vLLM 引擎目前是执行大型语言模型(LLM)的最高性能方式之一。它提供了 vllm serve 命令,作为在单机上部署模型的一个简单选项。虽然这很方便,但在生产环境和规模化的情况下,一些高级功能是必要的。
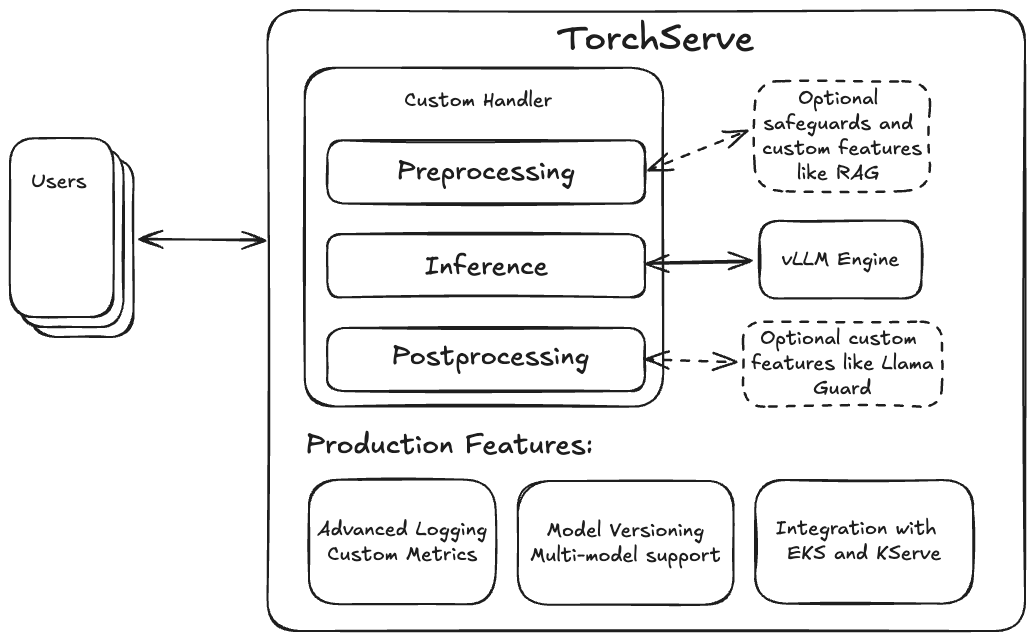
TorchServe 提供了这些必要的生产功能(如自定义指标和模型版本控制),并通过其灵活的自定义处理程序设计,使得集成检索增强生成(RAG)或像 Llama Guard 这样的保护措施变得非常容易。因此,将 vLLM 引擎与 TorchServe 配对,以创建一个完整的生产级 LLM 服务解决方案是自然而然的。
在深入集成细节之前,我们将演示使用 TorchServe 的 vLLM docker 图像部署 Llama-3.1-70B-Instruct 模型。
快速开始使用 Llama 3.1 在 TorchServe + vLLM 上
要开始,我们需要构建新的 TS LLM Docker 容器镜像,通过检出 TorchServe 仓库,并在主目录下执行以下命令:
docker build --pull . -f docker/Dockerfile.vllm -t ts/vllm
容器使用我们新的LLM 启动脚本 ts.llm_launcher ,它接受一个 Hugging Face 模型 URI 或本地文件夹,并启动一个带有 vLLM 引擎在后台运行的本地 TorchServe 实例。要本地提供模型,可以使用以下命令创建容器实例:
#export token=<HUGGINGFACE_HUB_TOKEN>
docker run --rm -ti --shm-size 10g --gpus all -e HUGGING_FACE_HUB_TOKEN=$token -p
8080:8080 -v data:/data ts/vllm --model_id meta-llama/Meta-Llama-3.1-70B-Instruct --disable_token_auth
您可以使用以下 curl 命令测试本地端点:
curl -X POST -d '{"model":"meta-llama/Meta-Llama-3.1-70B-Instruct", "prompt":"Hello, my name is", "max_tokens": 200}' --header "Content-Type: application/json" "http://localhost:8080/predictions/model/1.0/v1/completions"
Docker 将模型权重存储在本地文件夹“data”中,该文件夹在容器内挂载为/data。要使用您自定义的本地权重,只需将它们复制到 data 文件夹中,并将 model_id 指向/data/您的权重。
容器内部使用我们新的 ts.llm_launcher 脚本来启动 TorchServe 并部署模型。启动器将 TorchServe 部署LLM简化为单条命令行,并且也可以作为容器外高效的实验和测试工具使用。要在 Docker 外使用启动器,请按照 TorchServe 安装步骤进行操作,然后执行以下命令以启动一个 8B Llama 模型:
# after installing TorchServe and vLLM run
python -m ts.llm_launcher --model_id meta-llama/Meta-Llama-3.1-8B-Instruct --disable_token_auth
如果有多个 GPU 可用,启动器将自动声明所有可见设备并应用张量并行(请参阅 CUDA_VISIBLE_DEVICES 以指定要使用的 GPU)。
虽然这非常方便,但需要注意的是,它并不包含 TorchServe 提供的所有功能。对于那些想要利用更高级功能的人来说,需要创建一个模型存档。虽然这个过程比执行单个命令要复杂一些,但它具有自定义处理程序和版本管理的优势。前者允许在预处理步骤中实现 RAG,后者则让你在更大规模部署之前测试不同版本的处理程序和模型。
