Flashlight Text(Flashlight ML 框架的一部分)的快速光束搜索解码现在在 TorchAudio 中提供官方支持,为基于 PyTorch 的语音和文本应用带来了高性能的光束搜索和文本工具。当前集成支持 CTC 风格解码,但可用于任何输出时间步长上概率分布的标记级建模设置。
光束搜索快速回顾
在语音和语言设置中,光束搜索是一种高效的贪婪算法,可以将连续值序列(即概率或分数)转换为图或序列(即标记、词片段、单词),使用可选的有效序列约束(即词汇表)、可选的外部评分(即一个对有效序列进行评分的 LM)和其他特定序列的评分调整。
在下面的例子中,我们将考虑一个标记集 {ϵ, a, b},其中 ϵ 是一个特殊标记,我们可以想象它表示单词之间的空格或语音中的停顿。此处及以下图形均来自 Awni Hannun 在 distill.pub 上关于 CTC 和 beam search 的优秀文章。
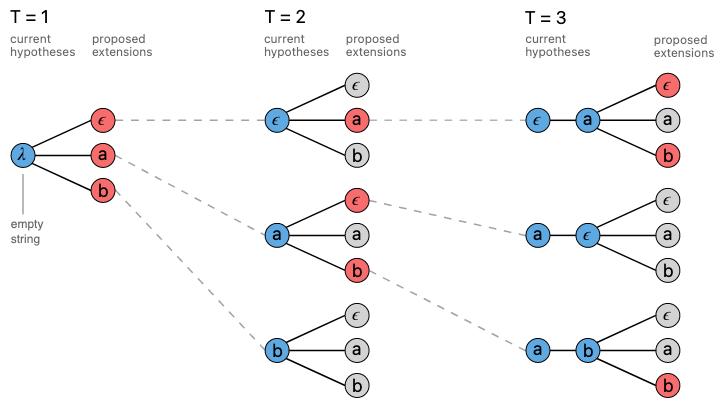
类似于贪婪算法的方法,beam search 考虑给定现有标记序列的下一个可行标记——在上面的例子中,a, b, b 是一个有效序列,但 a, b, a 则不是。在 beam search 的每一步,我们都会根据评分函数对每个可能的下一个标记进行排名。评分函数(s)通常看起来像这样:
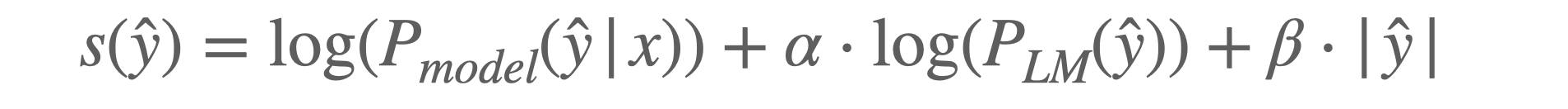
其中 ŷ 是一个潜在的标记路径/序列,x 是输入(P(ŷ|x) 表示模型随时间的变化预测),而 𝛼 是语言模型概率(P(y) 表示序列在语言模型下的概率)的权重。一些评分函数还会添加 𝜷,它根据预测序列的长度 |ŷ| 调整分数。这个特定的评分函数用于 FAIR 在端到端 ASR 上的先前工作,并且评分函数有很多变体,这些变体可能因应用领域而异。
给定一个特定序列,为了评估该序列中的下一个可行标记(可能受一组允许的单词或序列的限制,例如单词词典),束搜索算法会为每个添加的候选标记对序列进行评分,并根据这些评分对标记候选进行排序。由于路径数量与标记集大小呈指数关系,因此只保留前 k 个最高评分的候选——k 代表束大小。
