在人工智能创新以前所未有的速度加速发展的背景下,Meta 的 Llama 系列开源大型语言模型(LLMs)脱颖而出,成为一项显著的突破。Llama 标志着LLMs的重大进步,展示了预训练架构在广泛应用中的强大能力。Llama 2 进一步推动了规模和能力的边界,激发了语言理解、生成等方面的进步。
在 Llama 发布后不久,我们发布了一篇博客文章,展示了在 Cloud TPU v4 上使用 PyTorch/XLA 为 Llama 实现的超低推理延迟。在此基础上,今天,我们自豪地分享使用 PyTorch/XLA 在 Cloud TPU v4 和我们的最新 AI 超级计算机 Cloud TPU v5e 上进行的 Llama 2 训练和推理性能。
在这篇博客文章中,我们以 Llama 2 为例,展示了 PyTorch/XLA 在 Cloud TPUs 上进行LLM训练和推理的强大功能。我们讨论了用于提高推理吞吐量和训练模型 FLOPs 利用率(MFU)的计算技术和优化方法。对于 70B 参数的 Llama 2,我们实现了 53%的训练 MFU,17 毫秒/令牌的推理延迟,42 个令牌/芯片的吞吐量,这一切都得益于 PyTorch/XLA 在 Google Cloud TPU 上的应用。我们提供了训练用户指南和推理用户指南,以帮助您重现本文中的结果。此外,您还可以在此处找到我们的 Google Next 2023 演示文稿。
模型概述
Llama 2 有多种大小,参数量从 7B 到 70B 不等,满足不同的需求、计算资源和训练/推理预算。无论是小型项目还是大规模部署,Llama 模型都提供灵活性和可扩展性,以适应广泛的用途。
Llama 2 是一种自回归语言模型,采用优化的 Transformer 架构。最大的 70B 模型使用分组查询注意力,在不牺牲质量的情况下加快推理速度。Llama 2 在 200 万亿个标记(比 Llama 多 40%)上训练,推理的上下文长度为 4096 个标记(是 Llama 的两倍),这使模型具有更高的准确性、流畅性和创造力。
Llama 2 是最先进的LLM,在许多基准测试中,包括推理、编码、熟练度和知识测试中,优于许多其他开源语言模型。该模型的规模和复杂性对 AI 加速器提出了许多要求,使其成为 PyTorch/XLA 在 Cloud TPUs 上训练和推理性能的理想基准。
LLMs 性能挑战
大规模分布式训练对于 Llama 2 等模型来说,引入了需要实际解决方案的技术挑战,以最大限度地利用 TPU。Llama 的规模可能会对 TPU 的内存和计算资源造成压力。为了解决这个问题,我们采用了模型分片技术,即将模型分解成更小的部分,每个部分都适合单个 TPU 核心的容量。这可以在多个 TPU 之间实现并行处理,提高训练速度同时减少通信开销。
另一个挑战是管理训练 Llama 2 所需的大量数据集,这需要有效的数据分布和同步方法。此外,优化学习率调度、梯度聚合以及跨分布式 TPU 的权重同步对于实现收敛至关重要。
在预训练或微调 Llama 2 之后,在模型检查点上进行推理会带来额外的技术挑战。我们之前博客文章中讨论的所有挑战,例如自回归解码、可变输入提示长度以及模型分片和量化需求,在 Llama 2 中仍然适用。此外,Llama 2 还引入了两个新功能:分组查询注意力和早期停止。我们讨论了 PyTorch/XLA 如何处理这些挑战,以实现 Llama 2 在 Cloud TPU v4 和 v5e 上的高性能、低成本训练和推理。
大规模分布式训练
PyTorch/XLA 提供了两种进行大规模分布式训练的主要方式:SPMD,它利用 XLA 编译器将单设备程序转换和分区为多设备分布式程序;以及 FSDP,它实现了广泛采用的完全分片数据并行算法。
在本文中,我们展示了如何使用 SPMD API 来注释 HuggingFace(HF)Llama 2 实现以最大化性能。为了比较,我们还展示了相同配置下的 FSDP 结果;有关 PyTorch/XLA FSDP API 的更多信息请参阅此处。
SPMD 概述
让我们简要回顾 SPMD 的基本原理。详情请参阅我们的博客文章和用户指南。
网格
描述 TPU 设备逻辑拓扑的多维数组:
# Assuming you are running on a TPU host that has 8 devices attached
num_devices = xr.global_runtime_device_count()
# mesh shape will be (4,2) in this example
mesh_shape = (num_devices // 2, 2)
device_ids = np.array(range(num_devices))
# axis_names 'x' and 'y' are optional
mesh = Mesh(device_ids, mesh_shape, ('x', 'y'))
分区规范
描述相应张量维度如何在网格上划分的元组:
partition_spec = ('x', 'y')
标记划分
一个 API,它接受一个网格和分区规范,然后为 XLA 编译器生成划分注解。
tensor = torch.randn(4, 4).to('xla')
