多模型端点(MMEs)是 Amazon SageMaker 的一个强大功能,旨在简化机器学习(ML)模型的部署和操作。使用 MMEs,您可以在单个服务容器上托管多个模型,并将所有模型托管在单个端点后面。SageMaker 平台自动管理模型的加载和卸载,并根据流量模式调整资源,从而减轻管理大量模型的运营负担。该功能特别适用于需要加速计算的深度学习和生成式 AI 模型。通过资源共享和简化模型管理实现的成本节约,使 SageMaker MMEs 成为您在 AWS 上大规模托管模型的绝佳选择。
最近,生成式 AI 应用受到了广泛的关注和想象。客户希望在 GPU 上部署生成式 AI 模型,但同时又关注成本。SageMaker MMEs 支持 GPU 实例,是这类应用的绝佳选择。今天,我们激动地宣布 TorchServe 支持 SageMaker MMEs。这项新的模型服务器支持让您在继续使用 TorchServe 客户最熟悉的托管堆栈的同时,享受到 MMEs 的所有好处。在这篇文章中,我们展示了如何使用 TorchServe 在 SageMaker MMEs 上托管生成式 AI 模型,例如 Stable Diffusion 和 Segment Anything Model,并构建一个语言引导的编辑解决方案,帮助艺术家和内容创作者更快地开发和迭代他们的作品。
解决方案概述
语言引导的编辑是跨行业生成式 AI 的常见用例。它可以帮助艺术家和内容创作者更高效地工作以满足内容需求,通过自动化重复性任务、优化活动和为最终客户提供超个性化的体验。企业可以从增加内容输出、节省成本、改善个性化和提升客户体验中受益。在本篇文章中,我们将演示如何使用 MME TorchServe 构建语言辅助编辑功能,允许您通过提供文本指令从图像中删除任何不需要的对象,并修改或替换图像中的任何对象。
每个用例的用户体验流程如下:
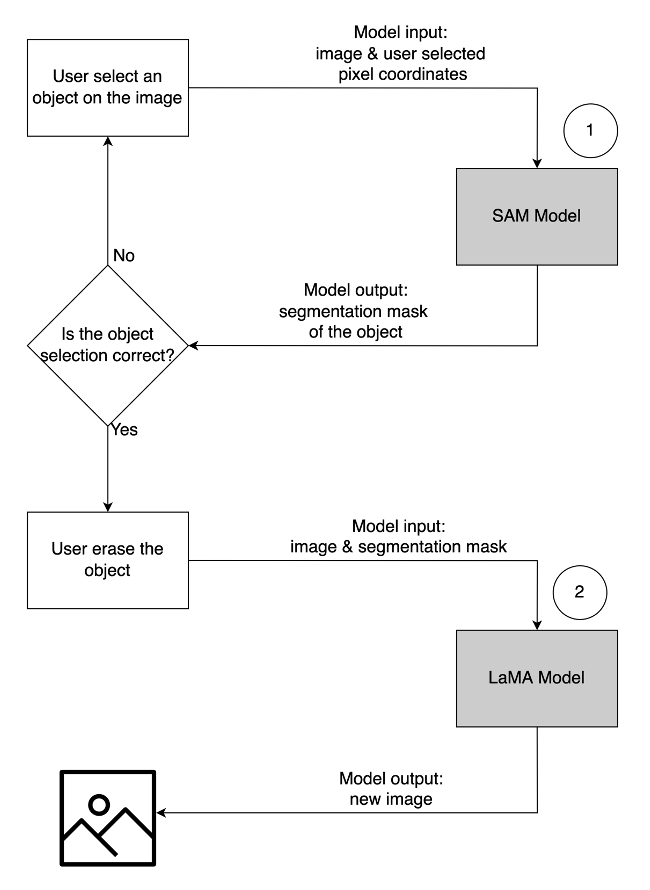
- 要删除不需要的对象,请从图像中选择该对象以突出显示它。此操作会将像素坐标和原始图像发送到生成式 AI 模型,该模型生成对象的分割掩码。在确认正确选择对象后,您可以发送原始图像和掩码图像到第二个模型进行删除。以下是对此用户流程的详细说明。

