示为 O ),它是一个与 Q 形状相同的 4D BF16 张量。请注意,矩阵乘法使用 BF16 进行,而累加和 softmax 使用 FP32。我们称之为“BF16 GQA”,因为 KV 缓存是 BF16。
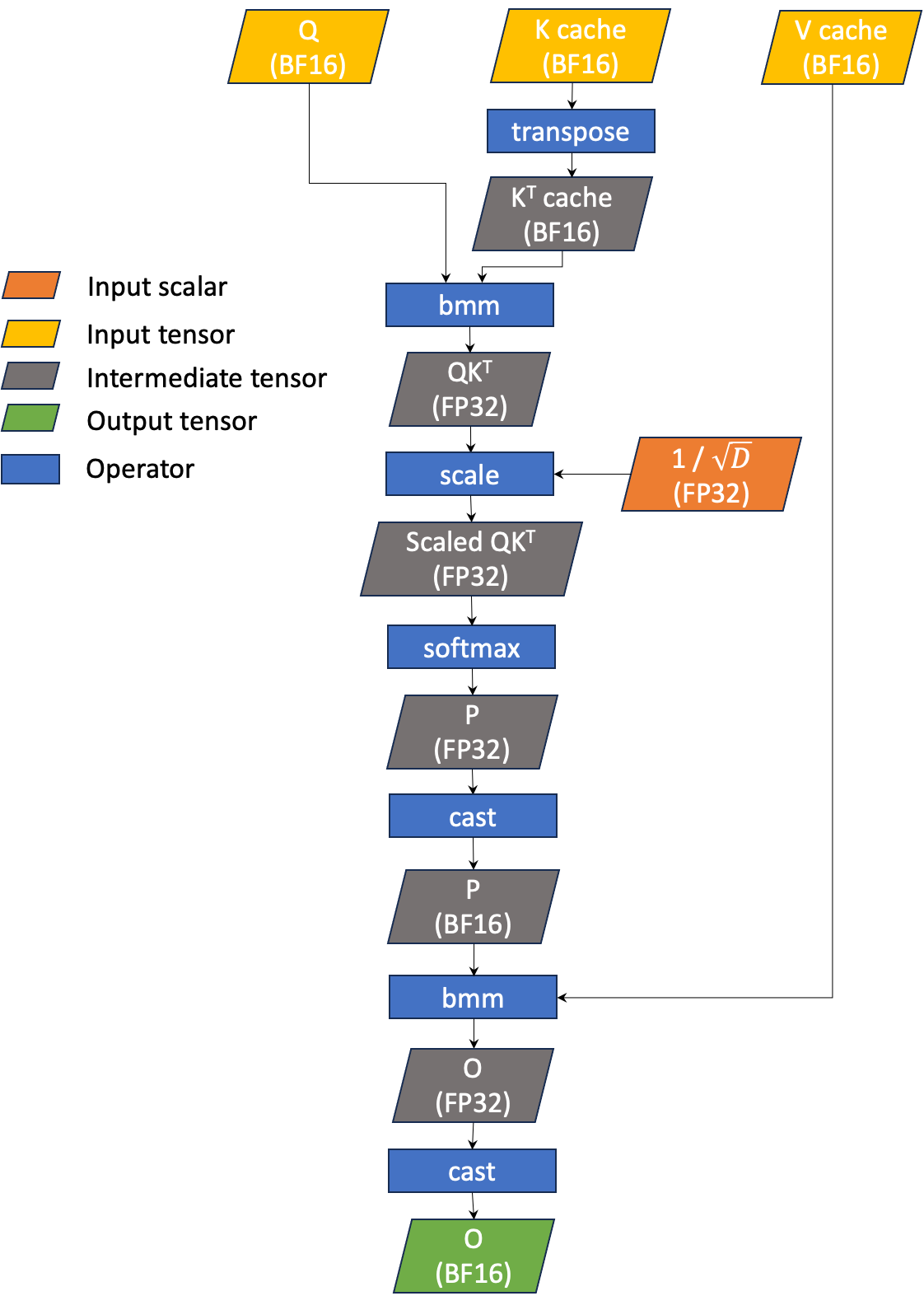
图 1 BF16 GQA 的简化工作流程,用于 LLM 推理
INT4 GQA
为了进一步减小 KV 缓存的尺寸,我们探讨了使用 INT4 代替 BF16 作为 KV 缓存的可行性。我们通过计算 INT4 GQA 和 BF16 GQA 的计算强度(CI)来评估潜在的性能提升,因为 CI 代表每字节浮点运算次数(FLOPS)。我们计算了 QKT 和 PV 的计算强度(如公式 1 所示),因为它们将 KV 缓存作为操作数。请注意,我们忽略了 Q 的加载,因为它与 KV 缓存相比可以忽略不计。我们还忽略了不在全局内存上的任何中间数据加载/存储。因此,CI 仅考虑计算 FLOPS 和 KV 缓存加载。
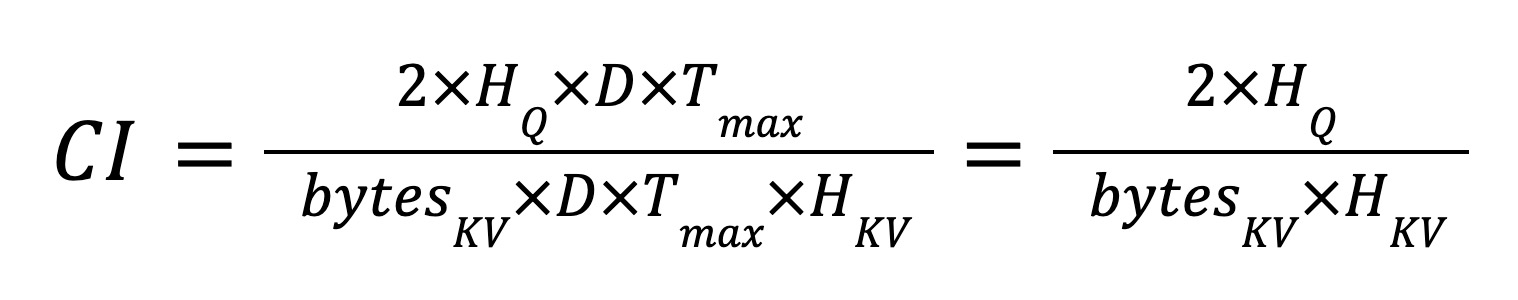
公式(1)
假设 HQ = 8 和 HKV = 1,BF16 KV 缓存的 CI 为 8,而 INT4 KV 缓存的 CI 为 32。CI 表明 BF16 和 INT4 GQA 都是内存受限的(A100 和 B100 的 BF16 张量核心的峰值 CI 分别为 312 TF / 2 TB/s = 141 和 990 TF / 3.35 TB/s = 269;请注意,这些 TF 数字不包括稀疏性)。此外,与 BF16 GQA 相比,使用 INT4 KV 缓存应可期待高达 4 倍的性能提升。
要在 GQA 中启用 INT4 KV 缓存支持,我们可以在将其传递给 BF16 GQA 算子之前,将 KV 缓存从 INT4 解量化为 BF16。然而,由于 KV 缓存通常很大,从/到全局内存的复制可能代价高昂。此外,解码 GQA 是一个内存密集型操作(内存单元的利用率远高于计算单元)。图 2 显示了 xFormers 中 FMHA CUTLASS BF16 GQA 内核的 NCU 配置文件,这是 GQA 的众多最先进实现之一。从图中可以看出,内存是一个瓶颈。
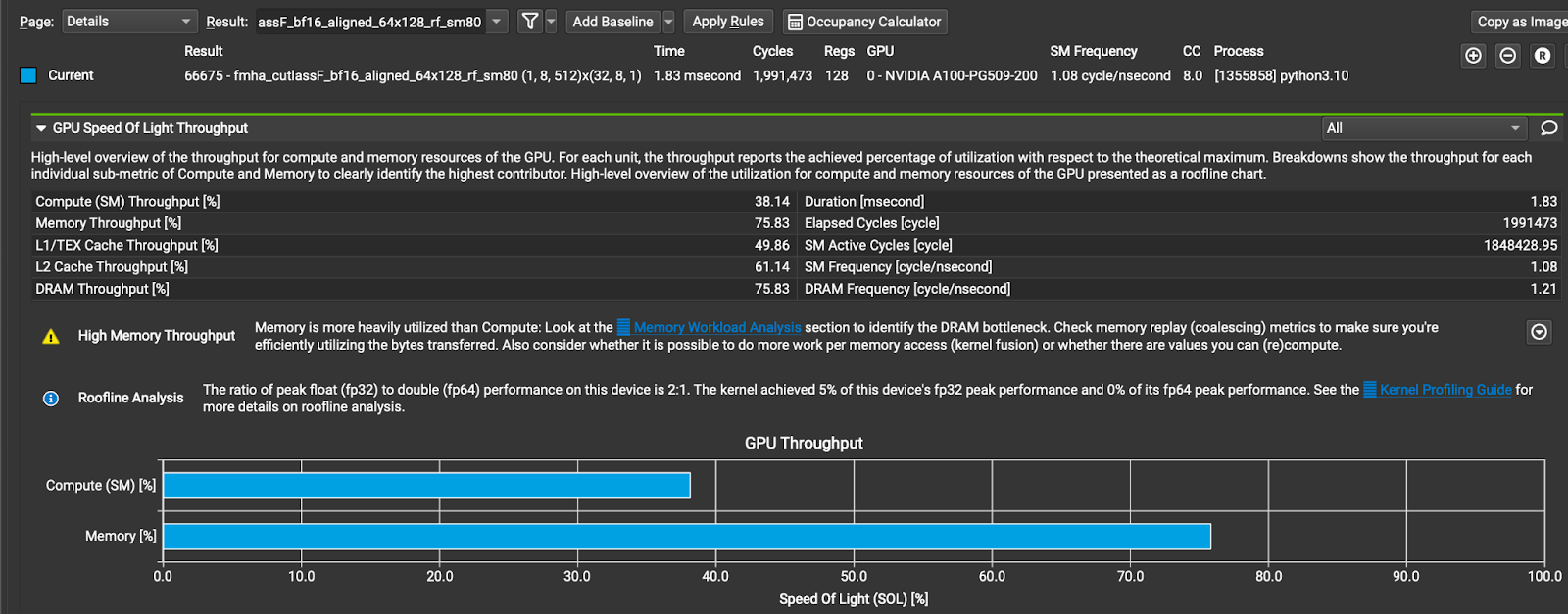
图 2 xFormers 中 FMHA CUTLASS BF16 内核的 NCU 配置文件
一种更有效的方法是将 INT4 解量化与 GQA 操作融合(如图 3 所示)。换句话说,让 GQA 直接读取 INT4 KV 缓存,并在内核内执行 INT4 到 BF16 的转换。这种改变有可能减少 KV 缓存所需的全球内存读取量,从而降低延迟。我们称之为“INT4 GQA”。
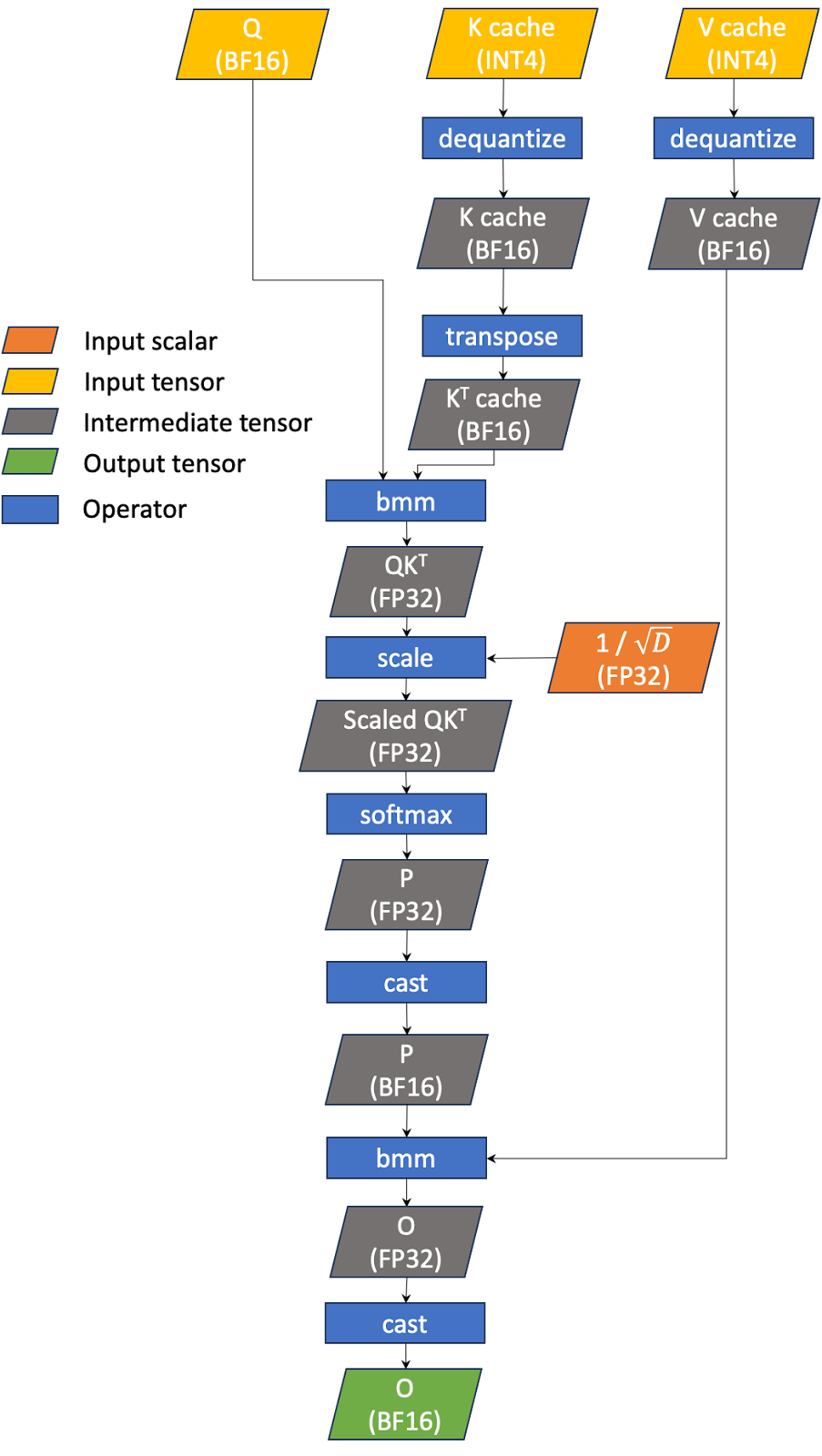
图 3 融合 INT4 GQA 的工作流程
以下表格列出了 GQA 的最新实现及其特性,详见表 1。
表 1 最新 GQA 实现
| 实现 | 表示 | BF16 GQA | 混合 INT4 GQA |
| 闪速解码(Triton 实现) | FD | 是的 | 是的 |
| 闪速注意力(v2.3.3) | FA | 是的 | 否 |
| CUDA 基线 | CU | 是的 | 是的 |
所有实现(除 CU 外)都支持 split-K 和非 split-K。CU 仅支持 split-K 实现。只有 FA 在后台有启发式算法来决定运行 split-K 或非 split-K 内核。对于其他实现,用户必须明确选择要运行的版本。在本报告中,我们关注长上下文长度(在我们的实验中,我们使用上下文长度为 8192),因此尽可能选择 split-K 版本。
作为基线,我们在 NVIDIA A100 和 H100 GPU 上测量了最先进的 GQA 实现的性能。延迟(微秒)和达到的带宽(GB/s)在表 2 中报告。请注意,我们运行了一系列的 split-K(从 2 到 128 个分割)并报告了每个实现的最佳性能。对于所有实验,我们使用上下文长度为 8192。对于 INT4 GQA,我们使用了行量化(即,量化组数=1)。
表 2 基线 GQA 性能
在 A100 上
| 时间(微秒) | BF16 GQA | INT4 GQA | ||||
| 批处理大小 | FD | FA | CU | FD | FA | CU |
| 32 | 139 | 133 | 183 | 137 | - | 143 |
| 64 | 245 | 229 | 335 | 234 | - | 257 |
| 128 | 433 | 555 | 596 | 432 | - | 455 |
| 256 | 826 | 977 | 1127 | 815 | - | 866 |
| 512 | 1607 | 1670 | 2194 | 1581 | - | 1659 |
| 有效带宽(GB/s) | BF16 GQA | INT4 GQA | ||||
| 批处理大小 | FD | FA | CU | FD | FA | CU |
| 32 | 965 | 1012 | 736 | 262 | - | 250 |
| 64 | 1097 | 1175 | 802 | 305 | - | 278 |