# Let's resue the above mesh and partition_spec.
# It means the tensor's 0th dim is sharded 4 way and 1th dim is sharded 2 way.
xs.mark_sharding(tensor, mesh, partition_spec)
2D Sharding with SPMD
在我们的 SPMD 博客文章中,我们展示了使用 1D FSDP 风格的分片。在这里,我们介绍了一种更强大的分片策略,称为 2D 分片,其中参数和激活都进行了分片。这种新的分片策略不仅允许拟合更大的模型,还提高了 MFU 至高达 54.3%。更多详情请参阅基准测试部分。
本节介绍了一组适用于大多数LLMs的一般规则,为了方便起见,我们直接引用了 HF Llama 中的变量名和配置名。
首先,让我们创建一个具有相应轴名称的 2D 网格:数据和模型。数据轴通常是分配输入数据的地方,模型轴是进一步分配模型的地方。
mesh = Mesh(device_ids, mesh_shape, ('data', 'model'))
mesh_shape 可以是一个超参数,可以根据不同的模型大小和硬件配置进行调整。相同的网格将在所有后续的碎片化注解中重复使用。在接下来的几节中,我们将介绍如何使用网格来碎片化参数、激活和输入数据。
参数碎片化
下表总结了 HF Llama 2 的所有参数及其相应的分区规范。示例 HF 代码可以在此处找到。
| 参数名称 | 说明 | 参数形状 | 分区规范 |
embed_tokens
|
嵌入层 | ( vocab_size , hidden_size ) |
(模型,数据) |
q_proj
|
注意力权重 | ( num_heads x head_dim , hidden_size ) |
(数据,模型) |
k_proj / v_proj
|
注意力权重 | ( num_key_value_heads x head_dim , hidden_size ) |
(数据,模型) |
o_proj
|
注意权重 | (hidden_size, num_heads x head_dim)
|
(模型,数据) |
gate_proj / up_proj
|
MLP 权重 | ( intermediate_size , hidden_size ) |
(模型,数据) |
down_proj
|
MLP 权重 | ( hidden_size , intermediate_size ) |
(数据,模型) |
lm_head
|
HF 输出嵌入 | ( vocab_size , hidden_size ) |
(模型,数据) |
表格 1:SPMD 2D 分片参数分区规范
规则是根据网格的 data 轴对除 QKVO 投影外的任何权重进行分片,然后使用剩余的 model 轴对其他维度进行分片。对于 QKVO,则执行相反操作。这种模型数据轴旋转方法与 Megatron-LM 类似,旨在减少通信开销。对于 layernorm 权重,由于它们是 1D 张量,我们隐式地将它们标记为跨不同设备复制。在 Llama 2 中,我们显式注释了所有 hidden_size 和 data 输出。表格 2 总结了相应的注释;示例 HF 代码可在此处找到。
激活分片
为了更好地利用设备内存,我们通常需要注释一些内存密集型操作的输出。这样编译器就只能在设备上保留部分输出,而不是全部输出。在 Llama 2 中,我们显式注释了所有 torch.matmul 和 nn.Linear 输出。表格 2 总结了相应的注释;示例 HF 代码可在此处找到。
| 输出名称 | 说明 | 输出形状 | 分区规范 |
inputs_embeds
|
嵌入层输出 | (batch_size, sequence_length, hidden_size)
|
(数据, None, 模型) |
query_states
|
注意力 nn.Linear 输出 | (batch_size, sequence_length, num_heads x head_dim)
|
(数据, None, 模型) |
key_states / value_states
|
注意力 nn.Linear 输出 | (batch_size, sequence_length, num_key_value_heads x head_dim)
|
(数据,None,模型) |
attn_weights
|
注意力权重 | ( batch_size , num_attention_heads , sequence_length , sequence_length ) |
(数据,模型,None,None) |
attn_output
|
注意力层输出 | (batch_size, sequence_length, hidden_size)
|
(数据, None, 模型) |
up_proj / gate_proj / down_proj
|
MLP nn.Linear 输出 |
(batch_size, sequence_length, intermediate_size)
|
(数据, 无, 模型) |
logits
|
HF 输出嵌入输出 | (batch_size, sequence_length, hidden_size)
|
(数据,None,模型) |
表 2:SPMD 2D 分片激活分区规范
规则是根据网格的 data 轴对任何输出的 batch_size 维度进行分片,然后复制任何输出的长度维度,最后沿着 model 轴对最后一个维度进行分片。
输入分片
对于输入分片,规则是沿着网格的 data 轴分片批量维度,并复制 sequence_length 维度。以下是示例代码,相应的 HF 更改可以在这里找到。
partition_spec = ('data', None)
sharding_spec = xs.ShardingSpec(mesh, partition_spec)
# MpDeviceLoader will shard the input data before sending to the device.
pl.MpDeviceLoader(dataloader, self.args.device, input_sharding=sharding_spec, ...)
现在,所有需要分片的数据和模型张量都已覆盖!
