1.0 摘要
我们提出了一种优化的 Triton FP8 GEMM(通用矩阵-矩阵乘法)内核 TK-GEMM,该内核利用 SplitK 并行化。对于小批量大小推理,TK-GEMM 在 NVIDIA H100 GPU 上对 Llama3-70B 推理问题大小实现了相对于基础 Triton matmul 实现的 1.94 倍提升,相对于 cuBLAS FP8 的 1.87 倍提升,相对于 cuBLAS FP16 的 1.71 倍提升。
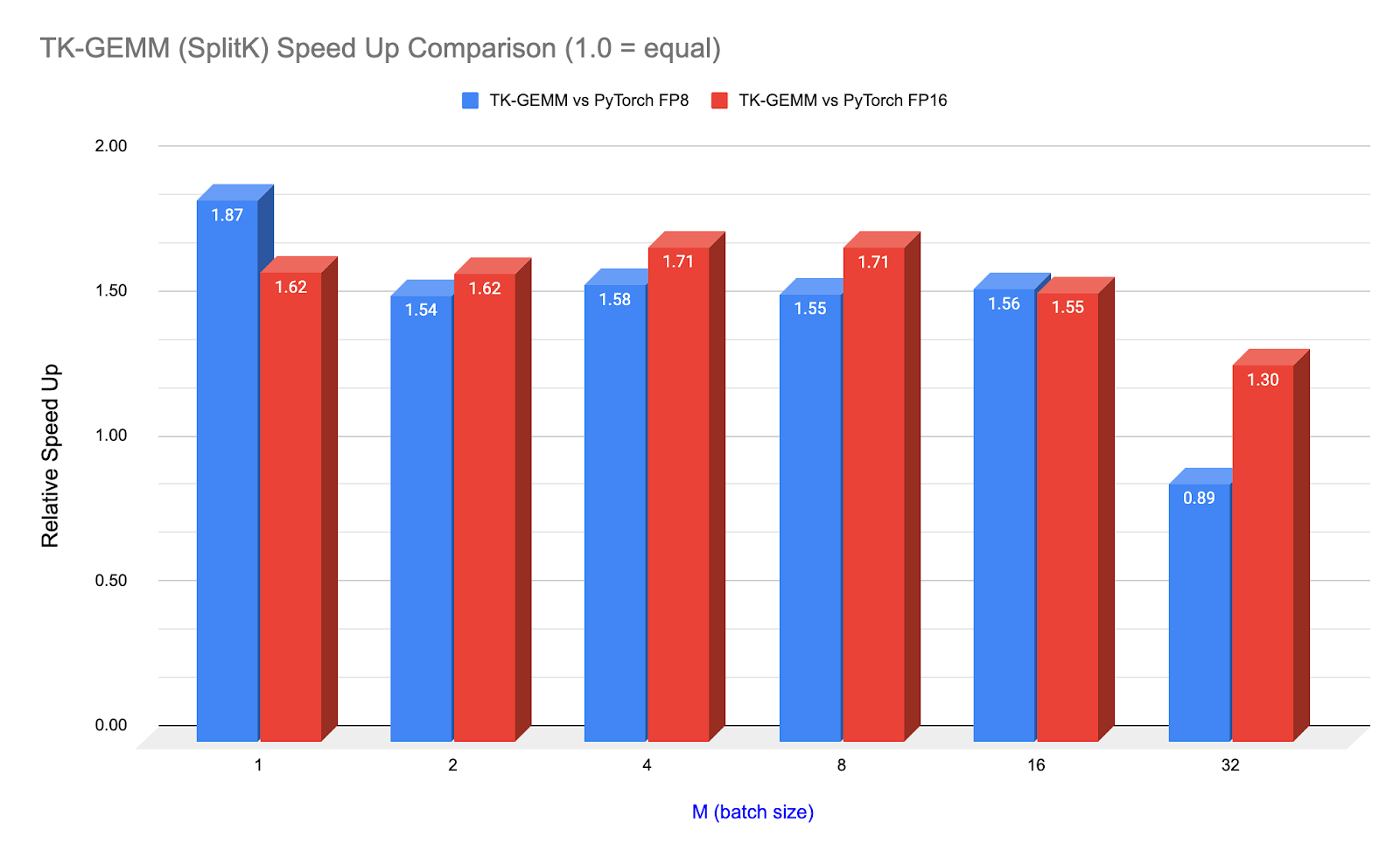
图 1. TK-GEMM 相对于 PyTorch(调用 cuBLAS)在 Llama3-70B 注意力层矩阵形状(N=K=8192)上的加速
在这篇博客中,我们将介绍如何使用 Triton 设计一个优化的内核,用于 FP8 推理,并将其针对 Lama3-70B 推理进行了调优。我们将介绍 FP8(8 位浮点数),这是由 Hopper 生成 GPU(SM90)支持的新的数据类型,Triton 支持的关键 SM90 特性,以及我们如何修改并行化以最大化内存吞吐量,适用于内存受限(推理)问题规模。