| 128 | 1240 | 968 | 901 | 331 | - | 314 |
| 256 | 1301 | 1100 | 954 | 351 | - | 331 |
| 512 | 1338 | 1287 | 980 | 362 | - | 345 |
在 H100 上
| 时间(微秒) | BF16 GQA | INT4 GQA | ||||
| 批处理大小 | FD | FA | CU | FD | FA | CU |
| 32 | 91 | 90 | 114 | 70 | - | 96 |
| 64 | 148 | 146 | 200 | 113 | - | 162 |
| 128 | 271 | 298 | 361 | 205 | - | 294 |
| 256 | 515 | 499 | 658 | 389 | - | 558 |
| 512 | 1000 | 1011 | 1260 | 756 | - | 1066 |
| 有效带宽(GB/s) | BF16 GQA | INT4 GQA | ||||
| 批处理大小 | FD | FA | CU | FD | FA | CU |
| 32 | 1481 | 1496 | 1178 | 511 | - | 371 |
| 64 | 1815 | 1840 | 1345 | 631 | - | 443 |
| 128 | 1982 | 1802 | 1487 | 699 | - | 487 |
| 256 | 2087 | 2156 | 1634 | 736 | - | 513 |
| 512 | 2150 | 2127 | 1706 | 757 | - | 537 |
首先,让我们讨论一下 BF16 GQA 的性能:在所有实现中,CU 在性能方面排名最后。FD 和 FA 的性能相当。当批量大小小于或等于 64 时,FA 使用 split-K 内核,性能略优于 FD。然而,当批量大小大于 64 时,FD 的性能更好。
同样的趋势也适用于 INT4 GQA。然而,我们没有测量 FA 的性能,因为它不支持 INT4 KV 缓存。在所有情况下,FD 的性能都优于 CU。
当比较 FD 在 BF16 和 INT4 GQA 之间的延迟时,我们发现它们几乎相同。这表明 INT4 GQA 效率非常低,这可以通过与 BF16 GQA 相比的显著较低的带宽进一步证实。当查看 CU 的性能时,也存在同样的趋势。
CUDA 与张量核心 INT4 GQA 实现
在本节中,我们简要描述了我们的基线实现,即 CUDA 与张量核心 INT4 GQA(CU)。每个线程块只处理一个 KV 头和来自一个输入提示的一组查询头。因此,每个线程块执行 mm(softmax(mm(Q, KT) / sqrt(D)), V) ;请注意, mm 正在执行,而不是 bmm 。此外,由于这是一个分割 K 实现,KV 缓存中的标记被分配到不同的线程块中。请注意,每个线程块包含 4 个 warp(每个 warp 包含 32 个线程,适用于 NVIDIA A100 和 H100 GPU)。每个线程块中的工作在 warp 之间分配。在每个 warp 内部,我们使用 WMMA API 在张量核心上计算矩阵乘法。图 4 展示了 CU 中的工作分区。
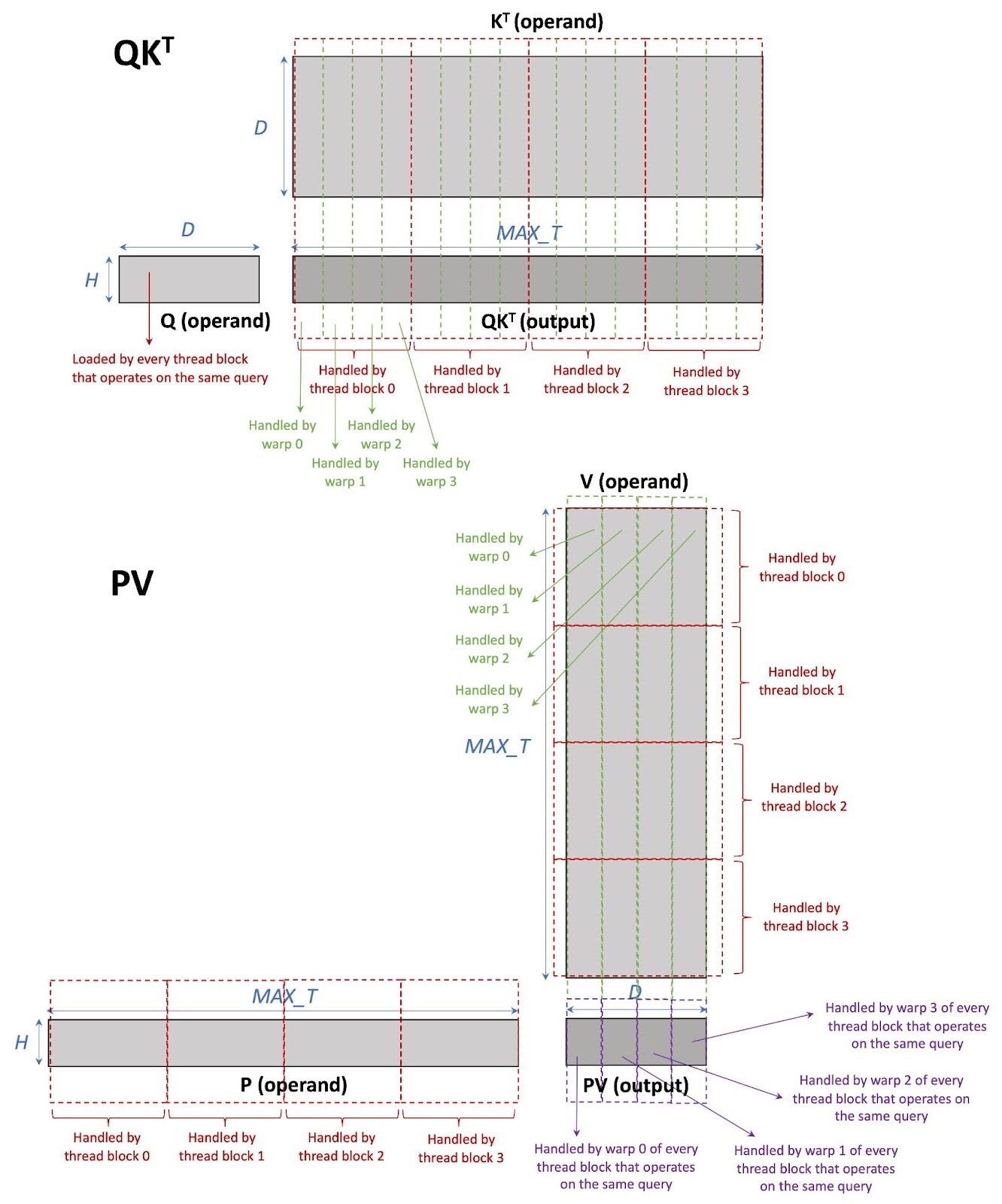
图 4 CU 工作分区
优化 INT4 GQA 的 CUDA 张量核心内核
在这篇笔记中,我们讨论了我们对 CUDA 带张量核心的 INT4 GQA(CU)实现所应用的优化。理想目标是基于前一部分的 CI 分析,将 INT4 GQA 性能提高 4 倍。请注意,当上下文长度较长时,查询大小与 KV 缓存大小相比可以忽略不计。
在我们的分析中,我们使用 NVIDIA Nsight Compute(NCU)作为主要分析器。我们的一般瓶颈消除方法是尽量减少停滞周期。我们对 INT4 GQA 应用了 10 项优化,其中三项是针对 NVIDIA A100/H100 GPU 的。这些优化是众所周知的 CUDA 优化技术,可以推广到许多应用中。
值得注意的是,我们选择优化 CUDA 实现而不是 Flash-Decoding 实现(FD,基于 Triton)的原因是因为使用 CUDA,我们可以更好地控制低级指令的生成。我们应用的许多优化技术,例如直接在张量核心片段上操作(优化 7-9),无法通过 Triton 实现,因为 Triton 不向开发者暴露低级细节。然而,这些优化可以集成到基于编译器的解决方案中,使优化对更广泛的操作员可用,这确实是我们未来的计划之一。
优化 1:展开 K 加载
问题分析:
NCU 配置文件显示,在 K 加载期间,只有 2 次全局加载,随后在 dequantize_permuted_int4 出现内存停滞。这些内存停滞是长计分板停滞,表明等待全局内存访问。这表明内核没有发出足够的内存加载指令。
隐藏全局加载延迟。内核发出数据加载,然后等待立即消耗数据,导致全局加载延迟暴露出来。停滞情况如图 5 所示。
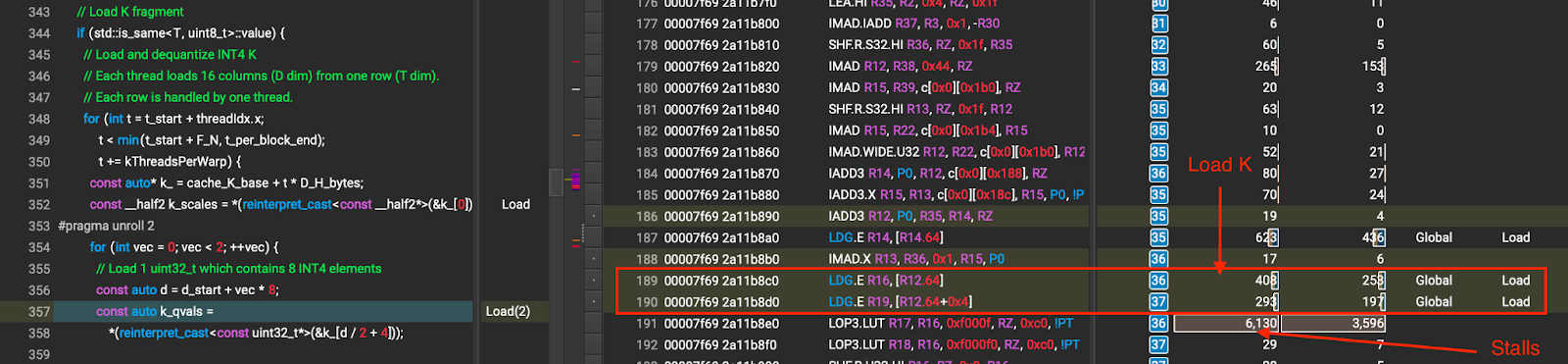
图 5 展开前 K 加载(箭头所指的数字是因全局内存等待造成的停滞周期)
解决方案:
在基线实现中,我们使用 uint32_t 在单次加载中加载 8 个 INT4 K 值,并在每次迭代中执行 2 个 uint32_t 加载,这是 16 个 INT4 K 值。为了更好地隐藏全局加载延迟,我们在消耗 dequantize_permuted_int4 中的 K 值之前发出 8 个 uint32_t 加载,而不是两个。这允许编译器展开加载,并重新排序指令以更好地隐藏全局加载延迟。图 6 显示了展开后的 K 加载的 NCU 配置文件。比较图 5 和图 6,我们通过展开 K 加载有效地减少了停滞周期。
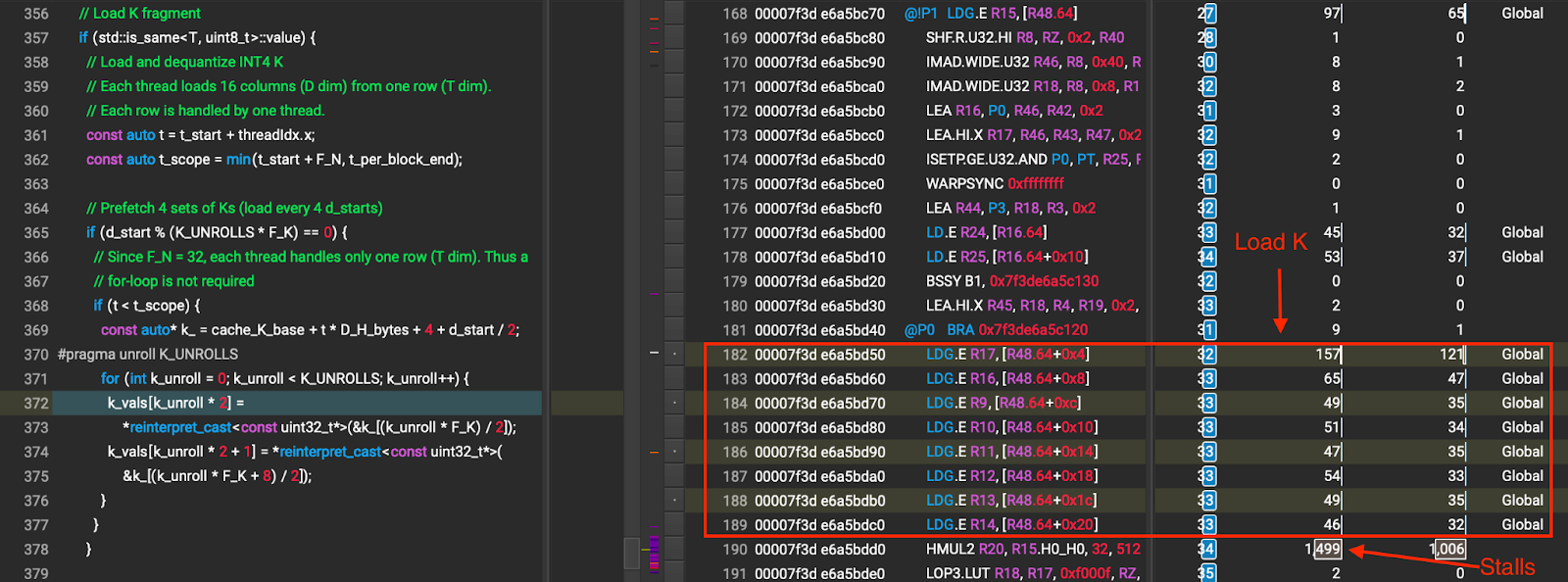
图 6 展开后的 K 加载(箭头所指的数字为全局内存等待导致的停滞周期)
结果:
表 3 优化 1 对 INT4 GQA(按行量化)的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 与 FD 对比 | 与 CU 基线对比 | |||
| 基准 | 选项 1 | 基准 | 选项 1 | |||||
| 32 | 137 | 143 | 134 | 262 | 250 | 267 | 1.02 | 1.07 |
| 64 | 234 | 257 | 237 | 305 | 278 | 302 | 0.99 | 1.09 |
| 128 | 432 | 455 | 422 | 331 | 314 | 339 | 1.02 | 1.08 |
| 256 | 815 | 866 | 806 | 351 | 331 | 355 | 1.01 | 1.07 |
| 512 | 1581 | 1659 | 1550 | 362 | 345 | 369 | 1.02 | 1.07 |
优化 2:改进 P 类型转换(FP32->BF16)
问题分析:
由于 softmax(bmm(Q, KT) / sqrt(D)) 的乘积是 FP32(在图 3 中表示为 P ),内核必须将 P 从 FP32 转换为 BF16,然后再将其输入到下一个 bmm 计算中。内核通过将 FP32 数据从共享内存的一个位置复制到另一个位置来执行 P 的 FP32 到 BF16 转换。这导致在共享内存访问期间出现停滞(如图 7 所示),这可能是由于(1)共享内存间接寻址;以及(2)共享内存银行冲突,因为每个线程访问一个 16 位元素(因此,两个线程可以同时访问相同的内存银行)。
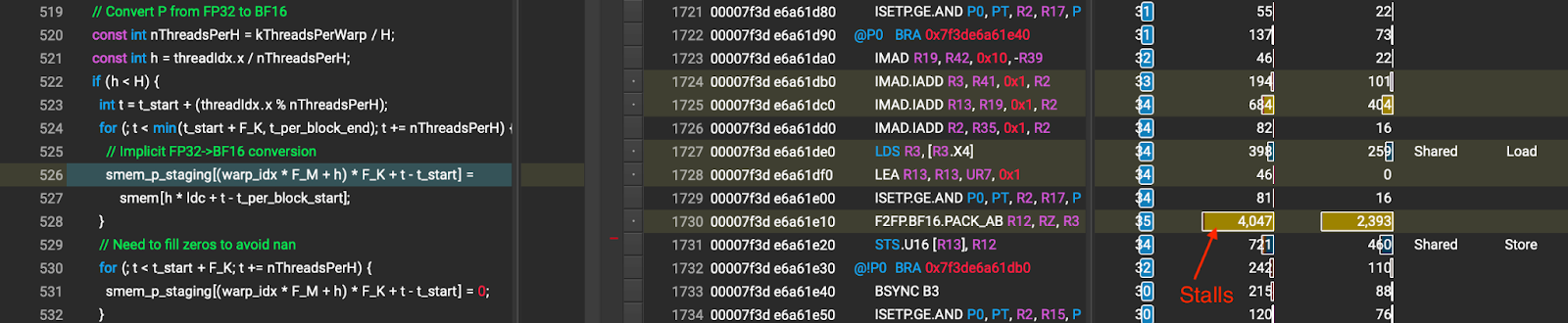
图 7 优化 2 之前的 P 类型转换(箭头所指的数字是因共享内存等待而造成的停滞周期)
解决方案:
我们使用线程块中的所有线程进行就地类型转换。每个线程对两个连续的元素进行操作,以避免在存储 BF16 时出现共享内存银行冲突。所有线程同时工作在相同的头部( h )上,以保证转换的正确性。就地转换步骤如下:
- 每个线程从共享内存中加载 2 个 FP32 令牌元素到相同的寄存器中
- 调用
__syncthreads()确保每个线程完成数据读取 - 每个线程将其数据转换为 2 个 BF16 令牌元素,然后将结果存储到相同的共享内存中
我们在实现中应用的一些优化:
- 使用向量类型(尤其是
nv_bfloat2) - 展开数据加载/存储,即在进行
__syncthreads()之前执行多次加载,并在执行__syncthreads()之后执行多次存储
经过这次优化后,在 P 类型转换过程中没有观察到长时间的停滞,如图 8 所示。
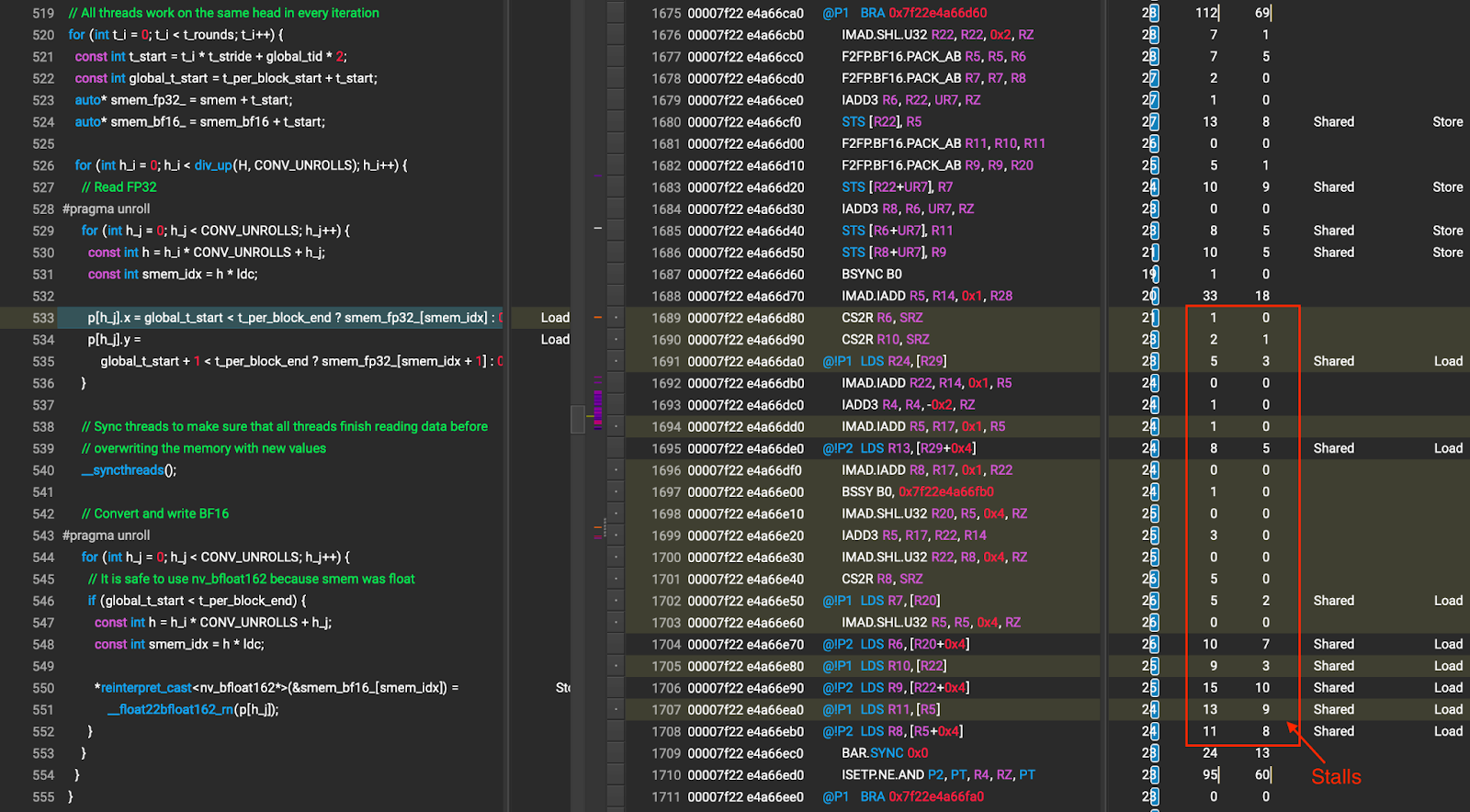
图 8 优化 2 后的 P 类型转换(箭头所指的数字是因共享内存等待造成的停滞周期)
犯罪者:
由于我们使用寄存器作为中间存储来展开数据加载/存储,每个线程的寄存器数量增加,导致占用率降低。
结果:
表 4 优化 2 对 INT4 GQA(按行量化)的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 与 FD 相比 | vs CU 基线 | |||
| 基准 | 选项 2 | 基准 | 选项 2 | |||||
| 32 | 137 | 143 | 126 | 262 | 250 | 285 | 1.09 | 1.14 |
| 64 | 234 | 257 | 221 | 305 | 278 | 324 | 1.06 | 1.16 |
| 128 | 432 | 455 | 395 | 331 | 314 | 362 | 1.09 | 1.15 |
| 256 | 815 | 866 | 749 | 351 | 331 | 382 | 1.09 | 1.16 |
| 512 | 1581 | 1659 | 1435 | 362 | 345 | 399 | 1.10 | 1.16 |
优化 3:移除局部内存使用以实现最大 QKT 计算
问题分析:
在 softmax 计算过程中,内核必须为每个头计算 max QKT 。它使用一个临时的“线程局部”存储来存储每个线程的 max QKT 结果(每个头一个浮点值)。根据编译器,线程局部存储可以分配在寄存器(片上)或局部内存(片外==全局内存)。不幸的是,在基线中,线程局部存储位于局部内存中,这比寄存器(如图 9 所示)慢得多。我们怀疑这是因为编译器无法在编译时确定线程局部存储的索引(因为内核中的头数( H )是运行时变量)。将访问局部内存当作访问寄存器可能会损害内核的性能。