优化器状态与梯度
您可能想知道是否需要将优化器状态和梯度也进行分片。好消息是,XLA 编译器的分片传播功能自动化了这两种场景中的分片注释,无需更多提示即可提高性能。
注意,优化器状态通常在训练循环的第一轮迭代中初始化。从 XLA 编译器的角度来看,优化器状态是第一个图的输出,因此会传播分片注解。对于后续迭代,优化器状态成为第二个图的输入,分片注解从第一个图传播过来。这也是为什么 PyTorch/XLA 通常为训练循环生成两个图的原因。如果优化器状态在第一轮迭代之前以某种方式初始化,用户将需要手动注解它们,就像模型权重一样。
再次,上述分片注解的所有具体示例都可以在我们的 HF Transformers 分支中找到。该仓库还包含我们实验性功能 MultiSlice 的代码,包括 HybridMesh 和 dcn 轴,遵循上述提到的相同原则。
注意事项
在使用 SPMD 进行训练时,有几个重要事项需要注意:
- 使用
torch.einsum代替torch.matmul;torch.matmul通常会在末尾进行张量展平并执行torch.mm操作,这对 SPMD 来说很不好,当合并的轴被分片时,XLA 编译器将很难确定如何传播分片。 - PyTorch/XLA 提供了修复后的
[nn.Linear](https://github.com/pytorch/xla/blob/master/torch_xla/experimental/xla_sharding.py#L570)来克服上述限制:
import torch_xla.experimental.xla_sharding as xs
from torch_xla.distributed.fsdp.utils import apply_xla_patch_to_nn_linear
model = apply_xla_patch_to_nn_linear(model, xs.xla_patched_nn_linear_forward)
- 在所有分片中始终重用相同的网格。
- 总是指定
