
理论上,注意力就是一切。然而在实践中,我们还需要像 FlashAttention 这样的优化注意力实现。
尽管这些融合的注意力实现显著提高了性能并实现了长上下文,但这种效率是以灵活性为代价的。您不能再通过编写几个 PyTorch 操作符来尝试新的注意力变体了——您通常需要编写一个新的自定义内核!这就像是一种“软件彩票”对机器学习研究人员来说——如果您的注意力变体不适合现有的优化内核,您将注定面临缓慢的运行时间和 CUDA OOMs。
一些注意力变体的例子包括因果注意力、相对位置嵌入、Alibi、滑动窗口注意力、PrefixLM、文档掩码/样本打包/锯齿形张量、Tanh 软上限、分页注意力等。更糟糕的是,人们经常想要这些的组合!滑动窗口注意力 + 文档掩码 + 因果 + 上下文并行?或者,PagedAttention + 滑动窗口 + Tanh 软上限呢?
下方左侧的图片展示了当今世界的状态——一些组合的口罩+偏差+设置已经实现了现有的内核。但是,各种选项导致设置数量呈指数级增长,因此总体上我们得到的支持相当零散。更糟糕的是,研究人员提出的新注意力变体将没有任何支持。
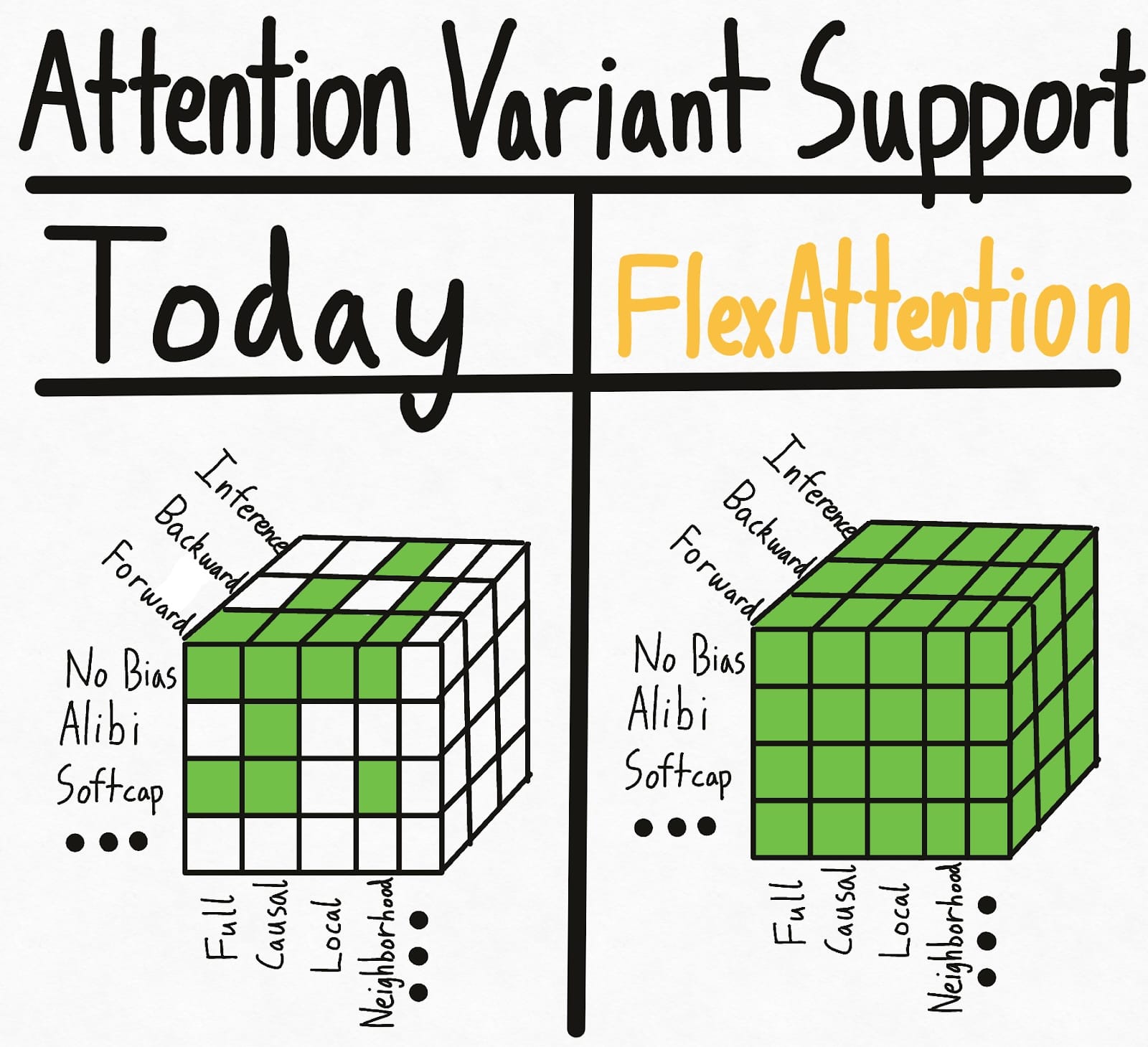
为了一劳永逸地解决这个问题,我们引入了 FlexAttention,一个新的 PyTorch API。
- 我们提供了一个灵活的 API,允许通过几行惯用的 PyTorch 代码实现许多注意力变体(包括到目前为止博客文章中提到的所有变体)。
- 我们通过
torch.compile将其降低为融合的 FlashAttention 内核,生成一个不产生额外内存且性能与手写内核相媲美的 FlashAttention 内核。 - 我们还自动生成反向传播,利用 PyTorch 的 autograd 机制。
- 最后,我们还可以利用注意力掩码的稀疏性,在标准注意力实现上取得显著改进。
在 FlexAttention 中,我们希望尝试新的注意力变体只受限于你的想象力。
你可以在 Attention Gym 找到许多 FlexAttention 的示例:https://github.com/pytorch-labs/attention-gym。如果你有任何酷炫的应用,欢迎提交示例!
PS:我们也觉得这个 API 非常有趣,因为它以有趣的方式利用了大量的现有 PyTorch 基础设施——更多内容将在最后介绍。
FlexAttention
这里是经典的注意力方程式:
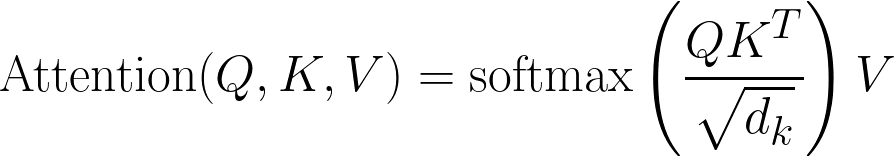
代码形式如下:
Q, K, V: Tensor[batch_size, num_heads, sequence_length, head_dim]
score: Tensor[batch_size, num_heads, sequence_length, sequence_length] = (Q @ K) / sqrt(head_dim)
probabilities = softmax(score, dim=-1)
output: Tensor[batch_size, num_heads, sequence_length, head_dim] = probabilities @ V
FlexAttention 允许用户定义一个函数 score_mod:

代码形式如下:
Q, K, V: Tensor[batch_size, num_heads, sequence_length, head_dim]
score: Tensor[batch_size, num_heads, sequence_length, sequence_length] = (Q @ K) / sqrt(head_dim)
modified_scores: Tensor[batch_size, num_heads, sequence_length, sequence_length] = score_mod(score)
probabilities = softmax(modified_scores, dim=-1)
output: Tensor[batch_size, num_heads, sequence_length, head_dim] = probabilities @ V
此函数允许您在 softmax 之前修改注意力分数。令人惊讶的是,这足以满足绝大多数注意力变体(以下为示例)!
具体来说, score_mod 的预期签名有些独特。
def score_mod(score: f32[], b: i32[], h: i32[], q_idx: i32[], kv_idx: i32[])
return score # noop - standard attention
换句话说, score 是一个标量 PyTorch 张量,表示查询标记和键标记的点积。其余的参数告诉你当前正在计算哪个点积 - b (批处理中的当前元素)、 h (当前头)、 q_idx (查询中的位置)、 kv_idx (键/值张量中的位置)。
要应用此函数,我们可以将其实现为
for b in range(batch_size):
for h in range(num_heads):
for q_idx in range(sequence_length):
for kv_idx in range(sequence_length):
modified_scores[b, h, q_idx, kv_idx] = score_mod(scores[b, h, q_idx, kv_idx], b, h, q_idx, kv_idx)
当然,这并不是 FlexAttention 在底层实现的真正方式。利用 torch.compile ,我们自动将你的函数降低到单个融合的 FlexAttention 内核 - 保证或退款!