|

|

|
| 第 1 步:从图像中选择一个对象(“狗”) | 步骤 2:确认正确的对象被突出显示 | 步骤 3:从图像中擦除对象 |
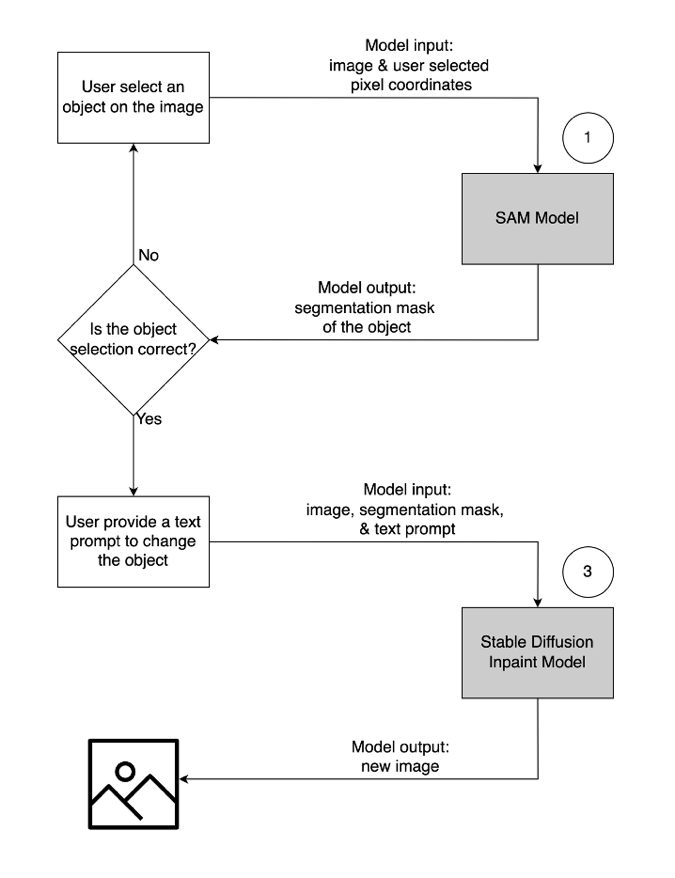
- 要修改或替换对象,请选择并突出显示所需对象,按照上述相同流程操作。一旦确认正确选择了对象,您可以通过提供原始图像、遮罩和文本提示来修改对象。然后,模型将根据提供的说明更改突出显示的对象。以下是对此第二个用户流程的详细说明。