图 9 max QKT 计算期间的局部内存访问
解决方案:
我们意识到我们不需要每个线程都使用 H (头数)个浮点数作为临时存储,因为每个线程只能计算一个头的最大值,而不是所有头的最大值。因此,我们只需要每个线程一个浮点数,这可以很容易地存储在寄存器中。为了累加战之间最大的结果,我们使用共享内存。这种优化消除了在最大 QKT 计算过程中的局部内存使用。
结果:
表 5:优化 3 在 INT4 GQA(按行量化)的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 与 FD 对比 | 与 CU 基线对比 | |||
| 基准 | 选项 3 | 基准 | 选项 3 | |||||
| 32 | 137 | 143 | 119 | 262 | 250 | 300 | 1.14 | 1.20 |
| 64 | 234 | 257 | 206 | 305 | 278 | 348 | 1.14 | 1.25 |
| 128 | 432 | 455 | 368 | 331 | 314 | 389 | 1.17 | 1.24 |
| 256 | 815 | 866 | 696 | 351 | 331 | 411 | 1.17 | 1.24 |
| 512 | 1581 | 1659 | 1338 | 362 | 345 | 428 | 1.18 | 1.24 |
优化 4:移除行求和的局部内存使用
问题分析:
与优化 3 类似, softmax 计算中的行求和过程中也观察到了局部内存使用问题。由于局部内存位于芯片之外,将其访问得像访问寄存器一样会损害内核的性能。
解决方案:
我们为行求和计算应用了与最大 QKT 计算相同的解决方案。也就是说,每个线程只计算一个头部的行求和,这只需要每个线程一个浮点数。这消除了对局部内存的需求。
结果:
表 6 INT4 GQA(按行量化)优化 4 的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速比 | |||||
| FD | CU | FD | CU | 对比 FD | 对比 CU 基准 | |||
| 基准 | 选项 4 | 基准 | 选项 4 | |||||
| 32 | 137 | 143 | 118 | 262 | 250 | 302 | 1.15 | 1.21 |
| 64 | 234 | 257 | 204 | 305 | 278 | 351 | 1.15 | 1.26 |
| 128 | 432 | 455 | 364 | 331 | 314 | 393 | 1.19 | 1.25 |
| 256 | 815 | 866 | 688 | 351 | 331 | 416 | 1.18 | 1.26 |
| 512 | 1581 | 1659 | 1328 | 362 | 345 | 431 | 1.19 | 1.25 |
优化 5:为 V 加载添加预取
问题分析:
当加载 V 时观察到与 K 加载相同的问题。也就是说,内核发出数据加载,然后等待立即消耗数据,导致全局加载延迟暴露。然而,当使用上述展开技术时,编译器将临时缓冲区分配在本地内存而不是寄存器中,导致大量减速。
解决方案:
我们采用数据预取技术进行 V 加载。在当前迭代值被消耗后,立即加载下一个迭代 V 的值。这允许数据加载与 PK 计算重叠,从而提高内核性能。
结果:
表 7 INT4 GQA(按行量化)优化 5 的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 与 FD 对比 | 与 CU 基线对比 | |||
| 基准 | 选项 5 | 基准 | 选项 5 | |||||
| 32 | 137 | 143 | 109 | 262 | 250 | 327 | 1.25 | 1.31 |
| 64 | 234 | 257 | 194 | 305 | 278 | 370 | 1.21 | 1.33 |
| 128 | 432 | 455 | 345 | 331 | 314 | 414 | 1.25 | 1.32 |
| 256 | 815 | 866 | 649 | 351 | 331 | 441 | 1.26 | 1.33 |
| 512 | 1581 | 1659 | 1244 | 362 | 345 | 460 | 1.27 | 1.33 |
优化 6:添加分组 INT4(分组数 = 4)的向量加载
问题分析:
在此优化之前,CU 仅支持行向 INT4 量化。也就是说,每行中的每一列都共享相同的尺度。每行的尺度存储在每个行的前 4 个字节中,如图 10 所示。在内核中,每个线程一次只加载一行。由于每行包含 68 字节(4 字节用于尺度,64 字节用于数据),无法保证每行都与任何向量类型的大小对齐。因此,向量加载不能用于加载 KV 缓存。

图 10 INT4 KV 缓存每行行向量化的布局
解决方案:
我们已实现支持组向 INT4 量化,组数为 4。在这种情况下,KV 缓存张量中每行的列被分为 4 个相等的组。同一组内的列在量化/反量化时共享相同的尺度。INT4 KV 缓存的布局数据如图 11 所示。所有组的尺度序列化并存储在每个行的开头。INT4 数据也序列化并排列在尺度旁边。
因为每行的字节数现在变为 80 字节,我们可以使用向量类型,即在本例中的 uint2 来加载数据。(我们不使用 uint4 ,因为每个线程由于张量核心片段大小,每次只加载 16 个 INT4。)向量加载通常比标量加载更好,因为它不会引起额外的字节加载。
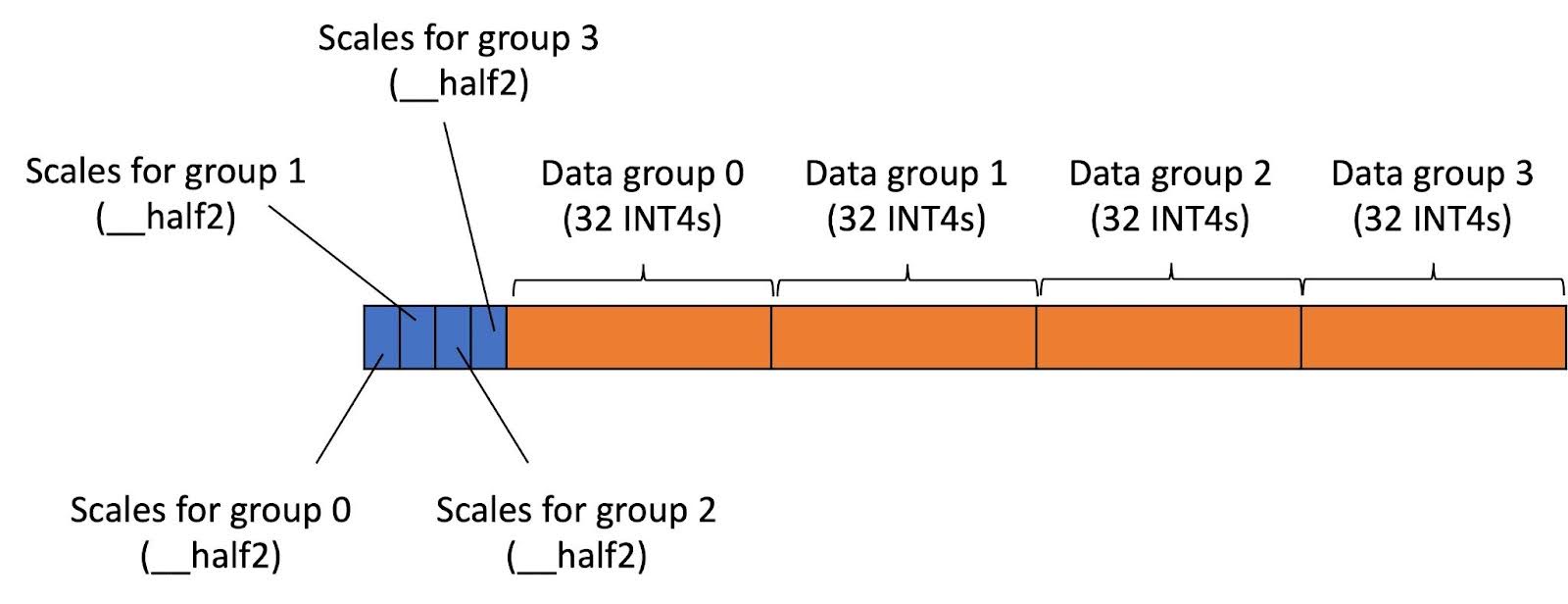
图 11 INT4 KV 缓存每行布局与行量化
结果:
表 8 INT4 GQA(行量化)优化 6 的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 与 FD 相比 | vs CU 基线 | |||
| 基准 | 选项 6 | 基准 | 选项 6 | |||||
| 32 | 137 | 143 | 111 | 262 | 250 | 322 | 1.23 | 1.29 |
| 64 | 234 | 257 | 192 | 305 | 278 | 372 | 1.22 | 1.34 |
| 128 | 432 | 455 | 346 | 331 | 314 | 414 | 1.25 | 1.32 |
| 256 | 815 | 866 | 642 | 351 | 331 | 446 | 1.27 | 1.35 |
| 512 | 1581 | 1659 | 1244 | 362 | 345 | 460 | 1.27 | 1.33 |
表 9 优化 6 在 INT4 GQA(分组量化,分组数为 4)的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | ||
| FD | CUDA_WMMA | FD | CUDA_WMMA | 与 FD 相比 | |
| 选项 6 | 选项 6 | ||||
| 32 | 129 | 116 | 325 | 364 | 1.31 |
| 64 | 219 | 195 | 385 | 431 | 1.36 |
| 128 | 392 | 347 | 429 | 484 | 1.39 |
| 256 | 719 | 638 | 468 | 527 | 1.41 |
| 512 | 1375 | 1225 | 489 | 550 | 1.43 |
优化 7:直接从 WMMA 片段计算最大值(A100/H100 专用)
问题分析:
我们观察到在执行 max QKT 计算(显示为大型短标牌停滞)时,由于共享内存访问导致的大停滞,如图 12 所示。
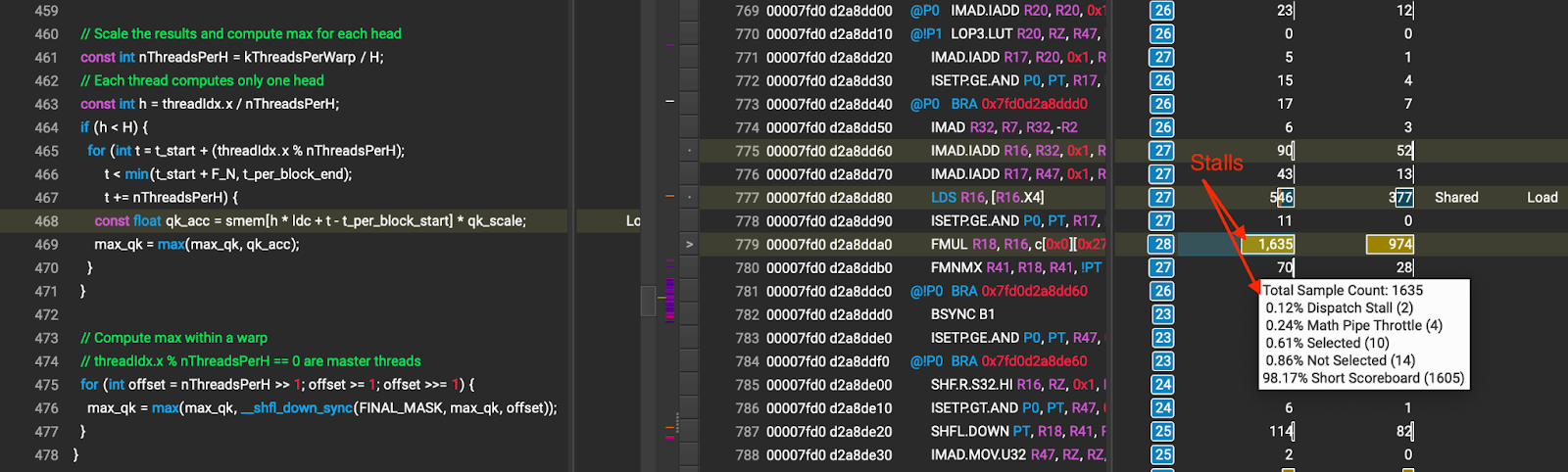
图 12 max QKT 计算期间由于共享内存访问导致的停滞(箭头所指的数字是由共享内存等待引起的停滞周期)
解决方案:
我们在计算 max QKT 时绕过共享内存,直接从 WMMA 片段(即张量核心片段)计算。WMMA 片段的布局特定于 GPU 架构。在这个优化中,我们只为 NVIDIA A100/H100 GPU 启用了此优化。其他 GPU 在执行 max QKT 计算时仍将使用共享内存。通过绕过共享内存,我们有效地消除了由共享内存访问引起的停滞。用于存储 QKT 结果的 C 片段的张量核心布局如图 13 所示。
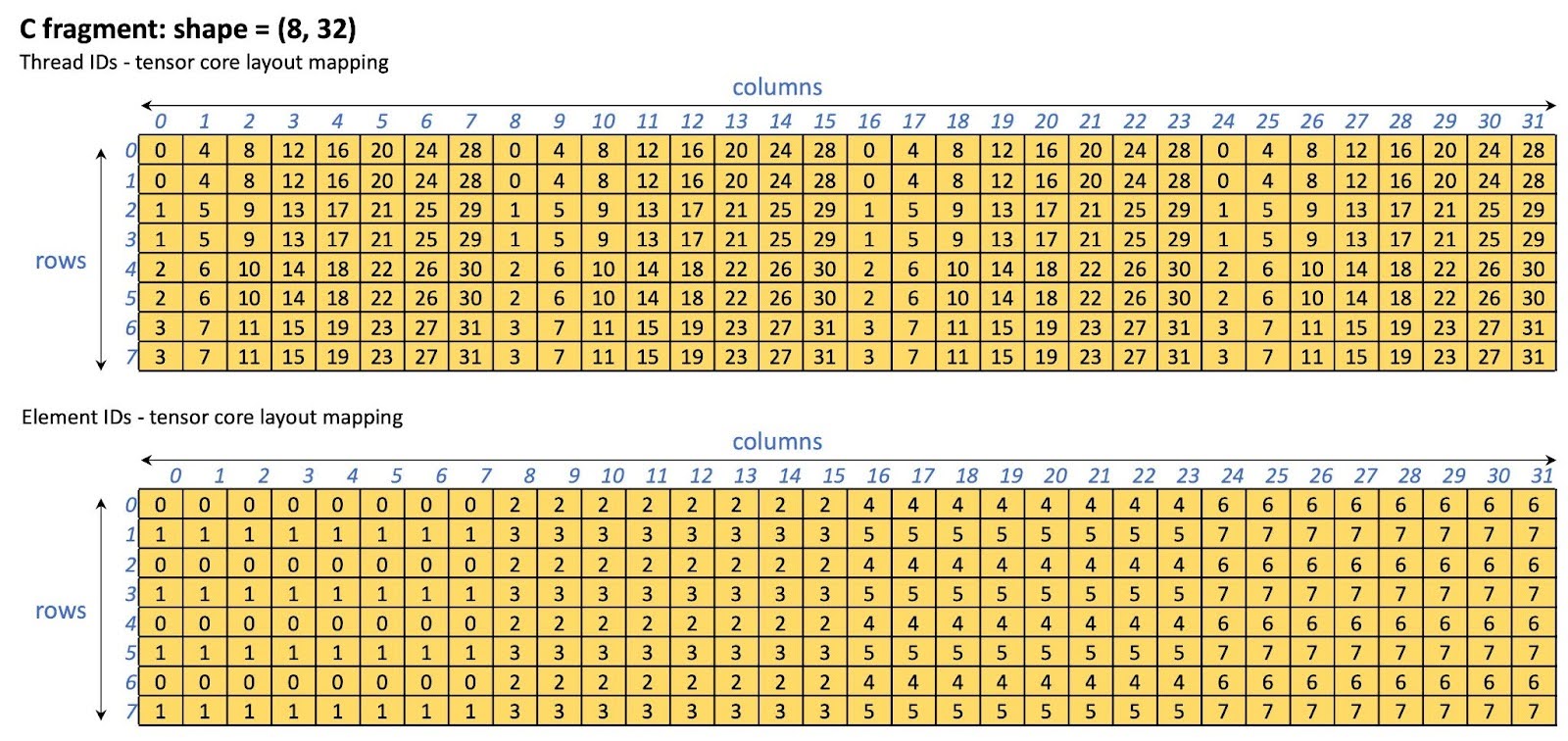
图 13 C 片段( QKT 存储)在 A100/H100 上的 tensor core 布局
表 10 优化 7 在 INT4 GQA(按行量化)的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 对比 FD | 对比 CU 基线 | |||
| 基准 | 选项 7 | 基准 | 选项 7 | |||||
| 32 | 137 | 143 | 107 | 262 | 250 | 333 | 1.27 | 1.33 |
| 64 | 234 | 257 | 183 | 305 | 278 | 391 | 1.28 | 1.40 |
| 128 | 432 | 455 | 333 | 331 | 314 | 430 | 1.30 | 1.37 |
| 256 | 815 | 866 | 620 | 351 | 331 | 461 | 1.31 | 1.40 |
| 512 | 1581 | 1659 | 1206 | 362 | 345 | 475 | 1.31 | 1.38 |
表 11 优化 7 的性能(INT4 GQA 分组量化,分组数为 4)
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CUDA_WMMA | FD | CUDA_WMMA | 与 FD 比较 | 与 CUDA_WMMA Opt 6 比较 | |||
| Opt 6 | 选项 7 | 选项 6 | 选项 7 | |||||
| 32 | 129 | 116 | 111 | 325 | 364 | 380 | 1.17 | 1.04 |
