动机
最近,大型语言模型(如 ChatGPT 或 Llama)受到了前所未有的关注。然而,它们的运行成本仍然非常高。即使生成单个响应可能只需花费约 0.01 美元(在 AWS 上 8xA100 实例上运行几秒钟),当扩展到数十亿用户时,这些用户可能会每天与这些LLMs进行多次交互,成本会迅速增加。一些用例的成本更高,如代码自动补全,因为它在每次输入新字符时都会运行。随着LLM应用的增多,即使是生成时间的小幅效率提升也可能产生巨大影响。
LLM推理(或“解码”)是一个迭代过程:逐个生成标记。生成 N 个标记的完整句子需要模型进行 N 次正向传递。幸运的是,可以缓存先前计算出的标记:这意味着单个生成步骤不依赖于上下文长度,除了单个操作,即注意力。这个操作在上下文长度上扩展得不好。
LLMs 有许多重要的新兴用例,这些用例利用了长上下文。有了更长的上下文,LLMs 可以对较长的文档进行推理,无论是总结还是回答有关它们的问题,它们可以跟踪更长的对话,甚至可以在编写代码之前处理整个代码库。例如,2022 年(GPT-3)中,大多数LLMs的上下文长度为 2k 以内,但现在我们有开源的LLMs扩展到 32k(Llama-2-32k),最近甚至有 100k(CodeLlama)。在这种情况下,注意力在推理过程中占据了相当大的时间比例。
当在批处理大小维度上进行扩展时,即使上下文相对较小,注意力也可能成为瓶颈。这是因为读取内存的数量与批处理维度成比例,而其余模型只依赖于模型大小。
我们提出了一种技术,称为 Flash-Decoding,它在推理过程中显著加快了注意力的速度,对于非常长的序列,可以带来高达 8 倍的生成速度。主要思想是尽可能快地并行加载键和值,然后分别重新缩放和组合结果,以保持正确的注意力输出。
多头注意力机制在解码中的应用
在解码过程中,每个新生成的标记都需要关注所有之前的标记,以计算:
softmax(queries @ keys.transpose) @ values
该操作已在训练案例中使用 FlashAttention(最近有 v1 和 v2 版本)进行了优化,其中瓶颈是读取和写入中间结果的内存带宽(例如 Q @ K^T)。然而,这些优化并不直接适用于推理案例,因为瓶颈不同。对于训练,FlashAttention 在批大小和查询长度维度上并行化。在推理过程中,查询长度通常是 1:这意味着如果批大小小于 GPU 上的流多处理器(SMs)数量(例如 A100 的 108 个),则操作将仅使用 GPU 的一小部分!当使用长上下文时,这种情况尤其明显,因为它需要更小的批大小才能适应 GPU 内存。当批大小为 1 时,FlashAttention 将使用不到 1%的 GPU!

FlashAttention 仅在查询块和批量大小上并行化,解码时无法占用整个 GPU
注意力也可以使用矩阵乘法原语进行操作 - 而不是使用 FlashAttention。在这种情况下,操作会占用整个 GPU,但会启动许多内核来写入和读取中间结果,这并不理想。
解码更快的方法:Flash-Decoding