这个 API 最终表现得非常灵活。让我们看看一些例子。
分数调整示例
全注意力机制
首先我们来做“全注意力机制”,或者标准的双向注意力。在这种情况下, score_mod 是一个空操作 - 它接收分数作为输入,然后原样返回。
def noop(score, b, h, q_idx, kv_idx):
return score
然后将其端到端使用(包括正向和反向):
from torch.nn.attention.flex_attention import flex_attention
flex_attention(query, key, value, score_mod=noop).sum().backward()
相对位置编码
一种常见的注意力变体是“相对位置编码”。与在查询和键中编码绝对距离不同,相对位置编码根据查询和键之间的“距离”调整分数。
def relative_positional(score, b, h, q_idx, kv_idx):
return score + (q_idx - kv_idx)
注意,与典型实现不同,这不需要实例化一个 SxS 张量。相反,FlexAttention 在内核中“实时”计算偏置值,从而带来显著的内存和性能提升。
ALiBi 偏置
来源:训练短,测试长:带有线性偏置的注意力实现输入长度外推
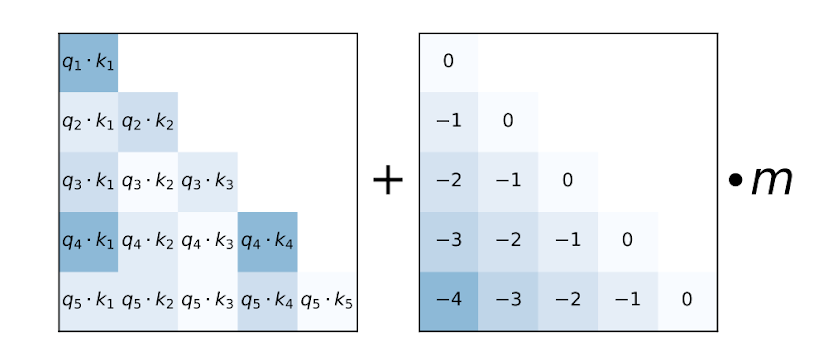
ALiBi 在《训练短,测试长:带有线性偏置的注意力实现输入长度外推》中被引入,并声称在推理阶段的长度外推具有有益的特性。值得注意的是,MosaicML 指出“缺乏内核支持”是他们最终从 ALiBi 切换到旋转嵌入的主要原因。
Alibi 与相对位置编码类似,只有一个例外——它有一个通常是预先计算的每个头的因子。
alibi_bias = generate_alibi_bias() # [num_heads]
def alibi(score, b, h, q_idx, kv_idx):
bias = alibi_bias[h] * (kv_idx - q_idx)
return score + bias
这展示了 torch.compile 提供的一个有趣的灵活性——我们可以从 alibi_bias 加载,即使它没有被明确地作为输入传递!生成的 Triton 内核将计算正确的加载量,并从 alibi_bias 张量中融合。请注意,即使我们重新生成 alibi_bias ,我们也不需要重新编译。
软上限
软上限是一种在 Gemma2 和 Grok-1 中使用的技巧,用于防止 logits 无限制地增长过大。在 FlexAttention 中,它看起来像:
softcap = 20
def soft_cap(score, b, h, q_idx, kv_idx):
score = score / softcap
score = torch.tanh(score)
score = score * softcap
return score
注意,我们在这里还自动从正向传递生成反向传递。尽管这种实现从语义上是正确的,但出于性能考虑,我们可能希望在这种情况下使用 tanh 近似。更多详情请参阅 attention-gym。
因果掩码
虽然双向注意力是最简单的,但原始的《Attention is All You Need》论文以及绝大多数LLMs在解码器仅设置中使用注意力,其中每个标记只能关注其之前的标记。人们通常认为这是一种下三角掩码,但通过 score_mod API 可以表示为:
def causal_mask(score, b, h, q_idx, kv_idx):
return torch.where(q_idx >= kv_idx, score, -float("inf"))
