
去年,Meta 公司宣布 PyTorch 加入 Linux 基金会,成为机器学习项目及社区的中立家园,AMD 作为创始会员和董事会成员之一参与其中。
PyTorch 基金会的使命是通过开源原则民主化其软件生态系统,推动人工智能的采用,这与 AMD 的核心原则——开放软件生态系统相一致。AMD 致力于通过支持最新一代的硬件、工具、库和其他组件,简化并加速人工智能在广泛科学发现中的应用。
AMD 与关键 PyTorch 代码库开发者(包括 Meta AI 的员工)一起,向 ROCm™开源软件生态系统提供了一系列更新,这些更新为 AMD Instinct™加速器和许多 Radeon™GPU 提供了稳定支持。这使得 PyTorch 开发者能够利用 AMD GPU 加速器和 ROCm 构建他们下一个伟大的 AI 解决方案。PyTorch 社区在识别差距、优先考虑关键更新、提供性能优化反馈以及支持我们从“Beta”版到“稳定版”的旅程方面提供了巨大帮助,我们深深感谢 AMD 和 PyTorch 两个团队之间的紧密合作。ROCm 从“Beta”版到“稳定版”的迁移发生在 PyTorch 1.12 版本(2022 年 6 月)中,为在原生环境中轻松运行 PyTorch 提供了额外支持,无需配置自定义 docker。这是对使用 AMD Instinct 和 ROCm 的 PyTorch 支持质量和性能的信心标志。这些合作努力的成果在以下图 1 中显示的 Microsoft 的 SuperBench 等关键行业基准测试的性能中显而易见。
“我们非常兴奋地看到 AMD 开发者为 PyTorch 做出重大贡献,扩展其功能,使 AI 模型以更高效、更节能和更可扩展的方式运行。这一点的杰出例子是框架与未来硬件系统之间统一内存方法的领导力,我们期待看到这一功能的进展。”
- Soumith Chintala,PyTorch 首席维护者和 Meta AI 工程总监
AMD CDNA™架构以及 ROCm 和 PyTorch 的渐进式改进表明,从 AMD Instinct MI100 到最新一代 AMD Instinct MI200 系列 GPU,从 ROCm 4.2 到 ROCm 5.3,从 PyTorch 1.7 到 PyTorch 1.12,单 GPU 模型吞吐量有所提升。
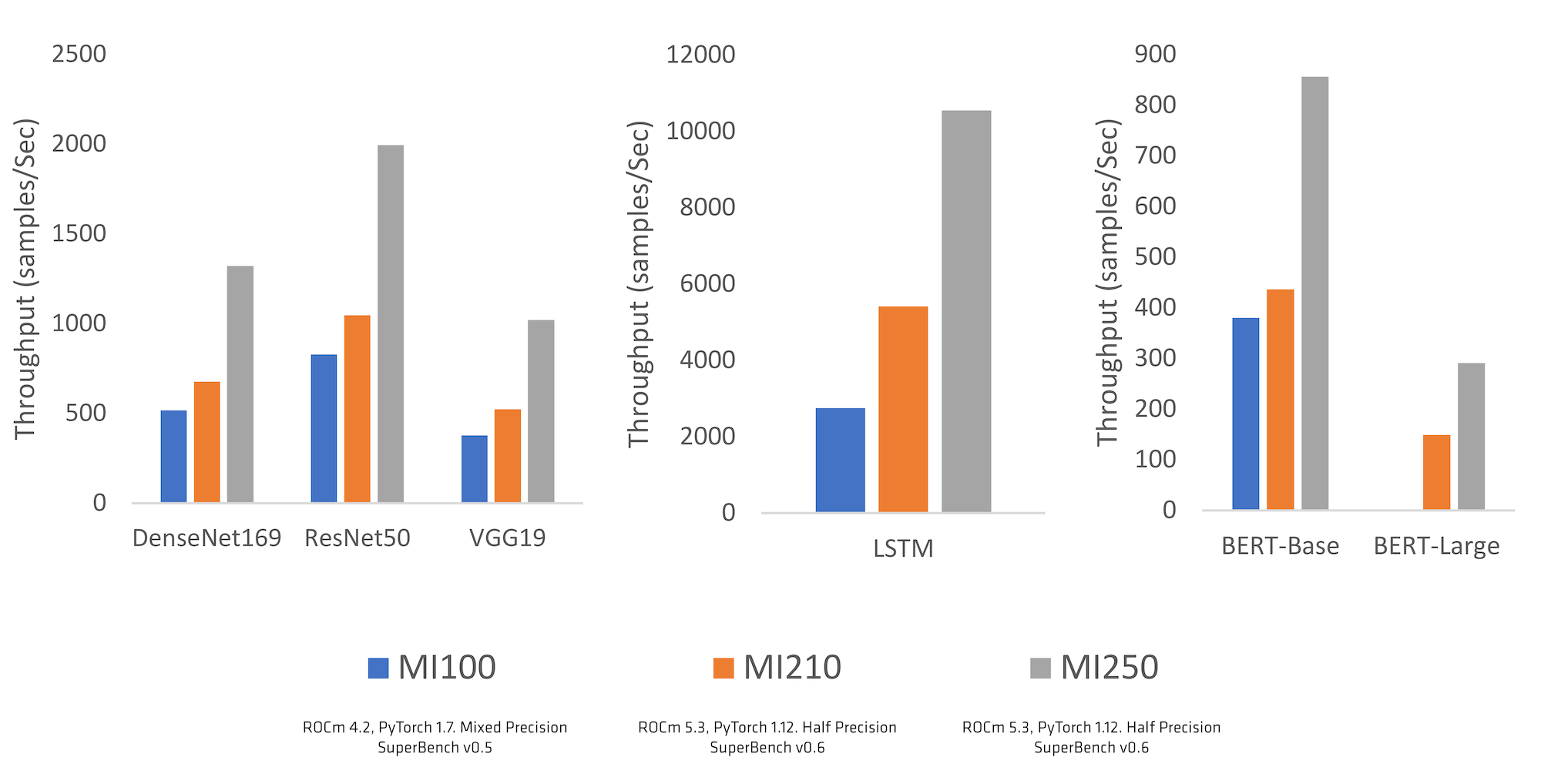
图 1:使用 Microsoft Superbench Suite 的 ML 模型性能随代际变化 1, 2, 3
以下是自 PyTorch 1.12 版本发布以来对 ROCm 支持的几个关键更新
PyTorch 上 ROCm 的完整持续集成(CI)
随着 PyTorch 对 ROCm 的支持从“Beta”版升级到“稳定”版,所有功能和特性的提交现在都通过完整的持续集成(CI)流程进行验证。CI 流程有助于确保在预期的 Docker 和 PIP wheel 发布之前,稳定提交的正确构建和测试过程。
