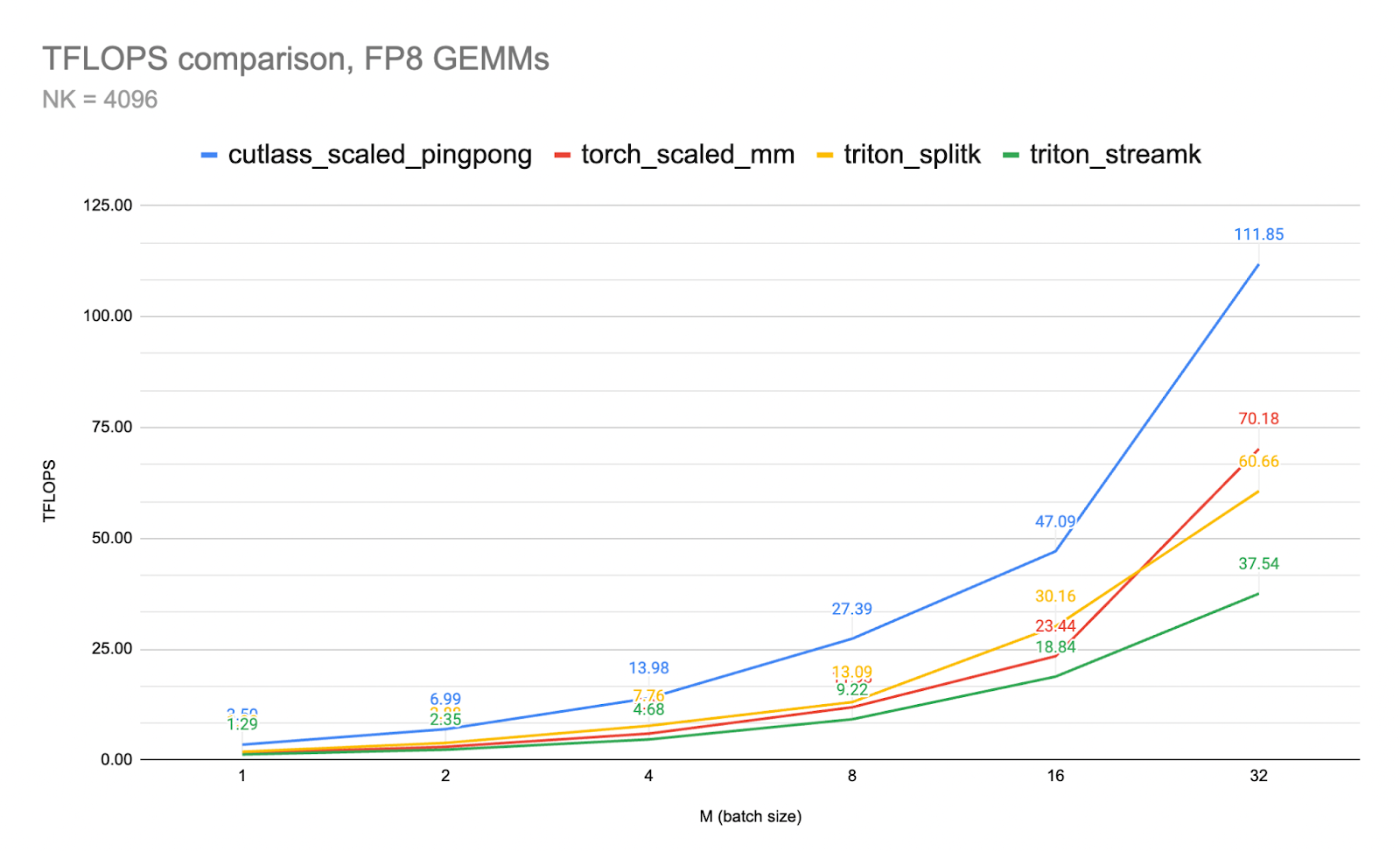
图 1. FP8 GEMM 吞吐量比较 CUTLASS 与 Triton
摘要
在本文中,我们提供了 CUTLASS Ping-Pong GEMM 内核的概述,并附上相关的 FP8 推理内核基准测试。
乒乓球是 Hopper GPU 架构中可用的最快的矩阵乘法(GEMM)内核架构之一。乒乓球是 Warp Group 专用持久内核家族的成员,该家族包括合作和乒乓球两种变体。与之前的 GPU 相比,Hopper 的巨大张量核心计算能力需要深度异步软件流水线才能达到峰值性能。
乒乓球和合作内核体现了这种范式,因为关键设计模式是持久内核以分摊启动和前导开销,以及“异步一切”与具有两个消费者和一个生产者的专用 warp 组,以创建一个高度重叠的处理流水线,能够持续向张量核心提供数据。
当 H100(Hopper)GPU 发布时,英伟达将其称为第一个真正异步的 GPU。这一声明突出了 H100 特定内核架构也需要异步,以便充分发挥计算/GEMM 吞吐量的需求。
CUTLASS 3.x 中引入的 pingpong GEMM 通过将内核的所有方面都移动到“完全异步”的处理范式来体现这一点。在这篇博客中,我们将展示 ping-pong 内核设计的核心特性,并展示其在推理工作负载上与 cublas 和 triton split-k 内核的性能对比。
Ping-Pong 内核设计
Ping-Pong(或技术上称为“sm90_gemm_tma_warpspecialized_pingpong”)使用异步流水线,利用 warp 专业化。与更传统的同质内核不同,“warp 组”承担了专业化的角色。请注意,一个 warp 组由 4 个 warp 组成,每个 warp 有 32 个线程,总共 128 个线程。