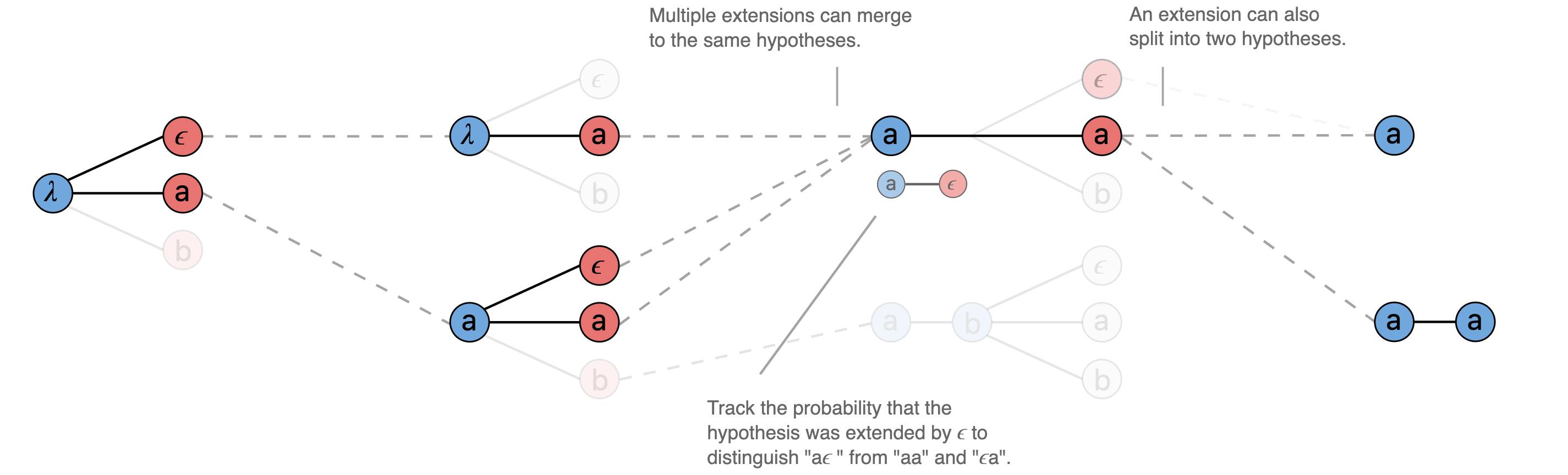
束搜索的进展有许多其他细微之处:例如,类似假设序列可以被“合并”。
评分函数可以进一步扩展,以增加/减少标记插入或长或短单词的权重。使用更强的外部语言模型进行评分,虽然会增加计算成本,但可以显著提高性能;这通常被称为 LM 融合。还有许多其他可调解码旋钮——这些在 TorchAudio 的文档中有记录,并在 TorchAudio 的 ASR 推理教程中进行了进一步探讨。由于解码效率很高,因此可以轻松地调整和微调参数。
这些年来,在 ASR 领域,束搜索被广泛用于众多无法一一列举的工作中,包括 wav2vec 2.0 和 NVIDIA 的 NeMo 等近期强有力结果和系统。
为什么使用束搜索?
束搜索仍然是与 RNN-Transducer 等更重的解码方法(如谷歌投资部署在设备上并已在常见基准测试中显示出强大结果的 RNN-Transducer)的快速竞争者。在规模上的自回归文本模型也可以从束搜索中受益。束搜索可以提供以下好处:
- 灵活的性能/延迟权衡——通过调整束大小和外部 LM,用户可以牺牲延迟以换取准确性,或者以很小的延迟成本支付更准确的结果。在没有外部 LM 的情况下解码可以在几乎不牺牲性能的情况下提高结果。
- 无需重新训练的可移植性——现有的神经模型可以从多个解码设置中受益,并且可以与外部 LM 进行即插即用,无需训练或微调。
- 吸引人的复杂度/准确性权衡——将束搜索添加到现有的建模流程中,增加的复杂性很小,可以提高性能。
性能基准
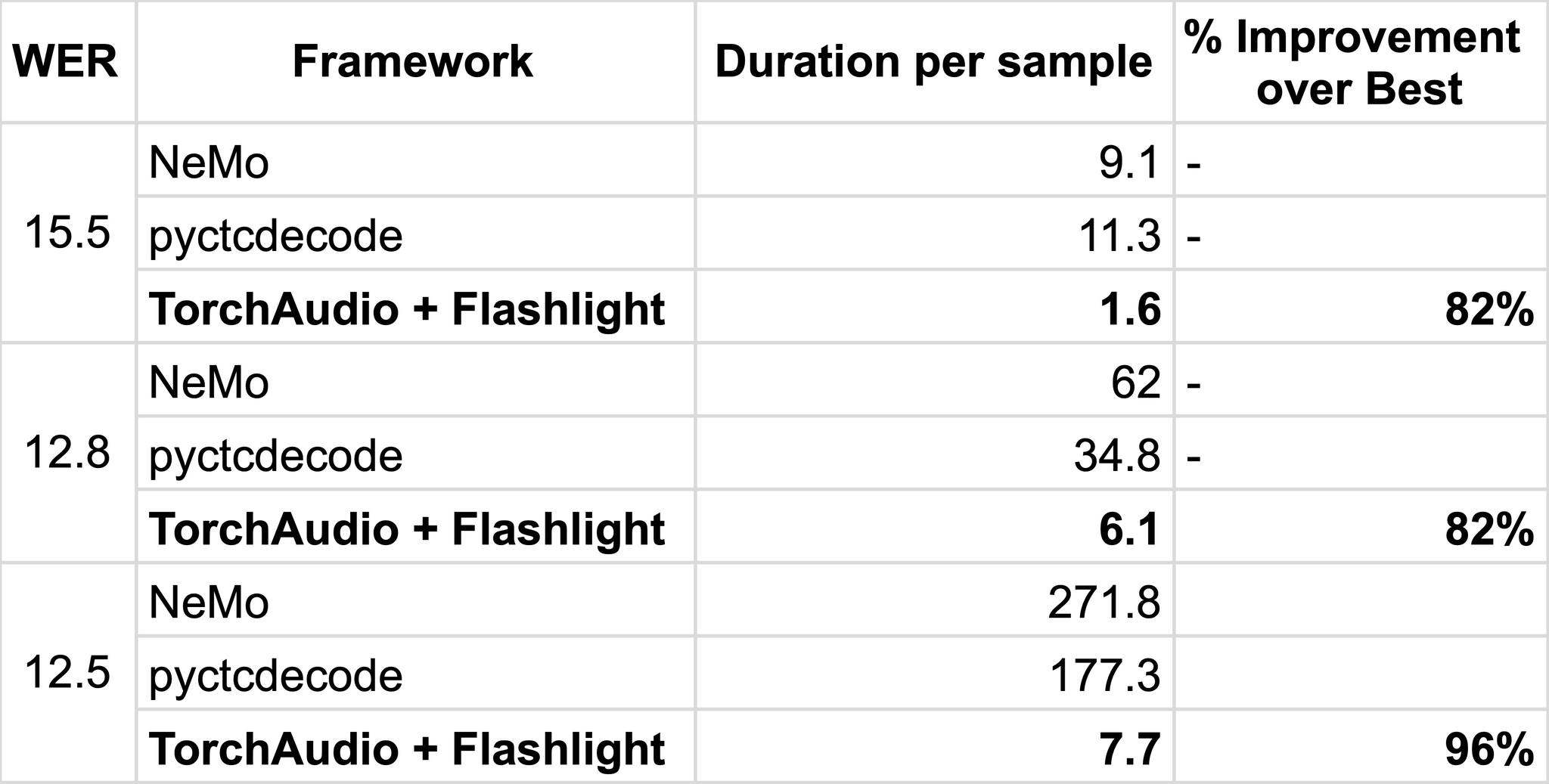
目前最常用的支持外部语言模型集成的束搜索解码库包括 Kensho 的 pyctcdecode、NVIDIA 的 NeMo 工具包。我们使用在 100 小时音频上训练的 wav2vec 2.0 基础模型,与它们进行了基准测试,该模型在 LibriSpeech dev-other 上进行评估,使用了官方的 KenLM 3-gram LM。基准测试在 Intel E5-2698 CPU 的单线程上运行。所有计算都在内存中进行——禁用了 KenLM 内存映射,因为它没有得到广泛支持。
