引言
PyTorch 2.0(PT2)提供了一种编译执行模式,该模式将 Python 字节码重写为 PyTorch 操作序列,将其转换为 Graph IR。然后,通过可定制的后端即时编译 IR,在不干扰用户的情况下提高训练性能。通常,生产模型可能需要经过多个优化/降低性能的阶段才能达到性能目标。因此,拥有编译模式是可取的,因为它可以将提高模型性能的工作与直接修改 PyTorch 模型实现的工作分开。因此,编译模式变得更加重要,使 Pytorch 用户能够在不修改 PyTorch 代码实现的情况下增强模型性能。这一特性对于优化复杂模型,包括大规模和现成生产模型尤其有价值。
在我们之前的博客文章中,我们概述了如何使用启发式模型转换规则来优化复杂的生产模型。虽然这些规则为一些试点模型带来了显著的性能提升,但它们缺乏普遍的适应性;它们并不能在不同模型或有时甚至在单个模型的各个部分中持续表现良好。
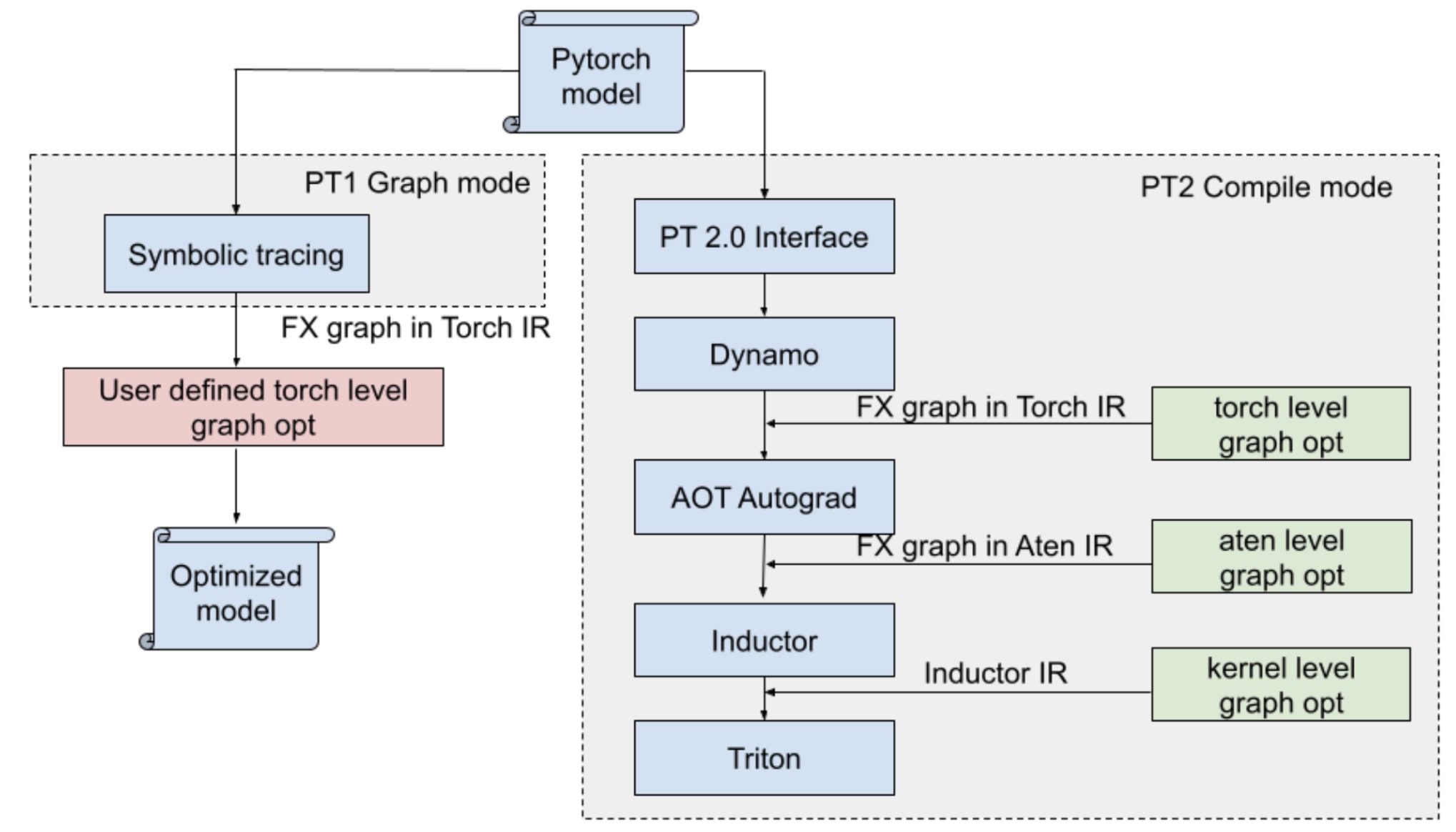
图 1:PT1 图形模式与 PT2 编译模式。
在本文中,我们提出了一种更通用的模型转换解决方案,作为 PT2 编译器的插件,如图 1 所示,它更通用、性能更优、用户友好,无需人工努力即可提升模型训练和推理的性能。如图 2 所示,通过将之前用户定义的转换集成到编译器中,我们简化了生产栈。这些变化为更广泛的 PyTorch 模型带来了优势,不仅限于 Meta 模型,这些模型已经集成到 PT2 中,并准备好为所有 PyTorch 模型带来益处。
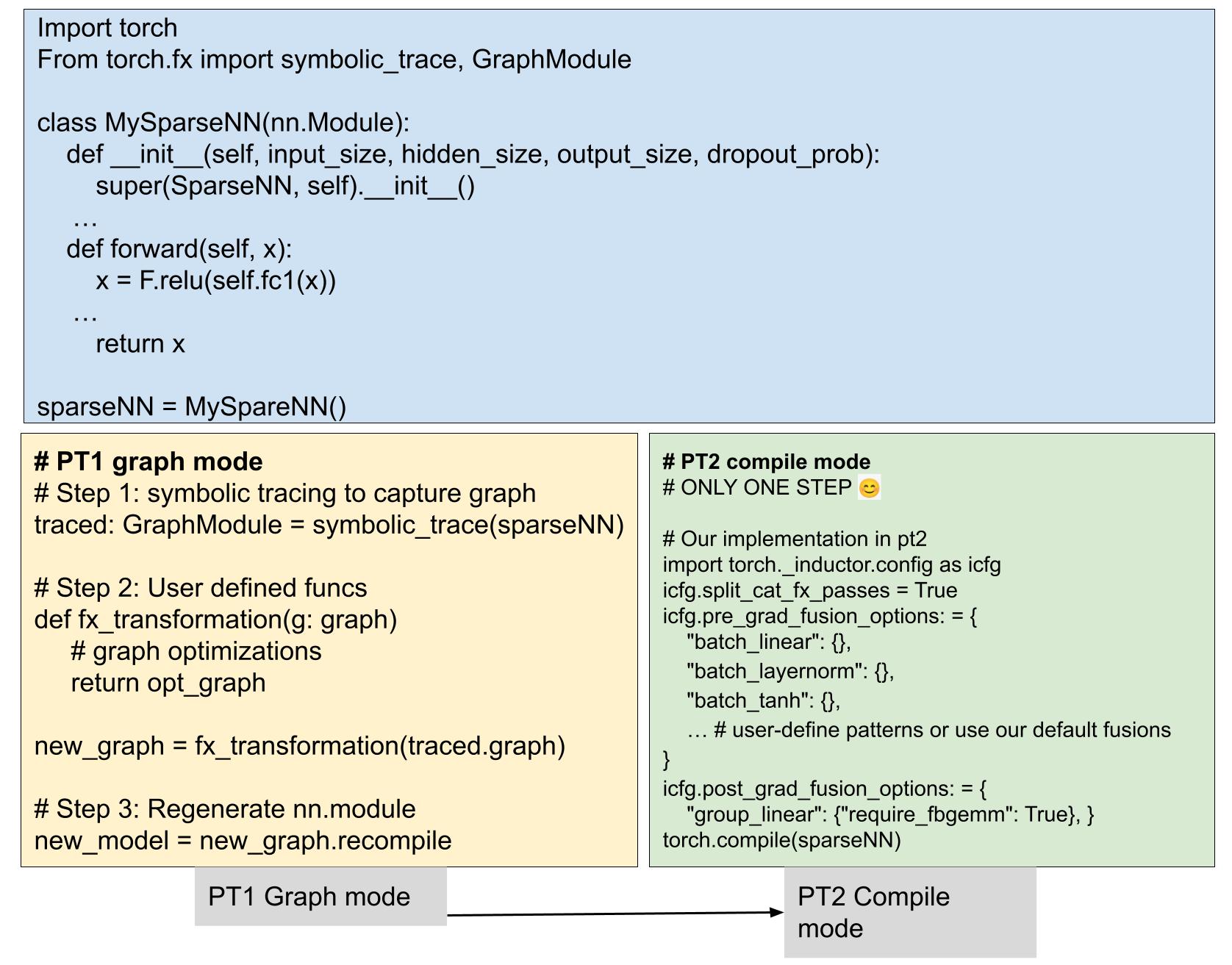
图 2:PT2 编译模式的简化栈。
指导原则:原子规则
传统上,人们可能会使用预定义的启发式规则来替换模型子图,以获得更高效的子图,从而减少启动开销、最小化内存带宽并充分利用 SMs。然而,这种方法扩展性不好,因为很难制定一套适合所有模型的规则。