基本上,如果查询标记在键标记“之后”,我们保留分数。否则,我们将其设置为-无穷大,从而确保它不会参与 softmax 计算。
然而,掩码与其他修改相比是特殊的——如果某些内容被掩码,我们可以完全跳过其计算!在这种情况下,因果掩码大约有 50%的稀疏性,如果不利用稀疏性,会导致 2 倍的性能下降。尽管这个 score_mod 足以正确实现因果掩码,但要获得稀疏性的性能优势,还需要另一个概念—— mask_mod 。
掩码修改
为了利用掩码的稀疏性,我们需要做更多的工作。具体来说,通过将 mask_mod 传递给 create_block_mask ,我们可以创建一个 BlockMask 。然后 FlexAttention 可以使用 BlockMask 来利用稀疏性!
mask_mod 的签名与 score_mod 非常相似——只是没有 score 。特别是
# returns True if this position should participate in the computation
mask_mod(b, h, q_idx, kv_idx) => bool
注意 score_mod 比 mask_mod 具有更强的表达能力。然而,对于掩码,建议使用 mask_mod 和 create_block_mask ,因为它性能更好。请参阅 FAQ 了解为什么 score_mod 和 mask_mod 是分开的。
现在,让我们看看如何使用 mask_mod 实现因果掩码。
因果掩码
from torch.nn.attention.flex_attention import create_block_mask
def causal(b, h, q_idx, kv_idx):
return q_idx >= kv_idx
# Because the sparsity pattern is independent of batch and heads, we'll set them to None (which broadcasts them)
block_mask = create_block_mask(causal, B=None, H=None, Q_LEN=1024, KV_LEN=1024)
# In this case, we don't need a score_mod, so we won't pass any in.
# However, score_mod can still be combined with block_mask if you need the additional flexibility.
flex_attention(query, key, value, block_mask=block_mask)
注意, create_block_mask 是一个相对昂贵的操作!虽然 FlexAttention 在变化时不需要重新编译,但如果您不仔细缓存它,可能会导致显著的性能下降(请参阅常见问题解答以获取最佳实践建议)。
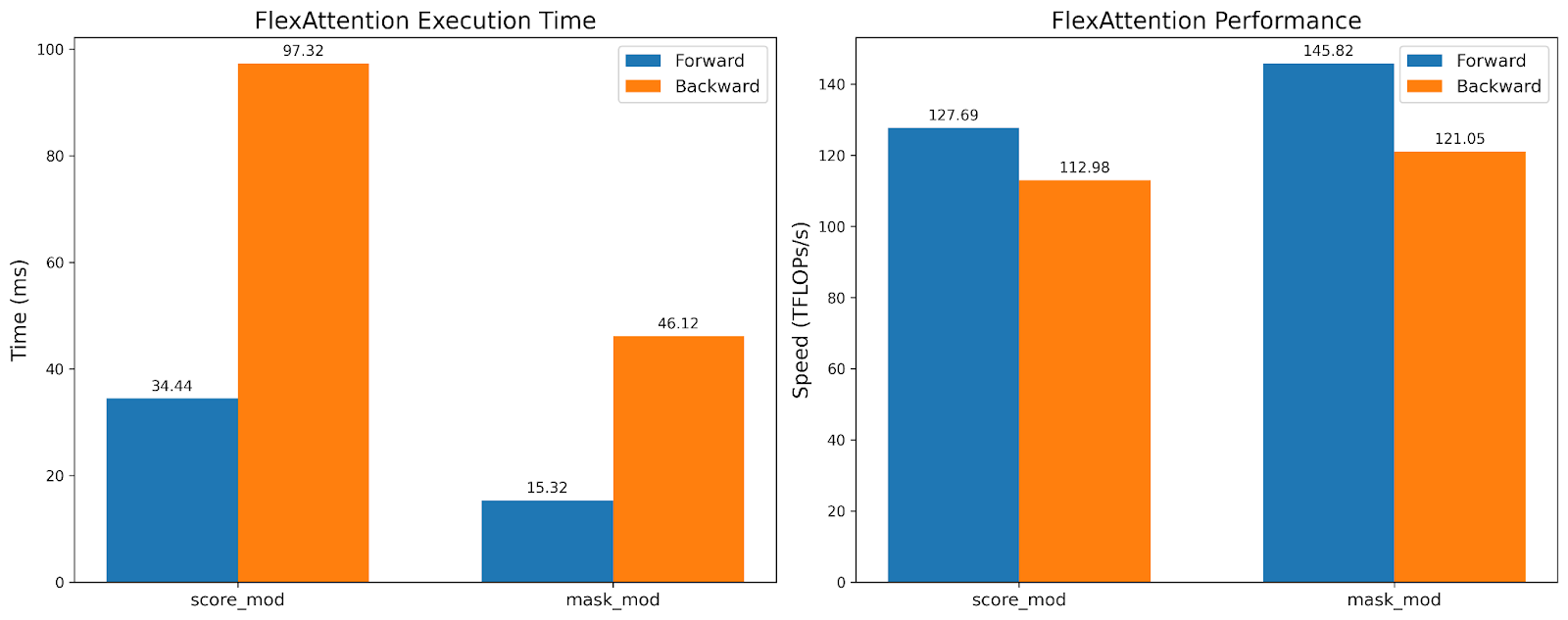
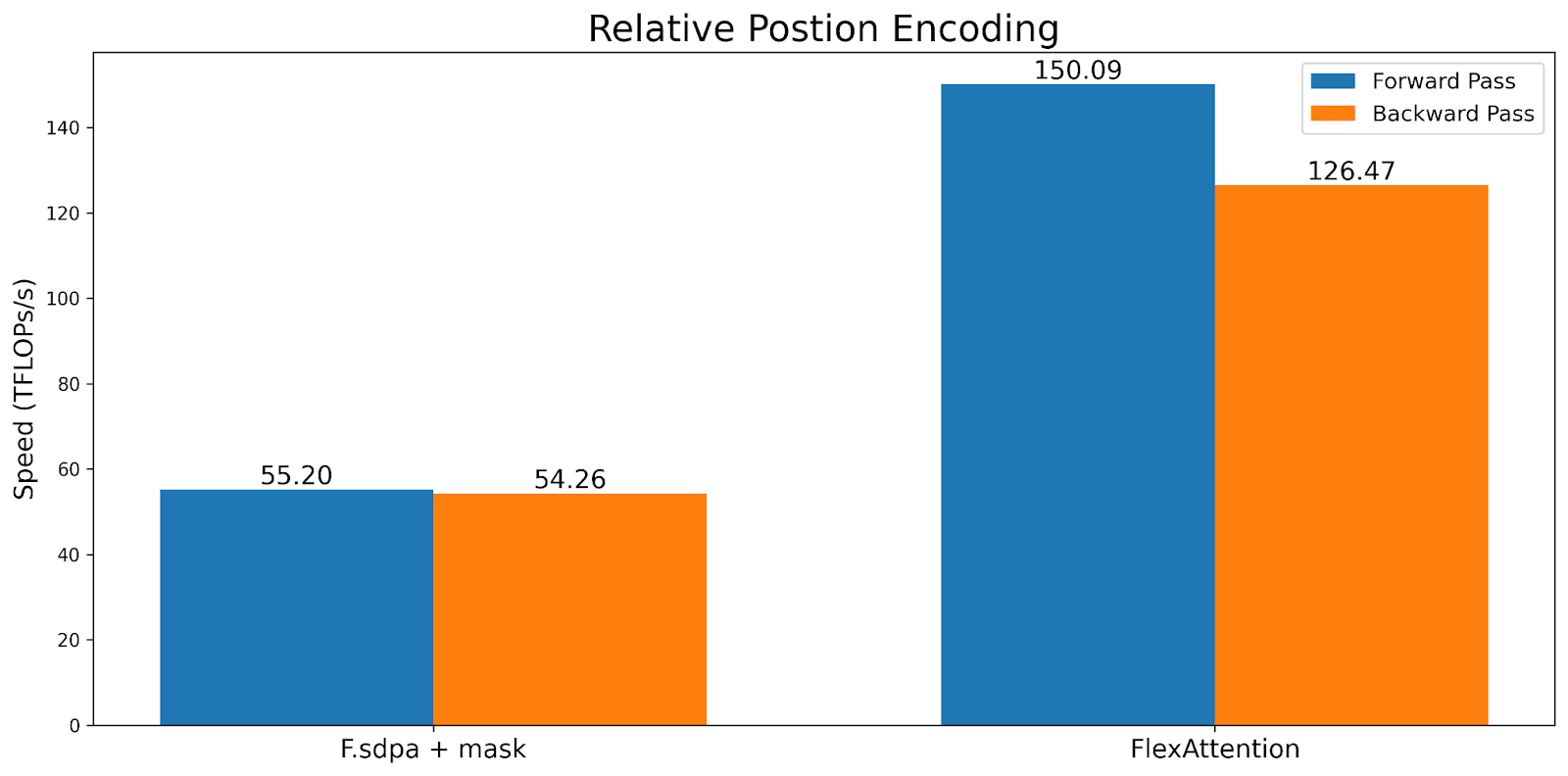
虽然 TFlops 大致相同,但 mask_mod 版本的执行时间快了 2 倍!这表明我们可以利用 BlockMask 提供的稀疏性,而不会损失硬件效率。
滑动窗口 + 因果
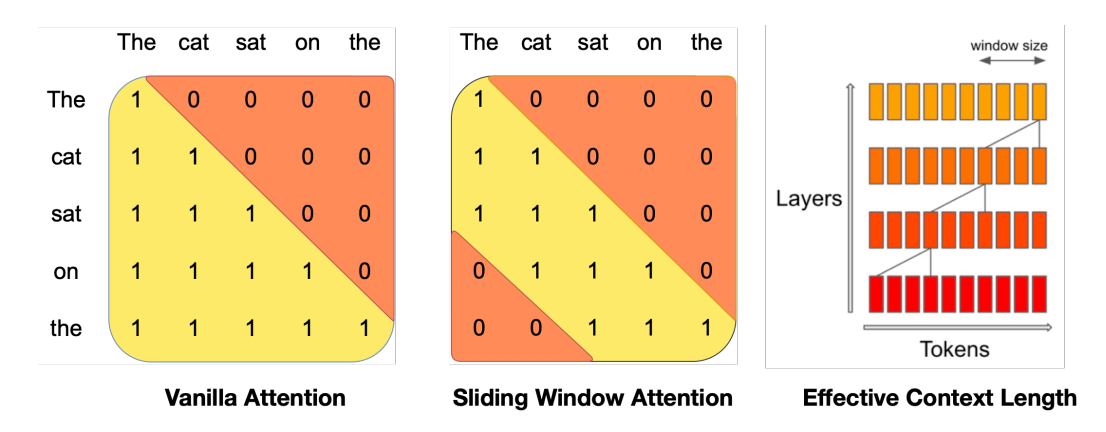
来源:Mistral 7B
滑动窗口注意力(也称为局部注意力)由 Mistral 推广,它利用了最近标记最有用的直觉。特别是,它允许查询标记仅关注最近的 1024 个标记。这通常与因果注意力一起使用。
SLIDING_WINDOW = 1024
def sliding_window_causal(b, h, q_idx, kv_idx):