支持 Kineto Profiler
ROCm 现已支持 Kineto 性能分析器,这有助于开发者和用户通过有效的诊断和性能分析工具了解性能瓶颈。该工具还通过 TensorBoard UI 提供改进已知问题的建议和可视化。
添加了关键 PyTorch 库支持
自 ROCm 5.1 以来,PyTorch 生态系统库如 TorchText(文本分类)、TorchRec(推荐系统库 - RecSys)、TorchVision(计算机视觉)、TorchAudio(音频和信号处理)得到全面支持,并与 PyTorch 1.12 一同上游。
ROCm 软件堆栈中提供的核心库,包括 MIOpen(卷积模型)、RCCL(ROCm 集体通信)和 rocBLAS(用于变换器的 BLAS),经过进一步优化,以提供新的潜在效率和更高的性能。
MIOpen 在多个方面进行创新,例如通过融合优化内存带宽和 GPU 启动开销,提供自动调优基础设施以克服问题配置的大设计空间,以及实现不同的算法以优化不同滤波器和输入大小的卷积。MIOpen 是第一个公开支持卷积 bfloat16 数据类型的库之一,允许在较低精度下高效训练,同时保持预期的准确性。
RCCL(发音为“Rickle”)是一个独立的库,包含用于 GPU 的标准集体通信例程,实现了全归约、全收集、归约、广播、归约散射、收集、散射和全对全。它支持直接 GPU 到 GPU 的发送和接收操作。RCCL 已针对使用 PCIe®、Infinity Fabric™(GPU 到 GPU)以及使用 InfiniBand Verbs 或 TCP/IP 套接字的网络进行优化,以实现高带宽。RCCL 支持单节点或多节点中安装的任意数量的 GPU,并可用于单进程或多进程(例如 MPI)应用程序。
除了上述关键亮点外,AMD 和 PyTorch 还共同完成了 50 多项功能和性能改进,以稳定支持 ROCm。这包括对工具、编译器、运行时、通过 TorchScript 的图优化、INT8 量化路径使用以及 ONNX 运行时集成等方面的改进,例如支持基于 Navi 21 的 Radeon™ PRO 数据中心显卡等。
AITemplate 推理引擎
MetaAI 最近发布了一篇博客,宣布其开源的 AITemplate(链接)的发布,这是一个支持 AMD Instinct GPU 加速器和 AMD ROCm 堆栈的统一推理系统。这个基于 Python 的框架可以通过提高 AMD 矩阵核心在 transformer 块中的利用率,显著提升性能。这是通过 AMD 可组合内核(CK)库实现的,该库为跨多个架构(包括 GPU 和 CPU)的机器学习和人工智能工作负载提供了性能关键的内核,通过 HIP 和 C++实现。
此外,AITemplate 还提供了对广泛使用的 AI 模型(如 BERT、ResNet、视觉 Transformer、Stable Diffusion 等)的即插即用支持,通过这些预训练模型简化了部署过程。
未来 ROCm 版本将带来什么?