我们还专门设置了一节介绍 CUDA 图,这是一种重要的技术,有助于实现内核级别的加速,并使希望在生产环境中使用 Triton 内核的开发者能够获得额外的性能提升。
代码库和代码可在以下链接获取:https://github.com/pytorch-labs/applied-ai
2.0 FP8 数据类型
FP8 数据类型是由 Nvidia、Arm 和 Intel 共同引入的,是 16 位浮点类型的继任者。由于位计数减半,它有可能为其前辈 Transformer 网络提供显著的吞吐量提升。FP8 数据类型包括以下两种格式:
E4M3(4 位指数和 3 位尾数)。能够存储+/- 448 和 nan。
E5M2(5 位指数和 2 位尾数)。能够存储+/- 57,334、nan 和 inf。
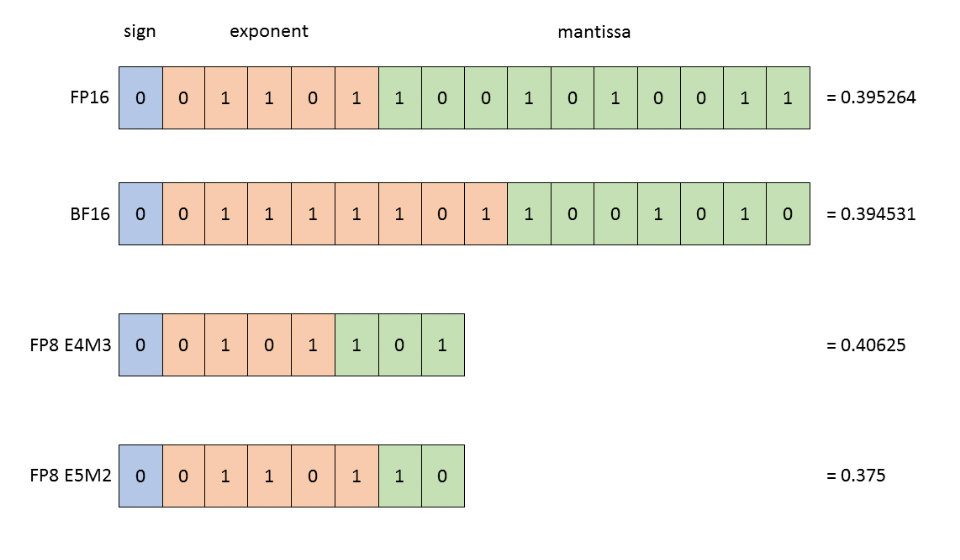
