欢迎来到理解 PyTorch 自动微分引擎系列的最后一篇!如果你还没有阅读第 1 篇和第 2 篇,请现在阅读它们,以便了解 PyTorch 如何为反向传播创建计算图!
本文基于 PyTorch v1.11 版本,因此一些突出显示的部分可能在不同版本中有所不同。
PyTorch 自动微分图执行
上一篇文章展示了 PyTorch 在执行正向传播时如何构建计算图来计算输出相对于输入的导数。现在我们将通过查看整个过程,从 Python 到 C++底层的内部实现,来了解反向传播的执行是如何协调和完成的。
当从 Python 调用 backward() / grad() 时会发生什么
使用 variable.backward()
在我们完成所有计算并将输入设置为需要梯度后,我们调用 .backward() 对结果进行反向传播执行。
>>> x = torch.tensor([0.5, 0.75], requires_grad=True)
>>> y = torch.exp(x).sum()
>>> y.backward()
在张量上调用 .backward() 将导致调用 torch.autograd.backward() 。
# torch/_tensor.py
def backward(self, gradient=None, retain_graph=None, create_graph=False, inputs=None):
…
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
torch.autograd.backward() 检查参数并在 C++层调用自动微分引擎。
def backward(
tensors: _TensorOrTensors,
grad_tensors: Optional[_TensorOrTensors] = None,
retain_graph: Optional[bool] = None,
create_graph: bool = False,
grad_variables: Optional[_TensorOrTensors] = None,
inputs: Optional[_TensorOrTensors] = None,
) -> None:
…
if inputs is not None and len(inputs) == 0:
raise RuntimeError("'inputs' argument to backward() cannot be empty.")
tensors = (tensors,) if isinstance(tensors, torch.Tensor) else tuple(tensors)
inputs = (inputs,) if isinstance(inputs, torch.Tensor) else \
tuple(inputs) if inputs is not None else tuple()
grad_tensors_ = _tensor_or_tensors_to_tuple(grad_tensors, len(tensors))
grad_tensors_ = _make_grads(tensors, grad_tensors_)
if retain_graph is None:
retain_graph = create_graph
Variable._execution_engine.run_backward(
tensors, grad_tensors_, retain_graph, create_graph, inputs,
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
首先,无论是否指定了 grad_tensors 参数,都会调用 _make_grads 函数。这用于检查提供的 grad_tensors 或通过查看 tensors 参数值的形状来指定它们的默认值。请查看第一篇博客文章,了解反向传播中 grad_tensors 的默认值详情。此函数仅提供如果最初未指定,则向量雅可比积的向量。
在上述代码中, Variable 有一个在 torch.autograd.variable 中定义的 _execution_engine 属性,其类型为 ImperativeEngine ;C++引擎导出到 Python 并在 torch/csrc/autograd/python_engine.cpp 中声明。在接下来的章节中,我们将详细解释该对象如何执行反向传播。
注意, torch.autograd.backward 函数有一个 inputs 可选参数。在正向传播中,当我们只想计算输入张量子集的 .grad 字段时,会使用此参数。
>>> x = torch.tensor([0.5, 0.75], requires_grad=True)
>>> y = torch.tensor([0.1, 0.90], requires_grad=True)
>>> z = torch.exp(x * y).sum()
>>> torch.autograd.backward([z], inputs=[x])
>>> x.grad
tensor([0.1051, 1.7676])
>>> y.grad # None
>>>
使用 torch.autograd.grad
backward() 的一个替代方案是使用 torch.autograd.grad() 。与 backward() 相比,主要区别在于 grad() 返回一个包含相对于 outputs 的 inputs kwargs 梯度的张量元组,而不是将它们存储在张量的 .grad 字段中。正如你所看到的,下面的 grad() 代码与反向传播非常相似。
def grad(
outputs: _TensorOrTensors,
inputs: _TensorOrTensors,
grad_outputs: Optional[_TensorOrTensors] = None,
retain_graph: Optional[bool] = None,
create_graph: bool = False,
only_inputs: bool = True,
allow_unused: bool = False,
is_grads_batched: bool = False
) -> Tuple[torch.Tensor, ...]:
outputs = (outputs,) if isinstance(outputs, torch.Tensor) else tuple(outputs)
inputs = (inputs,) if isinstance(inputs, torch.Tensor) else tuple(inputs)
overridable_args = outputs + inputs
if has_torch_function(overridable_args):
return handle_torch_function(
grad,
overridable_args,
outputs,
inputs,
grad_outputs=grad_outputs,
retain_graph=retain_graph,
create_graph=create_graph,
only_inputs=only_inputs,
allow_unused=allow_unused,
)
grad_outputs_ = _tensor_or_tensors_to_tuple(grad_outputs, len(outputs))
grad_outputs_ = _make_grads(outputs, grad_outputs_)
if retain_graph is None:
retain_graph = create_graph
if is_grads_batched:
# …. It will not be covered here
else:
return Variable._execution_engine.run_backward(
outputs, grad_outputs_, retain_graph, create_graph, inputs,
allow_unused, accumulate_grad=False) # Calls into the C++ engine to run the backward pass
图 1 显示了计算图,其中 backward() 和 grad() 参数分别用红色和蓝色突出显示:
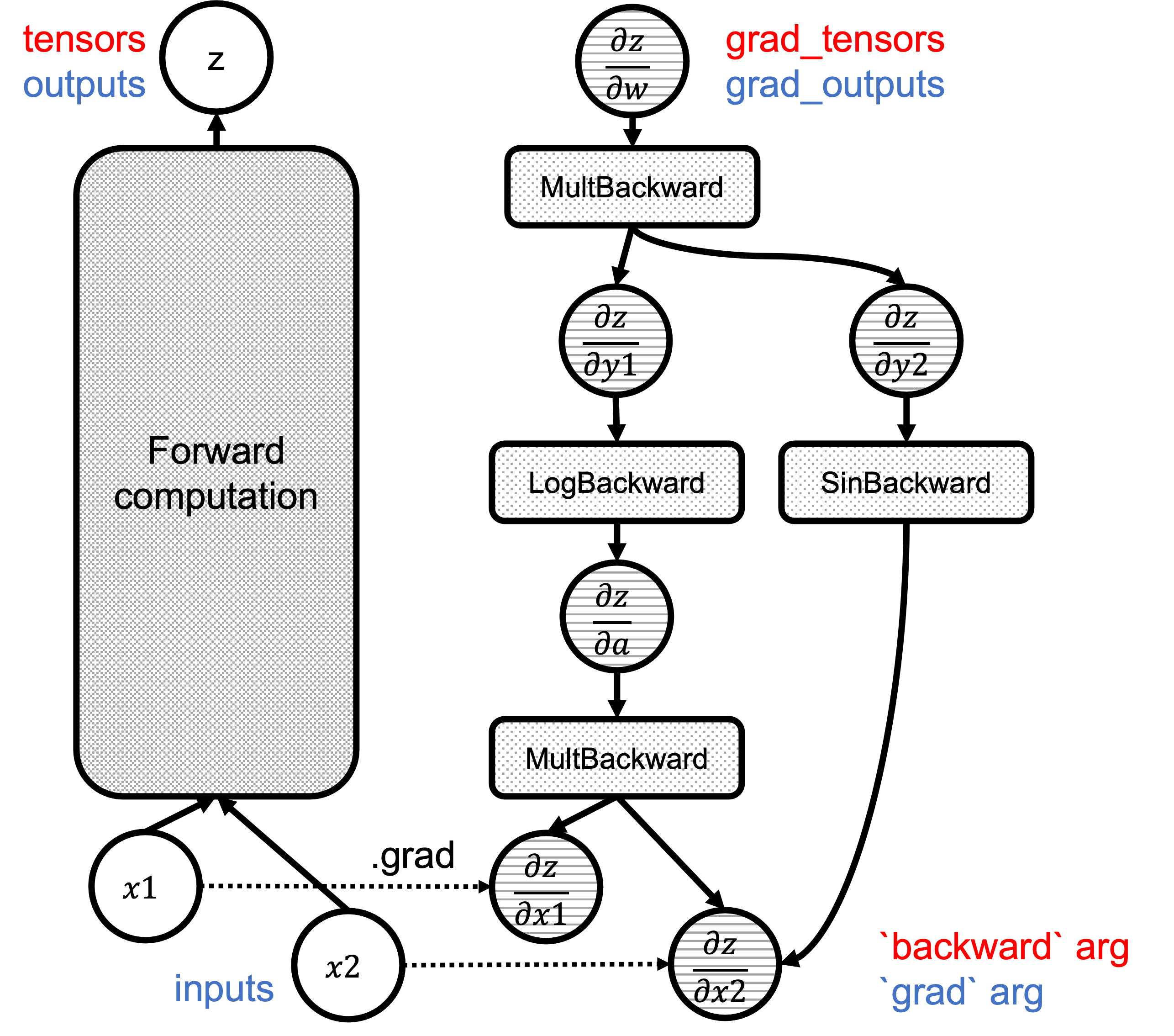
图 1:图中`backward`/`grad`参数的对应关系。
深入了解 Autograd 引擎
更新概念:节点和边
正如我们在 2 中看到的,计算图由 Node 和 Edge 对象组成。如果您还没有阅读过那篇文章,请务必阅读。
节点
Node 对象定义在 torch/csrc/autograd/function.h 中,并为关联函数提供 operator() 的重载以及用于图遍历的边列表。请注意, Node 是 autograd 函数继承并重写 apply 方法以执行反向函数的基类。
struct TORCH_API Node : std::enable_shared_from_this<Node> {
...
