TorchGeo 是一个提供地理空间数据集、采样器、转换和预训练模型的 PyTorch 领域库。
![]()
https://github.com/microsoft/torchgeo
几十年来,地球观测卫星、飞机以及最近的无人平台一直在收集地球表面的不断增加的图像。有了关于季节性和长期趋势的信息,遥感图像对于解决人类面临的一些最大挑战,包括气候变化适应、自然灾害监测、水资源管理和不断增长的全球人口的食物安全,具有无价的价值。从计算机视觉的角度来看,这包括土地覆盖制图(语义分割)、森林砍伐和洪水监测(变化检测)、冰川流动(像素跟踪)、飓风追踪和强度估计(回归)以及建筑和道路检测(目标检测、实例分割)等应用。通过利用深度学习架构的最新进展、更便宜且更强大的 GPU 以及数 PB 的免费卫星图像数据集,我们可以更接近解决这些重要问题。

国家海洋和大气管理局卫星图像显示的卡特里娜飓风,拍摄于 2005 年 8 月 28 日(来源)。可以使用像 TorchGeo 这样的地理空间机器学习库来检测、追踪和预测飓风和其他自然灾害的未来轨迹。
挑战
在传统的计算机视觉数据集中,如 ImageNet,图像文件本身通常相对简单且易于处理。大多数图像具有 3 个光谱波段(RGB),存储在常见的文件格式如 PNG 或 JPEG 中,并且可以轻松地使用流行的软件库如 PIL 或 OpenCV 加载。这些数据集中的每张图像通常足够小,可以直接输入到神经网络中。此外,这些数据集大多数包含有限数量的精心制作的图像,这些图像被认为是独立且同分布的,使得训练-验证-测试划分变得简单。由于这种相对的同质性,相同的预训练模型(例如在 ImageNet 上预训练的 CNN)在广泛的视觉任务中通过迁移学习方法已被证明是有效的。现有的库,如 torchvision,很好地处理了这些简单情况,并在过去十年中在视觉任务上取得了重大进展。