--dataloader_drop_last yes。最后较小的数据难以标注。 - 主机端初始化的大模型可能会引起主机端内存溢出。避免此问题的方法之一是在元设备上初始化参数,然后逐层创建和分片真实张量。
基础设施改进
除了上述建模技术之外,我们还开发了额外的功能和改进,以最大化性能,包括:
- 我们启用了异步集体通信。这需要对 XLA 编译器的延迟隐藏调度器进行增强,以更好地优化 Llama 2 PyTorch 代码。
- 我们现在允许在 IR 图中间进行分片注释,就像 JAX 的 jax.lax.with_sharding_constraint 一样。之前,只有图输入被注释。
- 我们还从编译器将复制的分片规范传播到图输出。这允许我们自动分片优化器状态。
推理优化
所有为 Llama 推理实现的 PyTorch/XLA 优化都应用于 Llama 2。这包括使用 torch-xla 集体操作的 Tensor Parallelism + Dynamo(torch.compile),自动回归解码逻辑改进以避免重新编译,分桶提示长度,KV 缓存与编译友好的索引操作。Llama 2 引入了两个新变化:分组查询注意力和当 eos 达到所有提示时的早期停止。我们对 PyTorch/XLA 应用了相应的更改,以促进更好的性能和灵活性。
分组查询注意力
Llama 2 允许 70B 模型使用分组查询注意力。它允许键和值头数小于查询头数,同时仍支持 KV 缓存分片至 KV 头数。对于 70B 模型, n_kv_heads 为 8,这限制了张量并行度小于或等于 8。为了将模型检查点分片以在更多设备上运行,需要首先复制 K、V 投影权重,然后将其分割成多个部分。例如,要将 70B 模型检查点从 8 片分割到 16 片,K、V 投影权重被复制并分割成每个分片 2 片。我们提供了一个 reshard_checkpoints.py 脚本来处理这个问题,并确保分割后的检查点在数学上与原始检查点相同。
EOS 提前停止