|

|

|
| 步骤 1:从图像中选择一个对象(“花瓶”) | 步骤 2:确认正确的对象被突出显示 | 步骤 3:提供文本提示(“未来主义花瓶”)以修改对象 |
为此解决方案提供动力,我们使用了三个生成式 AI 模型:Segment Anything Model(SAM)、Large Mask Inpainting Model(LaMa)和 Stable Diffusion Inpaint(SD)。以下是这些模型在用户体验工作流程中的使用方式:
| 要移除不需要的对象 | 修改或替换一个对象 |
|
|
- Segment Anything Model(SAM)用于生成感兴趣对象的分割掩码。SAM 由 Meta Research 开发,是一个开源模型,可以分割图像中的任何对象。该模型在名为 SA-1B 的庞大数据集上进行了训练,该数据集包含超过 1100 万张图像和 11 亿个分割掩码。有关 SAM 的更多信息,请参阅他们的网站和论文。
- LaMa 用于从图像中移除任何不需要的对象。LaMa 是一个专注于使用不规则掩码填充图像缺失部分的生成对抗网络(GAN)模型。模型架构结合了图像的全局上下文和单步架构,使用傅里叶卷积,使其能够以更快的速度实现最先进的成果。有关 LaMa 的更多详细信息,请访问他们的网站和论文。
- Stability AI 的 SD 2 inpaint 模型用于修改或替换图像中的对象。该模型允许我们通过提供文本提示来编辑遮罩区域中的对象。该修复模型基于文本到图像的 SD 模型,可以通过简单的文本提示创建高质量的图像。它提供了额外的参数,如原始图像和遮罩图像,以便快速修改和恢复现有内容。有关 AWS 上的 Stable Diffusion 模型的更多信息,请参阅“使用 Stable Diffusion 模型创建高质量图像,并使用 Amazon SageMaker 以经济高效的方式部署它们”。
所有三个模型都托管在 SageMaker MME 上,这减少了管理多个端点的运营负担。除此之外,使用 MME 消除了某些模型可能被低利用率的问题,因为资源是共享的。您可以从提高实例饱和度中观察到好处,这最终导致成本节约。以下架构图说明了如何使用 TorchServe 通过 SageMaker MME 提供所有三个模型。
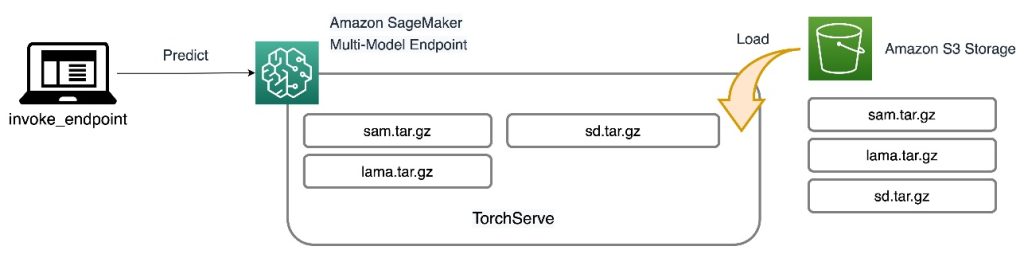
我们已经将实现此解决方案架构的代码发布到我们的 GitHub 仓库。要跟随文章的其余部分,请使用笔记本文件。建议使用 SageMaker 笔记本实例运行此示例,使用 conda_python3 (Python 3.10.10)内核。
扩展 TorchServe 容器
第一步是准备模型托管容器。SageMaker 提供了一个托管的 PyTorch 深度学习容器(DLC),您可以使用以下代码片段获取:
# Use SageMaker PyTorch DLC as base image
baseimage = sagemaker.image_uris.retrieve(
framework="pytorch",
region=region,
py_version="py310",
image_scope="inference",
version="2.0.0",
instance_type="ml.g5.2xlarge",
)
print(baseimage)
由于模型需要资源以及不在基础 PyTorch DLC 上的额外包,您需要构建一个 Docker 镜像。然后,将此镜像上传到 Amazon Elastic Container Registry(Amazon ECR),这样我们就可以直接从 SageMaker 访问。自定义安装的库在 Docker 文件中列出:
ARG BASE_IMAGE
FROM $BASE_IMAGE
#Install any additional libraries
RUN pip install segment-anything-py==1.0
RUN pip install opencv-python-headless==4.7.0.68
RUN pip install matplotlib==3.6.3
RUN pip install diffusers
RUN pip install tqdm
RUN pip install easydict
RUN pip install scikit-image
RUN pip install xformers
RUN pip install tensorflow
RUN pip install joblib
RUN pip install matplotlib
RUN pip install albumentations==0.5.2
RUN pip install hydra-core==1.1.0
RUN pip install pytorch-lightning
RUN pip install tabulate
RUN pip install kornia==0.5.0
RUN pip install webdataset
RUN pip install omegaconf==2.1.2
RUN pip install transformers==4.28.1
RUN pip install accelerate
RUN pip install ftfy
运行 shell 命令文件以在本地构建自定义镜像并将其推送到 Amazon ECR:
%%capture build_output
reponame = "torchserve-mme-demo"
versiontag = "genai-0.1"
# Build our own docker image
!cd workspace/docker && ./build_and_push.sh {reponame} {versiontag} {baseimage} {region} {account}
准备模型工件
新的 MMEs(具有 TorchServe 支持)的主要区别在于您准备模型工件的方式。代码仓库为每个模型(models 文件夹)提供了一个骨架文件夹来存放 TorchServe 所需的文件。我们遵循相同的四个步骤来准备每个模型的骨架文件夹。以下代码是 SD 模型骨架文件夹的示例:
workspace
|--sd
|-- custom_handler.py
|-- model-config.yaml
第一步是在 models 文件夹中下载预训练模型检查点:
import diffusers
import torch
import transformers
pipeline = diffusers.StableDiffusionInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting", torch_dtype=torch.float16
)
sd_dir = "workspace/sd/model"