/// Evaluates the function on the given inputs and returns the result of the
/// function call.
variable_list operator()(variable_list&& inputs) {
...
}
protected:
/// Performs the `Node`'s actual operation.
virtual variable_list apply(variable_list&& inputs) = 0;
…
edge_list next_edges_;
uint64_t topological_nr_ = 0;
…
每个节点对象都有一个名为 topological_nr_ 的属性。这个数字用于优化图执行,因为它允许在特定条件下丢弃图分支。拓扑编号是此节点与任何叶节点之间的最长距离,如图 2 所示。其主要特性是对于有向图 topo_nr(x) < topo_nr(y) 中的任意一对节点 x 、 y ,意味着从 x 到 y 没有路径。因此,这允许减少需要遍历的图中的路径数量。请查看 topological_nr()方法注释以获取更多详细信息。
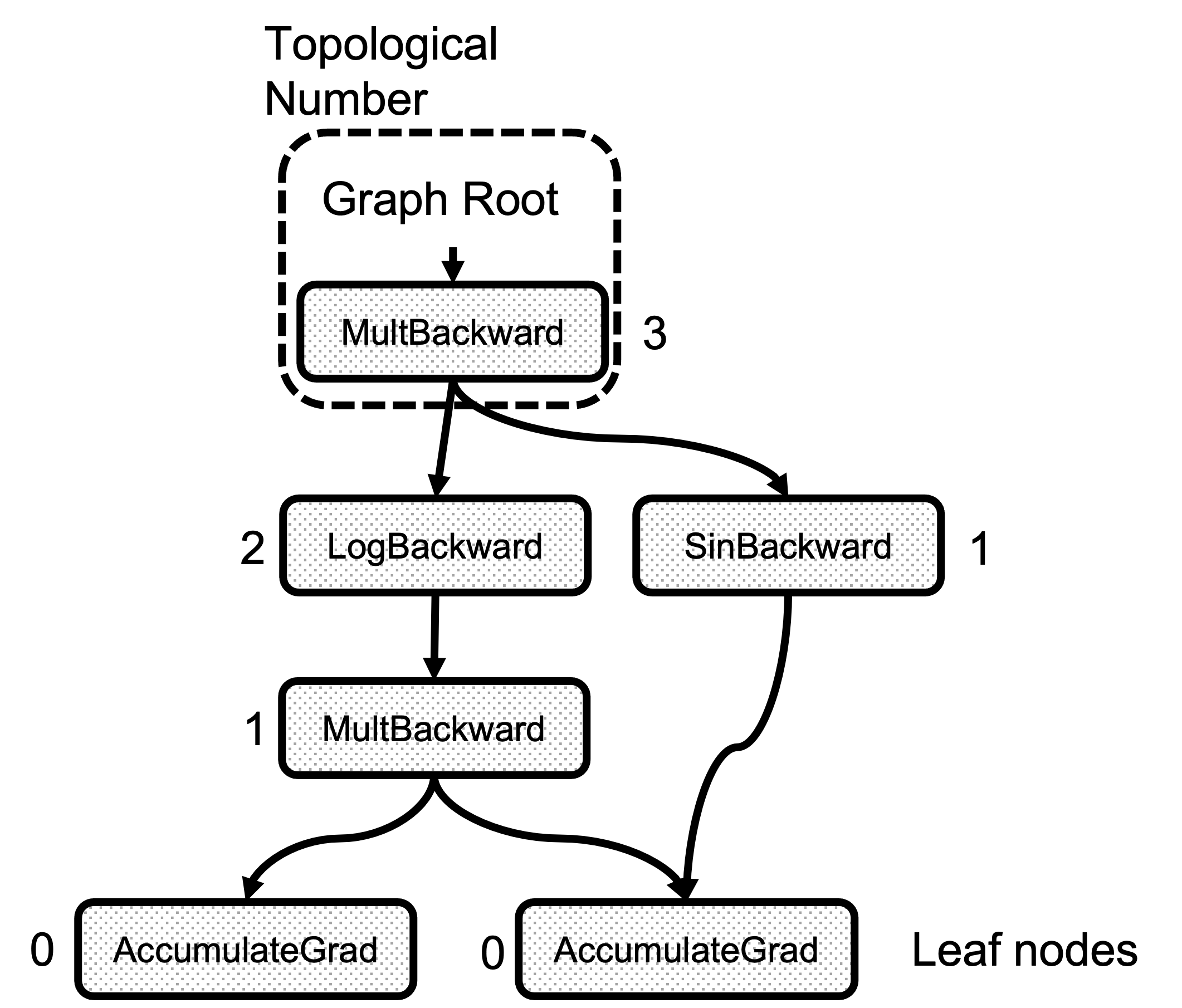
图 2:拓扑数计算的示例
边
Edge 对象将 Node 连接在一起,其实现方法简单。
struct Edge {
...
/// The function this `Edge` points to.
std::shared_ptr<Node> function;
/// The identifier of a particular input to the function.
uint32_t input_nr;
};
这只需要一个指向 Node 的函数指针以及一个输入数字,该数字是此边指向的前向函数输出的索引。在调用“函数”之前准备梯度集时,我们知道从这条边流出的应该累积在“input_nr”第个参数中。注意,这里的输入/输出名称是颠倒的,这是反向函数的输入。 Edge 对象使用 gradient_edge 函数方法构建。
Edge gradient_edge(const Variable& self) {
if (const auto& gradient = self.grad_fn()) {
return Edge(gradient, self.output_nr());
} else {
return Edge(grad_accumulator(self), 0);
}
}
进入 C++领域
一旦调用 torch.autograd.backward() , THPEngine_run_backward 例程开始图遍历。以下是函数体的架构:
PyObject *THPEngine_run_backward(PyObject *self, PyObject *args, PyObject *kwargs)
{
HANDLE_TH_ERRORS
PyObject *tensors = nullptr;
PyObject *grad_tensors = nullptr;
unsigned char keep_graph = 0;
unsigned char create_graph = 0;
PyObject *inputs = nullptr;
// Convert the python arguments to C++ objects
const char *accepted_kwargs[] = { // NOLINT
"tensors", "grad_tensors", "keep_graph", "create_graph", "inputs",
"allow_unreachable", "accumulate_grad", nullptr
};
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "OObb|Obb", (char**)accepted_kwargs,
&tensors, &grad_tensors, &keep_graph, &create_graph, &inputs, &allow_unreachable, &accumulate_grad))
// Prepare arguments
for(const auto i : c10::irange(num_tensors)) {
// Check that the tensors require gradients
}
std::vector<Edge> output_edges;
if (inputs != nullptr) {
// Prepare outputs
}
{
// Calls the actual autograd engine
pybind11::gil_scoped_release no_gil;
outputs = engine.execute(roots, grads, keep_graph, create_graph, accumulate_grad, output_edges);
}
// Clean up and finish
}
首先,我们将 PyObject 参数转换为实际的 C++对象后准备输入参数。 tensors 列表包含我们从其中开始反向传播的张量。这些张量通过 torch::autograd::impl::gradient_edge 转换为边,并添加到名为 roots 的列表中,图遍历从这里开始。
edge_list roots;
roots.reserve(num_tensors);
variable_list grads;
grads.reserve(num_tensors);
for(const auto i : c10::irange(num_tensors)) {
PyObject *_tensor = PyTuple_GET_ITEM(tensors, i);
const auto& variable = THPVariable_Unpack(_tensor);
auto gradient_edge = torch::autograd::impl::gradient_edge(variable);
roots.push_back(std::move(gradient_edge));
PyObject *grad = PyTuple_GET_ITEM(grad_tensors, i);
if (THPVariable_Check(grad)) {
const Variable& grad_var = THPVariable_Unpack(grad);
grads.push_back(grad_var);
}
}
现在,如果 inputs 参数已在 backward 中指定,或者我们使用了 torch.autograd.grad api,则以下代码将在计算结束时创建一个边列表,以累积指定张量中的梯度。引擎随后使用此列表来优化执行,因为它不会在所有叶节点中添加梯度,而只添加指定的那些。
std::vector<Edge> output_edges;
if (inputs != nullptr) {
int num_inputs = PyTuple_GET_SIZE(inputs);
output_edges.reserve(num_inputs);
for (const auto i : c10::irange(num_inputs)) {
PyObject *input = PyTuple_GET_ITEM(inputs, i);
const auto& tensor = THPVariable_Unpack(input);
const auto output_nr = tensor.output_nr();
auto grad_fn = tensor.grad_fn();
if (!grad_fn) {
grad_fn = torch::autograd::impl::try_get_grad_accumulator(tensor);
}
if (accumulate_grad) {
tensor.retain_grad();
}
if (!grad_fn) {
output_edges.emplace_back(std::make_shared<Identity>(), 0);
} else {
output_edges.emplace_back(grad_fn, output_nr);
}
}
}
下一步是实际的图遍历和节点函数执行,最后进行清理并返回。
{
// Calls the actual autograd engine