Llama 2 生成代码添加了提前停止逻辑。使用一个 eos_reached 张量来跟踪所有提示生成的完成情况,如果批次中所有提示都达到了 eos 标记,则生成将提前停止。类似的更改也被纳入 PyTorch/XLA 优化版本中,并进行了一些小的调整。
在 PyTorch/XLA 中,将张量 eos_reached 的值作为控制流条件的一部分进行检查将触发阻塞的设备到主机传输。该张量将从设备内存传输到 CPU 内存以评估其值,而所有其他逻辑都在等待。这导致每次新标记生成后引入了 ms 级的延迟。作为权衡,我们将检查 eos_reached 值的频率降低到每 10 个新标记生成一次。通过这种改变,阻塞的设备到主机传输的影响将降低 10 倍,而早期停止仍然有效,并且每次序列达到 eos 标记后,最多只会生成 9 个不必要的标记。
模型服务
PyTorch/XLA 正在开发一种服务策略,以使 PyTorch 社区能够通过 Torch.Export、StableHLO 和 SavedModel 来提供他们的深度学习应用程序。PyTorch/XLA 服务是 PyTorch/XLA 2.1 版本中的实验性功能;有关详细信息,请访问我们的服务用户指南。用户可以利用 TorchServe 来运行他们的单主机工作负载。
基准测试
指标
为了衡量训练性能,我们使用行业标准指标:模型 FLOPS 利用率(MFU)。模型 FLOPS 是指执行单个正向和反向传递所需的浮点运算。模型 FLOPs 与硬件和实现无关,仅取决于底层模型。MFU 衡量模型在训练过程中实际硬件的使用效率。达到 100% MFU 意味着模型正在完美地使用硬件。
为了衡量推理性能,我们使用行业标准指标——吞吐量。首先,我们测量模型编译和加载后每个标记的延迟。然后,通过将批大小(BS)除以每片的延迟来计算吞吐量。因此,吞吐量衡量模型在生产环境中的性能,无论使用多少芯片。
结果
训练评估