与之相反,我们可以将这些庞大的、复杂的规则分解成更小、更易于消化的部分——我们称之为“原子规则”。这些效率极高的微型规则针对单个操作符的转换,执行融合/转换的一步。这使得它们易于处理和应用,为优化模型提供了一条简单的路径。因此,有了这些原子规则,优化任何模型以实现顶级性能变得轻而易举!
我们将通过一些简单的示例来演示我们如何使用一系列原子规则来替换复杂的启发式规则。
案例一:以嵌入表访问开始的计算链水平融合
水平融合意味着将并行算子融合成一个,以减少需要启动的内核数量并提高性能。在我们之前的博客(第 3.2 节)中,我们描述了在嵌入包之后融合 layernorm 和激活函数的模型转换,如图所示。然而,这种方法存在局限性:
- 它仅适用于嵌入之后的 layernorm 和激活函数。
- 它受限于具有特定架构规则的模型,导致我们的生产堆栈中出现各种问题,包括参数更改和推理中断。
为了改进,我们可以使用图 3 中所示的三条原子规则来替换复杂的启发式规则:
- 横向融合具有相同分割节点的 layernorms。
- 然后,横向融合具有相同分割节点的 tanh 函数。
- 最后,融合垂直分割-cat 节点。
这些原子规则为模型简化和优化提供了一种干净、简洁的方法。
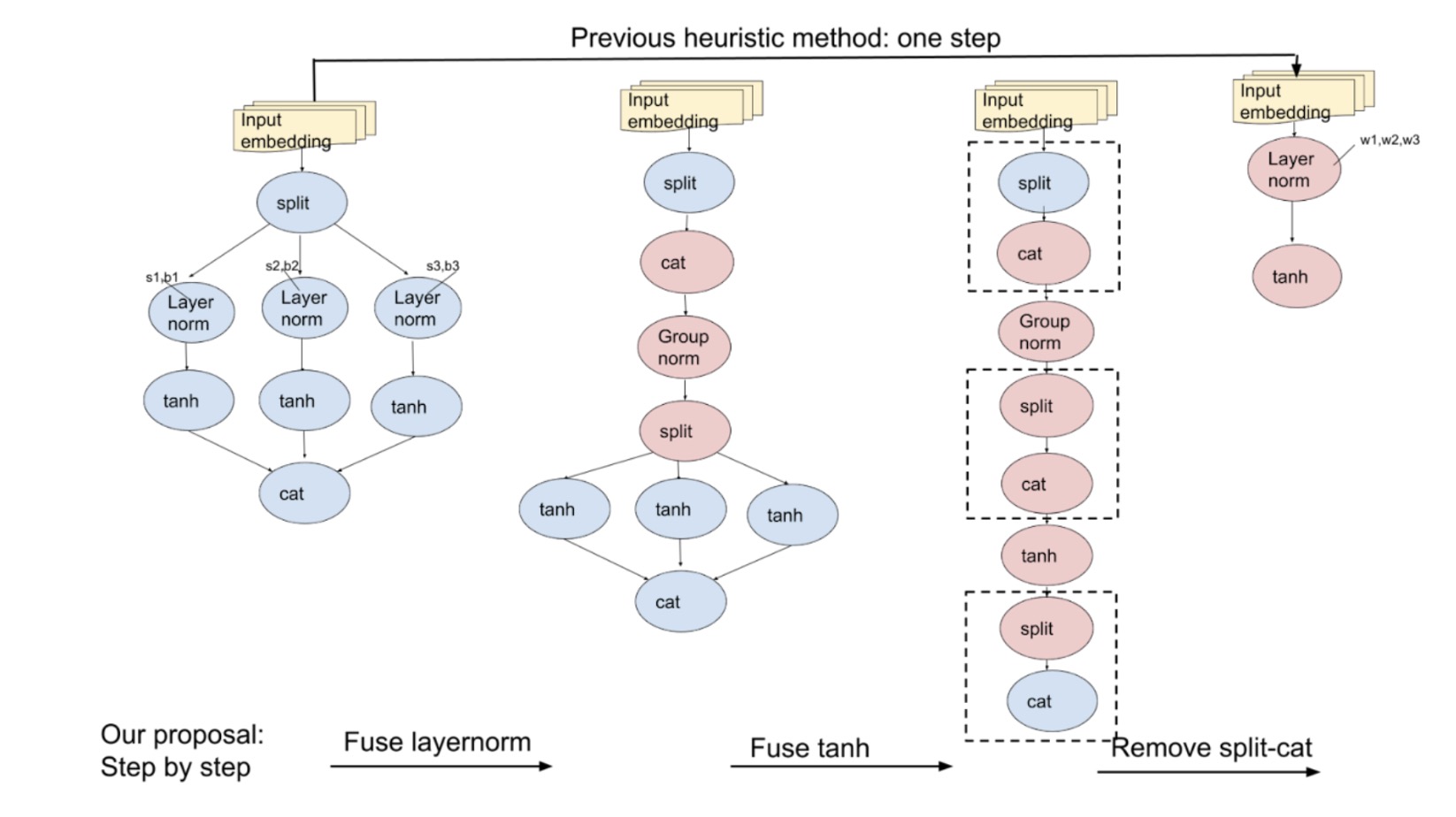
图 3:以前,我们一次性通过替换子图来优化模型。现在,使用原子规则,我们逐步优化,覆盖更多情况。
情况 2:融合水平 MLP
MLPs(多层感知器)是深度神经网络的基本组成部分,通常由线性、归一化和激活函数组成。在复杂模型中,通常需要融合许多水平 MLP。传统方法通过将并行 MLP 替换为融合模块来找到和替换,如图 4 所示,但这并不总是直接的。一些模型可能没有归一化,或者它们可能使用不同的激活函数,这使得应用一刀切规则变得困难。