| 64 | 219 | 195 | 187 | 385 | 431 | 449 | 1.17 | 1.04 |
| 128 | 392 | 347 | 333 | 429 | 484 | 506 | 1.18 | 1.04 |
| 256 | 719 | 638 | 615 | 468 | 527 | 547 | 1.17 | 1.04 |
| 512 | 1375 | 1225 | 1184 | 489 | 550 | 569 | 1.16 | 1.03 |
优化 8:将 FP32->BF16 结果写入 P 片段直接(A100/H100 专用)
问题分析:
在对 P 片段进行 FP32-BF16 转换过程中,内核从共享内存中加载 FP32 数据,执行转换,然后将 BF16 数据存储回共享内存。此外,转换过程需要许多线程块同步( __syncthreads() )。
解决方案:
由于内核的数据分区设计,每个 warp 只对 P 片段进行一次遍历。因此,我们不需要将转换结果写回共享内存以供将来使用。为了避免将 BF16 数据写入共享内存和线程块同步,我们让每个 warp 从共享内存中加载 P WMMA 片段的 FP32 数据,执行转换,然后将 BF16 数据直接写入 P 片段。
注意,此优化仅应用于 NVIDIA A100 和 H100 GPU,因为 WMMA 片段布局与架构相关。对于非 A100/H100 GPU,内核将回退到原始路径。
图 14 显示了 P 片段张量核心布局。请注意,此布局仅针对 NVIDIA A100/H100 GPU。
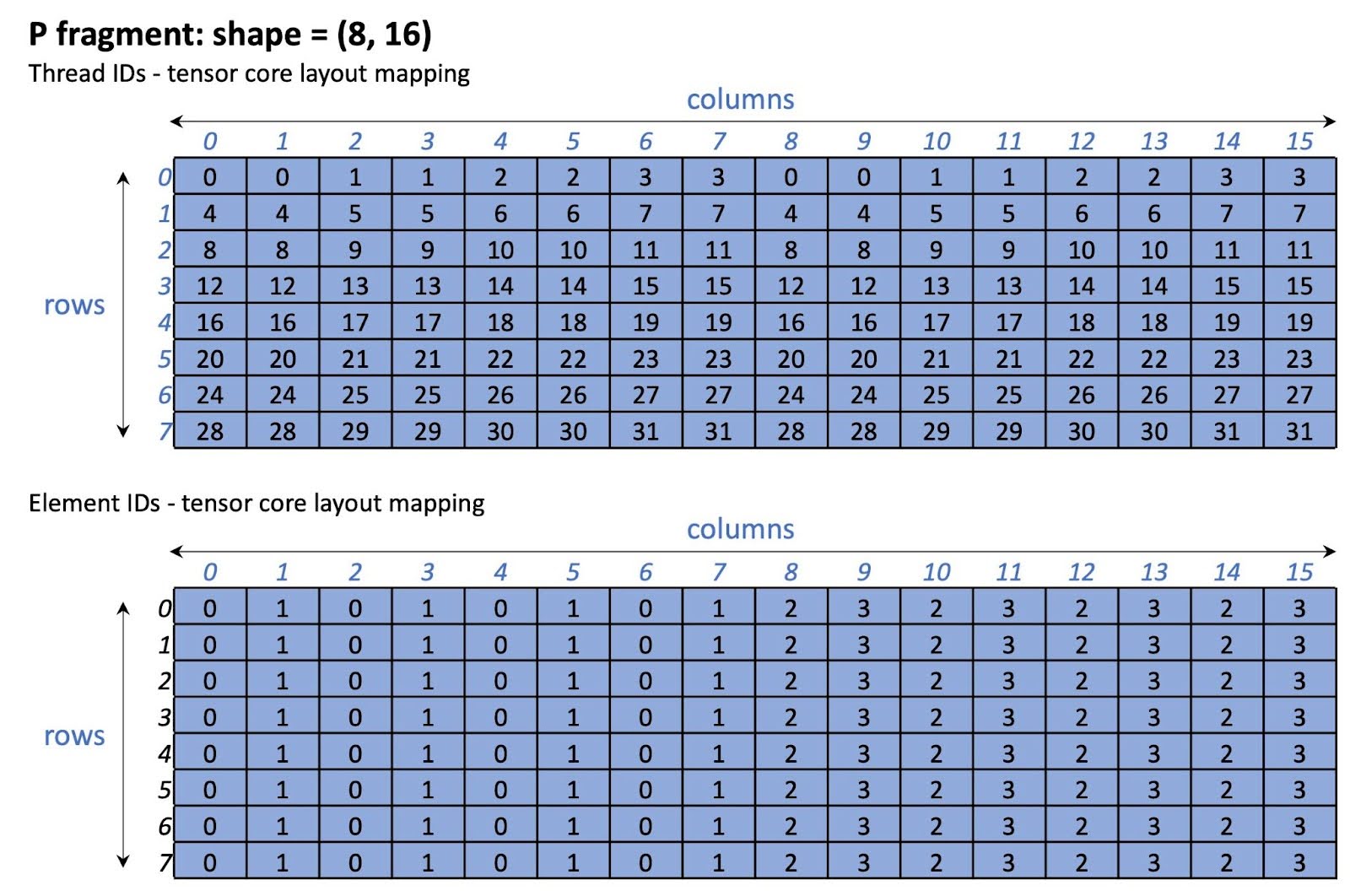
A100/H100 上的图 14 P 片段张量核心布局
表 12 优化 8 的 INT4 GQA(按行量化)性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 与 FD 相比 | vs CU 基线 | |||
| 基准 | 选项 8 | 基准 | 选项 8 | |||||
| 32 | 137 | 143 | 101 | 262 | 250 | 353 | 1.35 | 1.41 |
| 64 | 234 | 257 | 174 | 305 | 278 | 410 | 1.34 | 1.47 |
| 128 | 432 | 455 | 317 | 331 | 314 | 451 | 1.36 | 1.43 |
| 256 | 815 | 866 | 590 | 351 | 331 | 485 | 1.38 | 1.47 |
| 512 | 1581 | 1659 | 1143 | 362 | 345 | 501 | 1.38 | 1.45 |
表 13 优化 8 在 INT4 GQA(分组量化,分组数为 4)的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CUDA_WMMA | FD | CUDA_WMMA | 与 FD 相比 | vs CUDA_WMMA 选项 6 | |||
| 选项 6 | 选项 8 | 选项 6 | 选项 8 | |||||
| 32 | 129 | 116 | 106 | 325 | 364 | 396 | 1.22 | 1.09 |
| 64 | 219 | 195 | 180 | 385 | 431 | 467 | 1.21 | 1.08 |
| 128 | 392 | 347 | 319 | 429 | 484 | 528 | 1.23 | 1.09 |
| 256 | 719 | 638 | 596 | 468 | 527 | 565 | 1.21 | 1.07 |
| 512 | 1375 | 1225 | 1138 | 489 | 550 | 591 | 1.21 | 1.08 |
优化 9:Swizzle P 共享内存布局(A100/H100 专用)
问题分析:
我们观察到在 P 加载期间存在大量的共享内存银行冲突。银行冲突的数量取决于内存访问步长。例如,对于 split-Ks = 32 和最大序列长度 = 8192,我们观察到只有 4 个银行中的 32 个被并行访问(内存访问步长 = 256)。从图 14 可以看出,当所有线程访问元素 0 时,具有相同 threadIdx.x % 4 访问的线程访问相同的银行。
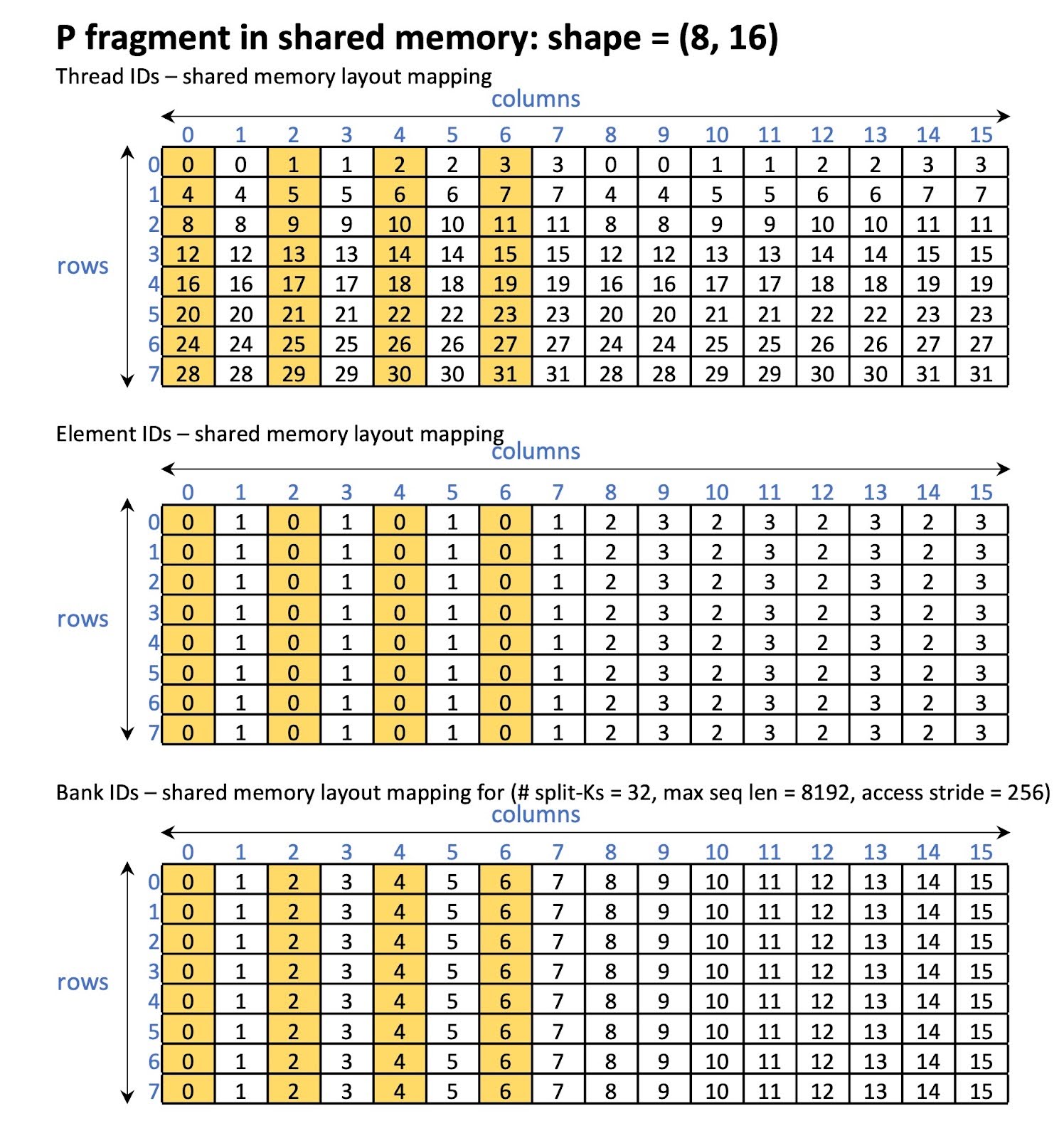
图 15 P 片段在交换前共享内存中的情况
解决方案:
我们以避免银行冲突的方式对共享内存中 P 加载/存储的布局进行洗牌。换句话说,我们使用洗牌后的布局存储 QKT 结果( C 片段)并加载它们( P 片段)。此外,我们不再使用依赖于每个线程块中令牌数量的原始内存访问步长,而是使用片段的列大小作为步长,这是恒定的。因此, P 片段的加载和存储始终是连续的。
C 和 P 片段的新布局如图 16 所示。在新布局下,可以保证并行访问 16 个银行,如图 17 所示。
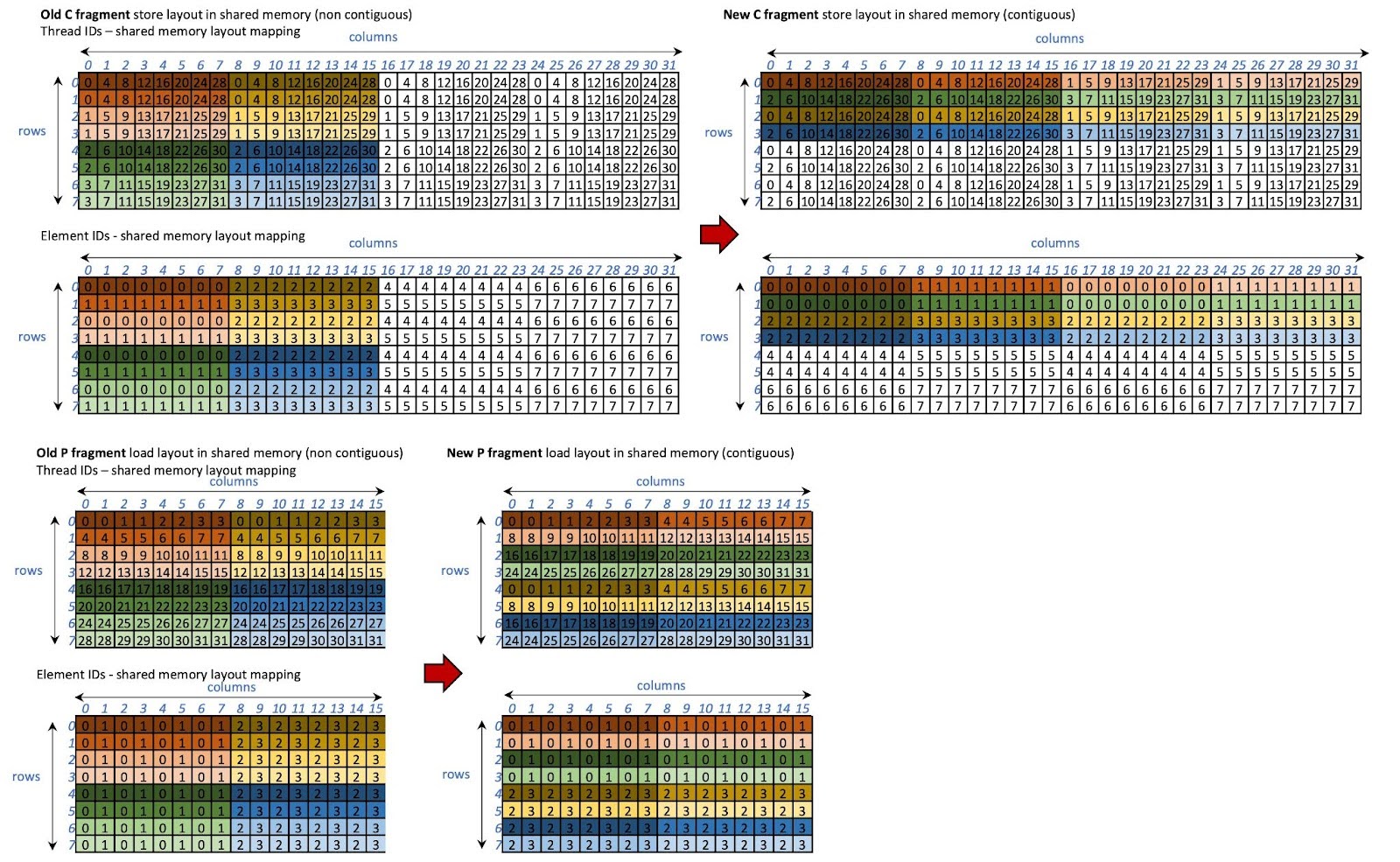
图 16 C 和 P 片段的交错布局
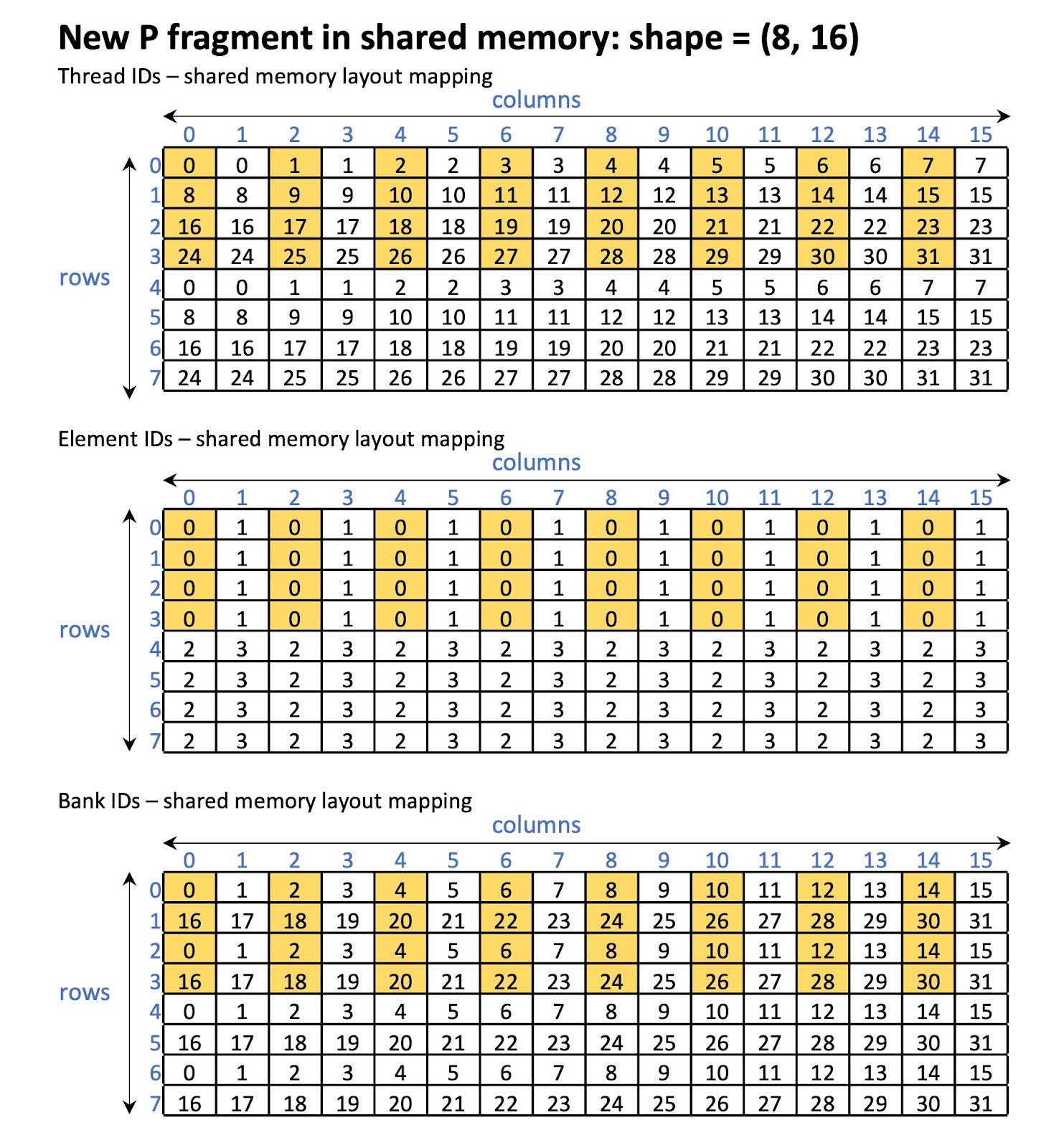
图 17 交错后的 P 片段在共享内存中