causal_mask = q_idx >= kv_idx
window_mask = q_idx - kv_idx <= SLIDING_WINDOW
return causal_mask & window_mask
# If you want to be cute...
from torch.nn.attention import and_masks
def sliding_window(b, h, q_idx, kv_idx)
return q_idx - kv_idx <= SLIDING_WINDOW
sliding_window_causal = and_masks(causal_mask, sliding_window)
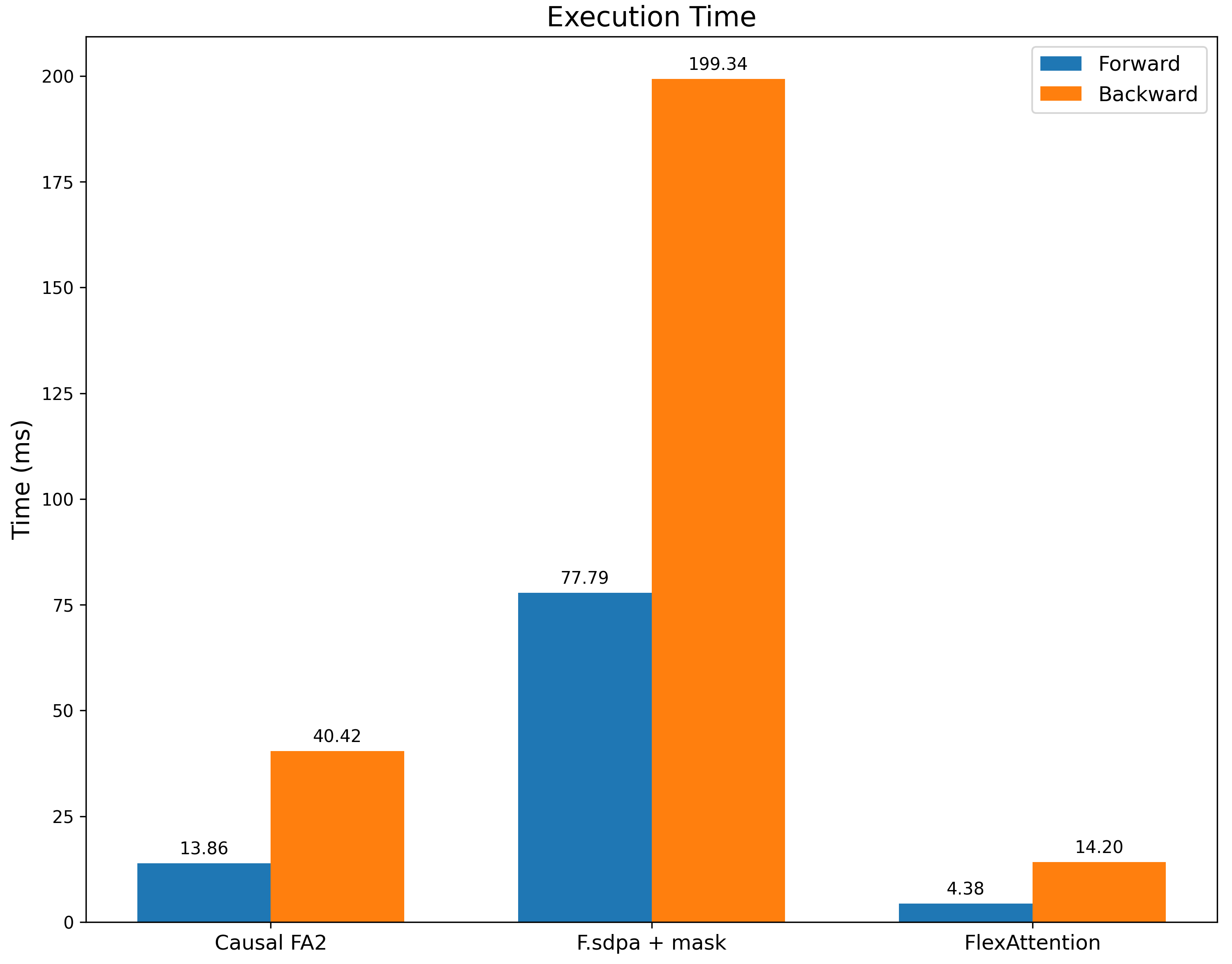
我们将其与带有滑动窗口掩码的 F.scaled_dot_product_attention 以及带有因果掩码的 FA2(作为性能参考点)进行了基准测试。我们不仅比 F.scaled_dot_product_attention 快得多,而且比带有因果掩码的 FA2 也要快得多,因为这种掩码的稀疏性显著更高。
PrefixLM
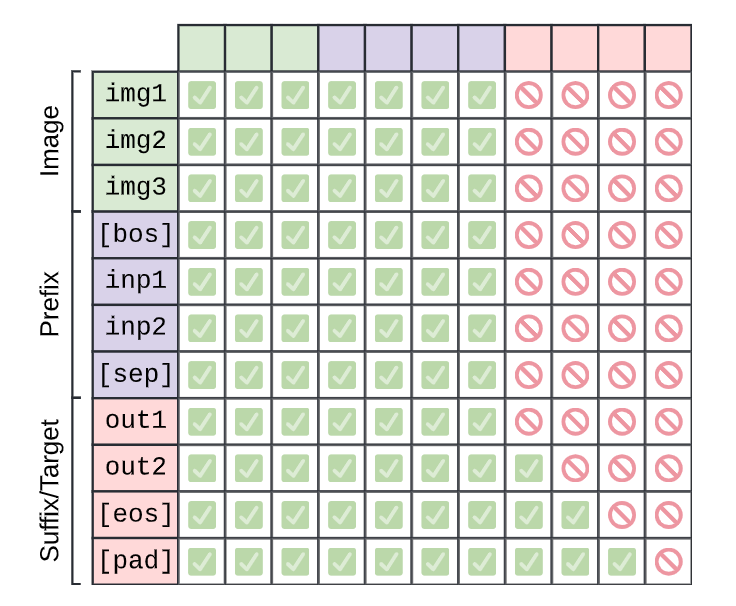
来源:PaliGemma:一个通用的 3B VLM 用于迁移
在《探索统一文本到文本变换器在迁移学习中的极限》一文中提出的 T5 架构,描述了一种在“前缀”上执行全双向注意力,而在其余部分执行因果注意力的注意力变体。我们再次组合两个掩码函数来完成这个任务,一个用于因果掩码,另一个基于前缀长度。
prefix_length: [B]
def prefix_mask(b, h, q_idx, kv_idx):
return kv_idx <= prefix_length[b]
prefix_lm_causal = or_masks(prefix_mask, causal_mask)
# In this case, our mask is different per sequence so we set B equal to our batch size
block_mask = create_block_mask(prefix_lm_causal, B=B, H=None, S, S)
就像 score_mod 一样, mask_mod 允许我们引用不是函数显式输入的其他张量!然而,在 prefixLM 中,稀疏模式会根据输入而变化。这意味着对于每个新的输入批次,我们都需要重新计算 BlockMask 。一种常见的模式是在模型的开始处调用 create_block_mask ,然后重用 block_mask 来处理模型中的所有注意力调用。参见“重新计算块掩码与重新编译”。
然而,作为交换,我们不仅能够为 prefixLM 获得一个高效的注意力内核,还能够利用输入中存在的任何稀疏性!FlexAttention 将根据块掩码数据动态调整其性能,而无需重新编译内核。
文档遮罩/锯齿序列
另一种常见的注意力变体是文档遮罩/锯齿序列。想象一下,你有一系列长度不同的序列。你希望一起训练它们,但不幸的是,大多数操作员只接受矩形张量。
通过 BlockMask ,我们也可以在 FlexAttention 中高效地支持这一点!
- 首先,我们将所有序列展平成一个序列,包含序列长度之和的标记。
- 然后,我们计算每个标记所属的 document_id。
- 最后,在我们的
mask_mod中,我们简单地判断查询和 kv 标记是否属于同一文档!
# The document that each token belongs to.
# e.g. [0, 0, 0, 1, 1, 2, 2, 2, 2, 2, 2] corresponds to sequence lengths 3, 2, and 6.
document_id: [SEQ_LEN]
def document_masking(b, h, q_idx, kv_idx):
return document_id[q_idx] == document_id[kv_idx]
就这样!在这种情况下,我们看到我们最终得到一个块对角掩码。
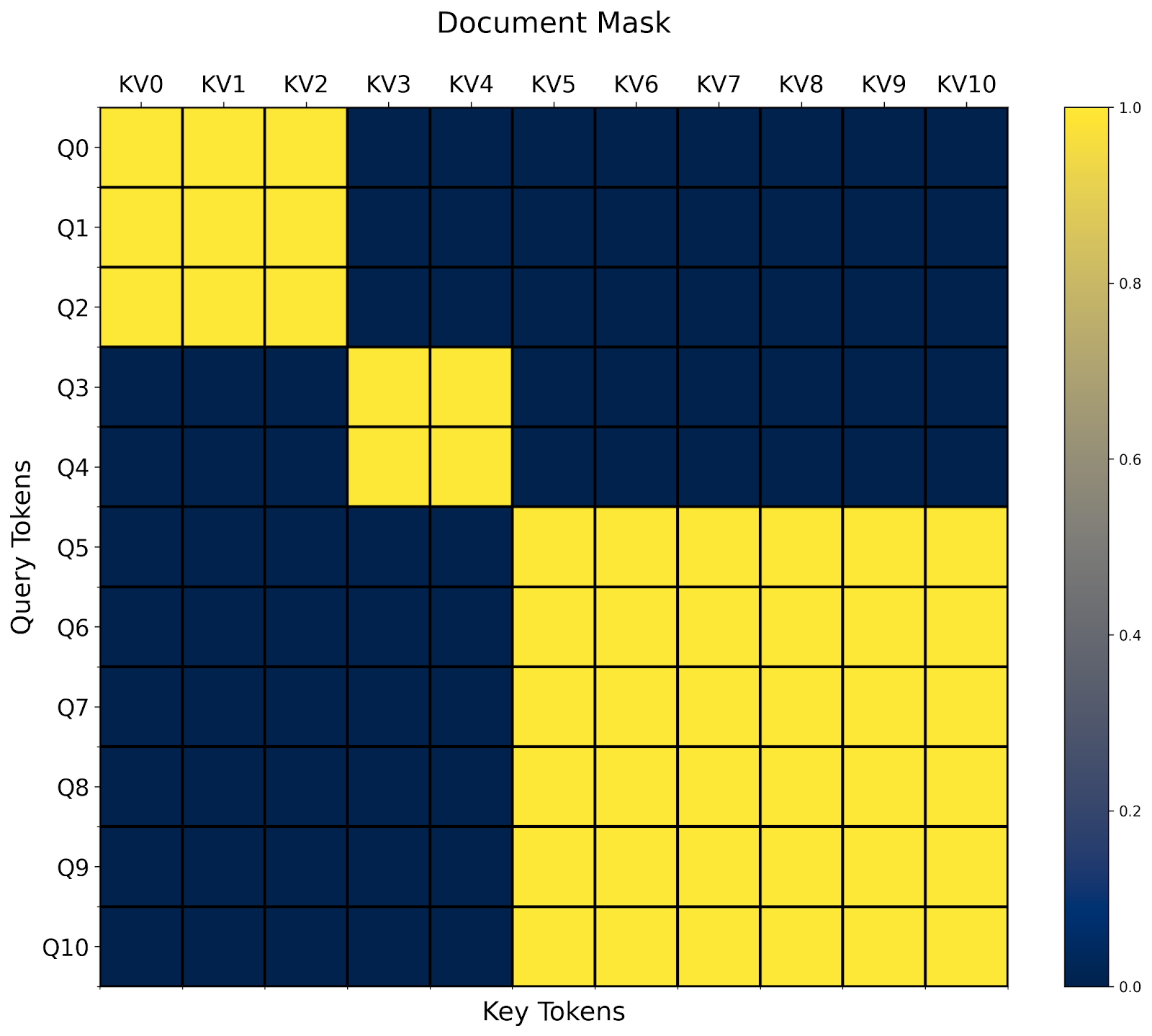
关于文档掩码的一个有趣方面是,很容易看出它如何可能与任意组合的其他掩码结合。例如,我们已经在上一节中定义了 prefixlm_mask 。我们现在还需要定义一个 prefixlm_document_mask 函数吗?