遥感影像并不那么均匀。卫星通常捕获的不是简单的 RGB 图像,而是多光谱(Landsat 8 有 11 个光谱波段)甚至超光谱(Hyperion 有 242 个光谱波段)的图像。这些图像在更宽的波长范围内捕获信息(400 nm–15 µm),远远超出可见光谱。不同的卫星也有非常不同的空间分辨率——GOES 的分辨率为 4 km/px,Maxar 影像为 30 cm/px,无人机影像的分辨率可高达 7 mm/px。这些数据集几乎总是具有时间成分,卫星重访周期为每日、每周或双周。图像通常与其他数据集中的图像重叠,需要根据地理元数据拼接。这些图像往往非常大(例如,10K x 10K 像素),因此不可能将整个图像通过神经网络。这些数据以数百种不同的栅格和矢量文件格式(如 GeoTIFF 和 ESRI Shapefile)分布,需要像 GDAL 这样的专业库来加载。
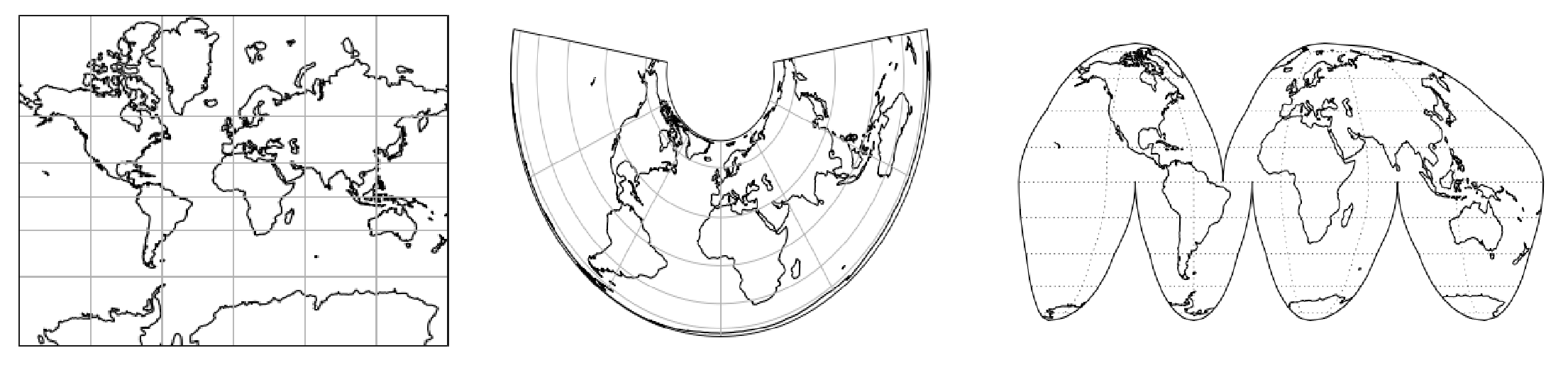
从左到右:墨卡托、阿尔贝斯等面积和中断的哥德投影(来源)。地理空间数据与许多不同类型的参考系统相关联,这些参考系统将 3D 地球投影到 2D 表示形式。从不同来源组合数据通常需要重新投影到公共参考系统,以确保所有图层对齐。
虽然每个图像都是 2D 的,但地球本身是 3D 的。为了拼接图像,它们首先需要投影到地球的 2D 表示形式,称为坐标参考系统(CRS)。大多数人熟悉像墨卡托这样的等角表示,它会扭曲区域的大小(尽管非洲比格陵兰大 15 倍,但格陵兰看起来更大),但还有许多其他常用的 CRS。每个数据集可能使用不同的 CRS,单个数据集中的每个图像也可能在独特的 CRS 中。为了使用多个图层的数据,它们必须共享一个公共 CRS,否则数据将无法正确对齐。对于那些不熟悉遥感数据的人来说,这可能是一项艰巨的任务。