表 14 优化 9 对 INT4 GQA(按行量化)的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 与 FD 对比 | 与 CU 基线对比 | |||
| 基准 | 选项 9 | 基准 | 选项 9 | |||||
| 32 | 137 | 143 | 98 | 262 | 250 | 365 | 1.39 | 1.46 |
| 64 | 234 | 257 | 167 | 305 | 278 | 429 | 1.41 | 1.54 |
| 128 | 432 | 455 | 299 | 331 | 314 | 479 | 1.45 | 1.52 |
| 256 | 815 | 866 | 549 | 351 | 331 | 521 | 1.48 | 1.58 |
| 512 | 1581 | 1659 | 1060 | 362 | 345 | 540 | 1.49 | 1.56 |
表 15:针对 INT4 GQA(分组量化,分组数为 4)的优化 9 的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CUDA_WMMA | FD | CUDA_WMMA | 与 FD | 与 CUDA_WMMA Opt 6 | |||
| 选项 6 | 选项 9 | 选项 6 | 选项 9 | |||||
| 32 | 129 | 116 | 105 | 325 | 364 | 400 | 1.23 | 1.10 |
| 64 | 219 | 195 | 174 | 385 | 431 | 484 | 1.26 | 1.12 |
| 128 | 392 | 347 | 302 | 429 | 484 | 558 | 1.30 | 1.15 |
| 256 | 719 | 638 | 560 | 468 | 527 | 601 | 1.28 | 1.14 |
| 512 | 1375 | 1225 | 1065 | 489 | 550 | 632 | 1.29 | 1.15 |
优化 10:为 INT4 反量化填充共享内存
问题分析:
当内核从全局内存读取 INT4 K 或 V 缓存后,它执行反量化并将结果(BF16)存储在共享内存中。然后,通过 WMMA 接口将 BF16 数据从共享内存加载到 WMMA 片段。我们观察到 K 和 V 访问都存在大量的银行冲突。例如,对于 K 存储,只有 32 个银行中的 4 个被并行访问。对于 K 加载,16 个银行被并行访问。同样, V 存储和加载也存在这种情况。请参见解决方案部分的图表。
解决方案:
我们通过填充共享内存来减少银行冲突。具体来说,我们为每一行填充 2 个。也就是说, K 的行步长变为 F_K + 2,V 的行步长变为 F_N + 2( F_K 和 F_N 分别是 K 和 V WMMA 片段的固定宽度)。通过这种优化,我们能够将银行冲突减少 1.8 倍,如图 18 所示。
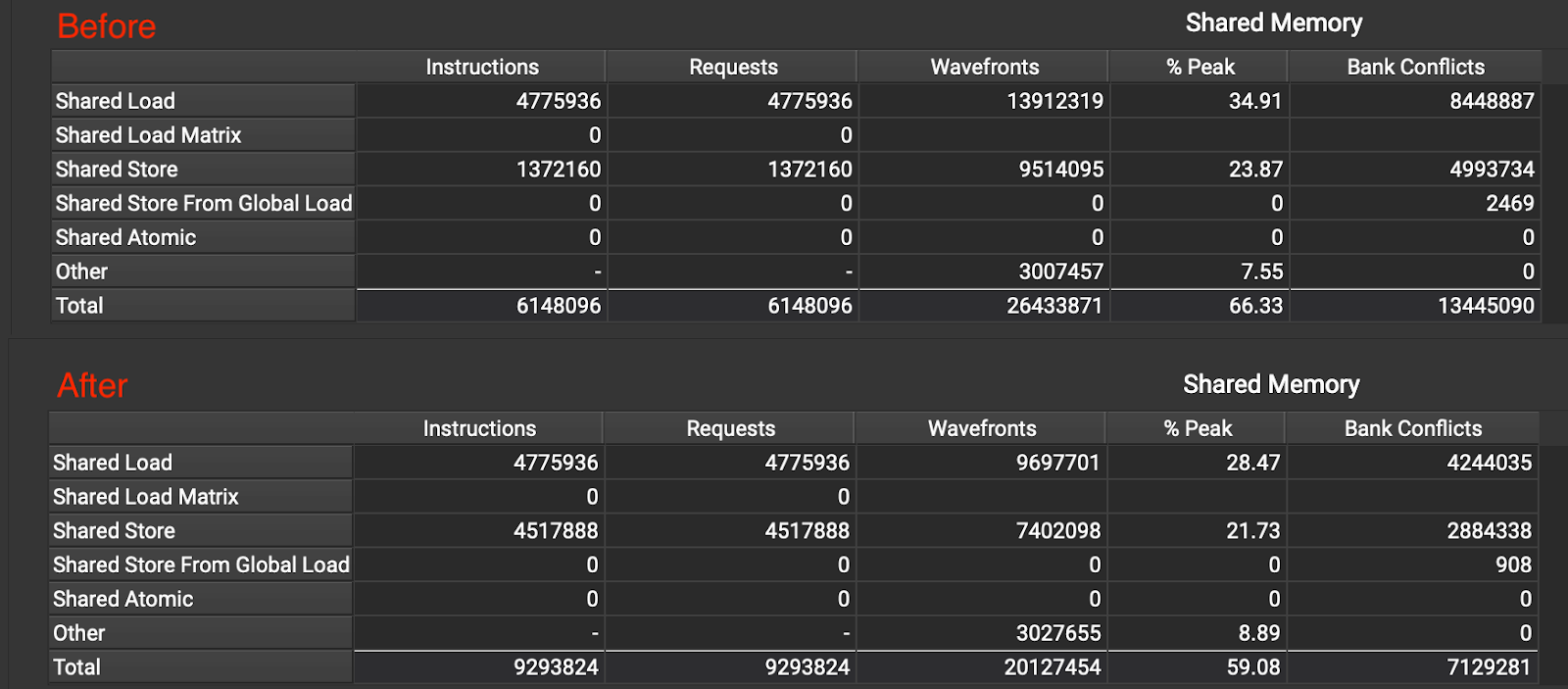
图 18 优化前后的银行冲突
经过优化 10 后,对于 K 存储,32 个银行并行访问(如图 19 所示),而对于 K 加载,29 个银行并行访问(如图 20 所示)。

图 19 带填充和不带填充的 K 片段存储共享内存布局

图 20 K 片段负载带填充和不带填充的共享内存布局
表 16 优化 10 对 INT4 GQA(按行量化)的性能
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CU | FD | CU | 对比 FD | 对比 CU 基线 | |||
| 基准 | 选项 10 | 基准 | 选项 10 | |||||
| 32 | 137 | 143 | 94 | 262 | 250 | 380 | 1.45 | 1.52 |
| 64 | 234 | 257 | 151 | 305 | 278 | 475 | 1.55 | 1.71 |
| 128 | 432 | 455 | 266 | 331 | 314 | 538 | 1.63 | 1.71 |
| 256 | 815 | 866 | 489 | 351 | 331 | 586 | 1.67 | 1.77 |
| 512 | 1581 | 1659 | 930 | 362 | 345 | 616 | 1.70 | 1.79 |
表 17 优化 10 的性能(INT4 GQA 分组量化,分组数 = 4)
| 批处理大小 | 时间(微秒) | 带宽(GB/s) | 加速 | |||||
| FD | CUDA_WMMA | FD | CUDA_WMMA | 与 FD 比较 | 与 CUDA_WMMA Opt 6 比较 | |||
| Opt 6 | 选项 10 | 选项 6 | 选项 10 | |||||
| 32 | 129 | 116 | 99 | 325 | 364 | 425 | 1.31 | 1.17 |
| 64 | 219 | 195 | 161 | 385 | 431 | 523 | 1.36 | 1.21 |
| 128 | 392 | 347 | 282 | 429 | 484 | 598 | 1.39 | 1.23 |