图 1 展示了 Llama 2 SPMD 2D 分片训练结果,在一系列 Google TPU v4 硬件上,以 PyTorch/XLA FSDP 作为基准。与在同一硬件配置上运行的 FSDP 相比,我们在所有大小的 Llama 2 上提高了 28%的 MFU。这种性能提升主要归因于:1)2D 分片比 FSDP 有更少的通信开销,2)SPMD 中启用了异步集体通信,这允许通信和计算重叠。此外,随着模型规模的扩大,我们保持了高 MFU。表 3 显示了所有硬件配置以及训练基准中使用的某些超参数。
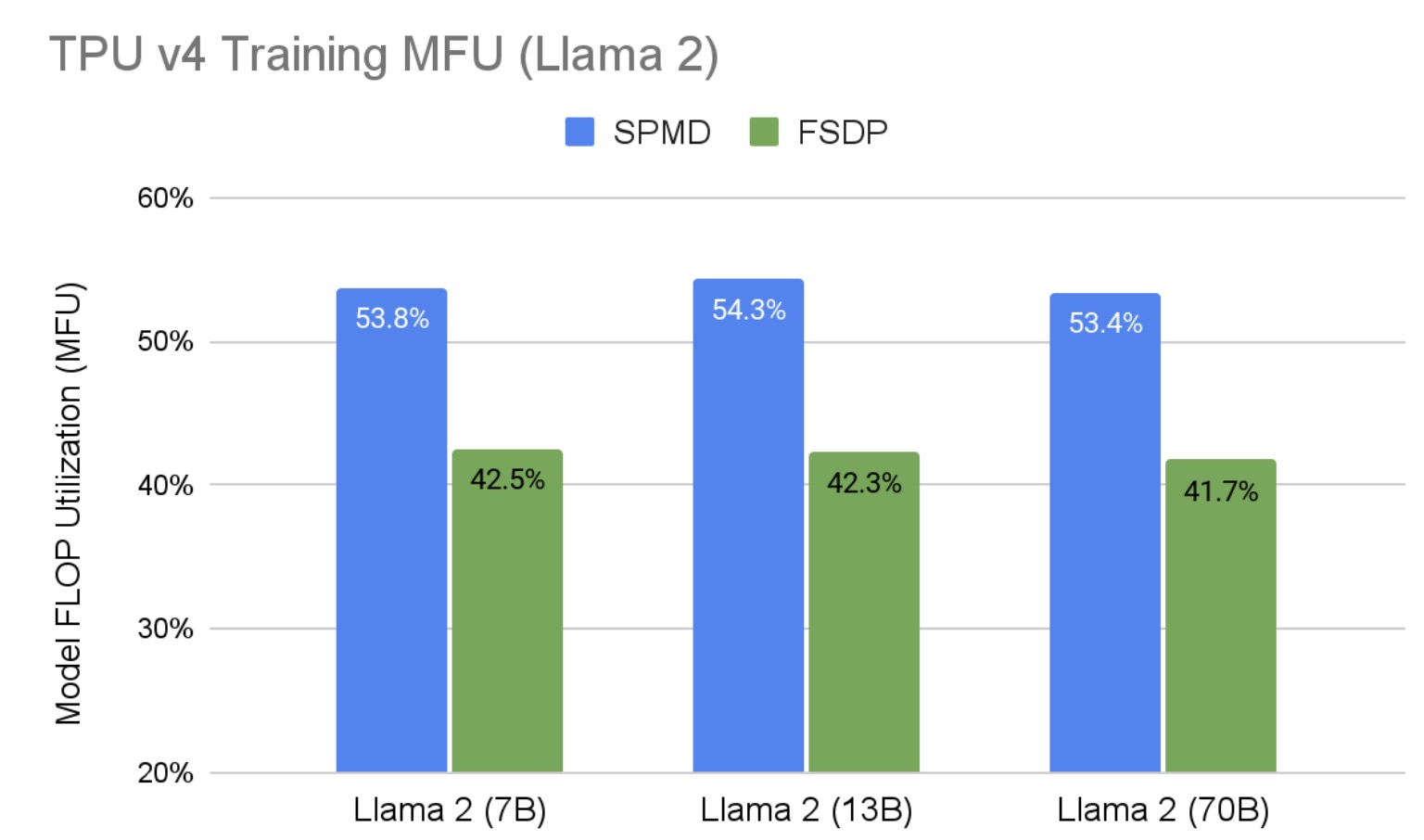
图 1:Llama 2 在 TPU v4 硬件上的训练 MFU
图 1 的结果使用 1,024 的序列长度生成。图 2 展示了随着序列长度的增加,性能如何表现。它显示我们的性能也随着序列长度的增加而线性增长。由于 2D 分片没有对序列长度轴进行分片,因此需要更小的每个设备的批量大小来适应更大的序列长度带来的额外内存压力,因此 MFU 预计会略有下降。TPU 对批量大小非常敏感。对于 Llama 2,70B 参数,性能下降仅为 4%。在准备这些结果的时候,Hugging Face Llama 2 分词器限制了最大模型输入为 2,048,这阻止了我们评估更大的序列长度。
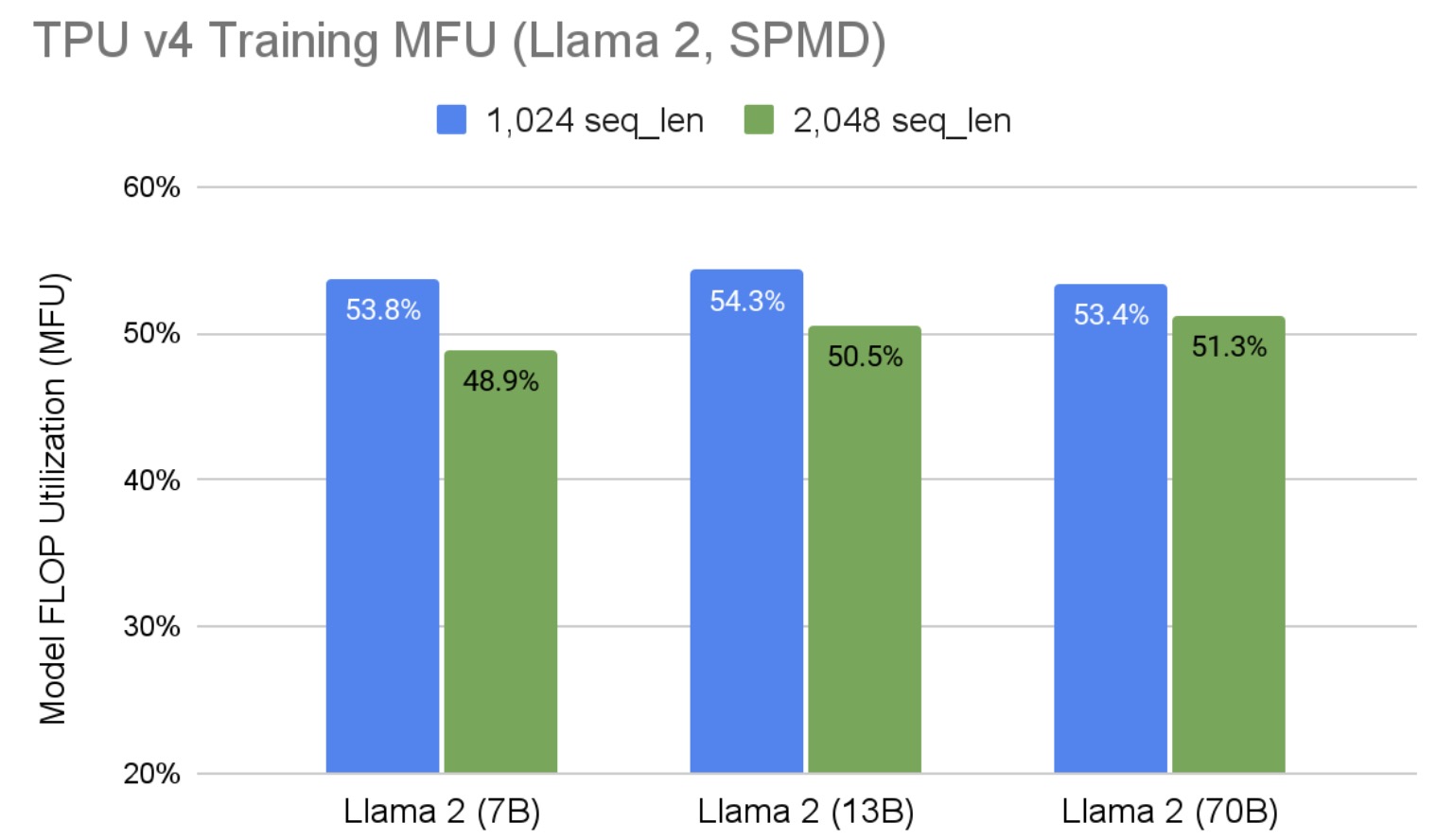
图 2:Llama 2 SPMD 在 TPU v4 上的不同序列长度下的 MFU 训练
| 模型大小 | 7B | 13B | 70B | |||
| TPU 核心数 | V4-32 | V4-64 | V4-256 | |||
| 网格形状 | (16, 1) | (32, 1) | (32, 4) | |||
| 序列长度 | 1,024 | 2,048 | 1,024 | 2,048 | 1,024 | 2,048 |
| 全局批量 | 256 | 128 | 256 | 128 | 512 | 256 |
| 每设备批量 | 16 | 8 | 8 | 4 | 16 | 8 |
表格 3:Llama 2 SPMD 训练基准 TPU 配置和超参数
最后要指出的是,我们使用 adafactor 作为优化器以实现更好的内存利用率。再次提供用户指南,以重现上述基准结果。