在这些情况下,我们发现一种非常有用的模式,我们称之为“高级修改”。在这种情况下,我们可以将现有的 mask_mod 自动转换成适用于锯齿状序列的版本!
def generate_doc_mask_mod(mask_mod, document_id):
# Get unique document IDs and their counts
_, counts = torch.unique_consecutive(document_id, return_counts=True)
# Create cumulative counts (offsets)
offsets = torch.cat([torch.tensor([0], device=document_id.device), counts.cumsum(0)[:-1]])
def doc_mask_wrapper(b, h, q_idx, kv_idx):
same_doc = document_id[q_idx] == document_id[kv_idx]
q_logical = q_idx - offsets[document_id[q_idx]]
kv_logical = kv_idx - offsets[document_id[kv_idx]]
inner_mask = mask_mod(b, h, q_logical, kv_logical)
return same_doc & inner_mask
return doc_mask_wrapper
例如,给定上面的 prefix_lm_causal 掩码,我们可以将其转换成适用于打包文档的版本,如下所示:
prefix_length = torch.tensor(2, dtype=torch.int32, device="cuda")
def prefix_mask(b, h, q_idx, kv_idx):
return kv_idx < prefix_length
prefix_lm_causal = or_masks(prefix_mask, causal_mask)
doc_prefix_lm_causal_mask = generate_doc_mask_mod(prefix_lm_causal, document_id)
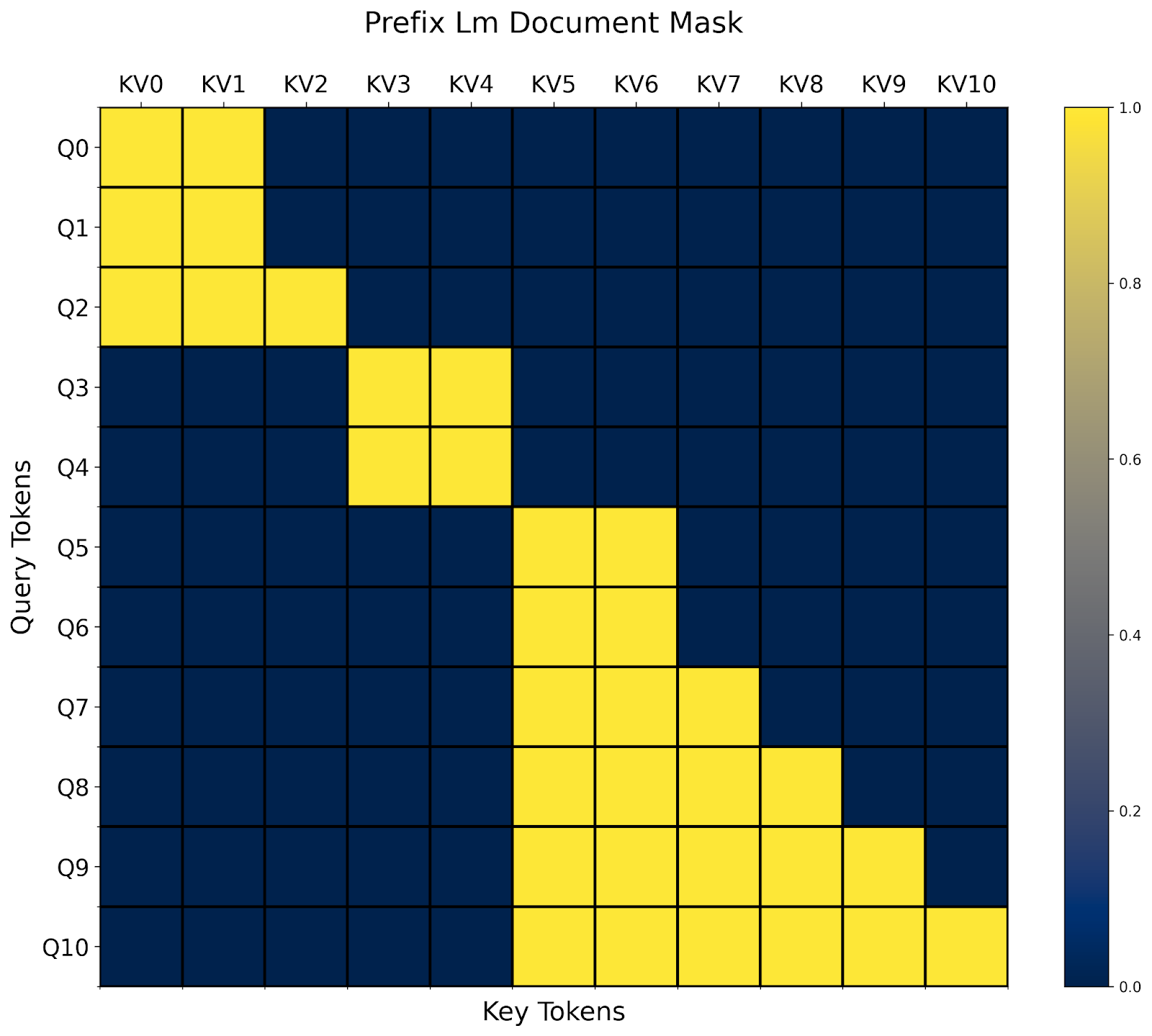
现在,这个掩码是“block-prefixLM-diagonal”形状的。:)
这就是我们的所有示例!注意力的变体远比我们能够列出的要多,所以请查看 Attention Gym 获取更多示例。我们希望社区也能贡献一些他们最喜欢的 FlexAttention 应用。
常见问题解答
Q: FlexAttention 何时需要重新编译?
由于 FlexAttention 利用 torch.compile 进行图捕获,实际上在广泛的情况下可以避免重新编译。值得注意的是,即使捕获的张量值发生变化,它也不需要重新编译!
flex_attention = torch.compile(flex_attention)
def create_bias_mod(bias)
def bias_mod(score, b, h, q_idx, kv_idx):
return score + bias
return bias_mod
bias_mod1 = create_bias_mod(torch.tensor(0))
flex_attention(..., score_mod=bias_mod1) # Compiles the kernel here
bias_mod2 = create_bias_mod(torch.tensor(2))
flex_attention(..., score_mod=bias_mod2) # Doesn't need to recompile!
即使改变块稀疏性也不需要重新编译。然而,如果块稀疏性发生变化,我们确实需要重新计算 BlockMask。
问:我们应该何时重新计算 BlockMask?