如上图所示:BF16、FP16、FP8 E4M3 和 FP8 E5M2。
为了展示精度差异,每个格式中均显示了与 0.3952 最接近的表示。
图片来源:Nvidia
我们在推理和正向传递训练中使用 E4M3,因为它具有更高的精度;在反向传递训练中使用 E5M2,因为它具有更宽的动态范围。Nvidia 设计了他们的 H100 FP8 Tensor Core,以提供峰值 3958 TFLOPS,是 FP16 Tensor Core 的 2 倍 FLOPS。
我们在设计 Triton 内核时考虑了这些硬件创新,在接下来的博客中,我们将讨论如何利用和验证这些特性确实被 Triton 编译器所使用。
3.0 三叉戟跳跃支持及 FP8 张量核心指令
Hopper GPU 架构新增以下新特性,我们预计将加速 FP8 GEMM。
- 张量内存加速器(TMA)硬件单元
- 线程组矩阵乘累加指令(WGMMA)
- 线程块集群
目前 Triton 利用了这些特性之一,即 wgmma 指令,而 PyTorch(调用 cuBLAS)则利用了全部 3 个,这使得这些加速效果更加令人印象深刻。为了充分利用 Hopper FP8 张量核心,即使旧的 mma.sync 指令仍然得到支持,wgmma 也是必要的。
mma 和 wgmma 指令之间的关键区别在于,不再是 1 个 CUDA 线程束负责一个输出碎片,而是整个线程束组,即 4 个 CUDA 线程束,异步地向一个输出碎片贡献。
为了看到这个指令在实际中的样子,并验证我们的 Triton 内核确实利用了这个特性,我们使用了 nsight compute 分析了 PTX 和 SASS 汇编代码。
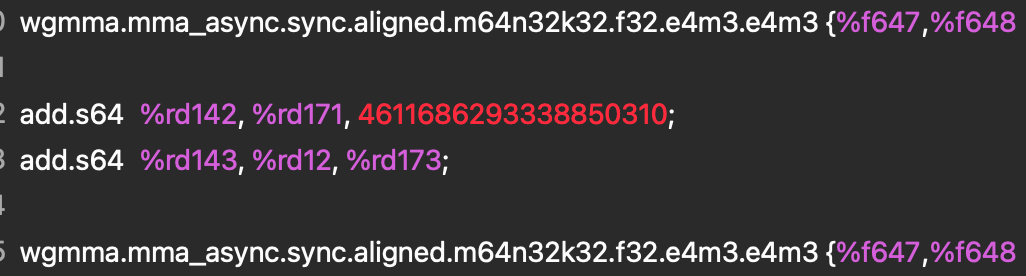
图 2. PTX 汇编
此指令在 SASS 中进一步降低为 QGMMA 指令。

图 3. SASS 汇编
这两条指令告诉我们正在对两个 FP8 E4M3 输入张量进行乘法运算,并在 F32 中进行累加,这证实了 TK-GEMM 内核正在使用 FP8 张量核心,并且降低操作正在正确进行。
