亚马逊广告使用 PyTorch、TorchServe 和 AWS Inferentia,将推理成本降低 71%,并推动扩展。
亚马逊广告帮助公司通过在亚马逊商店内外展示的广告建立品牌并连接消费者,包括在超过 15 个国家的网站、应用程序和流媒体电视内容。所有规模的企业和品牌,包括注册卖家、供应商、书籍供应商、Kindle Direct Publishing (KDP) 作者、应用程序开发人员和代理机构都可以上传自己的广告创意,这些创意可以包括图片、视频、音频,当然还有在亚马逊上销售的产品。

为了推广准确、安全和愉快的购物体验,这些广告必须遵守内容指南。例如,广告不能闪烁,产品必须在适当的环境中展示,图像和文本应适合一般观众。为了确保广告符合所需的政策和标准,我们需要开发可扩展的机制和工具。
作为解决方案,我们使用了机器学习(ML)模型来揭示可能需要修订的广告。随着深度神经网络在过去十年中的蓬勃发展,我们的数据科学团队开始探索更多样化的深度学习(DL)方法,这些方法能够在最小的人为干预下处理文本、图像、音频或视频。为此,我们使用了 PyTorch 构建计算机视觉(CV)和自然语言处理(NLP)模型,这些模型可以自动标记可能不符合规定的广告。PyTorch 直观、灵活、用户友好,使我们的深度学习模型使用过渡变得无缝。在 AWS Inferentia 基于的 Amazon EC2 Inf1 实例上部署这些新模型,而不是基于 GPU 的实例,将我们的推理延迟降低了 30%,并将推理成本降低了 71%,对于相同的工作负载。
深度学习转型
我们的人工智能系统将经典模型与词嵌入相结合,以评估广告文本。但随着提交量的持续增加,我们需要一种足够敏捷的方法来与我们的业务一起扩展。此外,我们的模型必须快速,在毫秒内提供广告,以提供最佳的客户体验。
过去十年,深度学习在众多领域变得非常流行,包括自然语言、视觉和音频。由于深度神经网络通过许多层传递数据集——提取更高层次的特征——它们可以比经典机器学习模型做出更细微的推断。例如,与其仅仅检测违规语言,深度学习模型可以拒绝广告中存在虚假陈述。
此外,深度学习技术具有可迁移性——为某一任务训练的模型可以适应执行相关任务。例如,一个预训练的神经网络可以被优化以检测图像中的对象,然后微调以识别不允许在广告中显示的特定对象。
深度神经网络可以自动化经典机器学习中最耗时的两个步骤:特征工程和数据标注。与传统监督学习方法不同,后者需要探索性数据分析和人工程序化特征,深度神经网络可以直接从数据中学习相关特征。深度学习模型还可以分析非结构化数据,如文本和图像,而无需像机器学习那样进行预处理。随着数据的增加,深度神经网络能够有效扩展,并在涉及大量数据集的应用中表现尤为出色。
我们选择 PyTorch 来开发我们的模型,因为它帮助我们最大化了系统的性能。使用 PyTorch,我们可以更好地服务客户,同时利用 Python 最直观的概念。PyTorch 中的编程是面向对象的:它将处理函数与它们修改的数据分组在一起。因此,我们的代码库是模块化的,我们可以在不同的应用程序中重用代码片段。此外,PyTorch 的即时模式允许循环和控制结构,因此模型中可以进行更复杂的操作。即时模式使得原型设计和模型迭代变得容易,我们可以处理各种数据结构。这种灵活性帮助我们快速更新模型以满足不断变化的企业需求。