pipeline.save_pretrained(sd_dir)
下一步是定义一个 custom_handler.py 文件。这是定义模型在接收到请求时的行为所必需的,例如加载模型、预处理输入和后处理输出。 handle 方法是请求的主要入口点,它接受一个请求对象并返回一个响应对象。它加载预训练模型的检查点,并应用 preprocess 和 postprocess 方法到输入和输出数据。以下代码片段展示了 custom_handler.py 文件的一个简单结构。更多详情请参考 TorchServe 处理器 API。
def initialize(self, ctx: Context):
def preprocess(self, data):
def inference(self, data):
def handle(self, data, context):
requests = self.preprocess(data)
responses = self.inference(requests)
return responses
TorchServe 所需的最后一个文件是 model-config.yaml 。该文件定义了模型服务器的配置,例如工作进程数和批量大小。配置是按模型级别进行的,以下代码展示了示例配置文件。有关参数的完整列表,请参阅 GitHub 仓库。
minWorkers: 1
maxWorkers: 1
batchSize: 1
maxBatchDelay: 200
responseTimeout: 300
最后一步是将所有模型工件打包成一个单独的.tar.gz 文件,使用 torch-model-archiver 模块:
!torch-model-archiver --model-name sd --version 1.0 --handler workspace/sd/custom_handler.py --extra-files workspace/sd/model --config-file workspace/sam/model-config.yaml --archive-format no-archive!cd sd && tar cvzf sd.tar.gz .
创建多模型端点
创建 SageMaker MME 的步骤与之前相同。在这个特定示例中,您使用 SageMaker SDK 启动一个端点。首先定义一个 Amazon Simple Storage Service (Amazon S3) 位置和托管容器。这个 S3 位置是 SageMaker 根据调用模式动态加载模型的地方。托管容器是在之前步骤中构建并推送到 Amazon ECR 的自定义容器。请参阅以下代码:
# This is where our MME will read models from on S3.
multi_model_s3uri = output_path
然后您需要定义一个 MulitDataModel 来捕获所有属性,如模型位置、托管容器和权限访问:
print(multi_model_s3uri)
model = Model(
model_data=f"{multi_model_s3uri}/sam.tar.gz",
image_uri=container,
role=role,
sagemaker_session=smsess,
env={"TF_ENABLE_ONEDNN_OPTS": "0"},
)
mme = MultiDataModel(
name="torchserve-mme-genai-" + datetime.now().strftime("%Y-%m-%d-%H-%M-%S"),
model_data_prefix=multi_model_s3uri,
model=model,
sagemaker_session=smsess,
)
print(mme)
deploy() 函数创建端点配置并托管端点:
mme.deploy(
initial_instance_count=1,
instance_type="ml.g5.2xlarge",
serializer=sagemaker.serializers.JSONSerializer(),
deserializer=sagemaker.deserializers.JSONDeserializer(),
)
在我们提供的示例中,我们还展示了如何使用 SDK 列出模型和动态添加新模型。 add_model() 函数将您的本地模型 .tar 文件复制到 MME S3 位置:
# Only sam.tar.gz visible!
list(mme.list_models())
models = ["sd/sd.tar.gz", "lama/lama.tar.gz"]
for model in models:
mme.add_model(model_data_source=model)
调用模型
现在我们已经将三个模型托管在 MME 上,我们可以按顺序调用每个模型来构建我们的语言辅助编辑功能。要调用每个模型,请在 predictor.predict() 函数中提供 target_model 参数。模型名称只是我们上传的 .tar 模型文件的名称。以下是一个 SAM 模型的示例代码片段,它接受像素坐标、点标签和膨胀核大小,并生成像素位置中对象的分割掩码:
img_file = "workspace/test_data/sample1.png"
img_bytes = None
with Image.open(img_file) as f:
img_bytes = encode_image(f)
gen_args = json.dumps(dict(point_coords=[750, 500], point_labels=1, dilate_kernel_size=15))
payload = json.dumps({"image": img_bytes, "gen_args": gen_args}).encode("utf-8")
response = predictor.predict(data=payload, target_model="/sam.tar.gz")
encoded_masks_string = json.loads(response.decode("utf-8"))["generated_image"]
base64_bytes_masks = base64.b64decode(encoded_masks_string)
with Image.open(io.BytesIO(base64_bytes_masks)) as f:
generated_image_rgb = f.convert("RGB")
generated_image_rgb.show()
要从图像中移除不需要的对象,请将 SAM 生成的分割掩码输入到 LaMa 模型中,并与原始图像一起使用。以下图像显示了示例。