在我们提供创建和部署模型存档的详细步骤之前,让我们深入了解 vLLM 引擎的集成细节。
TorchServe 的 vLLM 引擎集成
作为一款最先进的托管框架,vLLM 提供了丰富的先进功能,包括 PagedAttention、连续批处理、通过 CUDA 图快速执行模型以及支持各种量化方法,如 GPTQ、AWQ、INT4、INT8 和 FP8。它还提供了对 LoRA 等重要参数高效适配方法的集成,以及访问包括 Llama 和 Mistral 在内的广泛模型架构。vLLM 由 vLLM 团队和蓬勃发展的开源社区维护。
为了方便快速部署,它提供了一种基于 FastAPI 的托管模式,通过 HTTP 提供 LLMs 服务。为了更紧密、更灵活的集成,该项目还提供了 vllm.LLMEngine,该引擎提供了连续处理请求的接口。我们利用了异步变体将其集成到 TorchServe 中。
TorchServe 是一个易于使用的开源解决方案,用于在生产环境中托管 PyTorch 模型。作为一个经过生产测试的托管解决方案,TorchServe 提供了众多有益于大规模部署 PyTorch 模型的功能和优势。通过结合 vLLM 引擎的推理性能,这些优势现在也可以用于大规模部署 LLMs。
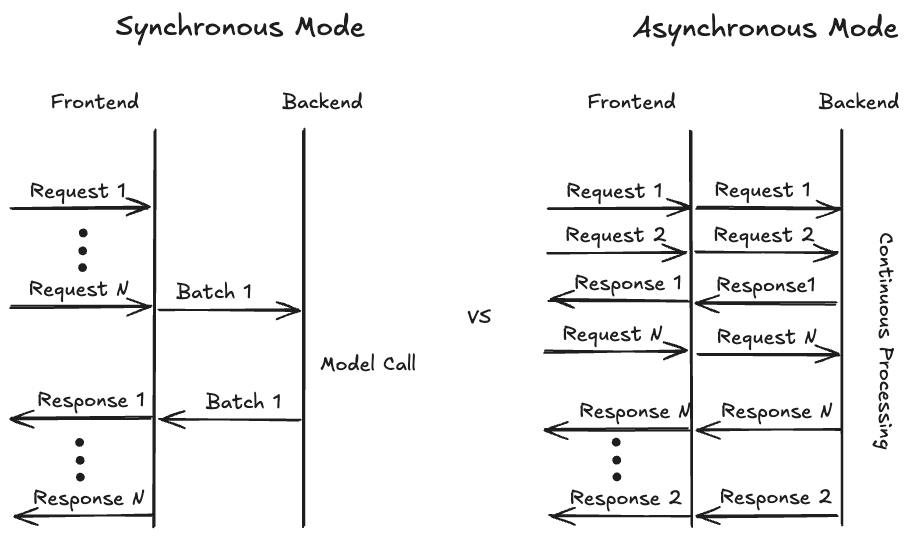
为了最大化硬件利用率,通常将来自多个用户的请求一起批量处理是一个好习惯。历史上,TorchServe 仅提供同步模式来收集来自不同用户的请求。在这种模式下,TorchServe 会等待预定义的时间(例如,batch_delay=200ms)或直到足够多的请求(例如,batch_size=8)到达。当触发这些事件之一时,批量数据被转发到后端,模型在批量上应用,并通过前端将模型输出返回给用户。这对于传统视觉模型特别有效,因为每个请求的输出通常同时完成。
对于生成用例,尤其是文本生成,假设请求同时准备就绪不再成立,因为响应长度会有所不同。尽管 TorchServe 支持连续批处理(动态添加和删除请求的能力),但这种模式仅能容纳静态的最大批处理大小。随着分页注意力(PagedAttention)的引入,甚至最大批处理大小的这一假设也变得更加灵活,因为 vLLM 可以以高度适应的方式组合不同长度的请求,以优化内存利用率。
要实现最优内存利用率,即填充内存中的空闲空间(想想俄罗斯方块),vLLM 需要完全控制在任何给定时间处理哪些请求的决定。为了提供这种灵活性,我们必须重新评估 TorchServe 处理用户请求的方式。我们不再使用之前的同步处理模式,而是引入了异步模式(见下方的图示),其中传入的请求将直接转发到后端,使其对 vLLM 可用。后端将数据喂给 vllm.AsyncEngine,现在可以从所有可用的请求中进行选择。如果启用了流模式,并且请求的第一个标记可用,后端将立即发送结果,并继续发送标记,直到生成最后一个标记。
我们实现的 VLLMHandler 允许用户通过配置文件快速部署任何与 vLLM 兼容的模型,同时仍然通过自定义处理程序提供相同级别的灵活性和可定制性。用户可以自由添加例如自定义预处理或后处理步骤,通过继承 VLLMHandler 并重写相应的类方法。
我们还支持单节点、多 GPU 分布式推理,其中我们配置 vLLM 使用模型张量并行划分以增加较小模型的容量或启用无法适应单个 GPU 的较大模型,例如 70B 的 Llama 变体。之前,TorchServe 仅支持使用 torchrun 进行分布式推理,其中会启动多个后端工作进程来划分模型。vLLM 内部管理这些进程的创建,因此我们在 TorchServe 中引入了新的“自定义”parallelType,它启动单个后端工作进程并提供分配的 GPU 列表。后端进程可以在此基础上启动自己的子进程。
为方便将 TorchServe + vLLM 集成到基于 Docker 的部署中,我们提供了一个基于 TorchServe GPU Docker 镜像的单独 Dockerfile,并将 vLLM 作为依赖项添加。我们选择将其保持独立,以避免增加非LLM部署的 Docker 镜像大小。