“在此之前,我们尝试过其他“Pythonic”的框架,但 PyTorch 对我们来说无疑是最佳选择。”应用科学家 Yashal Kanungo 说。“使用 PyTorch 很容易,因为它的结构感觉像是 Python 编程的本地化,这是数据科学家们非常熟悉的。”
训练流程
今天,我们完全使用 PyTorch 构建我们的文本模型。为了节省时间和金钱,我们经常通过微调预训练的 NLP 模型来进行语言分析,从而跳过训练的早期阶段。如果我们需要一个新的模型来评估图像或视频,我们首先浏览 PyTorch 的 torchvision 库,该库为图像和视频分类、目标检测、实例分割和姿态估计提供了预训练选项。对于专业任务,我们从零开始构建自定义模型。PyTorch 非常适合这项工作,因为即时模式和用户友好的前端使得实验不同的架构变得容易。
要了解如何在 PyTorch 中微调神经网络,请参阅这篇教程。
在开始训练之前,我们优化模型的超参数,这些参数定义了网络架构(例如,隐藏层的数量)和训练机制(如学习率和批量大小)。选择合适的超参数值至关重要,因为它们将塑造模型的训练行为。我们依靠 SageMaker 中的贝叶斯搜索功能来完成这一步骤。贝叶斯搜索将超参数调整视为回归问题:它提出可能产生最佳结果的超参数组合,并运行训练作业来测试这些值。每次试验后,回归算法确定下一组要测试的超参数值,性能逐步提高。
我们使用 SageMaker Notebooks 对模型进行原型设计和迭代。Eager 模式允许我们快速原型设计模型,通过为每个训练批次构建一个新的计算图来实现;操作序列可以从一次迭代到下一次迭代改变,以适应不同的数据结构或与中间结果保持一致。这使我们能够在训练过程中调整网络而无需从头开始。这些动态图对于基于可变序列长度的递归计算特别有价值,例如在广告中用 NLP 分析的单词、句子和段落。
当我们最终确定模型架构后,我们将在 SageMaker 上部署训练作业。PyTorch 通过同时运行多个训练作业来帮助我们更快地开发大型模型。PyTorch 的分布式数据并行(DDP)模块在 SageMaker 内部多个相互连接的机器上复制单个模型,所有进程同时在其数据集的独特部分上运行前向传递。在反向传递期间,该模块平均所有进程的梯度,因此每个本地模型都使用相同的参数值进行更新。
模型部署流程
当我们将模型部署到生产环境中时,我们希望在不影响预测准确性的情况下确保较低的推理成本。几个 PyTorch 功能和 AWS 服务帮助我们解决了这一挑战。
动态图的灵活性丰富了训练过程,但在部署时我们希望最大化性能和可移植性。在 PyTorch 中开发 NLP 模型的一个优势是,它们可以直接通过 TorchScript 转换为静态操作序列,TorchScript 是专门为 ML 应用优化的 Python 子集。Torchscript 将 PyTorch 模型转换为更高效、更适合生产的中间表示(IR)图,易于编译。我们通过模型运行一个样本输入,TorchScript 记录正向传递期间执行的操作。生成的 IR 图可以在高性能环境中运行,包括 C++和其他多线程的 Python 无关环境,并且如算子融合等优化可以加快运行时间。
Neuron SDK 和 AWS Inferentia 驱动的计算