pybind11::gil_scoped_release no_gil;
auto& engine = python::PythonEngine::get_python_engine();
outputs = engine.execute(roots, grads, keep_graph, create_graph, accumulate_grad, output_edges);
}
// Clean up and finish
}
开始实际执行
engine.execute 存在于 torch/csrc/autograd/engine.cpp
这里有两个区分的步骤:
分析图以找到函数之间的依赖关系 创建遍历图的工人线程
用于执行的数据结构
GraphTask
所有执行元数据都由 torch/csrc/autograd/engine.h 中的 GraphTask 类管理
struct GraphTask: std::enable_shared_from_this<GraphTask> {
std::atomic<uint64_t> outstanding_tasks_{0};
// …
std::unordered_map<Node*, InputBuffer> not_ready_;
std::unordered_map<Node*, int> dependencies_;
struct ExecInfo {
// …
};
std::unordered_map<Node*, ExecInfo> exec_info_;
std::vector<Variable> captured_vars_;
// …
std::shared_ptr<ReadyQueue> cpu_ready_queue_;
};
这里我们看到一系列用于维护执行状态的变量。 outstanding_tasks_ 跟踪反向传播完成前剩余的任务数量。 not_ready_ 保存尚未准备就绪的 Node 的输入参数。 dependencies_ 跟踪一个 Node 的前驱数量。当计数达到 0 时, Node 准备就绪;它被放入就绪队列以供稍后检索和执行。
只有在指定 inputs 参数或调用 autograd.grad() 时,才会使用 exec_info_ 和相关的 ExecInfo 结构。它们允许在图中进行过滤路径,因为只有 inputs 列表中的变量才计算梯度。
如果我们使用了 torch.autograd.grad() api 而不是 torch.autograd.backward() ,则 captured_vars_ 是临时存储图执行结果的地方,因为 grad() 返回梯度作为张量,而不是仅仅填充输入的 .grad 字段。
节点任务
NodeTask 结构体是一个基本类,它包含一个指向要执行的节点的 fn_ 指针,以及一个用于存储该函数输入参数的 inputs_ 缓冲区。请注意,反向传播过程中执行的是 derivatives.yaml 文件中指定的导数函数,或者在使用自定义函数时,如第二篇博客中所述,由用户提供的反向函数。
inputs_ 缓冲区也是之前执行函数的输出梯度汇总的地方,它被定义为具有在给定位置累积值的 std::vector<Variable> 容器。
struct NodeTask {
std::weak_ptr<GraphTask> base_;
std::shared_ptr<Node> fn_;
// This buffer serves as an implicit "addition" node for all of the
// gradients flowing here. Once all the dependencies are finished, we
// use the contents of this buffer to run the function.
InputBuffer inputs_;
};
图根
GraphRoot 是一个特殊函数,用于在单个位置存储多个输入变量。代码很简单,它只作为变量的容器。
struct TORCH_API GraphRoot : public Node {
GraphRoot(edge_list functions, variable_list inputs)
: Node(std::move(functions)),
outputs(std::move(inputs)) {
for (const auto& t : outputs) {
add_input_metadata(t);
}
}
variable_list apply(variable_list&& inputs) override {
return outputs;
}
AccumulateGrad
此函数在创建图时设置于 gradient_edge ,当 Variable 对象没有 grad_fn 时。也就是说,它是一个叶子节点。
if (const auto& gradient = self.grad_fn()) {
// …
} else {
return Edge(grad_accumulator(self), 0);
}
函数体定义在 torch/csrc/autograd/functions/accumulate_grad.cpp 中,它本质上累积对象 .grad 属性中的输入梯度。
auto AccumulateGrad::apply(variable_list&& grads) -> variable_list {
check_input_variables("AccumulateGrad", grads, 1, 0);
…
at::Tensor new_grad = callHooks(variable, std::move(grads[0]));
std::lock_guard<std::mutex> lock(mutex_);
at::Tensor& grad = variable.mutable_grad();
accumulateGrad(
variable,
grad,
new_grad,
1 + !post_hooks().empty() /* num_expected_refs */,
[&grad](at::Tensor&& grad_update) { grad = std::move(grad_update); });
return variable_list();
}
}} // namespace torch::autograd
accumulateGrad 对张量格式进行多项检查,最终执行 variable_grad += new_grad; 累积操作。
准备执行图
现在,让我们来遍历 Engine::execute 。首先要做的事情除了参数一致性检查之外,就是创建我们上面描述的实际 GraphTask 对象。该对象保存了图执行的元数据。
auto Engine::execute(const edge_list& roots,
const variable_list& inputs,
bool keep_graph,
bool create_graph,
bool accumulate_grad,
const edge_list& outputs) -> variable_list {
validate_outputs(roots, const_cast<variable_list&>(inputs), [](const std::string& msg) {
return msg;
});
// Checks
auto graph_task = std::make_shared<GraphTask>(
/* keep_graph */ keep_graph,
/* create_graph */ create_graph,
/* depth */ not_reentrant_backward_call ? 0 : total_depth + 1,
/* cpu_ready_queue */ local_ready_queue);
// If we receive a single root, skip creating extra root node
// …
// Prepare graph by computing dependencies
// …
// Queue the root
// …
// launch execution
// …
}
创建 GraphTask 之后,如果我们只有一个根节点,我们会使用其关联的函数。如果我们有多个根节点,我们会创建一个特殊的 GraphRoot 对象,如之前所述。
bool skip_dummy_node = roots.size() == 1;
auto graph_root = skip_dummy_node ?