即使在索引过程中正确地理配准图像,如果没有将它们投影到公共 CRS,最终会得到周围带有 nodata 值的旋转图像,并且图像不会像素对齐。
解决方案
目前,在没有这两个非常不同的领域的专业知识的情况下,同时处理深度学习模型和地理空间数据可能相当具有挑战性。为了解决这些挑战,我们构建了 TorchGeo,这是一个用于处理地理空间数据的 PyTorch 领域库。TorchGeo 旨在使操作变得简单:
- 使机器学习专家能够处理地理空间数据,
- 为遥感专家探索机器学习解决方案。
TorchGeo 不仅仅是一个研究项目,而是一个生产级别的库,它使用持续集成来测试每个提交在多种 Python 版本和多种平台(Linux、macOS、Windows)上的兼容性。它可以轻松地通过您喜欢的任何包管理器安装,包括 pip、conda 和 spack:
$ pip install torchgeo
TorchGeo 的设计目标是与 PyTorch 的其他领域库(如 torchvision、torchtext 和 torchaudio)具有相同的 API。如果您已经在工作中使用 torchvision 处理计算机视觉数据集,只需更改几行代码即可切换到 TorchGeo。所有 TorchGeo 数据集和采样器都与 PyTorch DataLoader 类兼容,这意味着您可以利用像 PyTorch Lightning 这样的包装库进行分布式训练。在接下来的章节中,我们将探讨 TorchGeo 的可能用例,以展示其使用之简便。