我们将模型部署在由 AWS Inferentia 驱动的 Amazon EC2 Inf1 实例上,这是亚马逊首款专为加速深度学习推理工作负载而设计的 ML 硅芯片。与基于 Amazon EC2 GPU 的实例相比,Inferentia 已证明可以将推理成本降低高达 70%。我们使用了 AWS Neuron SDK——一套与 Inferentia 一起使用的软件工具——来编译和优化我们的模型,以便在 EC2 Inf1 实例上部署。
下面的代码片段展示了如何使用 Neuron 编译 Hugging Face BERT 模型。类似于 torch.jit.trace(),neuron.trace()在正向传递过程中记录模型在示例输入上的操作,以构建静态 IR 图。
import torch
from transformers import BertModel, BertTokenizer
import torch.neuron
tokenizer = BertTokenizer.from_pretrained("path to saved vocab")
model = BertModel.from_pretrained("path to the saved model", returned_dict=False)
inputs = tokenizer ("sample input", return_tensor="pt")
neuron_model = torch.neuron.trace(model,
example_inputs = (inputs['input_ids'], inputs['attention_mask']),
verbose = 1)
output = neuron_model(*(inputs['input_ids'], inputs['attention_mask']))
自动转换和重新校准
在底层,Neuron 通过将模型自动转换为更小的数据类型来优化模型性能。默认情况下,大多数应用程序使用 32 位单精度浮点数(FP32)格式表示神经网络值。将模型自动转换为 16 位格式——半精度浮点(FP16)或脑浮点(BF16)——可以减少模型的内存占用和执行时间。在我们的案例中,我们决定使用 FP16 来优化性能,同时保持高精度。
自动将数据类型转换为更小的类型在某些情况下可能会触发模型预测的细微差异。为确保模型的准确性不受影响,Neuron 会比较 FP16 和 FP32 模型的性能指标和预测结果。当自动转换降低模型准确性时,我们可以告诉 Neuron 编译器仅将权重和某些数据输入转换为 FP16,其余中间结果保持为 FP32。此外,我们通常使用训练数据运行几次迭代以重新校准我们的自动转换模型。这个过程比原始训练要少得多。
部署
为了分析多媒体广告,我们运行一组深度学习模型。所有上传到亚马逊的广告都会通过专门模型进行处理,评估它们包含的所有类型的内容:图像、视频和音频、标题、文本、背景,甚至语法、语法和可能的不当语言。我们从这些模型收到的信号表明广告是否符合我们的标准。
部署和监控多个模型非常复杂,因此我们依赖于 TorchServe,这是 SageMaker 的默认 PyTorch 模型服务库。由 Facebook 的 PyTorch 团队和 AWS 共同开发,以简化从原型设计到生产的过渡,TorchServe 帮助我们大规模部署训练好的 PyTorch 模型,无需编写自定义代码。它提供了一套安全的 REST API,用于推理、管理、指标和解释。凭借多模型服务、模型版本控制、集成支持、自动批处理等特性,TorchServe 非常适合支持我们庞大的工作负载。您可以在本博客文章中了解更多关于使用原生 TorchServe 集成在 SageMaker 上部署 PyTorch 模型的信息。