roots.at(0).function :
std::make_shared<GraphRoot>(roots, inputs);
下一步是在 GraphTask 对象中填充 dependencies_ 映射,因为引擎必须知道何时可以执行一个任务。这里的 outputs 是传递给 Python 中 torch.autograd.backward() 调用的 inputs 参数。但是在这里,我们反转了名称,因为相对于前向传递的输入的梯度现在是反向传递的输出。从现在开始,不再有前向/反向的概念,只有图遍历和执行。
auto min_topo_nr = compute_min_topological_nr(outputs);
// Now compute the dependencies for all executable functions
compute_dependencies(graph_root.get(), *graph_task, min_topo_nr);
if (!outputs.empty()) {
graph_task->init_to_execute(*graph_root, outputs, accumulate_grad, min_topo_nr);
}
我们首先对图进行预处理以执行节点。首先调用 compute_min_topological_nr 以获取 outputs 中指定的张量的最小拓扑编号(如果没有为 .backward 或 input 提供 inputs kwarg,则为 0)。此计算会修剪图中导致我们不希望/不需要计算梯度的输入变量的路径。
其次是 compute_dependencies 调用。这是一个非常简单的图遍历函数,从根 Node 开始,并对 node.next_edges() 中的每条边,它都会增加 dependencies_ 中的计数器。图 3 显示了示例图中依赖关系计算的结果。请注意,任何节点的依赖关系数量只是到达该节点的边的数量。
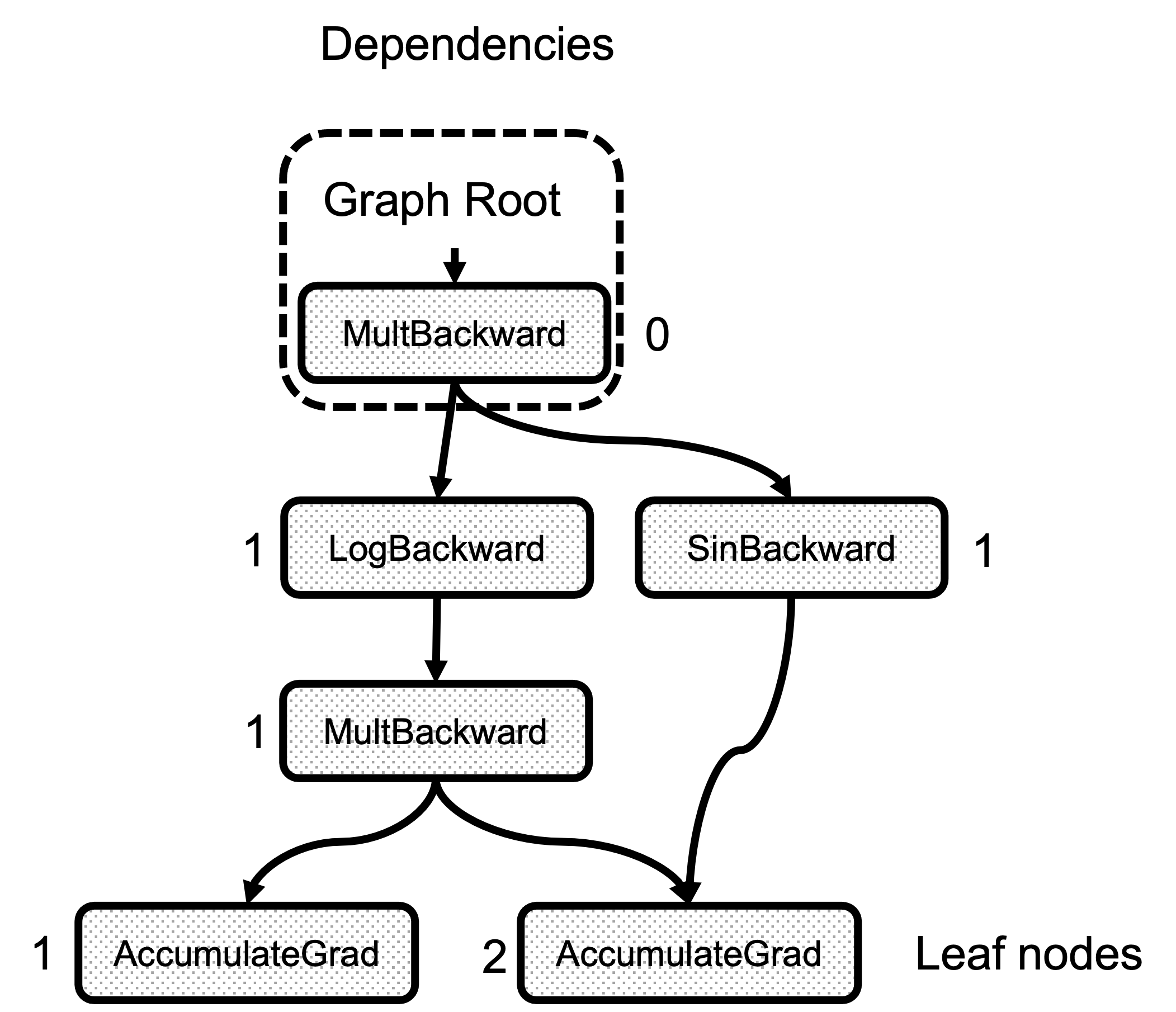
图 3:每个节点的依赖关系数量
最后是 init_to_execute 调用,这是在 Python backward 调用中指定 inputs 时填充 GraphTask::exec_info_ 映射的调用。它再次遍历图,从根开始,并将计算给定 inputs 梯度的必要中间节点记录在 exec_info_ 映射中。
// Queue the root
if (skip_dummy_node) {
InputBuffer input_buffer(roots.at(0).function->num_inputs());
auto input = inputs.at(0);
input_buffer.add(roots.at(0).input_nr,
std::move(input),
input_stream,
opt_next_stream);
execute_with_graph_task(graph_task, graph_root, std::move(input_buffer));
} else {
execute_with_graph_task(graph_task, graph_root, InputBuffer(variable_list()));
}
// Avoid a refcount bump for the Future, since we check for refcount in
// DistEngine (see TORCH_INTERNAL_ASSERT(futureGrads.use_count() == 1)
// in dist_engine.cpp).
auto& fut = graph_task->future_result_;
fut->wait();
return fut->value().toTensorVector();
}
现在,我们准备开始实际执行,通过创建 InputBuffer 。如果我们只有一个根变量,我们首先将 inputs 张量的值(这是传递给 python 的 gradients )复制到 input_buffer 的位置 0。这是一个小的优化,可以避免无谓地运行 RootNode 。另外,如果图的其他部分不在 cpu 上,我们直接在那个 worker 上开始,而 RootNode 始终放在 cpu 就绪队列中。下面将解释 worker 和就绪队列的详细信息。
另一方面,如果我们有多个根, GraphRoot 对象也包含输入,所以只需要传递一个空的 InputBuffer 。
图遍历和节点执行
设备、线程和队列
在实际执行之前,我们需要看看引擎的结构。
首先,该引擎是支持多线程的,每个设备对应一个线程。例如,调用线程与 CPU 相关联,而额外的线程被创建并与系统中的每个 GPU 或其他设备相关联。每个线程使用线程局部存储中的 worker_device 变量跟踪其设备。此外,线程还有一个任务队列,也位于线程局部存储中的 local_ready_queue ,这是工作被排队等待在 thread_main 函数中执行的地方(该函数将在后面解释)。你可能想知道一个任务应该在哪里执行所选择的设备。 InputBuffer 类有一个 device() 函数,该函数返回所有其张量中的第一个非 CPU 设备。这个函数与 Engine::ready_queue 一起用于选择队列以排队任务。
auto Engine::ready_queue(std::shared_ptr<ReadyQueue> cpu_ready_queue, at::Device device) -> std::shared_ptr<ReadyQueue>{
if (device.type() == at::kCPU || device.type() == at::DeviceType::Meta) {
return cpu_ready_queue;
} else {
// See Note [Allocating GPUs to autograd threads]
return device_ready_queues_.at(device.index());
}
}
ReadyQueue 对象定义在 torch/csrc/autograd/engine.h 中,它是对 std::priority_queue 的简单包装,允许线程在任务为空时等待。 ReadyQueue 的一个有趣特性是它会增加 GraphTask::outstanding_tasks_ 值,该值用于确定执行是否完成。
auto ReadyQueue::push(NodeTask item, bool incrementOutstandingTasks) -> void {
{
std::lock_guard<std::mutex> lock(mutex_);
if (incrementOutstandingTasks) {
std::shared_ptr<GraphTask> graph_task = item.base_.lock();
++graph_task->outstanding_tasks_;
}
heap_.push(std::move(item));
}
not_empty_.notify_one();
}
auto ReadyQueue::pop() -> NodeTask {
std::unique_lock<std::mutex> lock(mutex_);
not_empty_.wait(lock, [this]{ return !heap_.empty(); });
auto task = std::move(const_cast<NodeTask&>(heap_.top())); heap_.pop();
return task;
}
可重入反向
重新进入的回传发生在回传过程中的一项任务再次调用 backward 。这种情况并不常见,但它可以用来减少内存使用,因为它可能避免保存中间结果。更多信息,请查看这个 PyTorch 论坛帖子。
class ReentrantBackward(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
return input.sum()
@staticmethod
def backward(ctx, input):
# Let's compute the backward by using autograd
input = input.detach().requires_grad_()
with torch.enable_grad():
out = input.sum()
out.backward() # REENTRANT CALL!!
return out.detach()
在这里,我们在用户自定义的自动微分函数中调用 backward() 。这种情况可能导致死锁,因为第一个回传需要等待第二个回传完成。但一些内部实现细节可以防止第二个回传完成,如专用小节中所述。
线程初始化
execute_with_graph_task 负责初始化负责计算的线程,并将 root 节点放入产生它的设备的队列中。
c10::intrusive_ptr<at::ivalue::Future> Engine::execute_with_graph_task(
const std::shared_ptr<GraphTask>& graph_task,
std::shared_ptr<Node> graph_root,
InputBuffer&& input_buffer) {
initialize_device_threads_pool();
// Lock mutex for GraphTask.
std::unique_lock<std::mutex> lock(graph_task->mutex_);
auto queue = ready_queue(graph_task->cpu_ready_queue_, input_buffer.device());
if (worker_device == NO_DEVICE) {
set_device(CPU_DEVICE);
graph_task->owner_ = worker_device;
queue->push(NodeTask(graph_task, std::move(graph_root), std::move(input_buffer)));
lock.unlock();
thread_main(graph_task);
worker_device = NO_DEVICE;
} else {
// This deals with reentrant backwards, we will see it later.