在基准测试中,我们测量时间到 WER(词错误率)——由于解码算法实现的细微差异以及参数与解码速度之间的复杂关系,一些超参数在运行中有所不同。为了公平地评估性能,我们首先对达到基线 WER 的参数进行扫描,尽可能最小化搜索宽度。
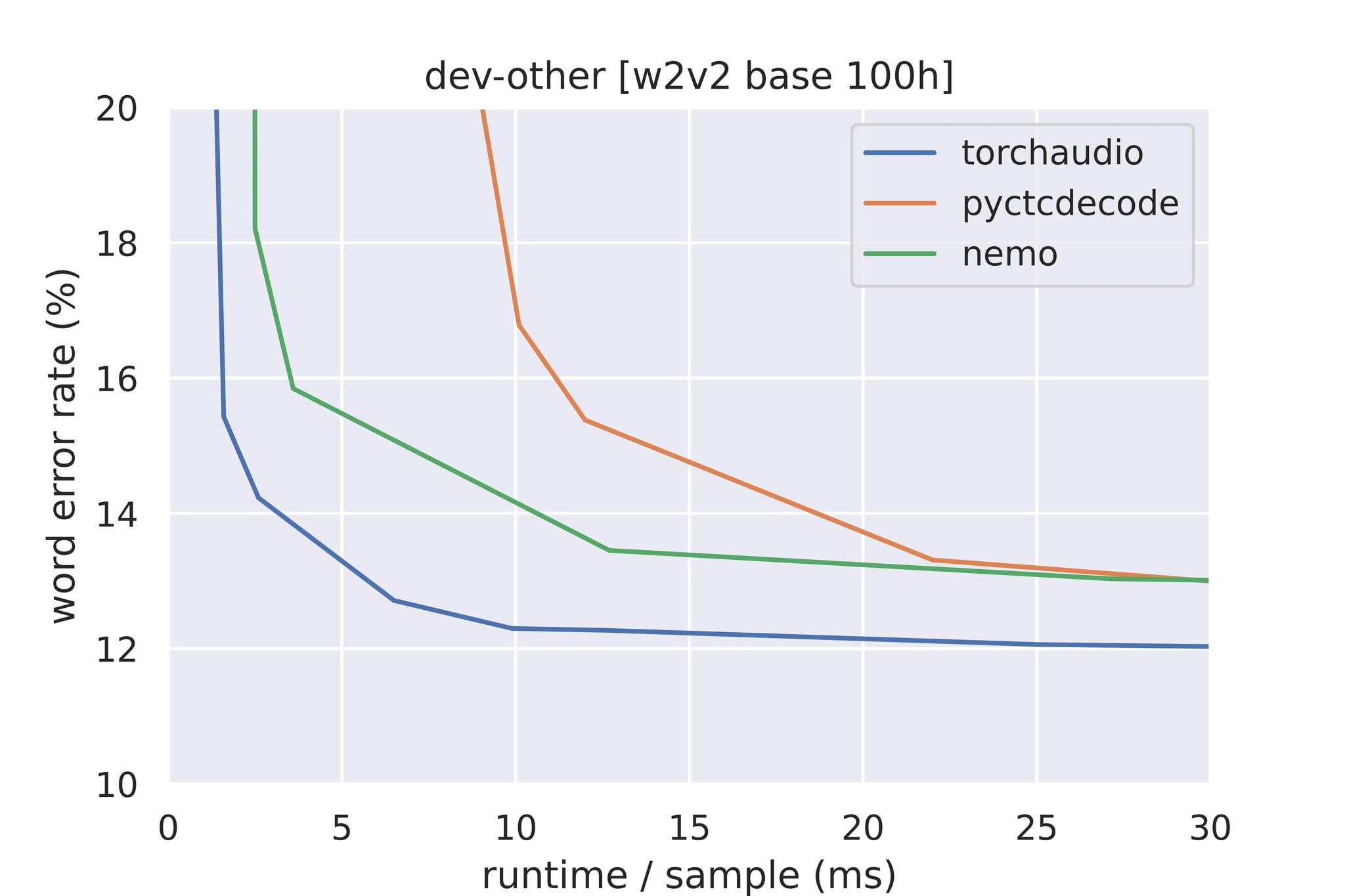
预训练的 wav2vec 2.0 模型在 Librispeech dev-other 上的解码性能。在低 WER 下,TorchAudio + Flashlight 解码器比其他方法高出一个数量级。
在不同解码器中,根据时间到 WER 结果,推迟到更小的搜索宽度。TorchAudio + Flashlight 解码器在大搜索宽度和低 WER 下具有更好的扩展性。
TorchAudio API 和用法
TorchAudio 提供 Python API 进行 CTC 束搜索解码,支持以下功能:
- 词典和词典自由解码
- KenLM n-gram 语言模型集成
- 字符和词元解码
- 样本预训练的 LibriSpeech KenLM 模型及其对应的词典和标记文件
- 可自定义的各种束搜索参数(束大小、剪枝阈值、LM 权重等)
设置解码器时,请使用 torchaudio.models.decoder.ctc_decoder 的工厂函数
from torchaudio.models.decoder import ctc_decoder, download_pretrained_files
files = download_pretrained_files("librispeech-4-gram")
decoder = ctc_decoder(
lexicon=files.lexicon,
tokens=files.tokens,
lm=files.lm,
nbest=1,
... additional optional customizable args ...
)