在某些用例中,我们利用 PyTorch 的面向对象编程范式将多个深度学习模型封装到一个父对象中——一个 PyTorch nn.Module,并将它们作为一个单一集成提供服务。在其他情况下,我们使用 TorchServe 在单独的 SageMaker 端点上为单个模型提供服务,这些模型运行在 AWS Inf1 实例上。
自定义处理程序
我们特别赞赏 TorchServe 允许我们将模型初始化、预处理、推理和后处理代码嵌入到单个 Python 脚本 handler.py 中,该脚本位于服务器上。这个脚本——处理器——对来自广告的无标签数据进行预处理,将数据通过我们的模型运行,并将生成的推理结果传递给下游系统。TorchServe 提供了几个默认处理器,用于加载权重和架构,并准备模型在特定设备上运行。我们可以将所有额外的必需工件,如词汇表文件或标签映射,与模型捆绑在一个单独的存档文件中。
当我们需要部署具有复杂初始化过程或来自第三方库的模型时,我们在 TorchServe 中设计自定义处理器。这些处理器使我们能够加载任何库中的任何模型,并执行任何所需的过程。以下代码片段展示了可以在任何 SageMaker 托管端点实例上提供服务的简单处理器,用于服务 Hugging Face BERT 模型。
import torch
import torch.neuron
from ts.torch_handler.base_handler import BaseHandler
import transformers
from transformers import AutoModelForSequenceClassification,AutoTokenizer
class MyModelHandler(BaseHandler):
def initialize(self, context):
self.manifest = ctx.manifest
properties = ctx.system_properties
model_dir = properties.get("model_dir")
serialized_file = self.manifest["model"]["serializedFile"]
model_pt_path = os.path.join(model_dir, serialized_file)
self.tokenizer = AutoTokenizer.from_pretrained(
model_dir, do_lower_case=True
)
self.model = AutoModelForSequenceClassification.from_pretrained(
model_dir
)
def preprocess(self, data):
input_text = data.get("data")
if input_text is None:
input_text = data.get("body")