地理空间数据集和采样器
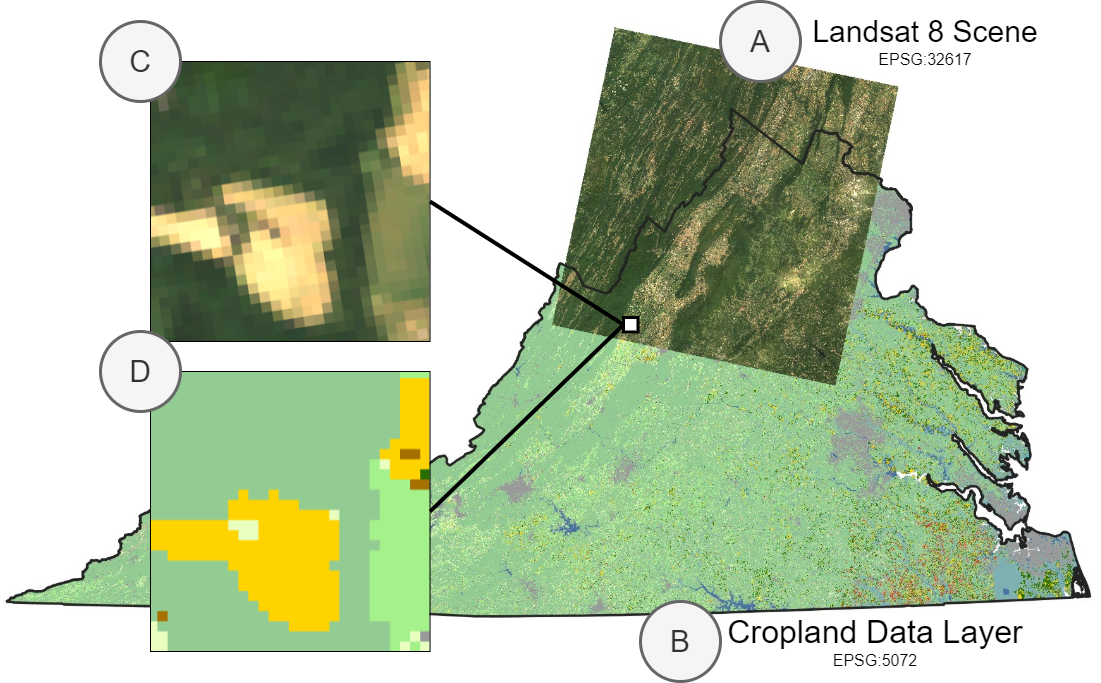
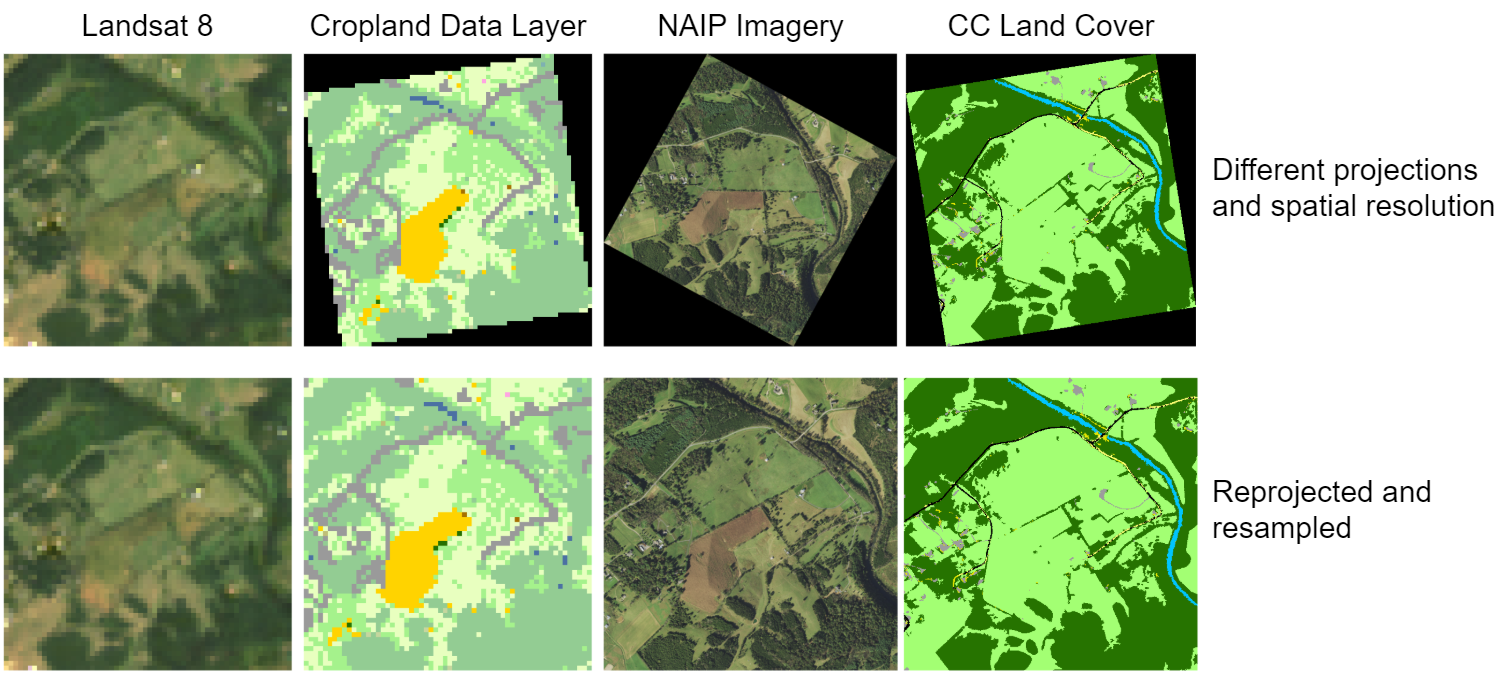
本示例是一个应用实例,我们将 A)Landsat 8 的一个场景和 B)农田数据层标签结合起来,尽管这些文件位于不同的 EPSG 投影中。我们希望使用地理空间边界框作为索引,从这些数据集中采样 C)和 D)区域。
许多遥感应用都涉及处理地理空间数据集——具有地理元数据的数据集。在 TorchGeo 中,我们定义了一个 GeoDataset 类来表示这类数据集。与按整数索引不同,每个 GeoDataset 都是按时空边界框索引的,这意味着可以智能地组合覆盖不同地理范围的两个或多个数据集。
在本例中,我们展示了如何轻松地处理地理空间数据,并使用 TorchGeo 从 Landsat 和农田数据层(CDL)数据的组合中采样小图像块。首先,我们假设用户已下载 Landsat 7 和 8 的影像。由于 Landsat 8 比 Landsat 7 具有更多的光谱波段,我们将只使用两个卫星共有的波段。我们将通过取这两个数据集的并集来创建包含 Landsat 7 和 8 所有图像的单个数据集。
from torch.utils.data import DataLoader
from torchgeo.datasets import CDL, Landsat7, Landsat8, stack_samples
from torchgeo.samplers import RandomGeoSampler
landsat7 = Landsat7(root="...")