这就是我们的原子规则派上用场的地方。这些简化的规则一次针对一个操作符,使过程更容易、更易于管理。我们使用以下原子规则进行水平 MLP 融合:
- 融合水平线性算子
- 融合水平层归一化
- 融合水平激活函数
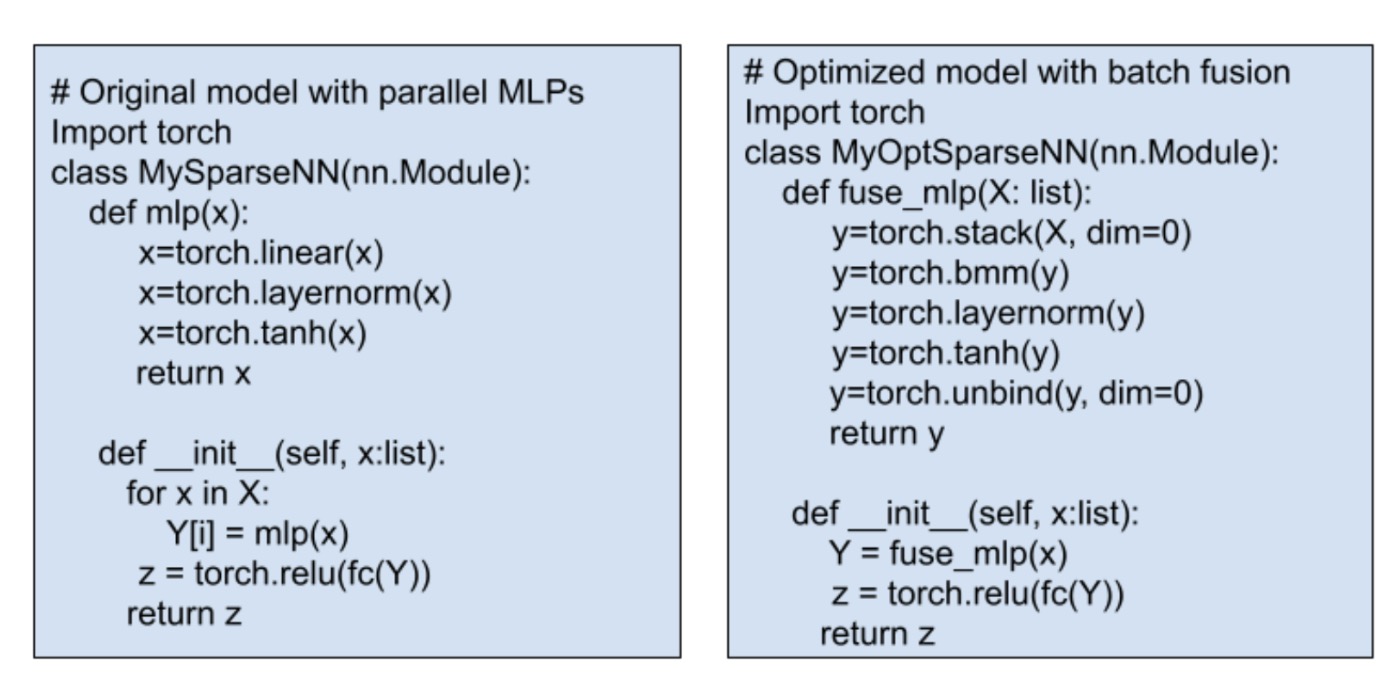
图 4:融合 MLP 的伪代码。传统的优化需要手动修改 Python 代码。
这些规则之美在于它们不仅限于一种情况。它们可以广泛地应用。由于 PyTorch 模型是用 torch 运算符构建的,关注更小的运算符集合可以简化过程。这种方法不仅更易于管理,而且与编写特定的大模式替换规则相比更具通用性,使得优化各种模型更加高效。
编译时图搜索
我们的原则是使用链式原子规则来替换启发式规则。虽然这种方法覆盖了更广泛的案例,但它确实需要更长时间进行图搜索和模式匹配。下一个问题是:如何在执行编译时图搜索的同时最小化编译时间?