4.0 分割 K 工作分解
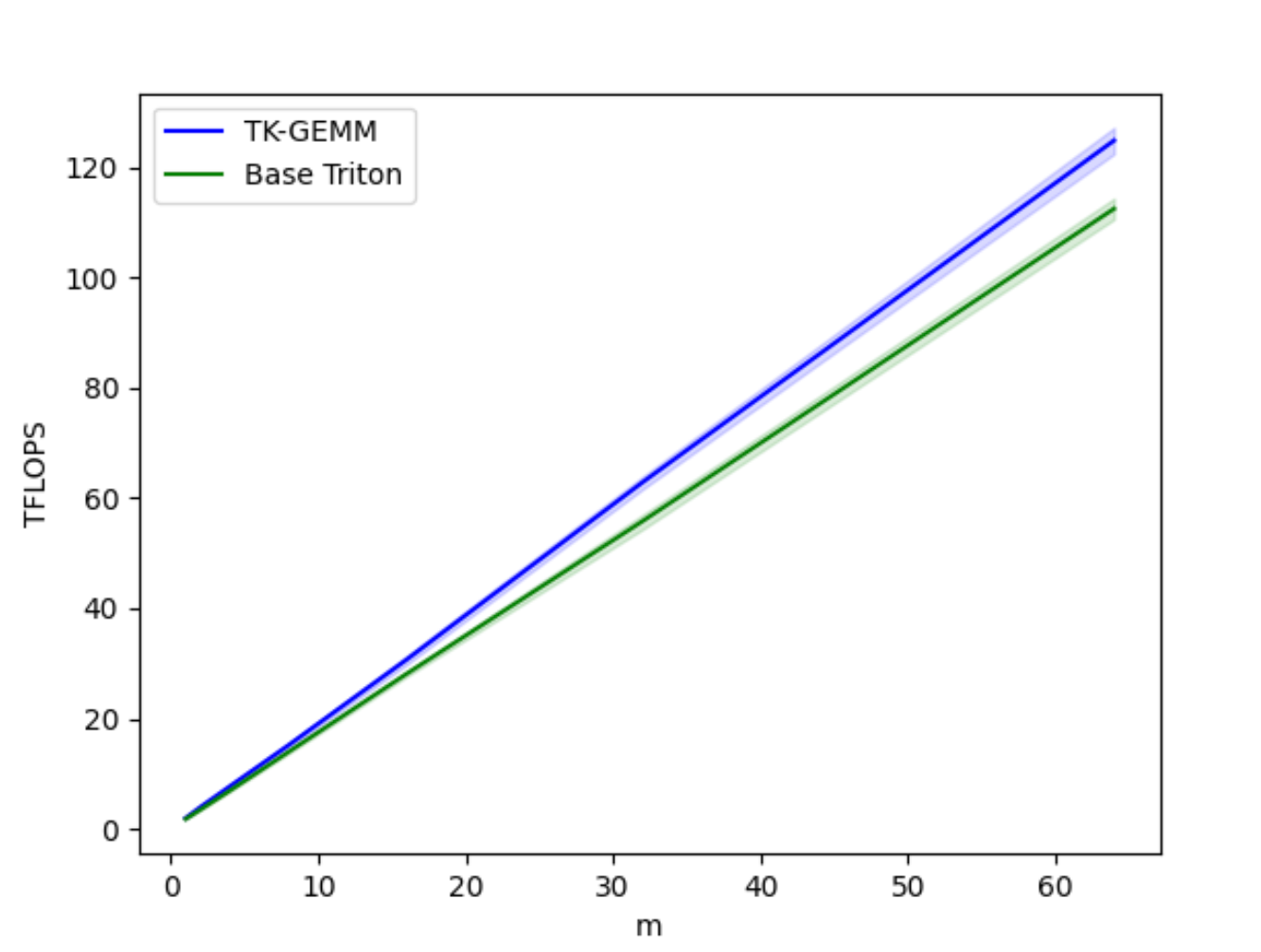
图 4. TK-GEMM 与基础 Triton GEMM TFLOPS 对比,M = 1-64
基础 Triton FP8 GEMM 实现对于小 M 范围性能不佳,对于矩阵乘法 A(MxN) x B(NxK),M < N, K。为了优化此类矩阵配置文件,我们采用了分割 K 工作分解,而不是基础 Triton 内核中的数据并行分解。这大大提高了小 M 范围的延迟。
关于背景,分割 K 在 k 维度上启动额外的线程块来计算部分输出和。然后使用原子减少来对每个线程块的部分结果进行求和。这允许进行更细粒度的工作分解,从而提高性能。更多关于分割 K 的细节可以在我们的 arXiv 论文中找到。
经过仔细调整其他相关超参数,如瓦片大小、线程束数量和管道阶段数量,以适应 Llama3-70B 问题规模,我们能够将 Triton 基础实现的速度提升至 1.94 倍。有关超参数调整的更全面介绍,请参阅我们的博客。