landsat8 = Landsat8(root="...", bands=Landsat8.all_bands[1:-2])
landsat = landsat7 | landsat8
接下来,我们将此数据集与 CDL 数据集进行交集操作。我们选择交集而不是并集,以确保我们只从既有 Landsat 又有 CDL 数据的地域进行采样。请注意,我们可以自动下载并校验 CDL 数据。另外,请注意,这些数据集中可能包含不同 CRS 或分辨率的文件,但 TorchGeo 会自动确保使用匹配的 CRS 和分辨率。
cdl = CDL(root="...", download=True, checksum=True)
dataset = landsat & cdl
现在可以使用 PyTorch 数据加载器来使用此数据集。与基准数据集不同,地理空间数据集通常包含非常大的图像。例如,CDL 数据集由一张覆盖整个美国大陆的单张图像组成。为了使用地理坐标从这些数据集中采样,TorchGeo 定义了一系列采样器。在本例中,我们将使用随机采样器,它返回 256 x 256 像素的图像,每个 epoch 返回 10,000 个样本。我们还将使用自定义的合并函数将每个样本字典组合成样本的小批量。
sampler = RandomGeoSampler(dataset, size=256, length=10000)
dataloader = DataLoader(dataset, batch_size=128, sampler=sampler, collate_fn=stack_samples)
现在可以将此数据加载器用于您的常规训练/评估流程。
for batch in dataloader:
image = batch["image"]
mask = batch["mask"]
# train a model, or make predictions using a pre-trained model
许多应用程序涉及根据此类地理空间元数据智能组合数据集。例如,用户可能希望:
- 将来自多个图像来源的数据集合并,并将它们视为等效(例如,Landsat 7 和 8)
- 将来自不同地理空间位置的数据集合并(例如,切萨皮克湾的纽约和宾夕法尼亚州)
这些组合要求所有查询至少存在于一个数据集中,并且可以使用 UnionDataset 创建。同样,用户可能希望:
- 将图像和目标标签结合并从两者中同时采样(例如,Landsat 和 CDL)
- 将多个图像来源的数据集结合用于多模态学习或数据融合(例如,Landsat 和 Sentinel)
这些组合要求两个数据集中都存在所有查询,可以使用 IntersectionDataset 创建,当您使用交集( & )和并集( | )运算符时,TorchGeo 会自动为您组合这些数据集。
多光谱和地理空间变换
在深度学习中,对数据进行增强和变换以使模型对输入空间中的变化具有鲁棒性是很常见的。地理空间数据可能存在季节变化和扭曲效应等变化,以及云层覆盖和大气畸变等图像处理和捕获问题。TorchGeo 利用 Kornia 库中的增强和变换,该库支持 GPU 加速,并支持具有 3 个以上通道的多光谱图像。
传统地理空间分析计算和可视化光谱指数,这些指数是多光谱波段的组合。光谱指数旨在突出多光谱图像中与某些应用相关的感兴趣区域,例如植被健康、人造变化区域或不断增长的城镇化,或积雪覆盖。TorchGeo 支持多种变换,可以计算常见的光谱指数并将它们作为额外的波段附加到多光谱图像张量中。
下面,我们展示了一个简单的示例,其中我们在 Sentinel-2 图像上计算归一化植被指数(NDVI)。NDVI 衡量植被的存在和植被健康,它是红光和近红外(NIR)光谱波段之间的归一化差值。光谱指数变换操作在 TorchGeo 数据集返回的样本字典上执行,并将生成的光谱指数附加到图像通道维度。
首先,我们实例化一个 Sentinel-2 数据集并加载一个样本图像。然后,我们绘制该数据的真彩色(RGB)表示,以查看我们正在查看的区域。
import matplotlib.pyplot as plt
from torchgeo.datasets import Sentinel2
from torchgeo.transforms import AppendNDVI
dataset = Sentinel2(root="...")
sample = dataset[...]