inputs = self.tokenizer.encode_plus(input_text, max_length=int(max_length), pad_to_max_length=True, add_special_tokens=True, return_tensors='pt')
return inputs
def inference(self,inputs):
predictions = self.model(**inputs)
return predictions
def postprocess(self, output):
return output
批处理
硬件加速器针对并行性和批处理进行了优化,将多个输入一次性喂给模型有助于充分利用所有可用容量,通常会导致更高的吞吐量。然而,过大的批处理大小会增加延迟,而吞吐量的提升却微乎其微。通过尝试不同的批处理大小,我们可以找到模型和硬件加速器的最佳平衡点。我们进行实验以确定适合我们模型大小、有效载荷大小和请求流量模式的最佳批处理大小。
现在 Neuron 编译器支持可变批处理大小。之前,对模型进行跟踪时硬编码了预定义的批处理大小,因此我们必须填充数据,这可能会浪费计算资源,降低吞吐量,并加剧延迟。Inferentia 针对小批次的吞吐量最大化进行了优化,通过减轻系统负载来降低延迟。
并行性
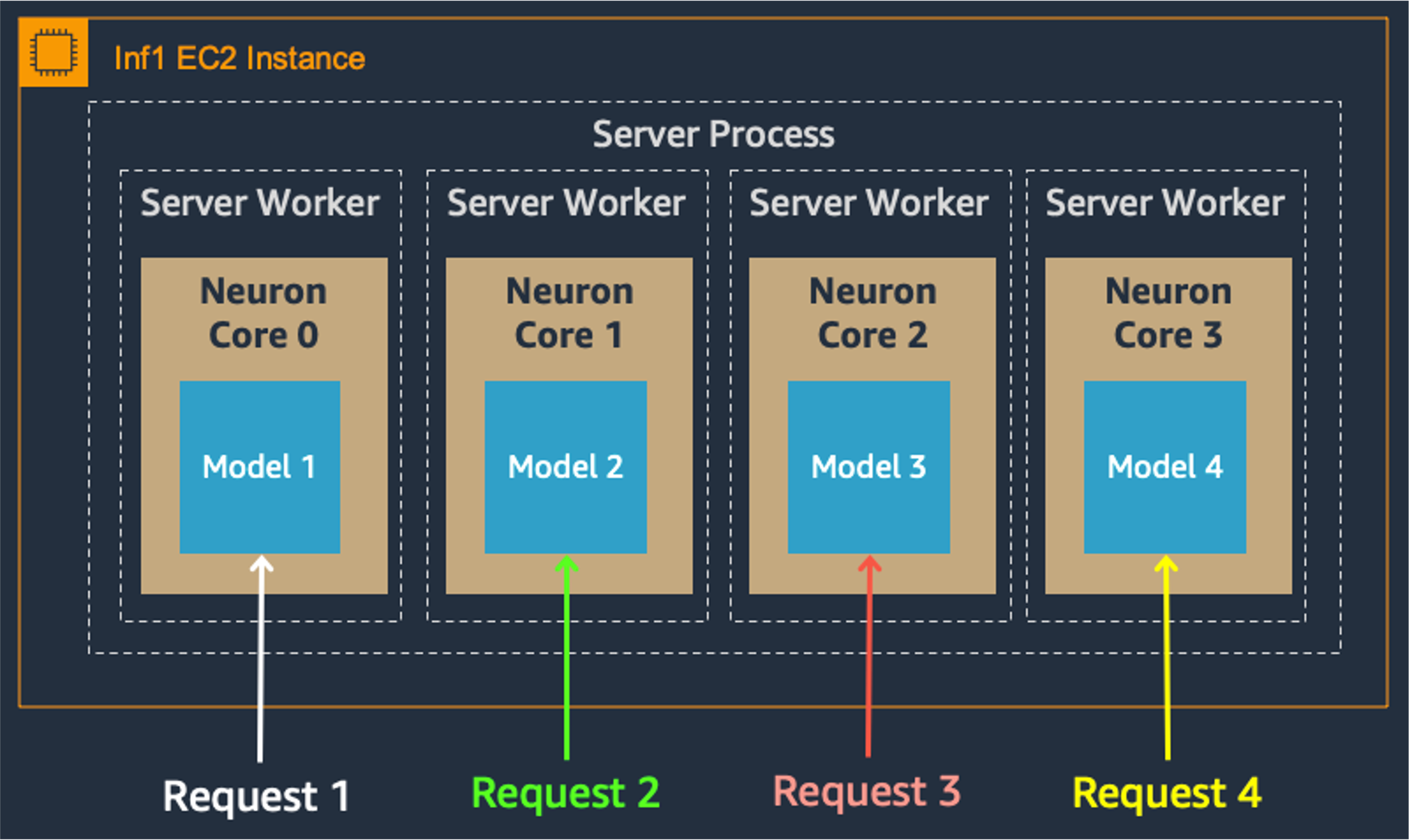
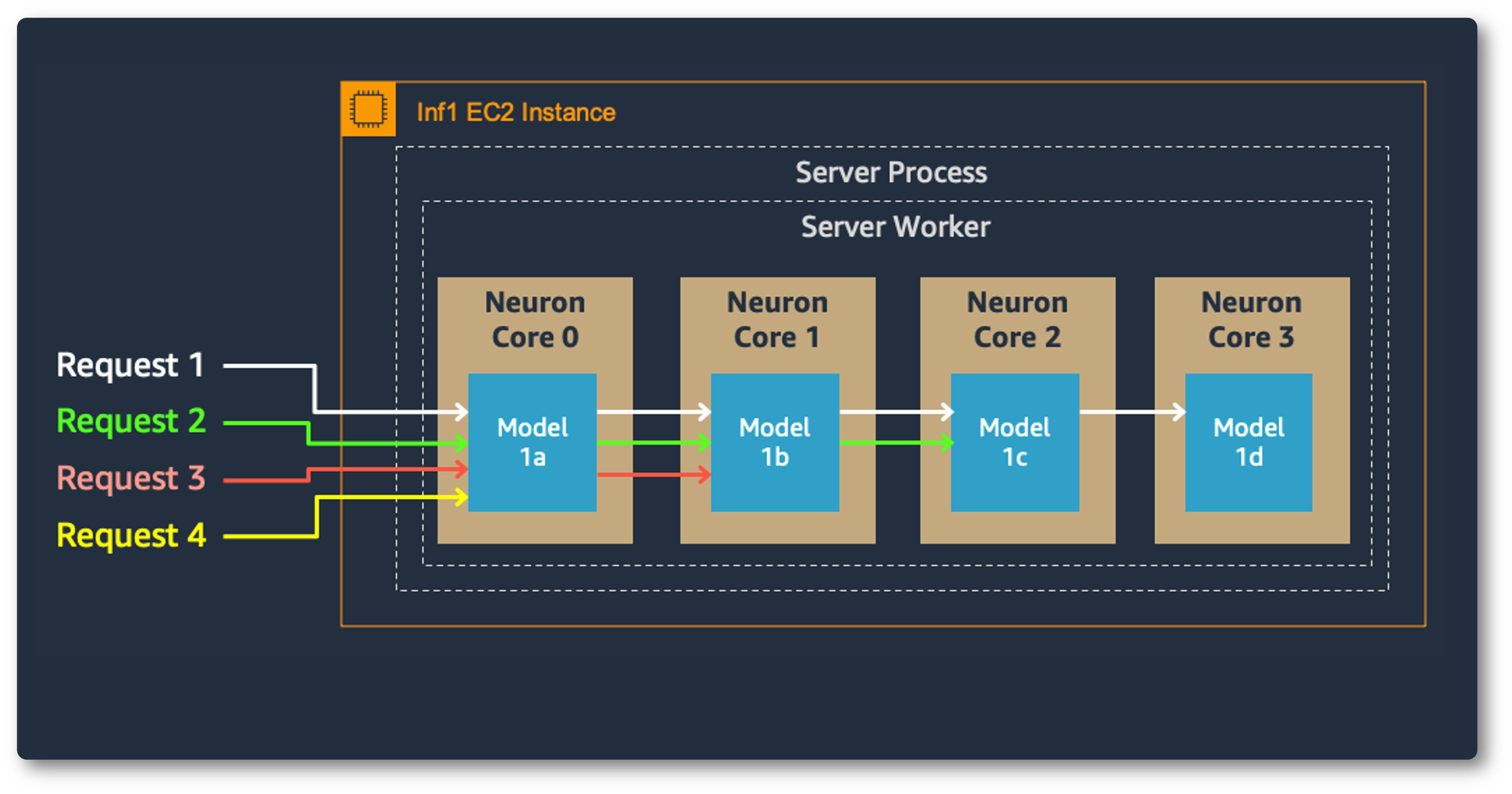
多核上的模型并行也提高了吞吐量和延迟,这对我们的重负载至关重要。每个 Inferentia 芯片包含四个 NeuronCores,它们可以同时运行不同的模型,或者形成一个流水线来流式传输单个模型。在我们的用例中,数据并行配置以最低的成本提供了最高的吞吐量,因为它可以扩展并发处理请求。
数据并行:
模型并行:
监控
监控生产中推理的准确性至关重要。最初预测良好的模型在部署过程中可能会因为接触到更广泛的数据而逐渐退化。这种现象称为模型漂移,通常发生在输入数据分布或预测目标发生变化时。
我们使用 SageMaker Model Monitor 来跟踪训练数据和生产数据之间的差异。当生产中的预测开始偏离训练和验证结果时,Model Monitor 会通知我们。多亏了这种早期预警,我们可以在我们的广告商受到影响之前恢复准确性——如果需要的话,可以通过重新训练模型。为了实时跟踪性能,Model Monitor 还会向我们发送有关预测质量的指标,例如准确性、F 分数和预测类别的分布。
为了确定我们的应用程序是否需要扩展,TorchServe 会定期记录 CPU、内存和磁盘的资源利用率指标;它还会记录收到的请求数与已服务的请求数。对于自定义指标,TorchServe 提供了 Metrics API。
一个令人满意的结果
我们的深度学习模型在 PyTorch 中开发并在 Inferentia 上部署,加速了我们的广告分析同时降低了成本。从我们第一次探索深度学习开始,使用 PyTorch 编程就感觉自然。其用户友好的特性帮助我们顺利地从早期实验到多模态集成部署的过程。PyTorch 让我们能够快速原型设计和构建模型,这对于我们的广告服务发展和扩展至关重要。作为额外的好处,PyTorch 与 Inferentia 和我们的 AWS ML 堆栈无缝协作。我们期待使用 PyTorch 构建更多用例,以便我们能够继续为客户提供准确、实时的结果。