在早期的架构中,通常通过在每个 SM 上运行多个线程块来隐藏延迟。然而,随着 Hopper 的 Tensor Core 吞吐量如此之高,这需要转向更深的流水线。这些更深的流水线又阻碍了在每个 SM 上运行多个线程块。因此,持久的线程块现在会在多个瓦片和多个战群之间发出集体主循环。线程块簇的分配基于总的 SM 数量。
对于 Ping-Pong,每个战群承担着数据生产者或数据消费者的专门角色。
生产者战群专注于将数据移动到共享内存缓冲区(通过 TMA)以填充。另外两个战群是专门的数据消费者,它们使用张量核心处理数学(MMA)部分,然后进行任何后续工作并将结果写回全局内存(尾程)。
生产者 warp 群使用 TMA(张量内存加速器),并且故意保持尽可能轻量。事实上,在 Ping-Pong 中,它们故意减少寄存器资源以提高占用率。生产者将减少最大寄存器计数 40,而消费者将增加最大寄存器计数 232,这一效果可以在 CUTLASS 源代码和相应的 SASS 中看到:

这是 Ping-Pong 独有的,每个消费者都在单独的 C 输出瓦片上工作。(作为参考,协作内核在很大程度上等同于 Ping-Pong,但两个消费者群都在同一个 C 输出瓦片上工作)。此外,两个消费者 warp 群随后将工作分配给主循环 MMA 和结尾部分。
如下图片所示:
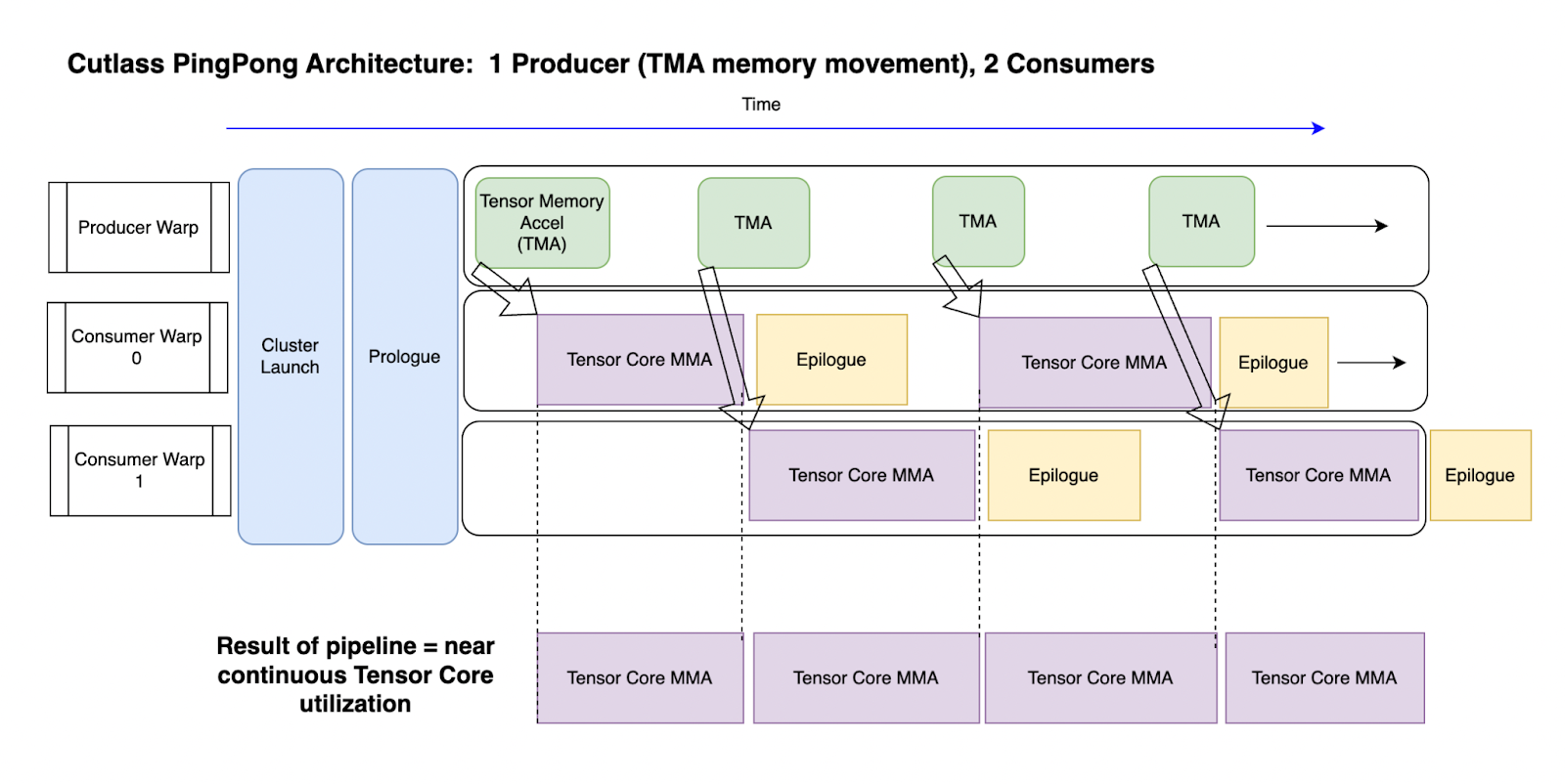
图 2:Ping-Pong 内核管道概述。时间从左到右移动。
拥有两个消费者意味着一个可以使用张量核心进行 MMA 操作,而另一个执行尾声,然后反过来。这最大化了每个 SM 上张量核心的“连续使用”,也是实现最大吞吐量的关键原因之一。张量核心可以持续接收数据,以实现其(接近)最大计算能力。(参见上图 2 底部部分)。
与生产者线程只关注数据移动类似,MMA 线程只发出 MMA 指令以实现峰值发射率。MMA 线程必须发出多个 MMA 指令,并保持这些指令在 TMA 等待屏障中飞行。