CPU + GPU 的统一内存模型
随着系统架构的发展,为了解决大型问题和数据集的复杂性,内存管理成为了一个关键的性能瓶颈,需要通过硬件和软件层面的创新来制定一个统一的策略来解决。AMD 凭借其有效的数据中心解决方案,将 AMD EPYC™ CPU 核心与其 AMD Instinct GPU 计算单元集成在一个真正的统一数据中心 APU(加速处理单元)形式中,预计将于 2023 年下半年推出。与 PyTorch 团队合作,我们已经开始了利用统一 CPU + GPU 内存的软件工作,以实现一个快速、低延迟、同步的内存模型,这不仅能够帮助 AMD,也能帮助其他 AI 加速器解决当今复杂的内存管理问题。我们期待这项联合努力和即将到来的公告。
我们已经与 PyTorch 团队合作开始了利用统一 CPU + GPU 内存的软件工作,以实现一个快速、低延迟、同步的内存模型,这不仅能够帮助 AMD,也能帮助其他 AI 加速器解决当今复杂的内存管理问题。我们期待这项联合努力和即将到来的公告。
致谢
本博客内容突出了 AMD 与包括 Meta 在内的关键 PyTorch 贡献者之间的合作,共同开发了许多核心功能,以及微软启用 ONNX Runtime 支持。我们期待与 PyTorch 基金会其他创始成员一起,在下一步和改进工作中,推动 PyTorch 在行业中的民主化和普及。
警告声明
本博客包含有关 AMD 公司(AMD)的前瞻性陈述,例如 AMD 数据中心 APU 形态的可用性、时间表和预期收益,这些陈述是根据 1995 年《私人证券诉讼改革法》的避风港条款做出的。前瞻性陈述通常通过“将”、“可能”、“预期”、“相信”、“计划”、“打算”、“预测”和其他具有类似含义的词语来识别。投资者应谨慎,本博客中的前瞻性陈述基于当前的信念、假设和预期,仅代表本博客发布日期,并涉及可能导致实际结果与当前预期存在重大差异的风险和不确定性。此类陈述受某些已知和未知风险和不确定性因素的影响,许多因素难以预测,通常超出 AMD 的控制范围,可能导致实际结果和其他未来事件与前瞻性信息和陈述中表达或暗示的内容存在重大差异。 投资者应详细审查 AMD 在证券交易委员会的文件中的风险和不确定性,包括但不限于 AMD 最近提交的 10-K 和 10-Q 表格报告。AMD 不承担,并在此明确否认,对在本博客中作出的前瞻性陈述进行更新的任何义务,除非法律要求。
脚注
- 基于 2022 年 11 月 9 日 AMD 内部测试的 MI100D-01 SuperBench v0.5 模型训练结果,使用 2P AMD EPYC™ 7763 CPU 服务器,配备 1x AMD Instinct™ MI100 (32GB HBM2e) 300W GPU,SBIOS 2.2,Ubuntu® 20.04.5 LTS,主机 ROCm™ 5.2.0,客户 ROCm 4.2,PyTorch 1.7.0,以半精度测量总训练吞吐量。服务器制造商可能配置不同,导致结果不同。性能可能受最新驱动程序和优化等因素的影响。
- MI200D-01 SuperBench v0.6 模型训练结果基于 AMD 内部测试,截至 2022 年 11 月 9 日,测量总训练吞吐量,使用 2P AMD EPYC™ 7763 CPU 服务器,配备 1x AMD Instinct™ MI210 (64GB HBM2e) 300W GPU,SBIOS 2.2,Ubuntu 20.04.5 LTS,主机 ROCm 5.3.0,虚拟机 ROCm 5.3,PyTorch 1.12。服务器制造商可能配置不同,导致结果不同。性能可能因最新驱动程序和优化等因素而有所不同。
- MI200D-02:SuperBench v0.6 模型训练结果基于 AMD 内部测试,截至 2022 年 11 月 9 日,测量总训练吞吐量,使用 2P AMD EPYC™️ 7763 CPU 服务器,配备 1x AMD Instinct™️ MI250 (128GB HBM2e) 560W GPU,SBIOS M12,Ubuntu 20.04 LTS,主机 ROCm 5.3.0,虚拟机 ROCm 5.3,PyTorch 1.12。服务器制造商可能配置不同,导致结果不同。性能可能因最新驱动程序和优化等因素而有所不同。