}
return graph_task->future_result_;
}
首先,此函数初始化多个线程(每个设备一个),调用 initialize_device_threads_pool() ,其中会发生几件事情:为每个设备创建一个 ReadyQueue 。为每个非 CPU 设备创建一个线程。设置一个线程局部 worker_device 变量来跟踪与线程关联的当前设备。调用 thread_main 函数,线程等待将任务放入它们的队列中。
然后,它根据包含在 input_buffer 中的张量所在的设备检索队列,以放置根节点,使用 ready_queue 函数。现在,主线程(也执行 Python 解释器的线程)的 worker_device 设置为 NO_DEVICE ,它负责执行所有张量都居住在 CPU 上的函数。如果 worker_device 设置为任何其他值,图执行已经启动,并且在运行中的 .backward() 内部调用了 Node ,创建了一个重入的后向调用。这将在后面解释。现在,主线程将任务放入队列并调用 thread_main 。
魔法发生的地方
路程遥远,但最终我们准备好遍历图并执行节点。每个生成的线程和主线程都调用 thread_main 。
auto Engine::thread_main(const std::shared_ptr<GraphTask>& graph_task) -> void {
while (graph_task == nullptr || !graph_task->future_result_->completed()) {
std::shared_ptr<GraphTask> local_graph_task;
{
NodeTask task = local_ready_queue->pop();
if (task.isShutdownTask_) {
break;
}
if (!(local_graph_task = task.base_.lock())) {
// GraphTask for function is no longer valid, skipping further
// execution.
continue;
}
if (task.fn_ && !local_graph_task->has_error_.load()) {
at::ThreadLocalStateGuard tls_guard(local_graph_task->thread_locals_);
try {
GraphTaskGuard guard(local_graph_task);
NodeGuard ndguard(task.fn_);
{
evaluate_function(
local_graph_task,
task.fn_.get(),
task.inputs_,
local_graph_task->cpu_ready_queue_);
}
} catch (std::exception& e) {
thread_on_exception(local_graph_task, task.fn_, e);
}
}
}
// Decrement the outstanding tasks.
--local_graph_task->outstanding_tasks_;
// Check if we've completed execution.
if (local_graph_task->completed()) {
local_graph_task->mark_as_completed_and_run_post_processing();
auto base_owner = local_graph_task->owner_;
if (worker_device != base_owner) {
std::atomic_thread_fence(std::memory_order_release);
ready_queue_by_index(local_graph_task->cpu_ready_queue_, base_owner)
->push(NodeTask(local_graph_task, nullptr, InputBuffer(0)));
}
}
}
}
这里的代码很简单,因为每个线程在线程局部存储中分配了 local_ready_queue 。线程会一直循环,直到图中没有剩余的任务要执行。注意,对于与设备关联的线程,传入的 graph_task 参数是 nullptr ,它们会在 local_ready_queue->pop() 中阻塞,直到队列中有任务被推入。在进行了某些一致性检查(任务类型是关闭,或者图仍然有效)之后,我们到达实际的函数调用在 evaluate_function 。
try {
GraphTaskGuard guard(local_graph_task);
NodeGuard ndguard(task.fn_);
{
evaluate_function(
local_graph_task,
task.fn_.get(),
task.inputs_,
local_graph_task->cpu_ready_queue_);
}
} catch (std::exception& e) {
thread_on_exception(local_graph_task, task.fn_, e);
}
}