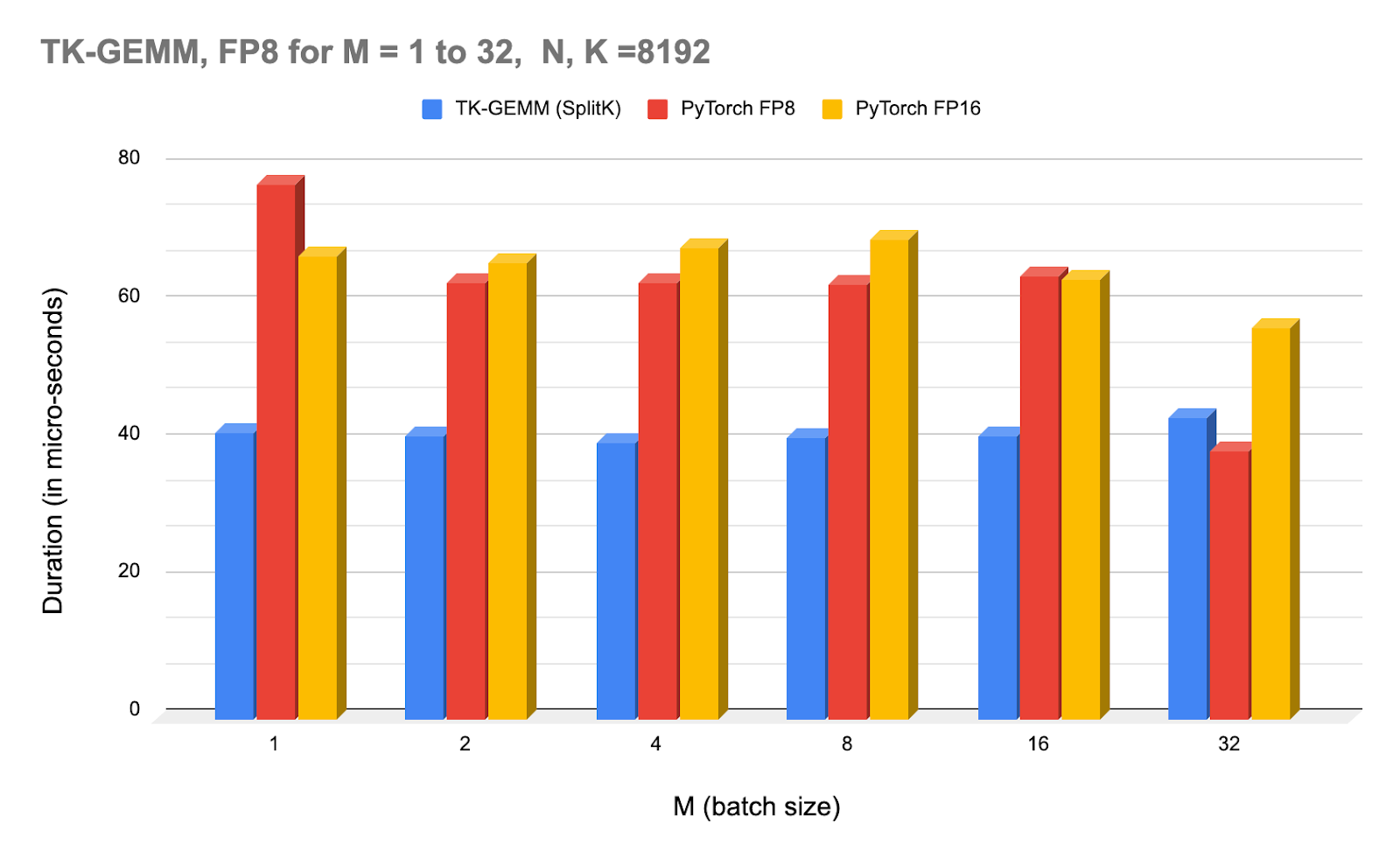
上图:TK-GEMM 在不同批处理大小下的 NCU 分析器时间,以及与 PyTorch(调用 cuBLAS)的 FP8 和 FP16 的比较。
注意,从 M=32 开始,cuBLAS FP8 内核开始优于 TK-GEMM。对于 M >= 32,我们怀疑我们找到的超参数并非最佳,因此需要另一组实验来确定中等规模 M 的最佳参数。
5.0 CUDA 图以实现端到端加速
为了在端到端环境中实现这些加速,我们必须同时考虑内核执行时间(GPU 持续时间)以及墙时间(CPU+GPU 持续时间)。与 torch 编译生成的内核相比,手写的 Triton 内核众所周知存在高内核启动延迟。如果我们使用 torch profiler 来跟踪 TK-GEMM 内核,我们可以在 CPU 端看到调用堆栈,从而精确地找出导致减速的原因。