我们的新方法 Flash-Decoding 基于 FlashAttention,并添加了一个新的并行化维度:键/值序列长度。它结合了上述两种方法的优点。与 FlashAttention 一样,它存储的额外数据很少,但是只要上下文长度足够大,即使批量大小很小,也能充分利用 GPU。
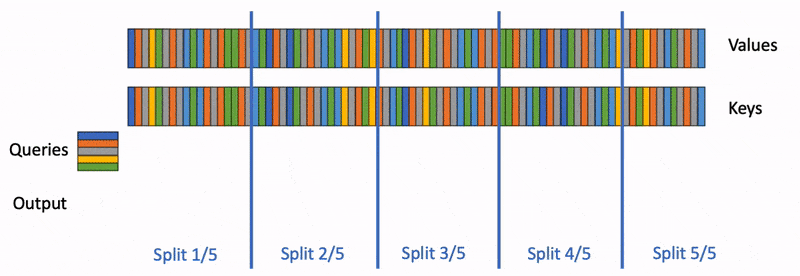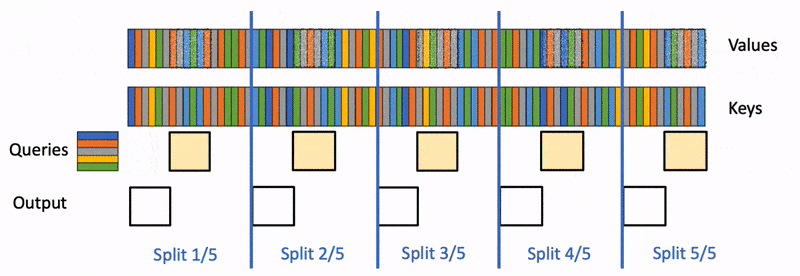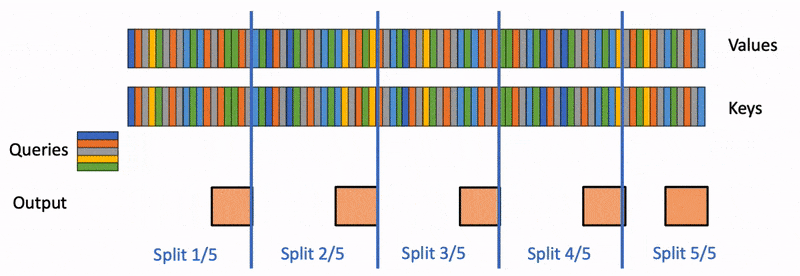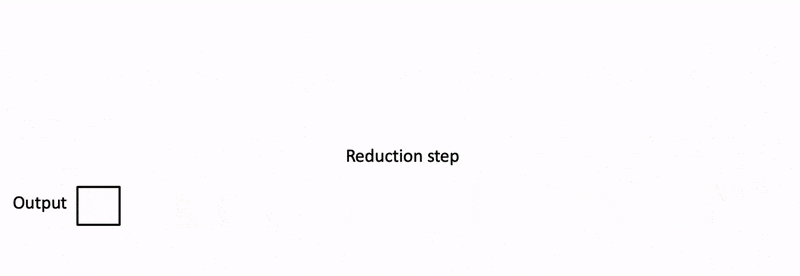
Flash-Decoding 也支持跨键和值并行化,但会牺牲一个小的最终减少步骤
Flash-Decoding 工作分为 3 个步骤:
- 首先,我们将键/值分割成更小的块。
- 我们使用 FlashAttention 并行计算每个分割的查询的注意力,并为每行和每个分割额外写入 1 个标量:注意力值的 log-sum-exp。
- 最后,我们通过对所有分割进行归约,使用 log-sum-exp 来调整每个分割的贡献,来计算实际输出。
所有这些之所以成为可能,是因为注意力/softmax 可以迭代计算。在 Flash-Decoding 中,它在两个层面上使用:在分割内(如 FlashAttention),以及在分割间执行最终归约。
在实践中,步骤(1)不涉及任何 GPU 操作,因为键/值块是完整键/值张量的视图。然后我们有 2 个独立的内核分别执行(2)和(3)。
在 CodeLlama 34B 上的基准测试
为了验证这种方法,我们对 CodeLLaMa-34b 的解码吞吐量进行了基准测试。该模型与 Llama 2 具有相同的架构,并且更普遍地,结果应该可以推广到许多LLMs。我们在各种序列长度下测量了解码速度,从 512 到 64k,并比较了计算注意力的多种方法:
- Pytorch:使用纯 PyTorch 原语运行注意力(不使用 FlashAttention)
- FlashAttention v2
- FasterTransformer:使用 FasterTransformer 注意力内核
- 闪解码
- 内存中读取整个模型及其 KV 缓存所需的时间计算出的上限
Flash-Decoding 解码速度在处理非常大的序列时可以提升至最高 8 倍,并且比其他方法具有更好的可扩展性。
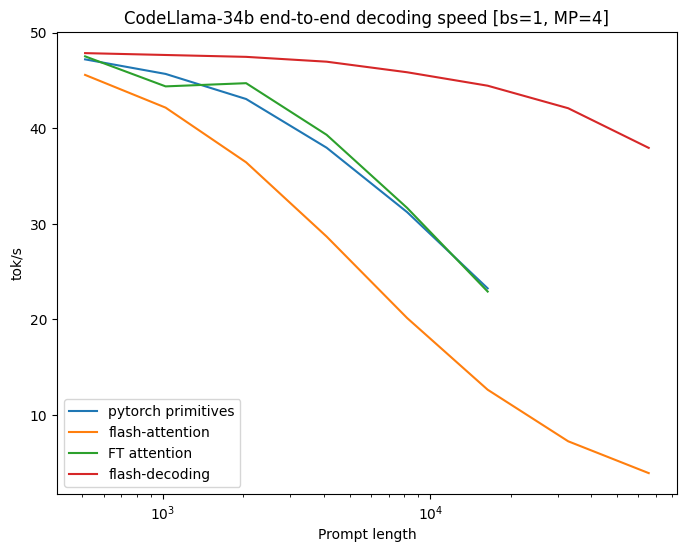
所有方法在小提示下表现相似,但随着序列长度从 512 增加到 64k,扩展性能较差,除了 Flash-Decoding。在此制度(批量大小为 1)下,使用 Flash-Decoding 扩展序列长度对生成速度影响很小
组件级微基准测试
我们还在 A100 上对各种序列长度和批处理大小进行了扩展的多头注意力微基准测试,输入为 f16。我们将批处理大小设置为 1,并使用 16 个维度为 128 的查询头,2 个键/值头(分组查询注意力),这与在 4 个 GPU 上运行 CodeLLaMa-34b 时使用的维度相匹配。