|

|
|
| 示例图像 | SAM 的分割掩码 | 使用 LaMa 擦除狗 |
要使用文本提示修改或替换图像中的任何对象,请从 SAM 获取分割掩码,并将其与原始图像和文本提示一起输入 SD 模型,如下例所示。
|
|
|

|
| 样本图像 | SAM 分割掩码 | 使用 SD 模型和文本提示替换 “一个坐在长椅上的仓鼠” |
成本节约
SageMaker MMEs 的益处随着模型整合规模的增加而提高。下表展示了本文中三个模型的 GPU 内存使用情况。它们通过一个 SageMaker MME 部署在一个 g5.2xlarge 实例上。
| Model | GPU 内存(MiB) |
| Segment Anything 模型 | 3,362 |
| 稳定扩散在绘画中的应用 | 3,910 |
| 羊驼 | 852 |
当使用一个端点托管三个模型时,您可以看到成本节约,对于有数百或数千个模型的用例,节约的幅度更大。
例如,考虑 100 个 Stable Diffusion 模型。每个模型单独使用一个端点(4 GiB 内存)可以在美国东部(弗吉尼亚北部)地区每小时花费 1.52 美元。如果使用自己的端点提供所有 100 个模型,每月将花费 218,880 美元。使用 SageMaker MME,单个端点可以使用 ml.g5.2xlarge 实例同时托管四个模型。这可以将生产推理成本降低 75%,每月仅需 54,720 美元。以下表格总结了此示例中单模型和多模型端点之间的差异。在所有模型都已加载后,具有足够内存的端点配置的稳定状态调用延迟将与单模型端点相似。
| 单模型端点 | 多模型端点 | |
| 每月端点总价 | $218,880 | $54,720 |
| 端点实例类型 | ml.g5.2xlarge | ml.g5.2xlarge |
| CPU 内存容量(GiB) | 32 | 32 |
| GPU 内存容量(GiB) | 24 | 24 |
| 端点每小时价格 | $1.52 | $1.52 |
| 每个端点的实例数量 | 2 | 2 |
| 100 个模型所需的端点数量 | 100 | 25 |
清理
完成后,请按照笔记本中清理部分的说明删除本帖中配置的资源,以避免产生不必要的费用。有关推理实例的定价详情,请参阅 Amazon SageMaker 定价。
结论
本篇博客展示了通过使用托管在 SageMaker MMEs 上的 TorchServe 生成式 AI 模型实现的辅助语言编辑功能。我们分享的示例说明了如何使用 SageMaker MMEs 进行资源共享和简化模型管理,同时仍然使用 TorchServe 作为我们的模型服务栈。我们使用了三个深度学习基础模型:SAM、SD 2 Inpainting 和 LaMa。这些模型使我们能够构建强大的功能,例如从图像中擦除任何不需要的对象,以及通过提供文本指令修改或替换图像中的任何对象。这些功能可以帮助艺术家和内容创作者更高效地工作,并通过自动化重复性任务、优化活动和提供高度个性化的体验来满足他们的内容需求。我们邀请您探索本篇博客中提供的示例,并使用 SageMaker MME 和 TorchServe 构建您自己的 UI 体验。
要开始,请参阅使用 GPU 后端实例的多模型端点支持的算法、框架和实例。
关于作者

|
吴杰明是 AWS 的高级 AI/ML 解决方案架构师,帮助客户设计和构建 AI/ML 解决方案。吴杰明的工作涵盖了广泛的机器学习用例,主要兴趣在于计算机视觉、深度学习和在企业中扩展机器学习。加入 AWS 之前,吴杰明担任了超过 10 年的架构师、开发者和技术领导者,其中包括 6 年的工程经验和 4 年的市场营销与广告行业经验。 |

|
李宁是 AWS 的高级软件工程师,专注于构建大规模 AI 解决方案。作为 AWS 与 Meta 共同开发的项目 TorchServe 的技术负责人,她热衷于利用 PyTorch 和 AWS SageMaker 帮助客户拥抱 AI,为更大的利益服务。在专业领域之外,李宁喜欢游泳、旅行、关注科技领域的最新进展,并享受与家人共度的美好时光。 |

|
安克思·古纳帕尔是 Meta(PyTorch)的 AI 合作伙伴工程师。他对模型优化和模型服务充满热情,经验涵盖从 RTL 验证、嵌入式软件、计算机视觉到 PyTorch。他拥有数据科学和电信的双硕士学位。在工作之外,安克思还是一名电子舞曲音乐制作人。 |

|
沙鲁巴·特里坎德是亚马逊 SageMaker 推理的高级产品经理。他热衷于与客户合作,并致力于实现机器学习的民主化。他专注于与部署复杂机器学习应用、多租户机器学习模型、成本优化以及使深度学习模型的部署更加便捷相关的核心挑战。在业余时间,沙鲁巴喜欢远足、了解创新技术、关注 TechCrunch 以及与家人共度时光。 |

|
Subhash Talluri 是亚马逊网络服务电信行业业务单元的 AI/ML 解决方案架构师。他一直在领导为全球电信客户和合作伙伴开发创新的 AI/ML 解决方案。他将工程和计算机科学的多学科专业知识带入其中,帮助在 AWS 云优化的架构上构建可扩展、安全且合规的 AI/ML 解决方案。 |