推理评估
在本节中,我们扩展了之前在 Cloud v4 TPU 上对 Llama 的评估。在此,我们展示了 TPU v5e 在推理应用中的性能特性。
我们将推理吞吐量定义为每秒每个 TPU 芯片产生的 token 数量。图 3 显示了 Llama 2 70B 在 v5e-16 TPU 节点上的吞吐量。由于 Llama 是一个内存密集型应用程序,我们发现仅应用权重量化就可以解锁扩展模型批大小到 32。在芯片间的 ICI 网络带宽限制 TPU 切片无法提供更高吞吐量的点上,更大的 TPU v5e 硬件将可能实现更高的吞吐量。探索 TPU v5e 在 Llama 2 上的上限超出了本工作的范围。请注意,为了使 Llama 2 70B 模型在 v5e-16 上运行,我们按照上文推理部分所述,复制了注意力头,每个芯片有一个头。如前所述,随着模型批大小的增加,每 token 的延迟成比例增长;量化通过减少内存 I/O 需求来提高整体延迟。
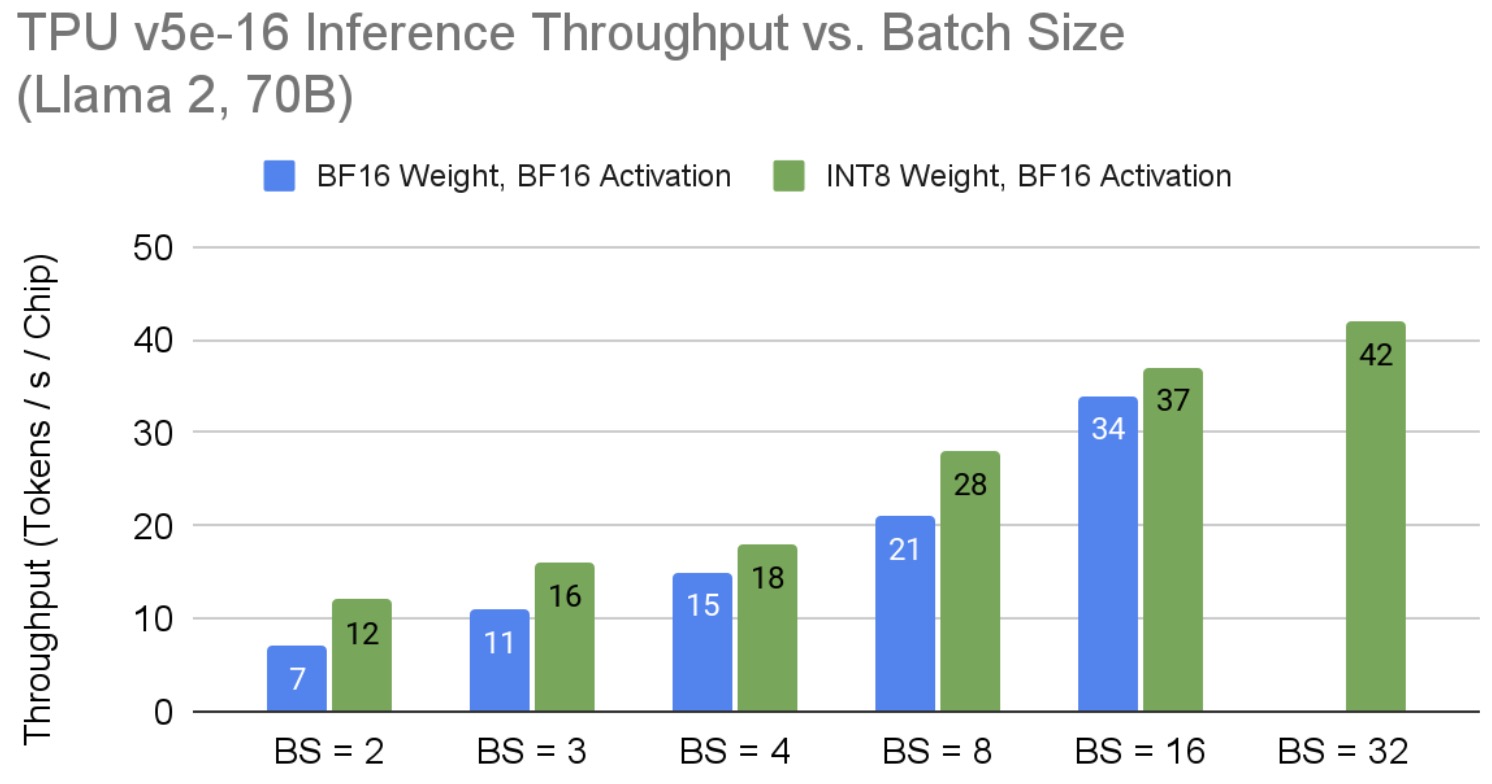
图 3:Llama 2 70B 在 TPU v5e 上的每芯片推理吞吐量与批大小
图 4 展示了不同模型大小下的推理吞吐量结果。这些结果突出了在 bf16 精度下,根据硬件配置所能达到的最大吞吐量。仅使用权重量化时,该吞吐量在 70B 模型上达到 42。如上所述,增加硬件资源可能会导致性能提升。
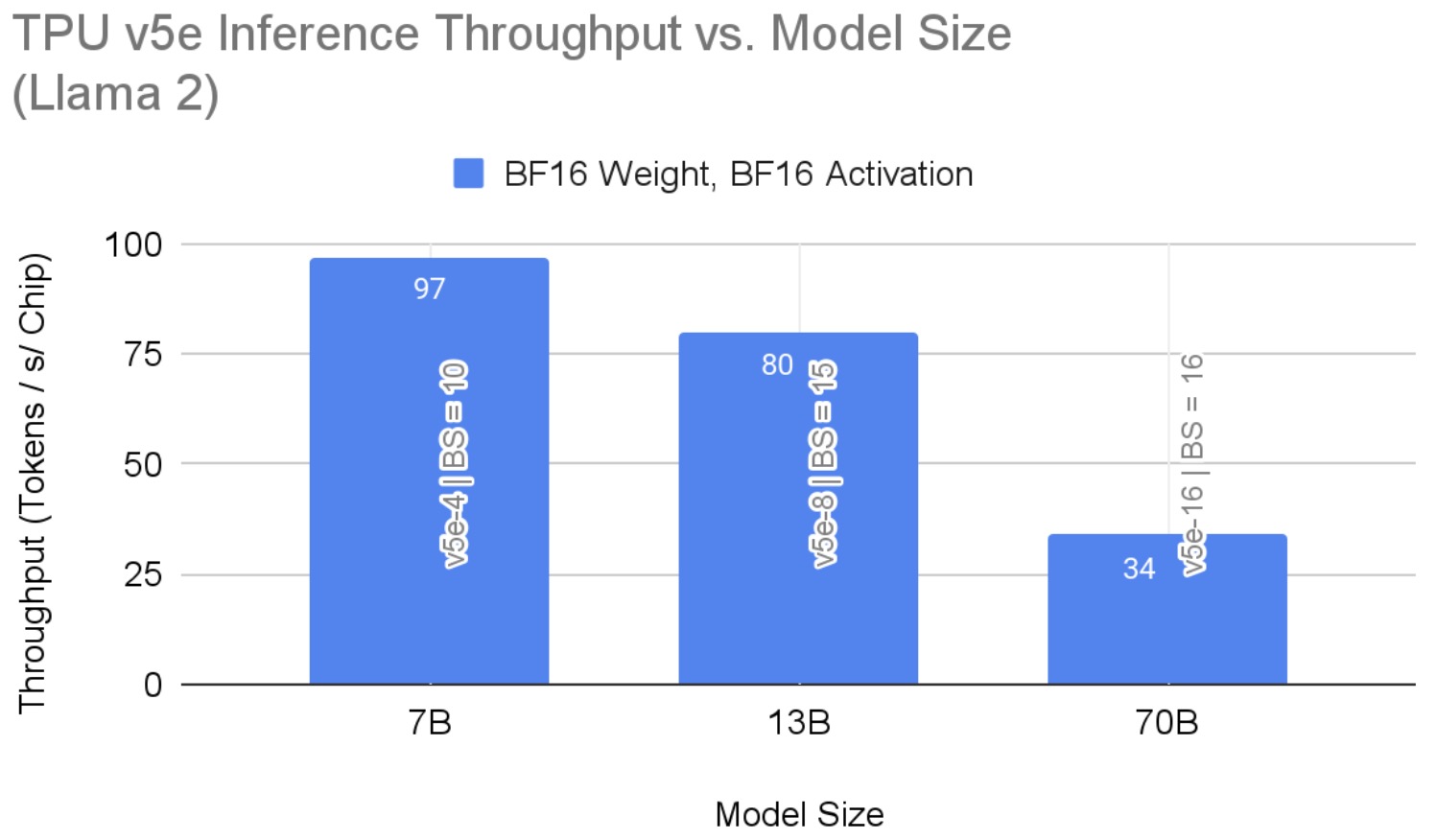
图 4:Llama 2 在 TPU v5e 上的每芯片推理吞吐量
图 5 展示了在 Cloud TPU v5e 上服务 Llama 2 模型(见图 4)的成本。我们报告了 us-west4 区域基于 3 年承诺(预留)价格的 TPU v5e 每芯片成本。所有模型大小均使用最大序列长度为 2,048,最大生成长度为 1,000 个 token。请注意,量化后,70B 模型的成本降至每 1,000 个 token 0.0036 美元。