接下来,我们将演示在具有四个 GPU 的机器上使用 TorchServe + vLLM 部署 Llama 3.1 70B 模型的步骤。
步骤指南
对于本篇逐步指南,我们假设 TorchServe 的安装已成功完成。目前,vLLM 不是 TorchServe 的硬依赖,因此让我们使用 pip 安装该软件包:
$ pip install -U vllm==0.6.1.post2
在以下步骤中,我们将(可选)下载模型权重,解释配置,创建模型存档,部署并测试它:
1. (可选)下载模型权重
此步骤是可选的,因为 vLLM 也可以在模型服务器启动时处理权重的下载。然而,预先下载模型权重并在 TorchServe 实例之间共享缓存文件可以在存储使用和模型工作者的启动时间方面带来好处。如果您选择下载权重,请使用 huggingface-cli 并执行:
# make sure you have logged into huggingface with huggingface-cli login before
# and have your access request for the Llama 3.1 model weights approved
huggingface-cli download meta-llama/Meta-Llama-3.1-70B-Instruct --exclude original/*
这将下载$HF_HOME 下的文件,如果您想将文件放在其他位置,可以更改该变量。请确保在运行 TorchServe 时更新该变量,并确保它有访问该文件夹的权限。
2. 配置模型
接下来,我们创建一个包含模型部署所需所有参数的 YAML 配置文件。配置文件的第一部分指定了前端如何启动后端工作进程,该工作进程最终将在处理器中运行模型。配置文件的第二部分包括后端处理器的参数,例如要加载的模型,然后是 vLLM 的各种参数。有关 vLLM 引擎的可能配置信息,请参阅此链接。
echo '
# TorchServe frontend parameters
minWorkers: 1
maxWorkers: 1 # Set the number of worker to create a single model instance
startupTimeout: 1200 # (in seconds) Give the worker time to load the model weights
deviceType: "gpu"
asyncCommunication: true # This ensures we can cummunicate asynchronously with the worker
parallelType: "custom" # This lets TS create a single backend prosses assigning 4 GPUs
parallelLevel: 4
# Handler parameters
handler:
# model_path can be a model identifier for Hugging Face hub or a local path
model_path: "meta-llama/Meta-Llama-3.1-70B-Instruct"
vllm_engine_config: # vLLM configuration which gets fed into AsyncVLLMEngine
max_num_seqs: 16
max_model_len: 512
tensor_parallel_size: 4
served_model_name:
- "meta-llama/Meta-Llama-3.1-70B-Instruct"
- "llama3"
'> model_config.yaml
3. 创建模型文件夹