当块稀疏度发生变化时,我们需要重新计算 BlockMask。尽管计算 BlockMask 的成本远低于重新编译(大约几百微秒,而重新编译需要几秒),但您仍然应该注意不要过度重新计算 BlockMask。
这里有一些常见的模式和一些建议,您可能如何处理它们。
遮罩从未改变(例如因果遮罩)
在这种情况下,您可以简单地预先计算块掩码并将其全局缓存,以便在所有注意力调用中重复使用。
block_mask = create_block_mask(causal_mask, 1, 1, S,S)
causal_attention = functools.partial(flex_attention, block_mask=block_mask)
掩码每批都会变化(例如,文档掩码)
在这种情况下,我们建议在模型开始时计算 BlockMask,并将其贯穿整个模型 - 为所有层重复使用 BlockMask。
def forward(self, x, doc_mask):
# Compute block mask at beginning of forwards
block_mask = create_block_mask(doc_mask, None, None, S, S)
x = self.layer1(x, block_mask)
x = self.layer2(x, block_mask)
...
# amortize block mask construction cost across all layers
x = self.layer3(x, block_mask)
return x
掩码每层都会变化(例如,数据相关稀疏性)
这是最困难的设置,因为我们无法将块掩码计算分摊到多个 FlexAttention 调用中。尽管 FlexAttention 确实仍然可以从这种情况下受益,但块掩码的实际好处取决于您的注意力掩码有多稀疏以及我们构建块掩码的速度有多快。这让我们想到了...
问:我们如何更快地计算块掩码?
create_block_mask 在内存和计算方面都相当昂贵,因为确定一个块是否完全稀疏需要在块的每个点上评估 mask_mod 。有几种方法可以解决这个问题:
- 如果您的掩码在批大小或头之间相同,请确保您已在这些掩码上进行了广播(即在
create_block_mask中将它们设置为None)。 - 编译
create_block_mask。遗憾的是,由于一些不幸的限制,torch.compile今天无法直接在create_block_mask上工作。然而,您可以设置_compile=True,这将显著降低峰值内存和运行时间(在我们的测试中通常是一个数量级的降低)。 -
为 BlockMask 编写一个自定义构造函数。BlockMask 的元数据非常简单(请参阅文档)。它本质上是由两个张量组成。a.
num_blocks:每个查询块计算的 KV 块的数量。
b.indices:每个查询块计算的 KV 块的位置。例如,这里是一个为
causal_mask的自定义 BlockMask 构造函数。
def create_causal_mask(S):
BLOCK_SIZE = 128
# The first query block computes one block, the second query block computes 2 blocks, etc.
num_blocks = torch.arange(S // BLOCK_SIZE, device="cuda") + 1
# Since we're always computing from the left to the right,
# we can use the indices [0, 1, 2, ...] for every query block.
indices = torch.arange(S // BLOCK_SIZE, device="cuda").expand(
S // BLOCK_SIZE, S // BLOCK_SIZE
)
num_blocks = num_blocks[None, None, :]
indices = indices[None, None, :]
return BlockMask(num_blocks, indices, BLOCK_SIZE=BLOCK_SIZE, mask_mod=causal_mask)
问:为什么 score_mod 和 mask_mod 不同? mask_mod 难道不是 score_mod 的一个特例吗?
非常敏锐的问题,假设的听众!实际上,任何 mask_mod 都可以轻松转换为 score_mod (我们不建议在实际中使用此功能!)
def mask_mod_as_score_mod(b, h, q_idx, kv_idx):
return torch.where(mask_mod(b, h, q_idx, kv_idx), score, -float("inf"))
那么,如果 score_mod 可以实现 mask_mod 的所有功能,那么拥有 mask_mod 的意义在哪里呢?
一个直接的挑战: score_mod 需要一个实际的 score 值作为输入,但当我们预计算 BlockMask 时,我们没有实际的 score 值。我们可以通过传递所有零来伪造这些值,如果 score_mod 返回 -inf ,那么我们将其视为已屏蔽(实际上我们最初就是这样做的!)
然而,有两个问题。第一个问题是这很笨拙——如果用户的 score_mod 在输入为 0 时返回 -inf ,或者如果用户的 score_mod 用一个大负值代替了 -inf ,那会怎样?这似乎是在把一个圆木塞进方孔。然而,将 mask_mod 与 score_mod 分开还有一个更重要的原因——它本质上更有效率!
事实上,对每个计算元素应用掩码实际上是非常昂贵的——我们的基准测试显示性能下降了 15-20%!所以,虽然我们可以通过跳过一半的计算来获得显著的加速,但我们失去了很大一部分速度提升,因为我们仍然需要为每个元素应用掩码!
幸运的是,如果我们可视化因果掩码,我们会注意到绝大多数块根本不需要“因果掩码”——它们已经完全计算了!只有对角线上的块,部分计算和部分掩码,才需要应用掩码。
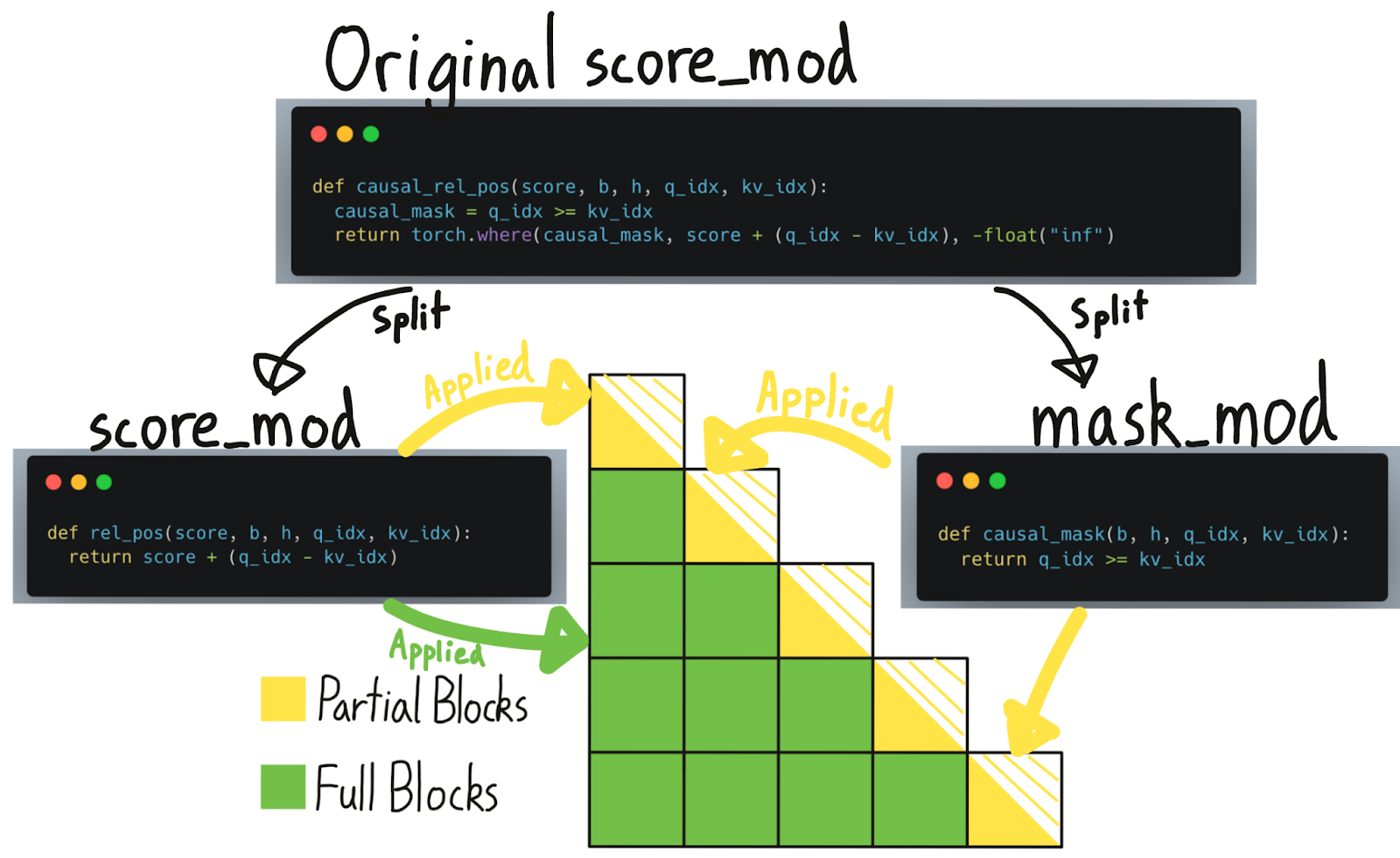
BlockMask 之前告诉我们哪些块需要计算,哪些块可以跳过。现在,我们进一步扩展这个数据结构,使其也能告诉我们哪些块是“完全计算”的(即可以跳过掩码),与“部分计算”的(即需要应用掩码)。请注意,尽管在“完全计算”的块上可以跳过掩码,但像相对位置编码这样的其他 score_mod 仍然需要应用。
仅给定一个 score_mod ,我们无法准确判断其中的哪些部分是“掩码”。因此,用户必须自己将这些部分分离出来成为 mask_mod 。
问:BlockMask 需要多少额外的内存?