| 256 | 719 | 638 | 509 | 468 | 527 | 662 | 1.41 | 1.25 |
| 512 | 1375 | 1225 | 965 | 489 | 550 | 698 | 1.43 | 1.27 |
性能评估
微基准测试结果
我们还使用我们的优化内核评估了 BF16 GQA 性能(如表 19 所示)。CU 在 BF16 方面通常表现不如 FD 和 FA。这是预期的,因为我们的优化主要集中在 INT4 上。
虽然 INT4 GQA 的效率仍然不如 BF16 GQA(见实现的带宽),但值得注意的是,当比较 FD BF16 GQA 性能与 CU INT4 GQA 性能时,我们可以看到 INT4 的延迟小于 BF16。
表 19:CU 优化后 BF16 GQA 和 INT GQA 的性能
在 A100 上
| 时间(微秒) | BF16 GQA | INT4 GQA | ||||||
| 批处理大小 | FD | FA | CU 之前 | CU 之后 | FD | FA | CU 之前 | CU 之后 |
| 32 | 139 | 133 | 183 | 163 | 137 | - | 143 | 94 |
| 64 | 245 | 229 | 335 | 276 | 234 | - | 257 | 151 |
| 128 | 433 | 555 | 596 | 517 | 432 | - | 455 | 266 |
| 256 | 826 | 977 | 1127 | 999 | 815 | - | 866 | 489 |
| 512 | 1607 | 1670 | 2194 | 1879 | 1581 | - | 1659 | 930 |
| 有效带宽(GB/s) | BF16 GQA | INT4 GQA | ||||||
| 批处理大小 | FD | FA | CU 之前 | CU 之后 | FD | FA | CU 之前 | CU 之后 |
| 32 | 965 | 1012 | 736 | 824 | 262 | - | 250 | 380 |
| 64 | 1097 | 1175 | 802 | 972 | 305 | - | 278 | 475 |
| 128 | 1240 | 968 | 901 | 1039 | 331 | - | 314 | 538 |
| 256 | 1301 | 1100 | 954 | 1075 | 351 | - | 331 | 586 |
| 512 | 1338 | 1287 | 980 | 1144 | 362 | - | 345 | 616 |
在 H100 上
| 时间(微秒) | BF16 GQA | INT4 GQA | ||||||
| 批处理大小 | FD | FA | CU 之前 | CU 之后 | FD | FA | CU 之前 | CU 之后 |
| 32 | 91 | 90 | 114 | 100 | 70 | - | 96 | 64 |
| 64 | 148 | 146 | 200 | 183 | 113 | - | 162 | 101 |
| 128 | 271 | 298 | 361 | 308 | 205 | - | 294 | 170 |
| 256 | 515 | 499 | 658 | 556 | 389 | - | 558 | 306 |
| 512 | 1000 | 1011 | 1260 | 1066 | 756 | - | 1066 | 575 |
| 有效带宽(GB/s) | BF16 GQA | INT4 GQA | ||||||
| 批处理大小 | FD | FA | CU 之前 | CU 之后 | FD | FA | CU 之前 | CU 之后 |
| 32 | 1481 | 1496 | 1178 | 1341 | 511 | - | 371 | 560 |
| 64 | 1815 | 1840 | 1345 | 1470 | 631 | - | 443 | 710 |
| 128 | 1982 | 1802 | 1487 | 1743 | 699 | - | 487 | 844 |
| 256 | 2087 | 2156 | 1634 | 1934 | 736 | - | 513 | 935 |
| 512 | 2150 | 2127 | 1706 | 2015 | 757 | - | 537 | 996 |
端到端结果
我们在 Llama 2 70B 上对优化的 INT4 GQA 内核进行了评估。我们在 8 个 H100 GPU 上运行了模型端到端,但只报告了解码延迟。我们使用 FP8 FFN(前馈网络)来强调解码阶段的注意力性能。我们将批处理大小从 1 到 256,上下文长度从 2,048(2K)到 16,384(16K)进行变化。端到端性能结果如图所示。
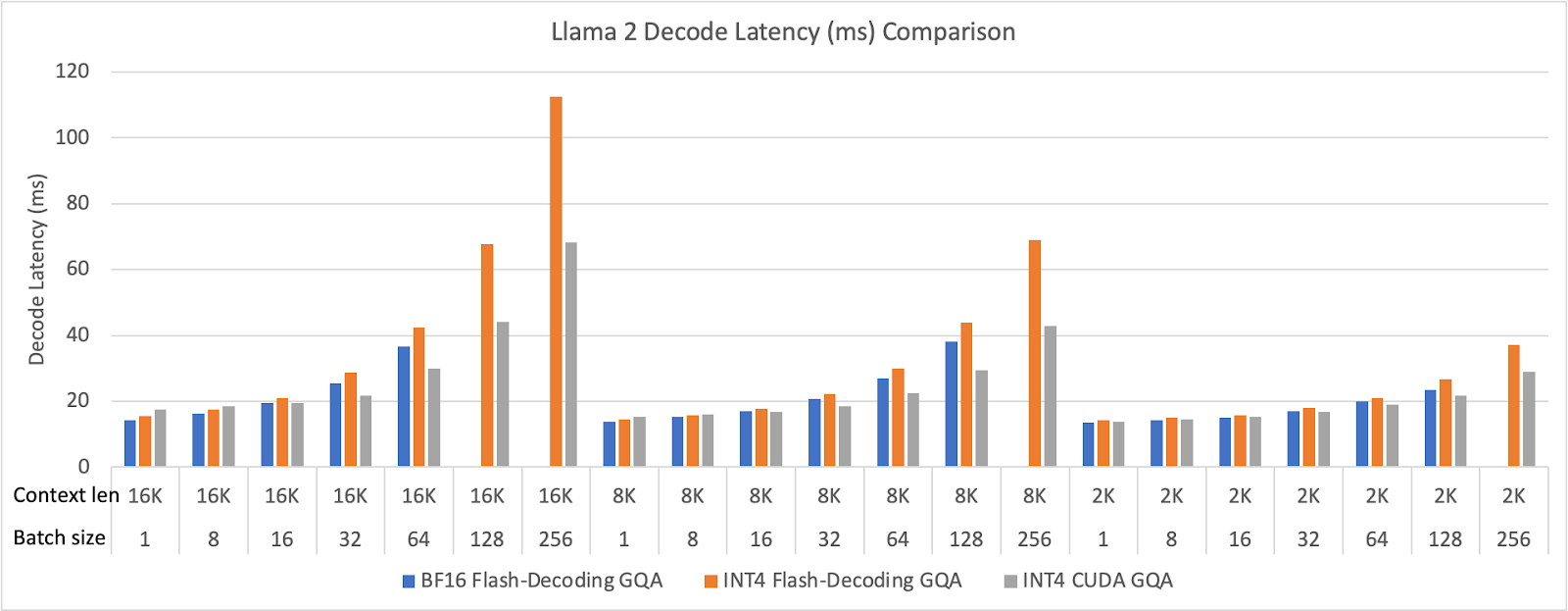
图 21 Meta Llama 2 解码延迟(毫秒)比较(BF16 GQA 在大批量配置中内存不足)
代码
如果您感兴趣,请在此处查看我们的代码。如果您有任何问题,请随时在 GitHub 上创建一个问题,我们将很乐意帮助您。欢迎您的贡献!