fig = dataset.plot(sample)
plt.show()
接下来,我们实例化并计算一个 NDVI 变换,将这个新通道附加到图像的末尾。Sentinel-2 图像使用索引 0 表示红光波段,索引 3 表示近红外波段。为了可视化数据,我们还对图像进行了归一化。NDVI 的值范围可以从-1 到 1,但为了绘图,我们希望使用 0 到 1 的范围。
transform = AppendNDVI(index_red=0, index_nir=3)
sample = transform(sample)
sample["image"][-1] = (sample["image"][-1] + 1) / 2
plt.imshow(sample["image"][-1], cmap="RdYlGn_r")
plt.show()

2018 年 11 月 16 日由 Sentinel-2 卫星拍摄的德克萨斯丘陵地区真彩色(左侧)和 NDVI(右侧)图像。在 NDVI 图像中,红色表示水体,黄色表示裸土,浅绿色表示不健康植被,深绿色表示健康植被。
基准数据集
计算机视觉进步背后的推动因素之一是存在像 ImageNet 和 MNIST 这样的标准化基准数据集。使用这些数据集,研究人员可以直接比较不同模型和训练过程的性能,以确定哪些表现最佳。在遥感领域,有许多这样的数据集,但由于上述处理这些数据困难和缺乏加载这些数据集的现有库,许多研究人员选择使用他们自己的定制数据集。
TorchGeo 的目标之一是提供易于使用的现有数据集加载器。TorchGeo 包含多个基准数据集——这些数据集包括输入图像和目标标签。这包括图像分类、回归、语义分割、目标检测、实例分割、变化检测等任务的数据集。
如果您之前使用过 torchvision,这些类型的数据集应该很熟悉。在这个例子中,我们将创建一个用于西北工业大学(NWPU)非常高的十类(VHR-10)地理空间目标检测数据集的数据集。这个数据集可以像 torchvision 一样自动下载、校验和提取。
from torch.utils.data import DataLoader
from torchgeo.datasets import VHR10
dataset = VHR10(root="...", download=True, checksum=True)
dataloader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
for batch in dataloader:
image = batch["image"]
label = batch["label"]
# train a model, or make predictions using a pre-trained model
所有 TorchGeo 数据集都与 PyTorch 数据加载器兼容,使它们易于集成到现有的训练工作流程中。TorchGeo 中的基准数据集与 torchvision 中类似数据集之间的唯一区别是,每个数据集都返回一个包含每个 PyTorch Tensor 键的字典。
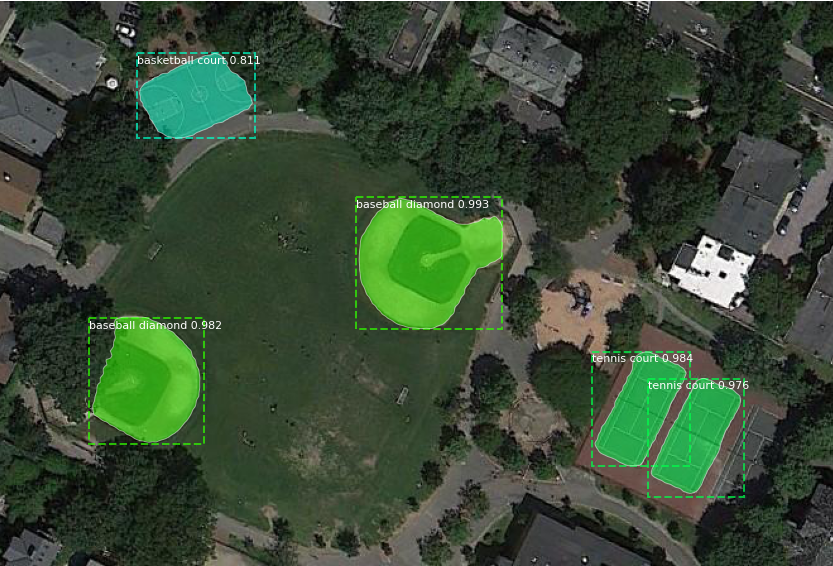
在 NWPU VHR-10 数据集上训练的 Mask R-CNN 模型的示例预测。该模型对所有具有高置信度分数的对象预测出锐利的边界框和掩码。
使用 PyTorch Lightning 实现可复现性
TorchGeo 的关键目标之一是实现可复现性。对于这些基准数据集中的许多,没有预定义的 train-val-test 划分,或者预定义的划分存在类别不平衡或地理分布问题。因此,文献中报告的性能指标要么无法复现,要么不能表明预训练模型在不同地理位置上的表现如何。
为了方便直接比较文献中发布的结果,并进一步减少在 TorchGeo 数据集上运行实验所需的样板代码,我们创建了具有明确定义的训练-验证-测试分割和各种任务(如分类、回归和语义分割)的训练器的 PyTorch Lightning 数据模块。这些数据模块展示了如何结合 kornia 库中的增强,包括预处理转换(带有预计算的通道统计信息),并使用户能够轻松地实验与数据本身相关的超参数(而不是建模过程)。在 Inria Aerial Image Labeling 数据集上训练语义分割模型就像导入几个模块和四行代码一样简单。
from pytorch_lightning import Trainer
from torchgeo.datamodules import InriaAerialImageLabelingDataModule
from torchgeo.trainers import SemanticSegmentationTask
datamodule = InriaAerialImageLabelingDataModule(root_dir="...", batch_size=64, num_workers=6)
task = SemanticSegmentationTask(segmentation_model="unet", encoder_weights="imagenet", learning_rate=0.1)
trainer = Trainer(gpus=1, default_root_dir="...")