| 设置 \ 算法 | PyTorch 急切(us) | Flash-Attention v2.0.9(美) | Flash-解码(美) |
| B=256, seqlen=256 | 3058.6 | 390.5 | 63.4 |
| B=128, seqlen=512 | 3151.4 | 366.3 | 67.7 |
| B=64,序列长度=1024 | 3160.4 | 364.8 | 77.7 |
| B=32,序列长度=2048 | 3158.3 | 352 | 58.5 |
| B=16,序列长度=4096 | 3157 | 401.7 | 57 |
| B=8,序列长度=8192 | 3173.1 | 529.2 | 56.4 |
| B=4,序列长度=16384 | 3223 | 582.7 | 58.2 |
| B=2,序列长度=32768 | 3224.1 | 1156.1 | 60.3 |
| B=1,序列长度=65536 | 1335.6 | 2300.6 | 64.4 |
| B=1,序列长度=131072 | 2664 | 4592.2 | 106.6 |
多头注意力机制的微基准测试,运行时间(微秒)。当序列长度扩展到 64k 时,Flash-Decoding 的运行时间几乎保持恒定。
之前测量的 8 倍速度提升得以实现,是因为注意力本身比 FlashAttention 快 50 倍。在序列长度达到 32k 之前,注意力时间大致保持恒定,因为 Flash-Decoding 能够充分利用 GPU。
使用 Flash-Decoding
Flash-decoding 可用:
- 在 FlashAttention 包中,从版本 2.2 开始
- 从版本 0.0.22 的 xFormers 开始,通过`xformers.ops.memory_efficient_attention`。调度器将根据问题大小自动使用 Flash-Decoding 或 FlashAttention 方法。当这些方法不受支持时,它可以调度到实现 Flash-Decoding 算法的高效 triton 内核。
在 FlashAttention 仓库和 xFormers 仓库中都可以找到使用 LLaMa v2 / CodeLLaMa 进行解码的完整示例。我们还提供了一个 LLaMa v1/v2 模型的快速、易于阅读、教育性和可修改的解码代码的最小示例。
致谢
感谢 Erich Elsen、Ashish Vaswani 和 Michaël Benesty 提出将 KVcache 加载拆分这一想法。我们还要感谢 Jeremy Reizenstein、Patrick Labatut 和 Andrew Tulloch 的宝贵讨论,以及 Quentin Carbonneaux 为 xFormers 贡献了高效的解码示例。我们还要感谢 Geeta Chauhan 和 Gregory Chanan 在撰写和更广泛地帮助将这篇文章发布在 PyTorch 博客上的贡献。