BlockMask 的元数据大小为 [BATCH_SIZE, NUM_HEADS, QUERY_LEN//BLOCK_SIZE, KV_LEN//BLOCK_SIZE]. 。如果掩码在批次或头维度上是相同的,则可以在该维度上广播以节省内存。
在默认的 BLOCK_SIZE 128 中,我们预计对于大多数用例,内存使用将非常微不足道。例如,对于长度为 100 万的序列,BlockMask 只会额外使用 60MB 的内存。如果这成为问题,您可以增加块大小: create_block_mask(..., BLOCK_SIZE=1024). 例如,将 BLOCK_SIZE 增加到 1024 将导致此元数据降至不到 1 兆字节。
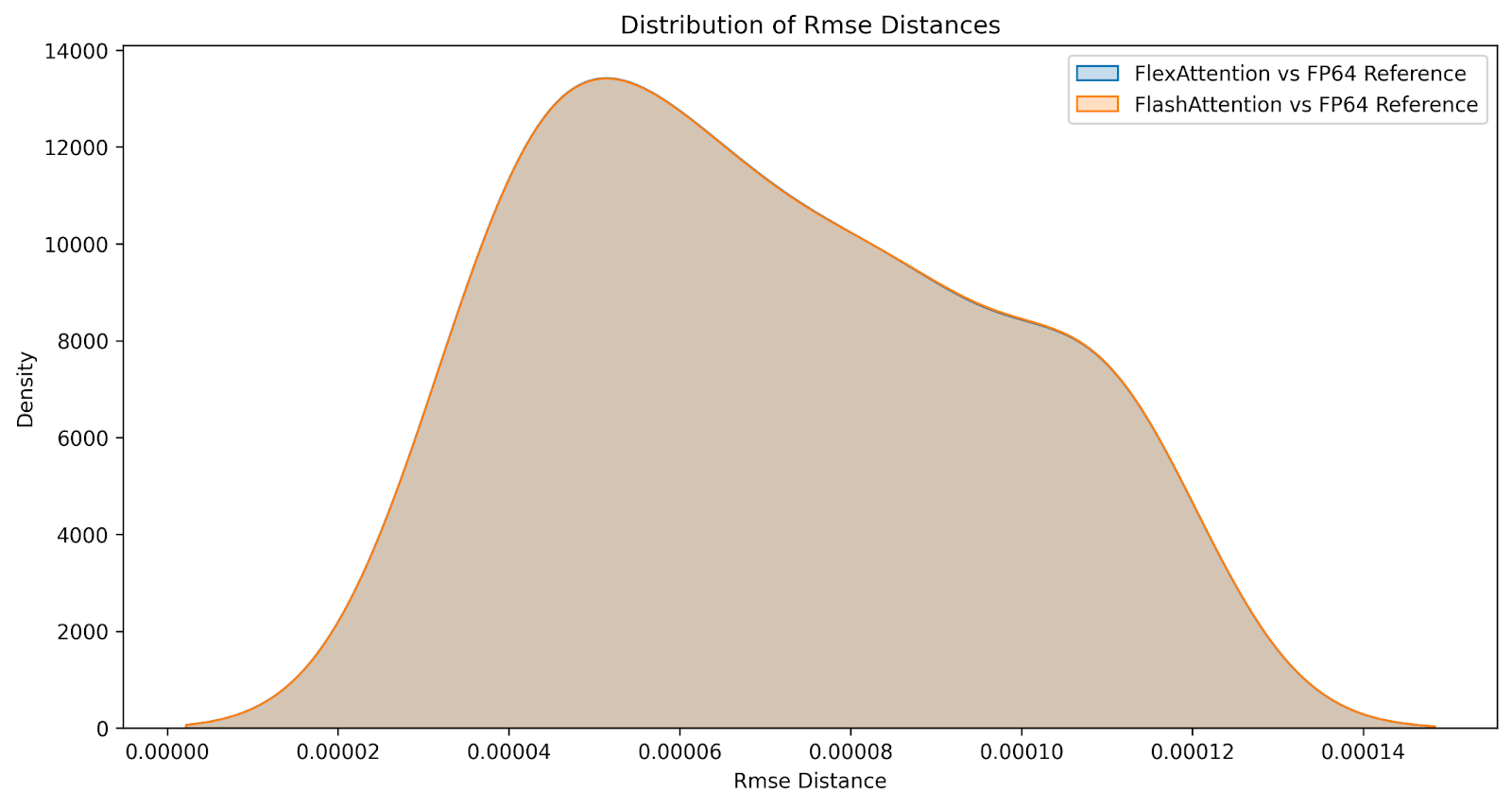
问:数值如何比较?
虽然结果并非位对位相同,但我们相信 FlexAttention 在数值上与 FlashAttention 一致。我们生成了以下差异分布,比较了 FlashAttention 与 FlexAttention 在大量输入上的因果和非因果注意力变体。误差几乎相同。
性能
一般而言,FlexAttention 的性能几乎与手写的 Triton 内核相当,这并不令人意外,因为我们大量使用了手写的 Triton 内核。然而,由于其通用性,我们确实会付出一点性能上的代价。例如,我们必须承担一些额外的延迟来确定下一个要计算的块。在某些情况下,我们提供了一些可以影响内核性能同时改变其行为的内核选项。它们可以在这里找到:性能旋钮
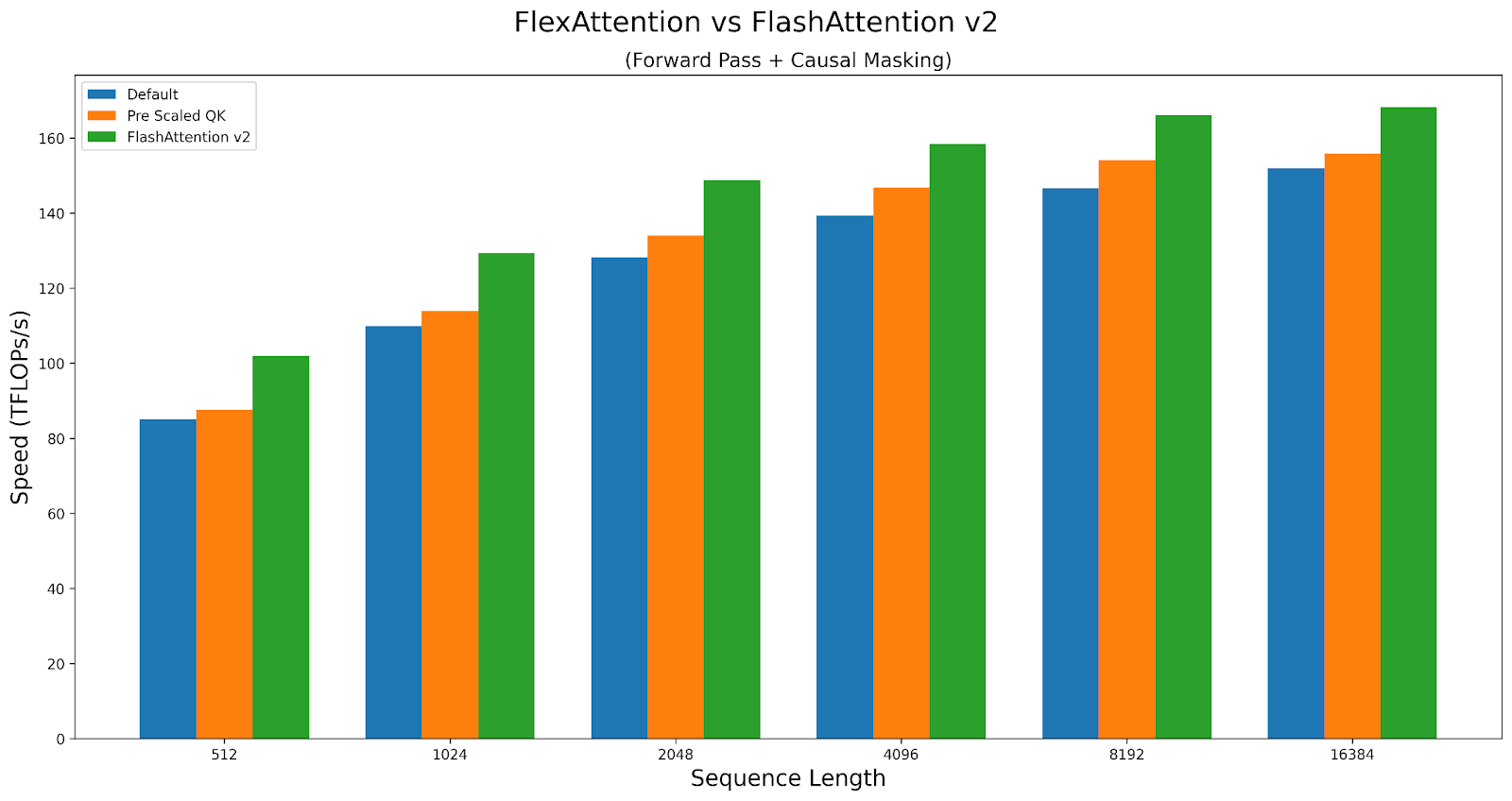
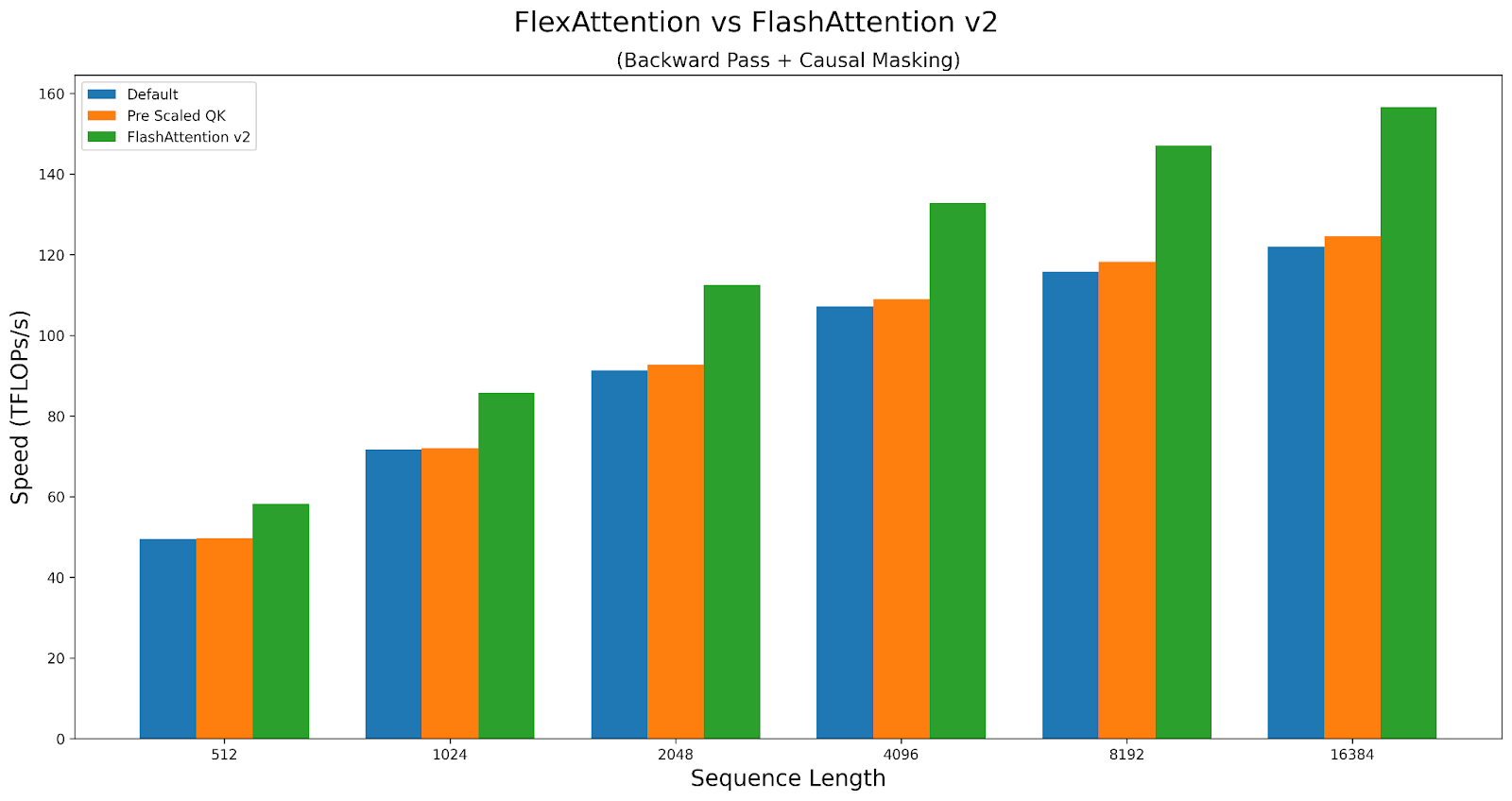
作为案例研究,让我们探讨这些旋钮如何影响因果注意力的性能。我们将比较 Triton 内核与 FlashAttentionv2 在 A100 上的性能。脚本可以在这里找到。
FlexAttention 在正向传递中达到了 FlashAttention2 性能的 90%,在反向传递中达到了 85%。FlexAttention 目前使用的是一个确定性算法,它比 FAv2 重新计算更多的中间值,但我们有计划改进 FlexAttention 的反向算法,希望缩小这个差距!
结论
我们希望您在使用 FlexAttention 时能像我们开发它时一样愉快!在开发过程中,我们发现这个 API 的应用范围比我们预期的要多得多。我们已经看到它将 torchtune 的样本打包吞吐量提高了 71%,取代了研究人员花费一周时间编写自己的自定义 Triton 内核的需求,并且与自定义手写注意力变体相比,提供了有竞争力的性能。