创建模型配置文件(model_config.yaml)后,我们现在将创建一个包含配置和附加元数据(如版本信息)的模型存档。由于模型权重较大,我们不会将其包含在存档中。相反,处理程序将通过在模型配置中指定的 model_path 访问权重。请注意,在这个例子中,我们选择了“no-archive”格式,它创建一个包含所有必要文件的模型文件夹。这使得我们能够轻松地修改配置文件进行实验,而没有任何摩擦。稍后,我们还可以选择 mar 或 tgz 格式来创建更易于传输的工件。
mkdir model_store
torch-model-archiver --model-name vllm --version 1.0 --handler vllm_handler --config-file model_config.yaml --archive-format no-archive --export-path model_store/
4. 部署模型
下一步是启动 TorchServe 实例并加载模型。请注意,为了本地测试目的,我们已经禁用了令牌身份验证。强烈建议在公开部署任何模型时实施某种形式的身份验证。
要启动 TorchServe 实例并加载模型,请运行以下命令:
torchserve --start --ncs --model-store model_store --models vllm --disable-token-auth
您可以通过日志语句监控模型加载的进度。一旦模型加载完成,您可以继续测试部署。
5. 测试部署
vLLM 集成使用与 OpenAI API 兼容的格式,因此我们可以使用专用工具或 curl 来完成此目的。我们在这里使用的 JSON 数据包括模型标识符以及提示文本。其他选项及其默认值可以在 vLLMEngine 文档中找到。
echo '{
"model": "llama3",
"prompt": "A robot may not injure a human being",
"stream": 0
}' | curl --header "Content-Type: application/json" --request POST --data-binary @- http://localhost:8080/predictions/vllm/1.0/v1/completions
请求的输出如下所示:
{
"id": "cmpl-cd29f1d8aa0b48aebcbff4b559a0c783",
"object": "text_completion",
"created": 1727211972,
"model": "meta-llama/Meta-Llama-3.1-70B-Instruct",
"choices": [
{
"index": 0,
"text": " or, through inaction, allow a human being to come to harm.\nA",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 26,
"completion_tokens": 16
}
当流设置为 False 时,TorchServe 将收集完整的答案,在创建最后一个标记后一次性发送。如果我们翻转流参数,我们将接收到包含每个消息中单个标记的分段数据。
结论
在这篇博客文章中,我们探讨了 vLLM 推理引擎与 TorchServe 的全新原生集成。我们展示了如何使用 ts.llm_launcher 脚本来本地部署 Llama 3.1 70B 模型,以及如何创建模型存档以便在任何 TorchServe 实例上部署。此外,我们还讨论了如何在 Docker 容器中构建和运行解决方案,以便在 Kubernetes 或 EKS 上部署。在未来的工作中,我们计划启用 vLLM 和 TorchServe 的多节点推理,并提供预构建的 Docker 镜像以简化部署过程。
我们想对 Mark Saroufim 和 vLLM 团队在撰写本博客文章前的宝贵支持表示衷心的感谢。