我们设计了一个如图 5 所示的两步贪婪算法。这个过程的第一步是识别目标节点,我们遵循某些规则,例如识别所有具有相同输入形状的线性操作。一旦识别出来,我们使用广度优先搜索(BFS)策略将这些节点分离到不同的集合中,使得集合内的节点没有数据依赖。这些集合内的节点是独立的,可以水平融合。
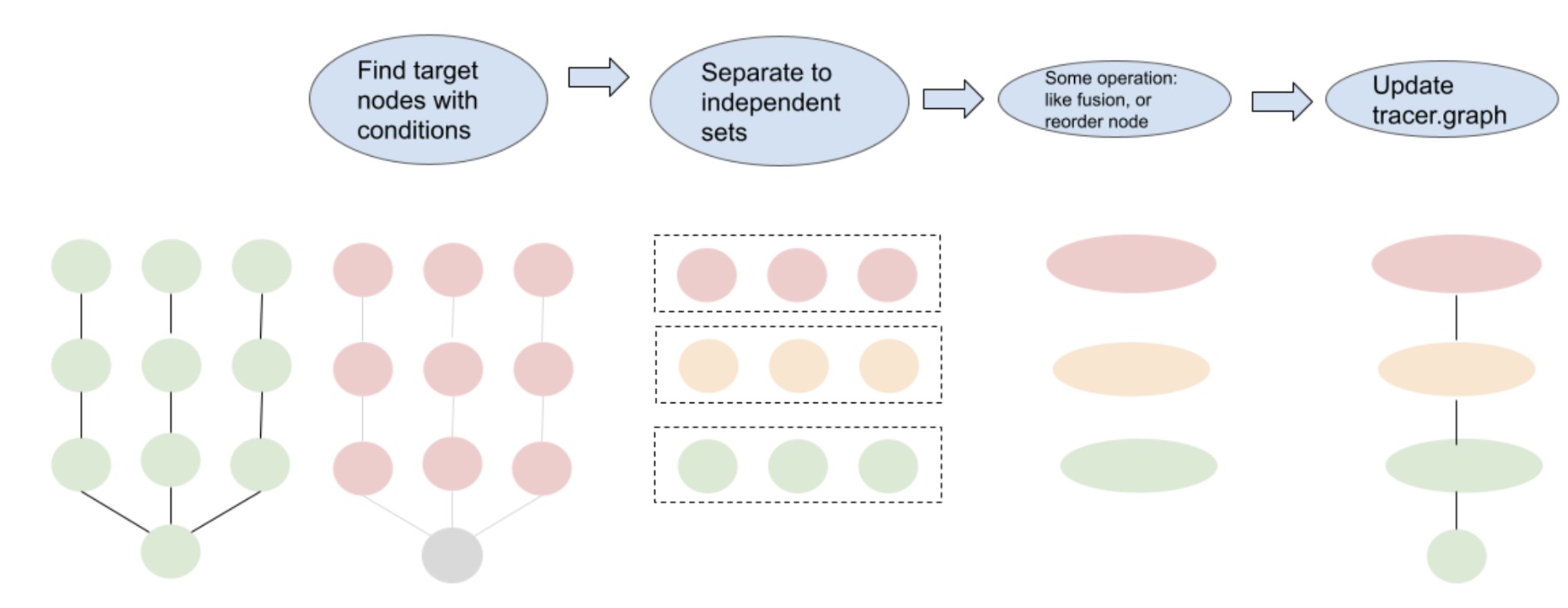
图 5:使用图 IR 的模型转换过程。
使用我们的方法,对于我们的最大内部模型之一,搜索时间大约为 60 秒,这对于即时任务来说是可管理的。
最后
在我们与内部排名模型的测试中,我们观察到在 torch.compile 带来的性能提升基础上,五个模型训练性能提高了大约 5%到 15%。我们已经将优化功能集成到 PT2 编译器堆栈中,并在用户选择 Inductor 作为后端(配置)时将其设置为默认。我们期望我们的通用转换方法能够惠及 Meta 以外的模型,并期待通过这个编译器级别的转换框架进行更多讨论和改进。
致谢
感谢 Mark Saroufim、Gregory Chanan、Adnan Aziz 和 Rocky Liu 对他们的详细和有见地的审阅。