调用 evaluate_function 之后,我们通过查看 outstanding_tasks_ 的数量来检查 graph_task 的执行是否完成。这个数字在任务被推入队列时增加,在任务被执行时在 local_graph_task->completed() 中减少。当执行完成时,我们返回结果,这些结果将位于 captured_vars_ ,如果我们调用 torch.autograd.grad() 而不是 torch.autograd.backward() ,因为这个函数返回张量而不是将它们存储在输入的 .grad 属性中。最后,如果主线程正在等待,我们通过发送一个虚拟任务来唤醒它。
// Decrement the outstanding tasks.
--local_graph_task->outstanding_tasks_;
// Check if we've completed execution.
if (local_graph_task->completed()) {
local_graph_task->mark_as_completed_and_run_post_processing();
auto base_owner = local_graph_task->owner_;
if (worker_device != base_owner) {
std::atomic_thread_fence(std::memory_order_release);
ready_queue_by_index(local_graph_task->cpu_ready_queue_, base_owner)
->push(NodeTask(local_graph_task, nullptr, InputBuffer(0)));
}
}
调用函数并解锁新任务
evaluate_function 有三个作用:
运行函数。将结果累积到下一个节点 InputBuffers 。减少下一个节点的依赖计数器,并将依赖计数器为 0 的任务入队执行。
void Engine::evaluate_function(
std::shared_ptr<GraphTask>& graph_task,
Node* func,
InputBuffer& inputs,
const std::shared_ptr<ReadyQueue>& cpu_ready_queue) {
// If exec_info_ is not empty, we have to instrument the execution
auto& exec_info_ = graph_task->exec_info_;
if (!exec_info_.empty()) {
// Checks if the function needs to be executed
if (!fn_info.needed_) {
// Skip execution if we don't need to execute the function.
return;
}
}
auto outputs = call_function(graph_task, func, inputs);
auto& fn = *func;
if (!graph_task->keep_graph_) {
fn.release_variables();
}
首先,我们检查 exec_info_ 映射的 GraphTask 结构,以确定当前节点是否需要执行。记住,如果这个映射为空,则所有节点都会执行,因为我们正在计算前向传递的所有输入的梯度。
检查之后,通过运行 call_function 来执行函数。其实现非常简单,调用实际的导数函数和已注册的钩子(如果有)。
int num_outputs = outputs.size();
if (num_outputs == 0) {
// Records leaf stream (if applicable)
return;
}
if (AnomalyMode::is_enabled()) {
// check for nan values in result
}
接下来,我们检查函数运行后的输出。如果输出数量为 0,则没有后续节点需要执行,因此可以安全地返回。这是与叶节点关联的 AccumulateGrad 节点的情况。
此外,如果需要,这里还会检查梯度中的 NaN 值。
std::lock_guard<std::mutex> lock(graph_task->mutex_);
for (const auto i : c10::irange(num_outputs)) {
auto& output = outputs[i];
const auto& next = fn.next_edge(i);
if (!next.is_valid()) continue;
我们现在执行了一个 grad_fn ,它为每个关联的前向传递函数输入返回了一个梯度。正如我们在之前的博客文章中看到的,对于这些输入张量中的每一个,我们都有一个 Edge 对象,以及产生它们的函数的 grad_fn 。本质上,反向传播节点中的 Output[0]对应于前向传递关联函数的第一个参数。图 4 显示了反向函数的输出与前向函数的输入之间的关系。请注意, grad_fn C 的输出是 z 相对于 Function C 输入的梯度。
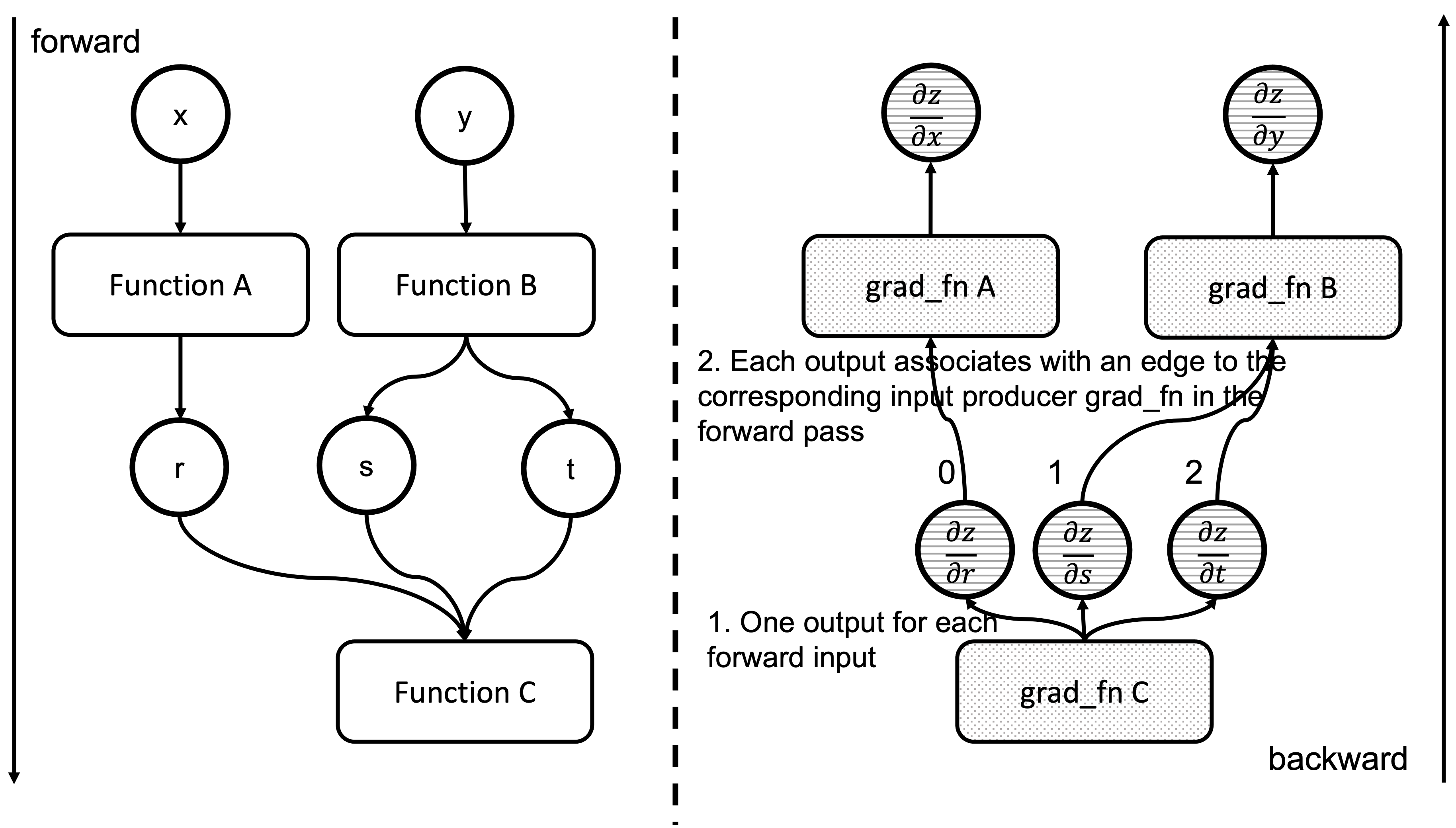
图 4:前向和反向函数的输入输出对应关系
我们现在遍历这些边,检查关联的函数是否准备好执行。
// Check if the next function is ready to be computed