trainer.fit(model=task, datamodule=datamodule)
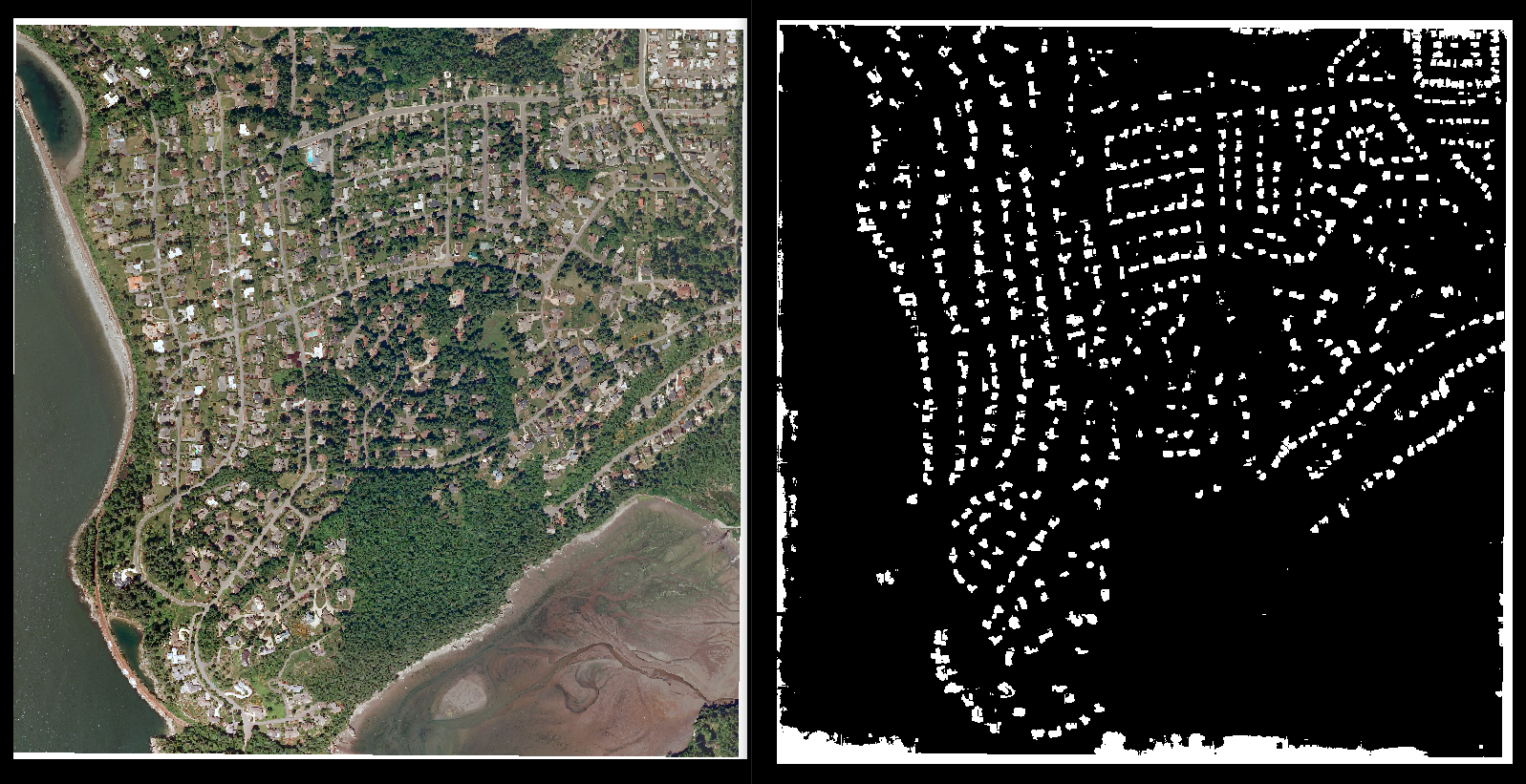
基于 Inria Aerial Image Labeling 数据集训练的 U-Net 模型生成的分割。重现这些结果就像导入几个模块和四行代码一样简单,这使得比较不同的模型和训练技术变得简单且容易。
在我们的预印本中,我们展示了一系列使用上述 datamodules 和 trainers 对 TorchGeo 中几个数据集进行基准测试的简单建模方法的结果。例如,我们发现简单的 ResNet-50 在 So2Sat 数据集上可以实现最先进的性能。这些类型的基线结果对于评估解决遥感数据问题时不同建模选择的贡献非常重要。
未来工作及贡献
为了使 TorchGeo 尽可能易于使用,特别是对于没有先前深度学习经验的用户,我们还有很多工作要做。我们计划通过扩展我们的教程来包括“编写自定义数据集”和“迁移学习”等主题,或者“土地覆盖制图”和“目标检测”等任务。
我们正在努力推进的一个重要项目是预训练模型。大多数遥感研究人员都使用非常小的标记数据集,可以从预训练模型和迁移学习技术中受益。TorchGeo 是第一个在多光谱影像上预训练模型的深度学习库。我们的目标是提供不同图像模态(光学、SAR、多光谱)和特定平台(Landsat、Sentinel、MODIS)的模型,以及展示它们在不同训练数据量下的性能基准结果。自监督学习是训练此类模型的有前景的方法。卫星影像数据集通常包含 PB 级的影像,但准确标记的数据集却很难获得。自监督学习方法将使我们能够直接在原始影像上训练,而无需大量标记数据集。