下面的内核代码摘录用于巩固专业化方面:
// Two types of warp group 'roles'
enum class WarpGroupRole {
Producer = 0,
Consumer0 = 1,
Consumer1 = 2
};
//warp group role assignment
auto warp_group_role = WarpGroupRole(canonical_warp_group_idx());
使用生产者和张量内存加速器的数据移动
生产者将焦点完全放在数据移动上 - 特别是它们尽可能地保持轻量级,并且实际上放弃了一些寄存器空间给消费者(只保留 40 个寄存器,而消费者将获得 232 个)。它们的主要任务是当共享内存缓冲区被信号为空时,立即发出 TMA(张量内存加速器)命令将数据从全局内存移动到共享内存。
要扩展 TMA(张量内存加速器),TMA 是随着 H100 推出的一个硬件组件,它异步处理从 HBM(全局内存)到共享内存的内存传输。通过拥有一个专门的硬件单元来处理内存移动,工作线程可以释放出来从事其他工作,而不是计算和管理数据移动。TMA 不仅处理数据的移动,还计算所需的内存地址,可以对数据进行任何转换(如缩减等),并且可以处理布局转换,以“交错”模式将数据传输到共享内存,以便无需任何银行冲突即可使用。最后,如果需要,它还可以将相同的数据多播到同一线程集群的其他 SM(流处理器)。一旦数据被传输,TMA 将向感兴趣的消费者发出信号,表明数据已准备好。
CUTLASS 异步管道类
生产和消费者之间的这种信号是通过 CUTLASS 描述的新异步管道类进行协调的,CUTLASS 将其描述如下:
实现持久化的 GEMM 算法需要管理数十种不同类型的异步执行操作,这些操作通过多个按环形列表组织的屏障进行同步。
这种复杂性对于程序员手动管理来说太过复杂。
因此,我们开发了[CUTLASS 流水线异步类]...