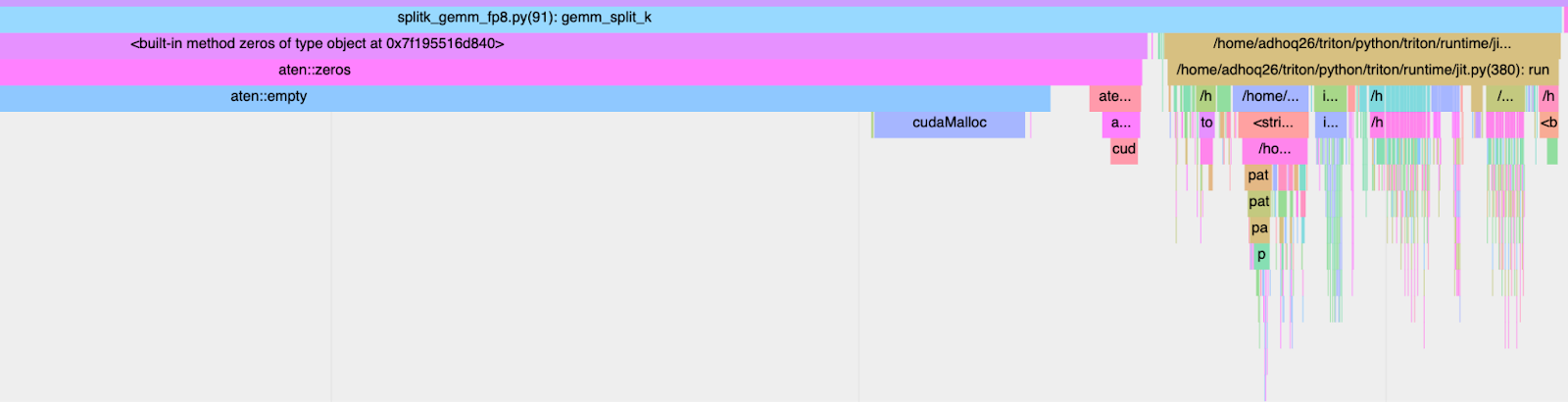
图 5. CPU 启动开销:2.413ms
从上面的分析中,我们可以看到我们优化后的内核的墙时间主要被 JIT(即时)编译开销所占据。为了解决这个问题,我们可以使用 CUDA 图。
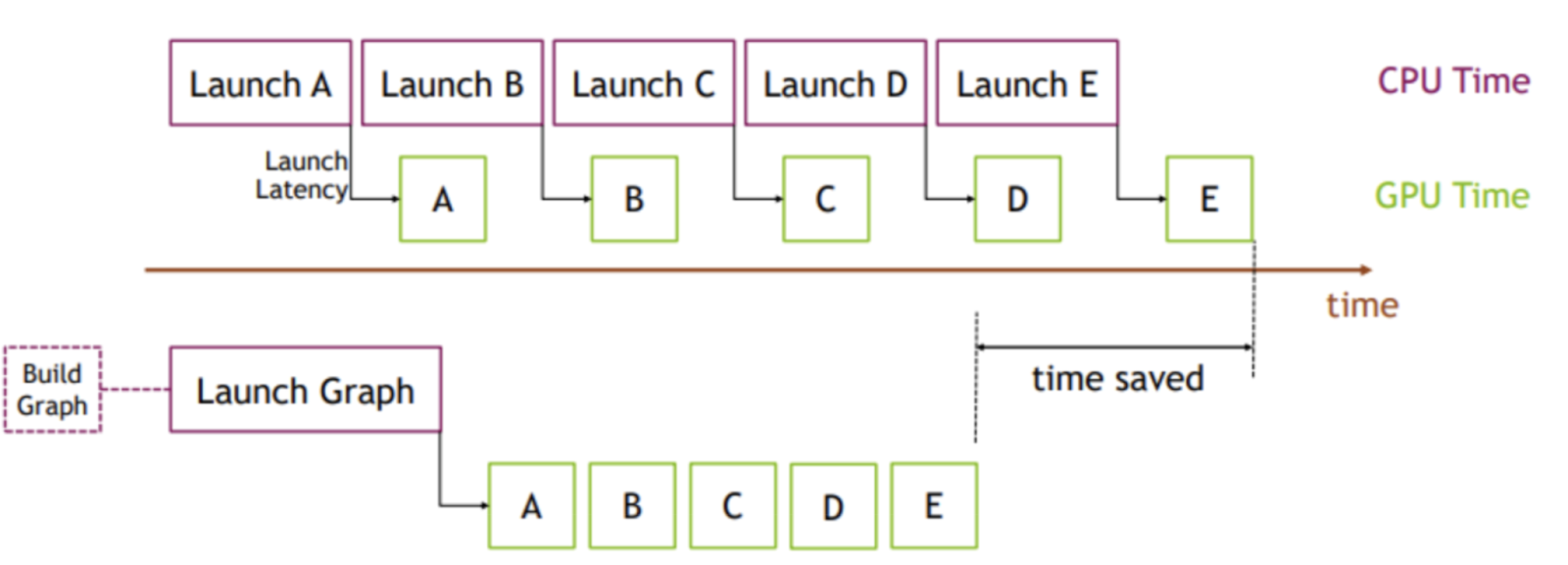
图 6. CUDA 图可视化
图像来源:PyTorch
关键思想是,我们不是进行多次内核启动,而是创建并实例化一个图(1 次成本),然后提交该图的实例进行执行。为了说明这一点,我们模拟了一个 Llama3-70B 注意力层,如图所示,使用 nsight systems 生成的以下图,每次 GEMM 之间的时间间隔为 165us,而实际的矩阵乘法由于 CPU 内核启动开销花费了 12us。这意味着在注意力层中,GPU 有 92%的时间处于空闲状态,没有进行任何工作。
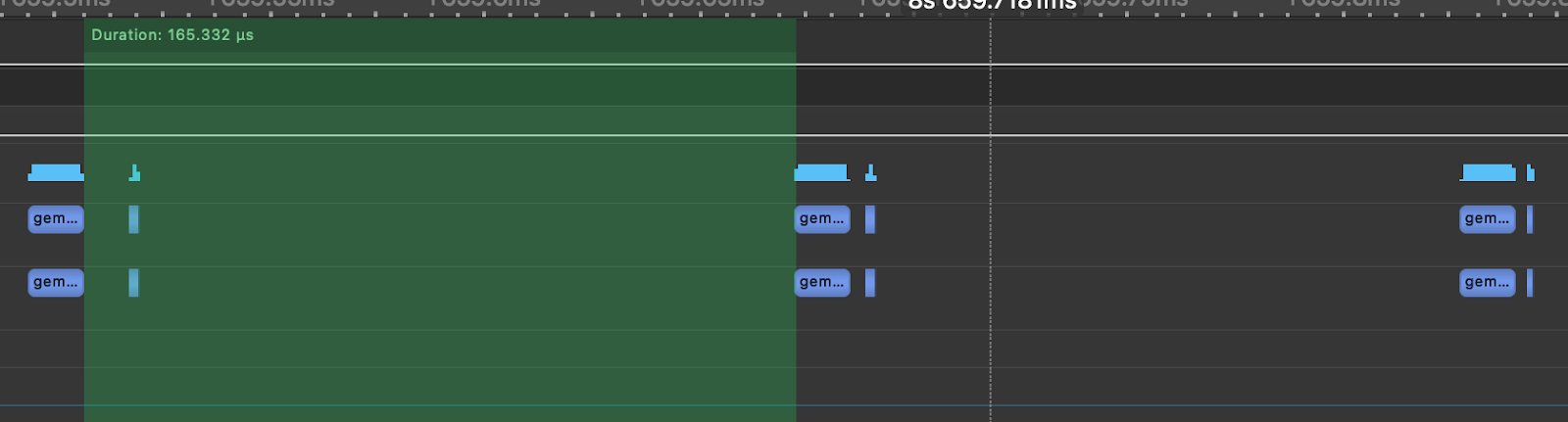
图 7. 模拟的 Llama3-70B 注意力层与 TK-GEMM