除了这些大型项目之外,我们一直在寻找添加新的数据集、数据增强转换和采样策略。如果您熟悉 Python 并且有兴趣为 TorchGeo 做出贡献,我们将非常欢迎!TorchGeo 遵循 MIT 开源许可,您几乎可以在任何项目中使用它。
外部链接:
- 主页:https://github.com/microsoft/torchgeo
- 文档:https://torchgeo.readthedocs.io/
- PyPI:https://pypi.org/project/torchgeo/
- 论文:https://arxiv.org/abs/2111.08872
如果您喜欢 TorchGeo,请在 GitHub 上给我们点个赞!如果您在工作中使用了 TorchGeo,请引用我们的论文。
致谢
我们感谢所有为创建 TorchGeo 库做出努力的贡献者,感谢微软 AI for Good 项目提供支持,以及 PyTorch 团队提供的指导。这项研究是 Blue Waters 持续百万亿次计算项目的一部分,该项目由美国国家科学基金会(奖项 OCI-0725070 和 ACI-1238993)、伊利诺伊州以及截至 2019 年 12 月的国家地理空间情报局支持。Blue Waters 是伊利诺伊大学香槟分校及其国家超级计算应用中心的一项联合努力。该研究部分得到了美国国家科学基金会(NSF)的资助,包括 IIS-1908104、OAC-1934634 和 DBI-2021898。