bool is_ready = false;
auto& dependencies = graph_task->dependencies_;
auto it = dependencies.find(next.function.get());
if (it == dependencies.end()) {
auto name = next.function->name();
throw std::runtime_error(std::string("dependency not found for ") + name);
} else if (--it->second == 0) {
dependencies.erase(it);
is_ready = true;
}
auto& not_ready = graph_task->not_ready_;
auto not_ready_it = not_ready.find(next.function.get());
因此,我们检查 graph_task->dependencies_ 映射。我们递减计数器,如果它达到 0,我们将指向边的函数标记为准备执行。接下来,我们准备由下一个边指示的任务的输入缓冲区。
if (not_ready_it == not_ready.end()) {
if (!exec_info_.empty()) {
// Skip functions that aren't supposed to be executed
}
// Creates an InputBuffer and moves the output to the corresponding input position
InputBuffer input_buffer(next.function->num_inputs());
input_buffer.add(next.input_nr,
std::move(output),
opt_parent_stream,
opt_next_stream);
if (is_ready) {
auto queue = ready_queue(cpu_ready_queue, input_buffer.device());
queue->push(
NodeTask(graph_task, next.function, std::move(input_buffer)));
} else {
not_ready.emplace(next.function.get(), std::move(input_buffer));
}
在这里,我们在 graph_task->not_ready_ 映射中查找任务。如果它不存在,我们创建一个新的 InputBuffer 对象,并将当前输出设置在边关联的缓冲区的 input_nr 位置。如果任务准备就绪,我们将其入队到适当的设备 ready_queue 并完成执行。然而,如果任务未就绪且我们之前已见过它,它就存在于 not_ready_map_ 中。
} else {
// The function already has a buffer
auto &input_buffer = not_ready_it->second;
// Accumulates into buffer
input_buffer.add(next.input_nr,
std::move(output),
opt_parent_stream,
opt_next_stream);
if (is_ready) {
auto queue = ready_queue(cpu_ready_queue, input_buffer.device());
queue->push(NodeTask(graph_task, next.function, std::move(input_buffer)));
not_ready.erase(not_ready_it);
}
}
}
}
在这种情况下,我们将输出累积到现有的 input_buffer 而不是创建一个新的。一旦所有任务都处理完毕,工作线程退出循环并完成。整个过程在图 5 的动画中进行了总结。我们看到线程如何查看就绪队列中的任务并递减下一个节点的依赖项,从而解锁它们以供执行。
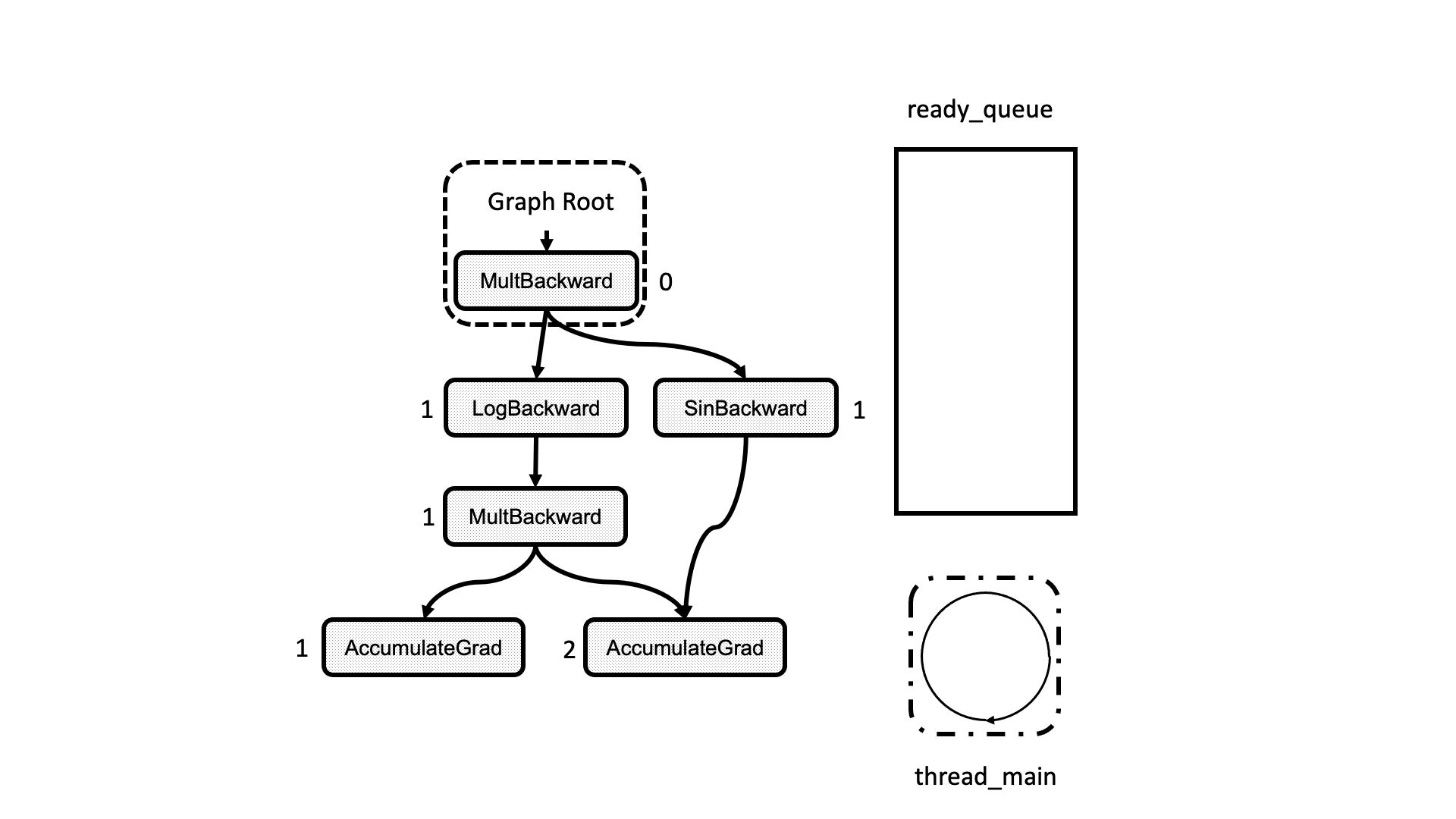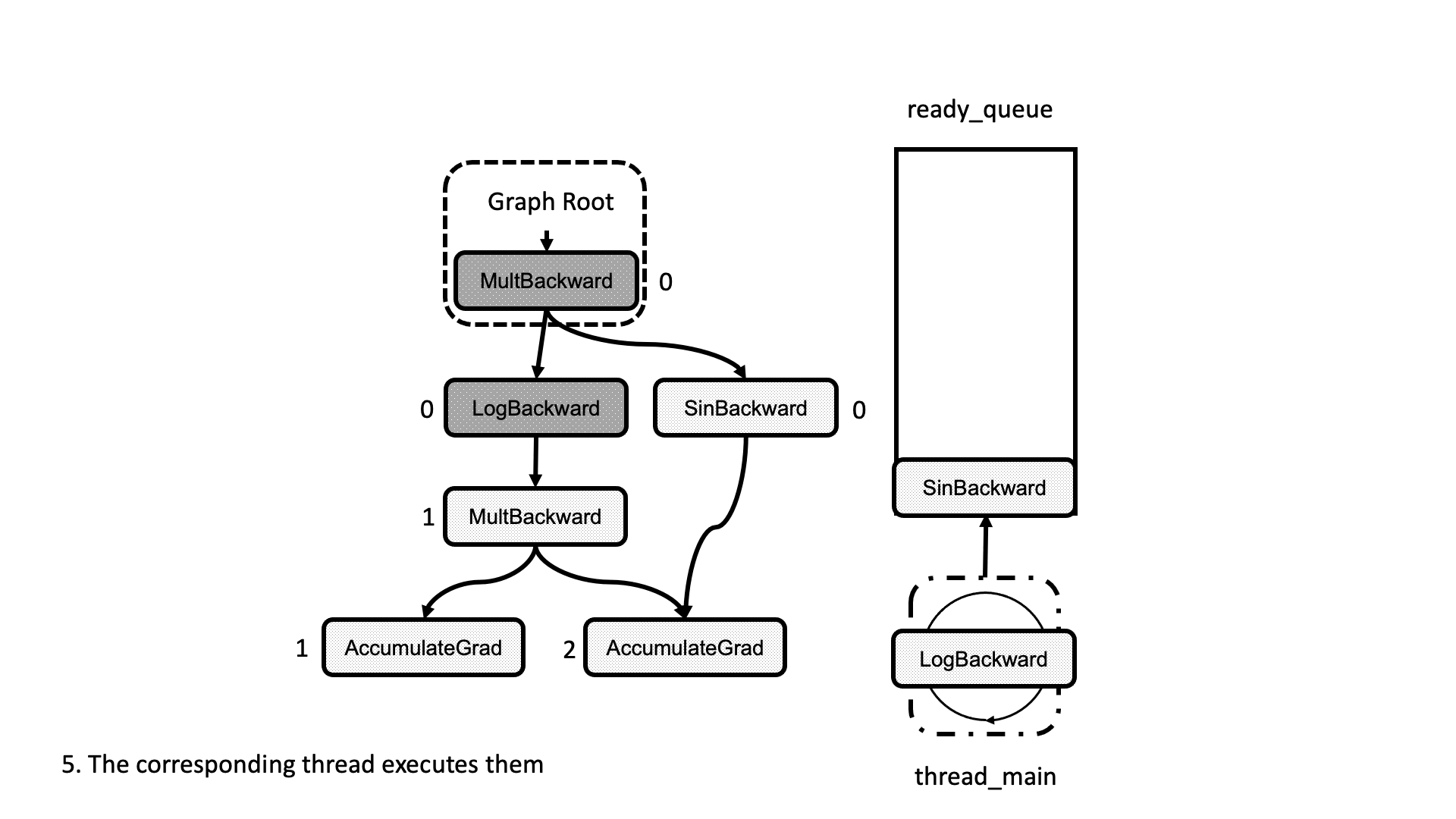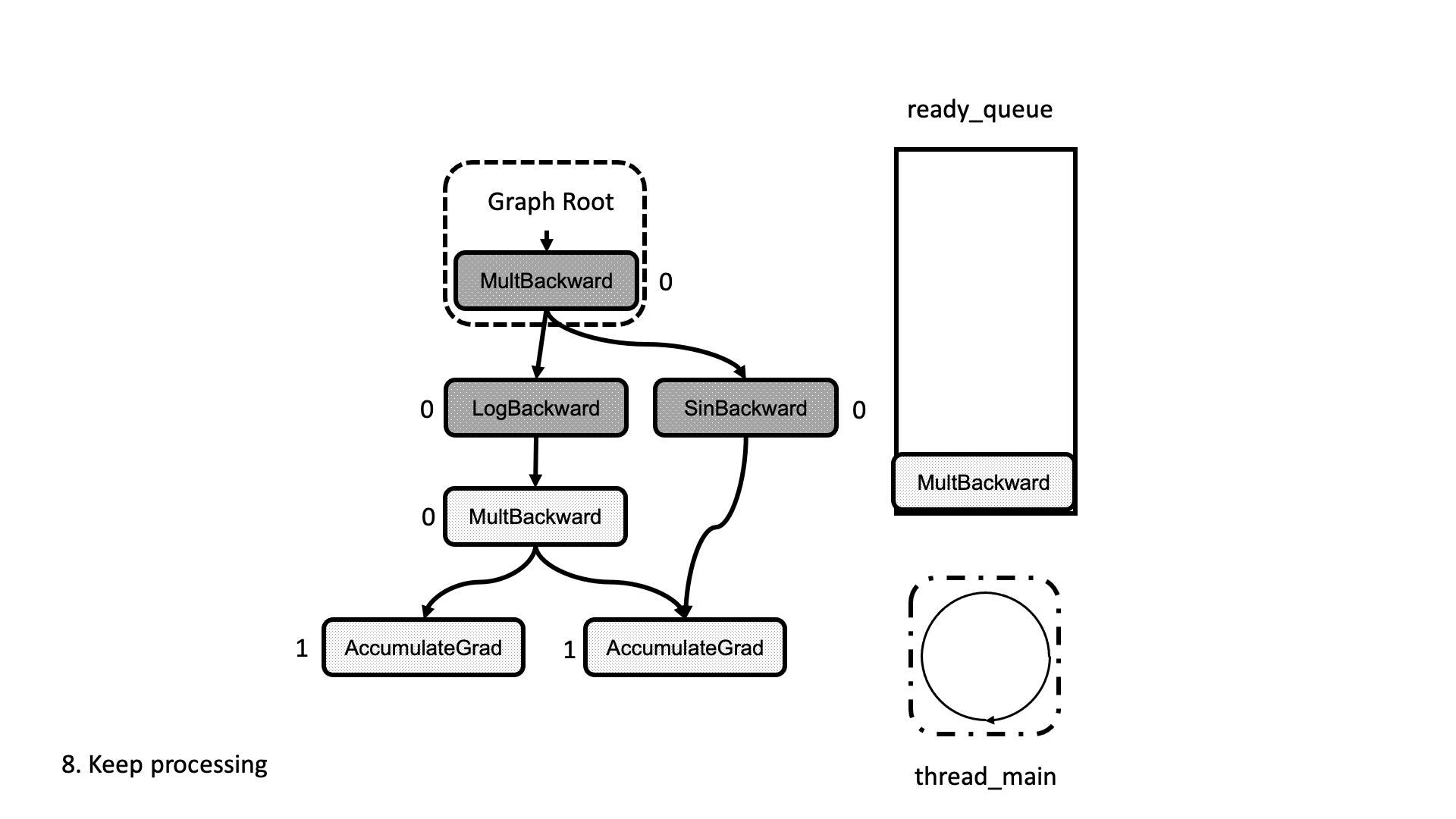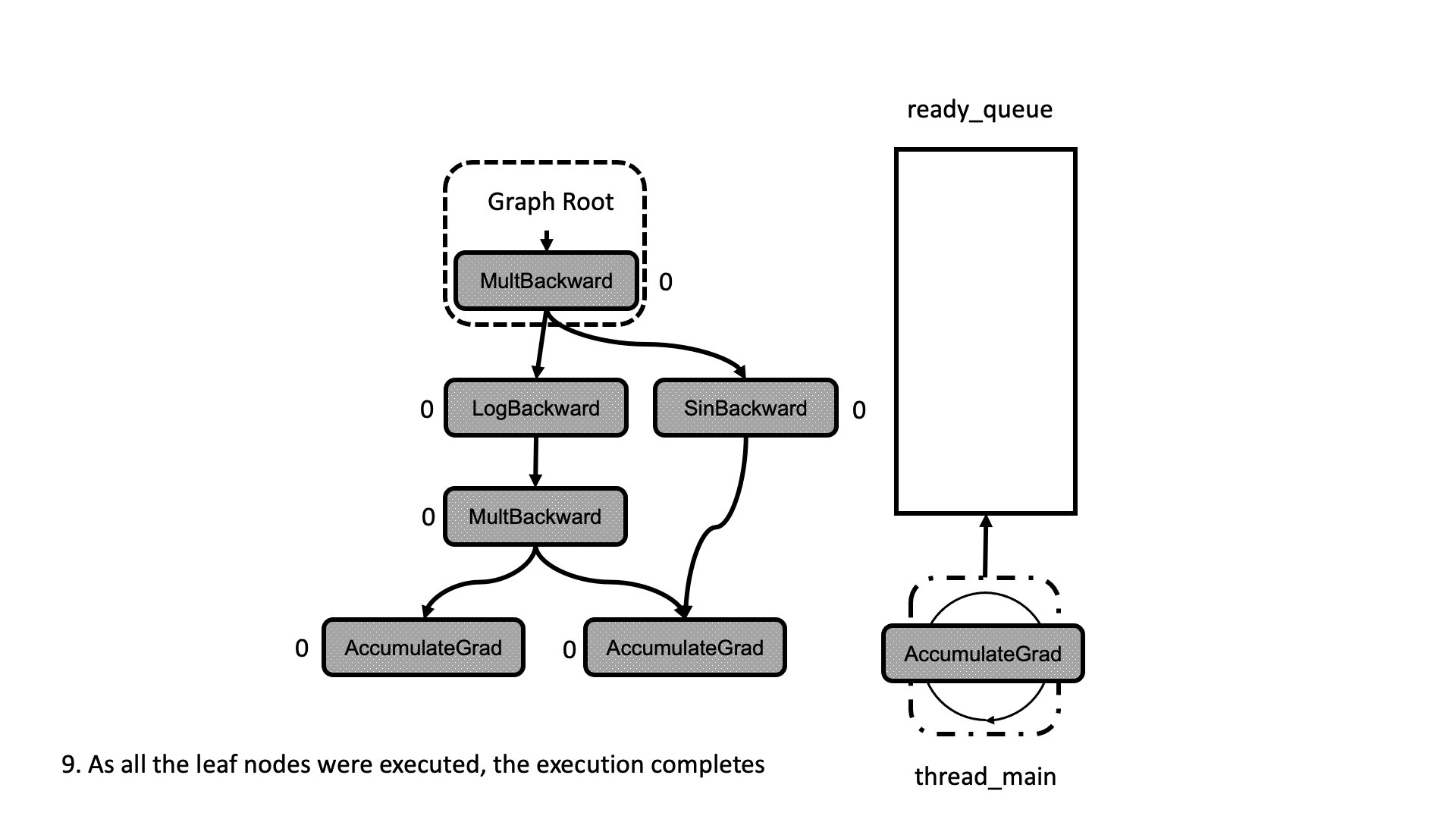
图 5:计算图执行的动画
递归回退流程
正如我们上面所看到的,递归回退问题是指当前正在执行的功能对 backward 进行嵌套调用。当这种情况发生时,运行此函数的线程会一直下降到 execute_with_graph_task ,就像非递归回退的情况一样,但这里有所不同。
c10::intrusive_ptr<at::ivalue::Future> Engine::execute_with_graph_task(
const std::shared_ptr<GraphTask>& graph_task,
std::shared_ptr<Node> graph_root,
InputBuffer&& input_buffer) {
initialize_device_threads_pool();
// Lock mutex for GraphTask.