Ping-Pong 异步管道中的屏障和同步
生产者必须通过“producer_acquire”来“获取”给定的 smem 缓冲区。在开始时,管道为空,这意味着生产者线程可以立即获取屏障并开始移动数据。
PipelineState mainloop_pipe_producer_state = cutlass::make_producer_start_state<MainloopPipeline>();
数据移动完成后,生产者发出“producer_commit”方法来通知消费者线程数据已准备好。
然而,对于 Ping-Pong,这实际上是一条空操作指令,因为基于 TMA 的生产者的屏障在写入完成后会自动由 TMA 更新。
consumer_wait - 等待来自生产者线程的数据(阻塞)。
consumer_release - 通知生产者线程它们已经完成从给定 smem 缓冲区中消费数据。换句话说,允许生产者开始工作,用新数据填充这个缓冲区。
从那里,同步将真正开始,生产者将通过阻塞生产者获取等待,直到他们可以获取锁,此时他们的数据移动工作将重复进行。这将继续,直到工作完成。
为了提供一个伪代码概述:
//producer
While (work_tile_info.is_valid_tile) {
collective_mainloop.dma() // fetch data with TMA
scheduler.advance_to_next_work()
Work_tile_info = scheduler.get_current_work()
}
// Consumer 1, Consumer 2
While (work_tile_info.is_valid_tile()) {
collective_mainloop.mma()
scheduler.advance_to_next_work()
Work_tile_info = scheduler.get_current_work()
}
以及一个从硬件角度的总体视觉鸟瞰图:
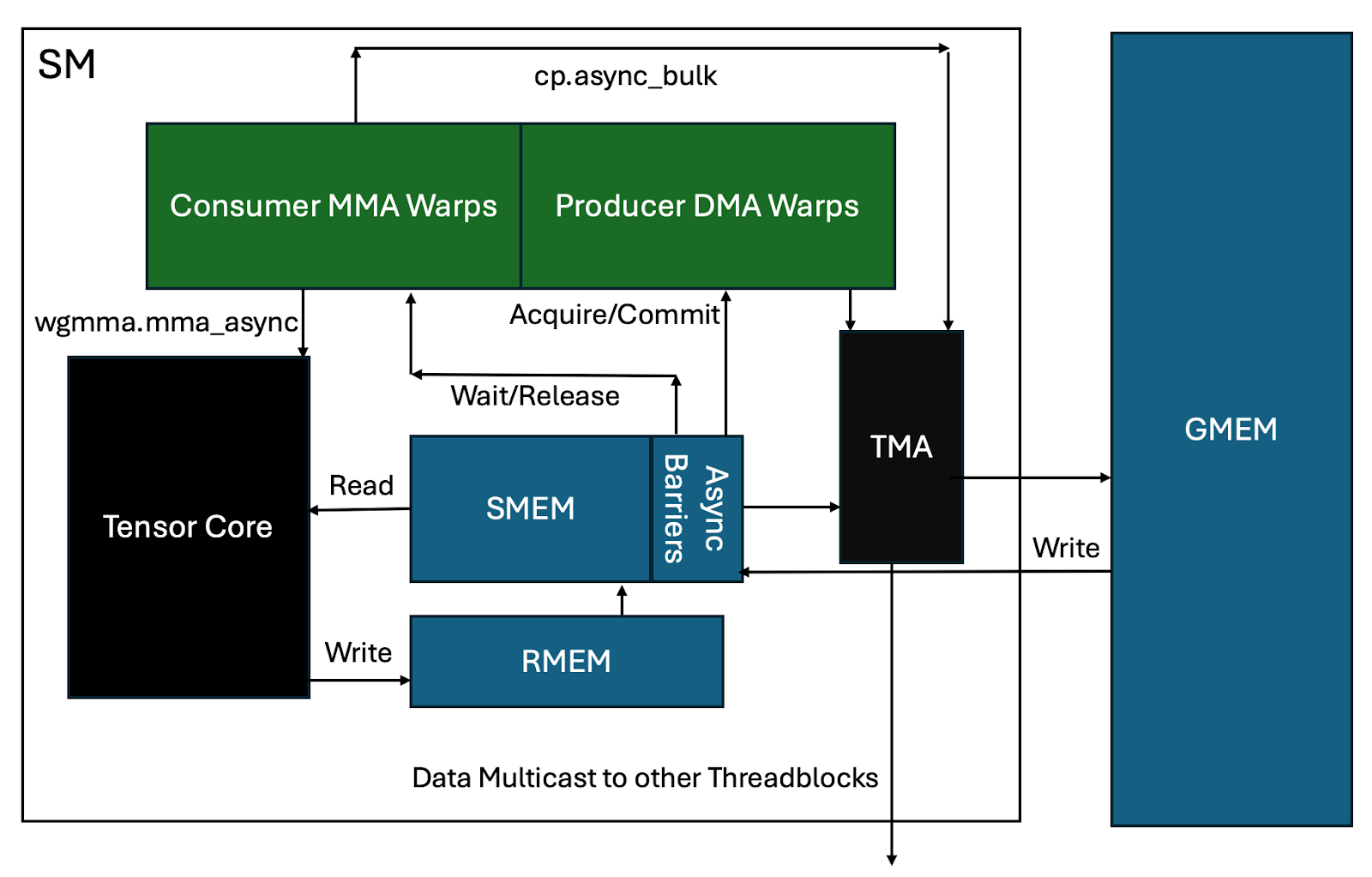
图 3:Ping-Pong 全异步管道概述
Ping-Pong 计算循环的逐步分解
最后,对 Ping-Pong 处理循环的更详细逻辑分解:
A - DMA(直接内存访问)生产者(warp 组)锁定共享内存缓冲区。
B - 这允许它通过单个线程启动对 tma cp_async.bulk 请求的 tma 芯片。
C - TMA 计算所需的实际共享内存寻址,并将数据移动到共享内存中。作为此过程的一部分,执行交换以在 smem 中布局数据,以便实现最快的(无行冲突)访问。
C1 - 可能,数据还可以被多播到其他 SM,或者它可能需要等待来自其他 tma 多播的数据完成加载。(线程块簇现在在多个 SM 之间共享共享内存!)