给定形状为(batch,time,num_tokens)的发射,解码器将计算并返回一个包含 batch 个列表的列表,每个列表包含对应发射的 nbest 假设。每个假设可以进一步分解为标记、单词(如果提供词典)、得分和时步组件。
emissions = acoustic_model(waveforms) # (B, T, N)
batch_hypotheses = decoder(emissions) # List[List[CTCHypothesis]]
# transcript for a lexicon decoder
transcripts = [" ".join(hypo[0].words) for hypo in batch_hypotheses]
# transcript for a lexicon free decoder, splitting by sil token
batch_tokens = [decoder.idxs_to_tokens(hypo[0].tokens) for hypo in batch_hypotheses]
transcripts = ["".join(tokens) for tokens in batch_tokens]
请参阅文档以获取更多 API 详细信息,以及教程(ASR 推理解码)或示例推理脚本以获取更多使用示例。
即将推出的改进
完整 NNLM 支持——在规模上,使用大型神经语言模型(例如 transformers)进行解码仍相对未充分探索。Flashlight 已支持,我们计划在 TorchAudio 中添加支持,使用户能够使用兼容自定义解码器的 LM。自定义词级语言模型已在 TorchAudio 夜间构建中提供,并计划在 TorchAudio 0.13 版本中发布。
自回归/seq2seq 解码——Flashlight Text 还支持自回归模型的序列到序列(seq2seq)解码,我们希望为其添加绑定,并将其与高效的 GPU 实现一起添加到 TorchAudio 和 TorchText 中。
更好的构建支持 — 为了从 Flashlight Text 的改进中受益,TorchAudio 将直接将 Flashlight Text 作为子模块,以便更容易地进行上游修改和改进。这已在夜间 TorchAudio 构建中生效,并计划在 TorchAudio 0.13 版本中发布。
引用
引用解码器时,请使用以下格式:
@inproceedings{kahn2022flashlight,
title={Flashlight: Enabling innovation in tools for machine learning},
author={Kahn, Jacob D and Pratap, Vineel and Likhomanenko, Tatiana and Xu, Qiantong and Hannun, Awni and Cai, Jeff and Tomasello, Paden and Lee, Ann and Grave, Edouard and Avidov, Gilad and others},
booktitle={International Conference on Machine Learning},
pages={10557--10574},
year={2022},
organization={PMLR}
}
@inproceedings{yang2022torchaudio,
title={Torchaudio: Building blocks for audio and speech processing},
author={Yang, Yao-Yuan and Hira, Moto and Ni, Zhaoheng and Astafurov, Artyom and Chen, Caroline and Puhrsch, Christian and Pollack, David and Genzel, Dmitriy and Greenberg, Donny and Yang, Edward Z and others},
booktitle={ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={6982--6986},
year={2022},
organization={IEEE}
}