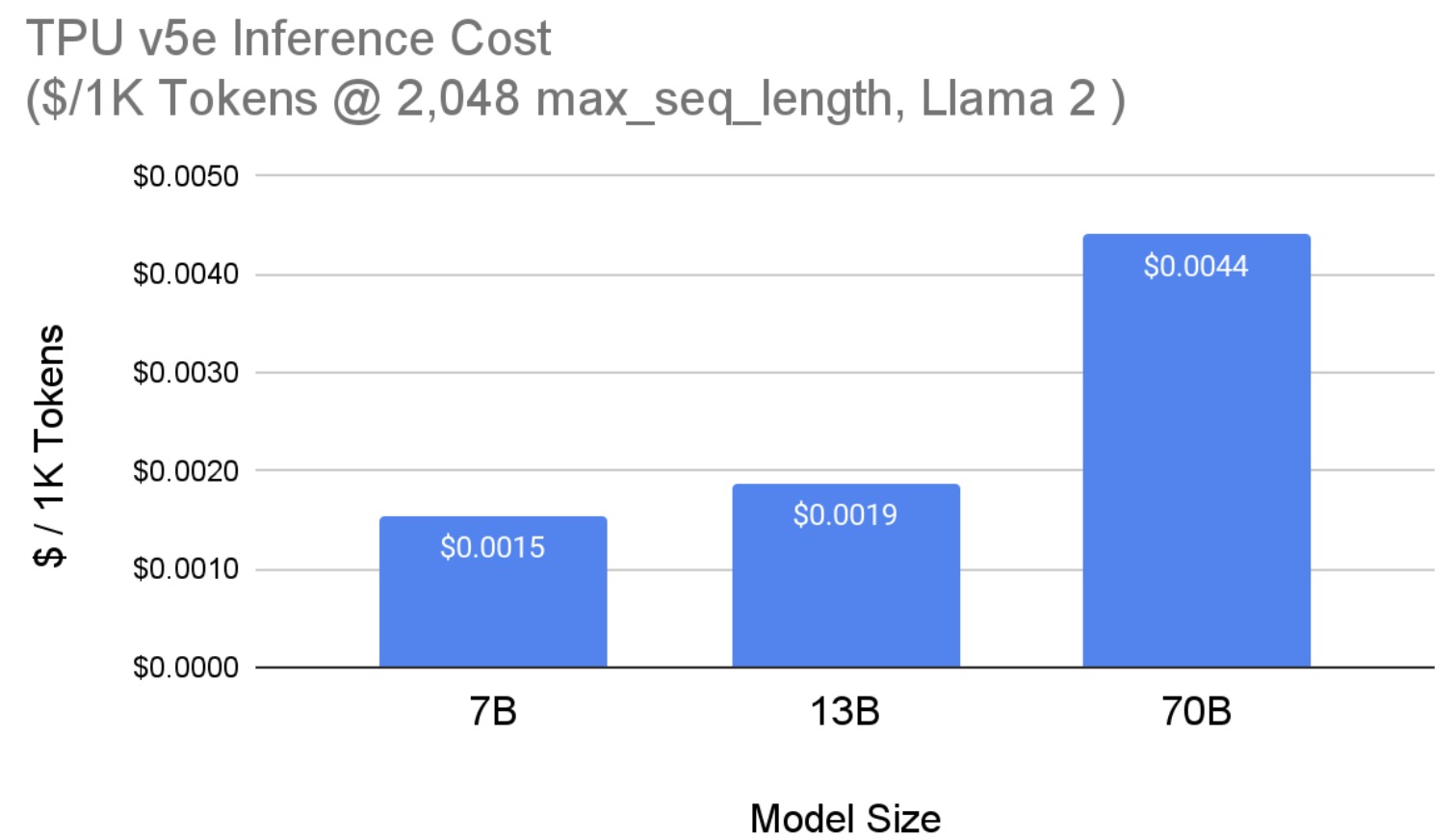
图 5:Llama 2 在 TPU v5e 上的每芯片推理成本
图 6 总结了我们在 TPU v5e 上最好的 Llama 2 推理延迟结果。7B 的 Llama 2 结果来自我们的非量化配置(BF16 权重,BF16 激活),而 13B 和 70B 的结果来自量化配置(INT8 权重,BF16 激活)。我们将这一观察归因于量化固有的内存节省与计算开销之间的权衡;因此,对于较小的模型,量化可能不会导致更低的推理延迟。
此外,提示长度对LLMs的内存需求有很强的影响。例如,我们在 v5e-4 上以批大小为 1 且未进行量化的情况下运行 Llama2 7B 时观察到 1.2ms/令牌的延迟(即每秒每芯片 201 个令牌)。
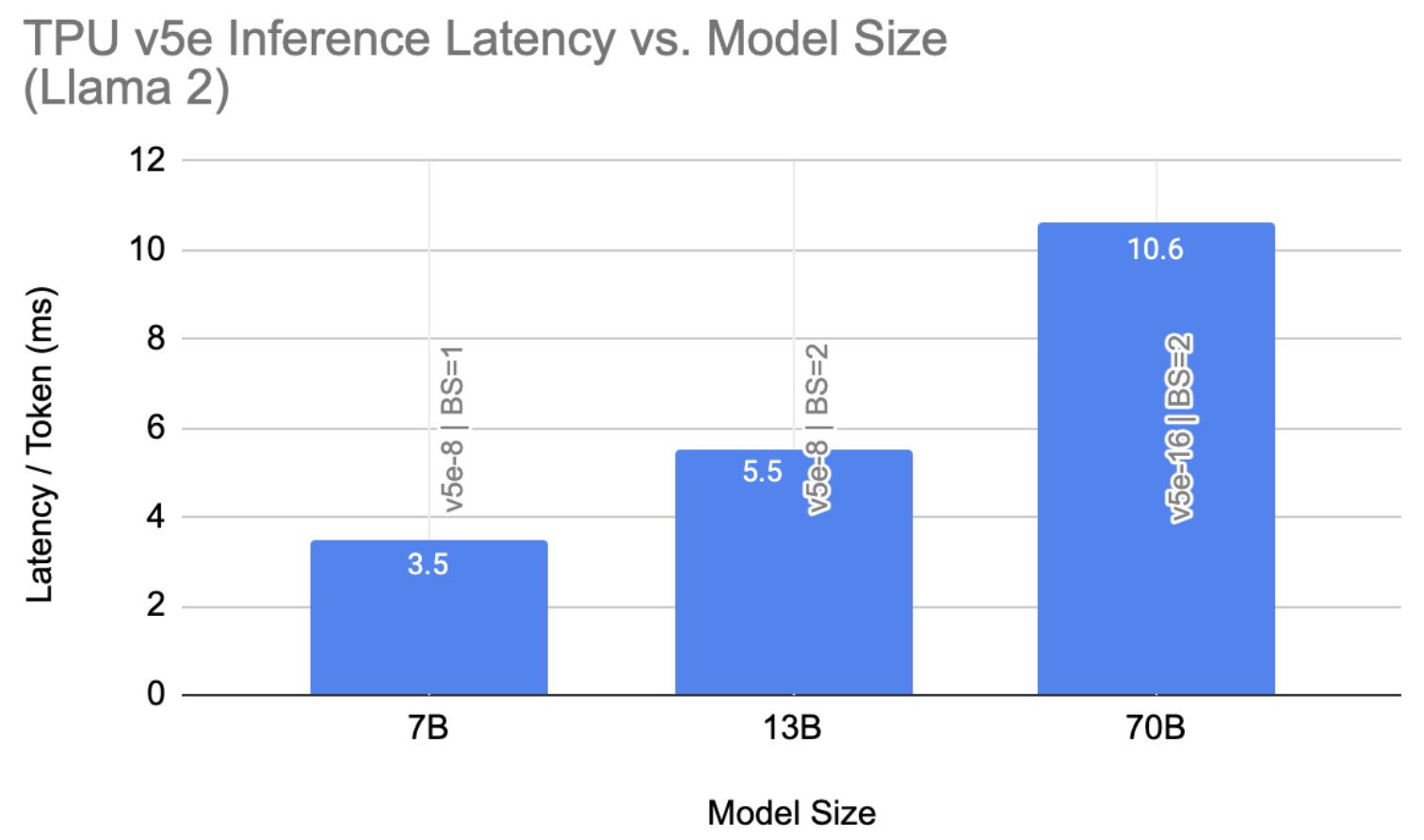
图 6:TPU v5e 上 Llama 2 推理延迟
总结
最近的人工智能创新浪潮堪称变革性的,其中LLMs的突破处于前沿。Meta 的 Llama 和 Llama 2 模型是这一波进步中的显著里程碑。PyTorch/XLA 独特地实现了 Llama 2 和其他LLMs以及生成式 AI 模型在 Cloud TPUs 上的高性能、低成本训练和推理,包括新的 Cloud TPU v5e。展望未来,PyTorch/XLA 将继续在 Cloud TPUs 的吞吐量和可扩展性上推动性能极限,同时保持相同的 PyTorch 用户体验。
我们对 PyTorch/XLA 的未来感到兴奋,并邀请社区加入我们。PyTorch/XLA 完全开源开发。因此,请将问题、提交拉取请求和发送 RFC 发送到 GitHub,以便我们可以公开协作。您还可以在包括 TPUs 和 GPU 在内的各种 XLA 设备上尝试 PyTorch/XLA。
我们想特别感谢 Marcello Maggioni、Tongfei Guo、Andy Davis、Berkin Ilbeyi 在这项工作中的支持和合作。
干杯,
谷歌 PyTorch/XLA 团队