最后,让我们在实现 FlexAttention 时感到非常有趣的一点是,我们能够以有趣的方式利用大量现有的 PyTorch 基础设施。例如,TorchDynamo(torch.compile 的前端)的一个独特之处在于,它不需要将编译函数中使用的张量明确传递为输入。这使得我们能够编译像文档掩码这样的 mod,这些 mod 需要访问全局变量,而全局变量需要改变!
bias = torch.randn(1024, 1024)
def score_mod(score, b, h, q_idx, kv_idx):
return score + bias[q_idx][kv_idx] # The bias tensor can change!
此外, torch.compile 是一个通用的图捕获机制,这也使得它能够支持更多“高级”的转换,例如将任何 mask_mod 转换为一个可以与交错张量一起工作的转换。
我们还利用了 TorchInductor(torch.compile 的后端)基础设施为 Triton 模板提供支持。这不仅使得支持 FlexAttention 的代码生成变得容易,而且还自动为我们提供了对动态形状以及尾端融合(即将运算符融合到注意力机制的末尾)的支持!在未来,我们计划扩展这一支持,以允许对注意力或 RadixAttention 等内容的量化版本进行支持。
此外,我们还利用了高阶运算符、PyTorch 的 autograd 自动生成反向传播,以及 vmap 自动应用 score_mod 以创建 BlockMask。
当然,如果没有 Triton 和 TorchInductor 生成 Triton 代码的能力,这个项目也不可能实现。
我们期待在未来的更多应用中利用这里使用的方法!
局限性与未来工作
- FlexAttention 目前已在 PyTorch 夜间版本中提供,我们计划在 2.5.0 版本中将其作为原型功能发布
- 本文未涵盖如何使用 FlexAttention 进行推理(或如何实现分页注意力)- 我们将在后续文章中介绍这些内容。
- 我们正在努力提高 FlexAttention 的性能,使其与 FlashAttention3 在 H100 GPU 上的性能相匹配。
- FlexAttention 需要所有序列长度都是 128 的倍数 - 这将很快得到解决。
- 我们计划很快添加 GQA 支持 - 目前,您只需复制 kv 头部即可。
致谢
我们想突出一些启发 FlexAttention 的先前工作(和人物)。
- 三道(Tri Dao)的 FlashAttention 工作
- 马萨·弗朗西斯科和 Xformers 团队在 Triton 中的 BlockSparseAttention
- Jax 团队对 SplashAttention 的研究工作
- 菲利普·蒂莱特和周克仁帮助我们使用 Triton
- 阿里·哈萨尼就邻域注意力进行的讨论
- 每个人都在抱怨注意力核不支持他们最喜欢的注意力变体 :)