std::unique_lock<std::mutex> lock(graph_task->mutex_);
auto queue = ready_queue(graph_task->cpu_ready_queue_, input_buffer.device());
if (worker_device == NO_DEVICE) {
//Regular case
} else {
// If worker_device is any devices (i.e. CPU, CUDA): this is a re-entrant
// backward call from that device.
graph_task->owner_ = worker_device;
// Now that all the non-thread safe fields of the graph_task have been populated,
// we can enqueue it.
queue->push(NodeTask(graph_task, std::move(graph_root), std::move(input_buffer)));
if (current_depth >= max_recursion_depth_) {
// If reached the max depth, switch to a different thread
add_thread_pool_task(graph_task);
} else {
++total_depth;
++current_depth;
lock.unlock();
thread_main(graph_task);
--current_depth;
--total_depth;
}
}
return graph_task->future_result_;
}
在这里, execute_with_graph_task 检测到这是一个递归调用,然后查找当前的嵌套调用次数。如果超过限制,我们创建一个新的线程来处理此图的执行,如果没有超过,我们则按常规执行这个递归调用。嵌套调用的限制最初是为了避免递归调用创建非常大的调用栈而导致的栈溢出。然而,当添加了 sanitizer 测试后,这个数字进一步减少了,因为线程在某一时刻可以持有的最大锁的数量。这可以在 torch/csrc/autograd/engine.h 中看到。
当超过这个最大深度时,会创建一个新的线程,并使用 add_thread_pool_task 函数。
void Engine::add_thread_pool_task(const std::weak_ptr<GraphTask>& graph_task) {
std::unique_lock<std::mutex> lck(thread_pool_shared_->mutex_);
// if we have pending graph_task objects to be processed, create a worker.
bool create_thread = (thread_pool_shared_->num_workers_ <= thread_pool_shared_->graphtasks_queue_.size());
thread_pool_shared_->graphtasks_queue_.push(graph_task);
lck.unlock();
if (create_thread) {
std::thread t(&Engine::reentrant_thread_init, this);
t.detach();
}
thread_pool_shared_->work_.notify_one();
}
在深入探讨之前,我们先看看 Engine 中的 thread_pool_shared_ 对象,它管理着与可重入向后调用相关的所有线程信息。
struct ThreadPoolShared {
unsigned int num_workers_;
std::condition_variable work_;
std::mutex mutex_;
std::queue<std::weak_ptr<GraphTask>> graphtasks_queue_;
// NOLINTNEXTLINE(cppcoreguidelines-pro-type-member-init)
ThreadPoolShared() : num_workers_(0) {}
};
ThreadPoolShared 是一个简单的容器,它包含一个队列,队列中存放着 GraphTask 对象,并具有同步机制以及当前工作进程的数量。
现在很容易理解当队列中有 graph_task 个对象且工作进程不足时, add_thread_pool_task 是如何创建线程的。
add_thread_pool_task 通过执行 reentrant_thread_init 初始化一个线程。
void Engine::reentrant_thread_init() {
at::init_num_threads();
auto tp_shared = thread_pool_shared_;
while(true) {
std::unique_lock<std::mutex> lk(tp_shared->mutex_);
++thread_pool_shared_->num_workers_;
tp_shared->work_.wait(lk, [&tp_shared]{ return !tp_shared->graphtasks_queue_.empty();});
--thread_pool_shared_->num_workers_;
auto task = tp_shared->graphtasks_queue_.front();
tp_shared->graphtasks_queue_.pop();
lk.unlock();
std::shared_ptr<GraphTask> graph_task;
if (!(graph_task = task.lock())) {
continue;
}
set_device(graph_task->owner_);
// set the local_ready_queue to the ready queue on the graph_task->owner_ device
local_ready_queue = ready_queue_by_index(graph_task->cpu_ready_queue_, graph_task->owner_);
total_depth = graph_task->reentrant_depth_;
thread_main(graph_task);
}
}
代码结构简单。新创建的线程等待在 thread_pool_shared->graphtasks_queue_ 上,以便可重入的向后图可用,然后执行它们。请注意,此线程通过访问在 execute_with_graph_task 函数中设置的 graph_task->owner_ 字段,使用启动此调用的线程所关联的设备任务就绪队列。
错误处理
当一个工作线程发生错误时,它将被传播到 backward 调用线程。
为了实现这一点,在 thread_main 中有一个 try/catch 块,它可以捕获 Node 函数调用中的任何异常,并将其设置为相关的 GraphTask 对象。
try {
…
GraphTaskGuard guard(local_graph_task);
NodeGuard ndguard(task.fn_);
{
evaluate_function(
…
}
} catch (std::exception& e) {
thread_on_exception(local_graph_task, task.fn_, e);
}
}
}
thread_on_exception 和它调用的函数最终会在 local_graph_task 对象中设置异常。
void Engine::thread_on_exception(
std::shared_ptr<GraphTask> graph_task,
const std::shared_ptr<Node>& fn,
std::exception& e) {
graph_task->set_exception(std::current_exception(), fn);
}
void GraphTask::set_exception_without_signal(const std::shared_ptr<Node>& fn) {
if (!has_error_.exchange(true)) {
if (AnomalyMode::is_enabled() && fn) {
fn->metadata()->print_stack(fn->name());
}
}
}
void GraphTask::set_exception(
std::exception_ptr eptr,
const std::shared_ptr<Node>& fn) {
set_exception_without_signal(fn);
if (!future_completed_.exchange(true)) {
// NOLINTNEXTLINE(performance-move-const-arg)
future_result_->setError(std::move(eptr));
}
}
在 set_exception 中,它将 has_error_ 标志设置为 true ,并调用 future_result_ 对象的 setError 函数。这将导致错误在访问 future_result_->value() 时在调用线程中被重新抛出。
IValue value() {
std::unique_lock<std::mutex> lock(mutex_);
AT_ASSERT(completed());
if (eptr_) {
std::rethrow_exception(eptr_);
}
return value_;
}
结束语
这是我们本系列关于 PyTorch 如何进行自动微分系列的最后一篇帖子。我们希望您喜欢阅读它,并且现在您已经足够熟悉 PyTorch 内部机制,可以开始为 PyTorch 开发做出贡献!