D - 在这一点上,屏障被更新以向 smem 发出数据到达的信号。
E - 相关的消费 warpgroup 现在通过发出多个 wgmma.mma_async 命令开始工作,这些命令作为 wgmma.mma_async 矩阵乘法操作的一部分,从 smem 读取数据到 Tensor 核心。
F - 当瓷砖完成时,MMA 累加器的值被写入寄存器内存。
G - 消费者 warpgroup 释放共享内存上的屏障。
H - 生产者 warpgroup 开始工作,发出下一个 tma 指令以填充现在空闲的 smem 缓冲区。
我 - 消费者 warp 组同时将任何后续动作应用到累加器上,然后将数据从寄存器移动到不同的 smem 缓冲区。
J - 消费者 warp 发出 cp_async 命令,将数据从 smem 移动到全局内存。
循环重复,直到工作完成。希望这能让你对 Ping-Pong 令人印象深刻的表现的核心概念有一个实际的理解。
微基准测试
为了展示 Ping-Pong 的一些性能,以下是与我们设计快速推理内核工作相关的比较图表。
首先,对迄今为止最快的三个内核进行一般基准测试(越低越好):
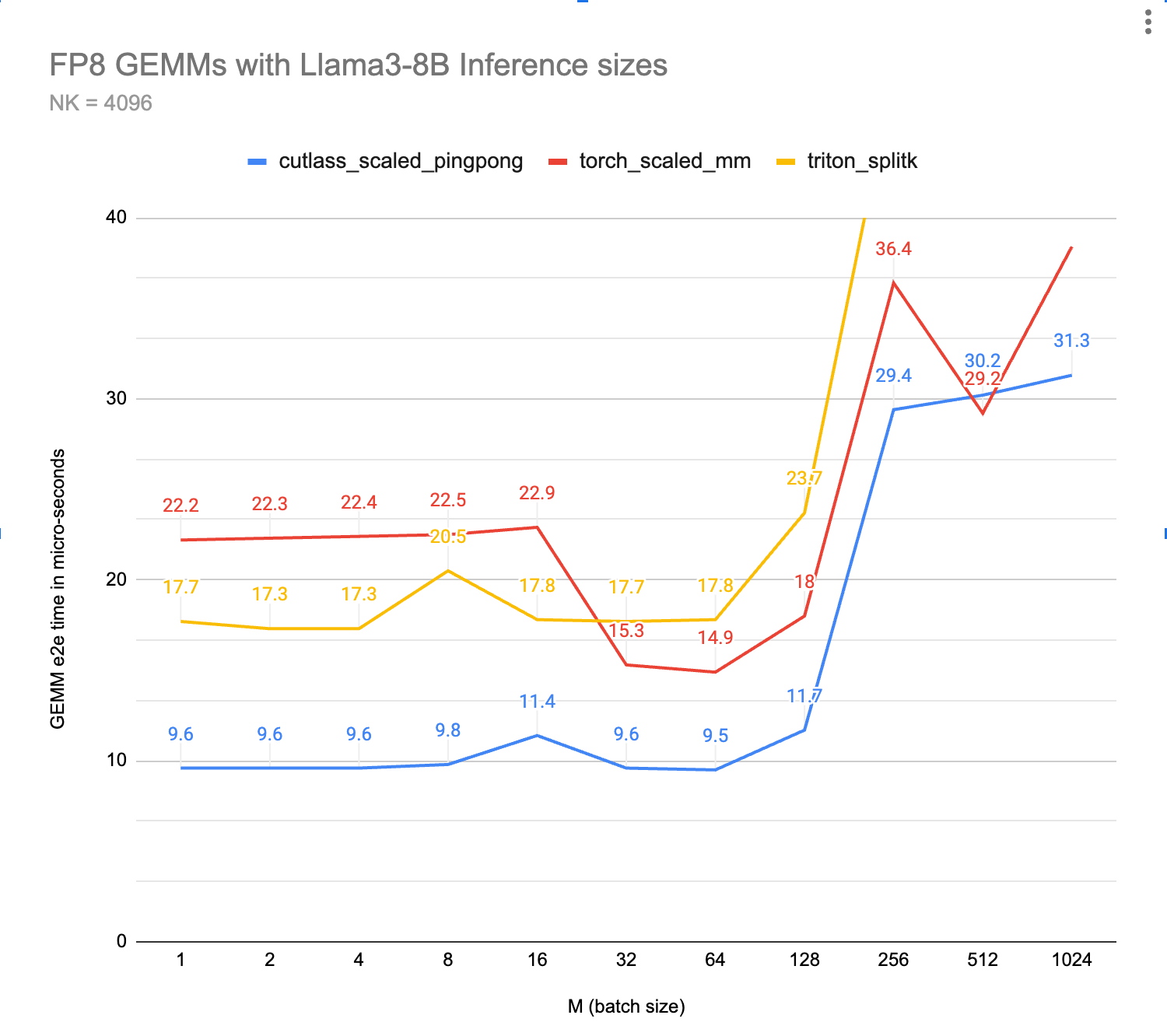
图 4,见上:FP8 GEMMs 的基准时序,越低越好(越快)
将其转化为 Ping-Pong 与 cuBLAS 和 Triton 的相对速度提升图表:
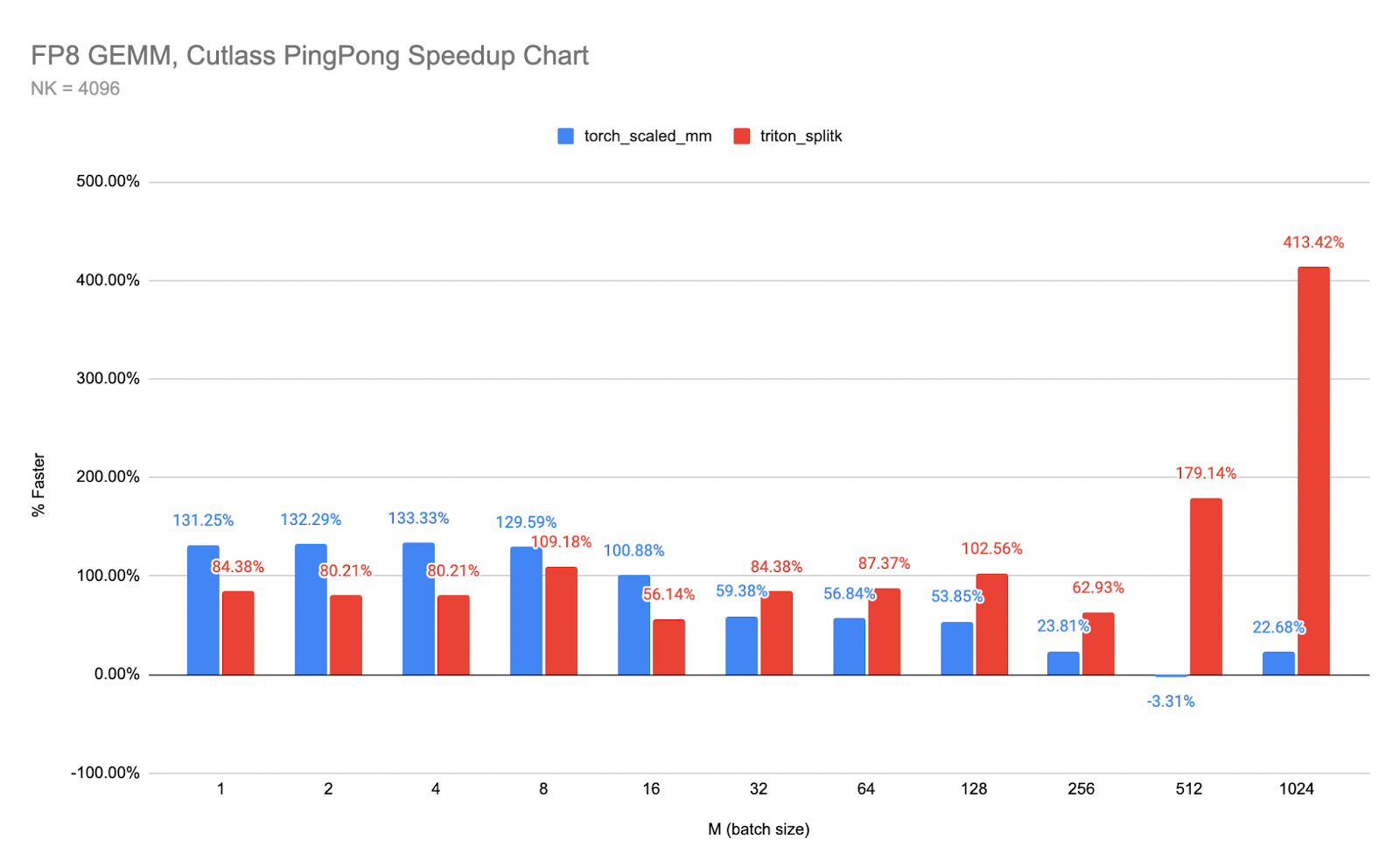
图 5,见上:Ping-Pong 与两个最接近的内核的相对速度提升
Ping-Pong 内核的完整源代码在此(619 行深度模板化的 CUTLASS 代码,或者用著名的乌龟梗来说——“全是模板……一直到底!”)
此外,我们已将 PingPong 实现为 CPP 扩展,以便轻松将其集成到 PyTorch 中(附带一个简单的测试脚本,展示其用法):
最后,为了持续学习,Nvidia 提供了两个 GTC 视频,深入探讨了 CUTLASS 的内核设计:
- 在 Hopper 张量核心上开发最优 CUDA 内核 | GTC 数字春季 2023 | NVIDIA 点播
- CUTLASS:一种高效、灵活且可移植的针对 Hopper 张量核心的定位方法 | GTC 24 2024 | NVIDIA On-Demand
未来工作
数据移动通常是任何内核达到顶级性能的最大障碍,因此对 Hopper 上的 TMA(张量内存加速器)的优化策略理解至关重要。我们之前在 Triton 上发表了关于 TMA 使用的论文。一旦在 Triton 中启用如 warp 专业化等特性,我们计划对 Triton 内核如 FP8 GEMM 和 FlashAttention 如何利用 Ping-Pong 等内核设计在 Hopper GPU 上进行加速进行深入研究。