为了展示 CUDA 图的影响,我们随后在玩具注意力层中创建了一个 TK-GEMM 内核的图,并回放了该图。下面我们可以看到,内核执行之间的间隔减少到了 6.65us。
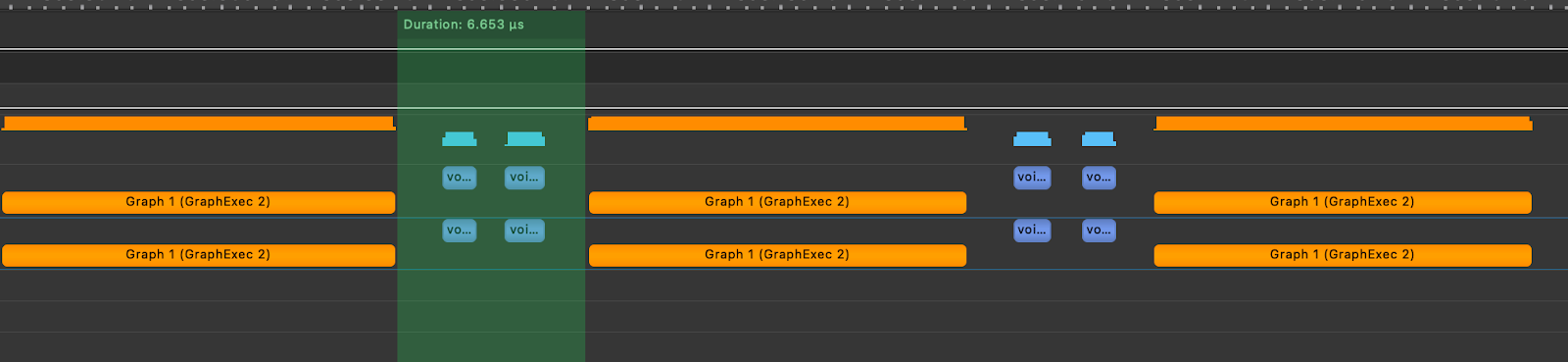
图 8.使用 TK-GEMM 和 CUDA 图模拟的 Llama3-70B 注意力层
实际上,这种优化将使 Llama3-70B 中单个注意力层的速度提高 6.4 倍,超过在无 CUDA 图模型中天真地使用 TK-GEMM
6.0 未来潜在优化路径
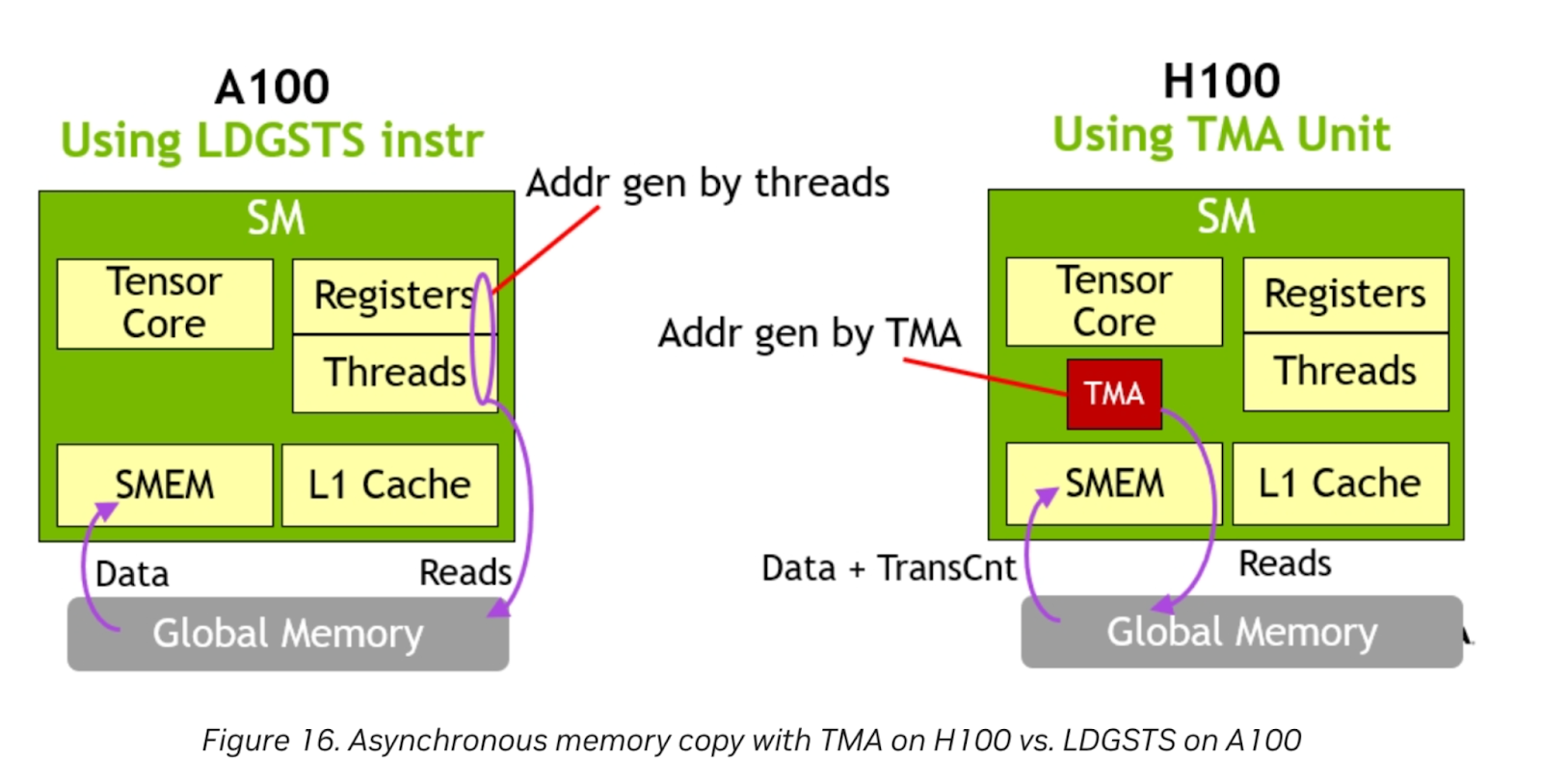
图 9. TMA 硬件单元
图像来源:Nvidia
Nvidia H100 搭载了 TMA 硬件单元。专门的 TMA 单元释放了寄存器和线程以执行其他工作,因为地址生成完全由 TMA 处理。对于内存受限的问题规模,当 Triton 启用对此功能的支持时,这可以提供更大的收益。
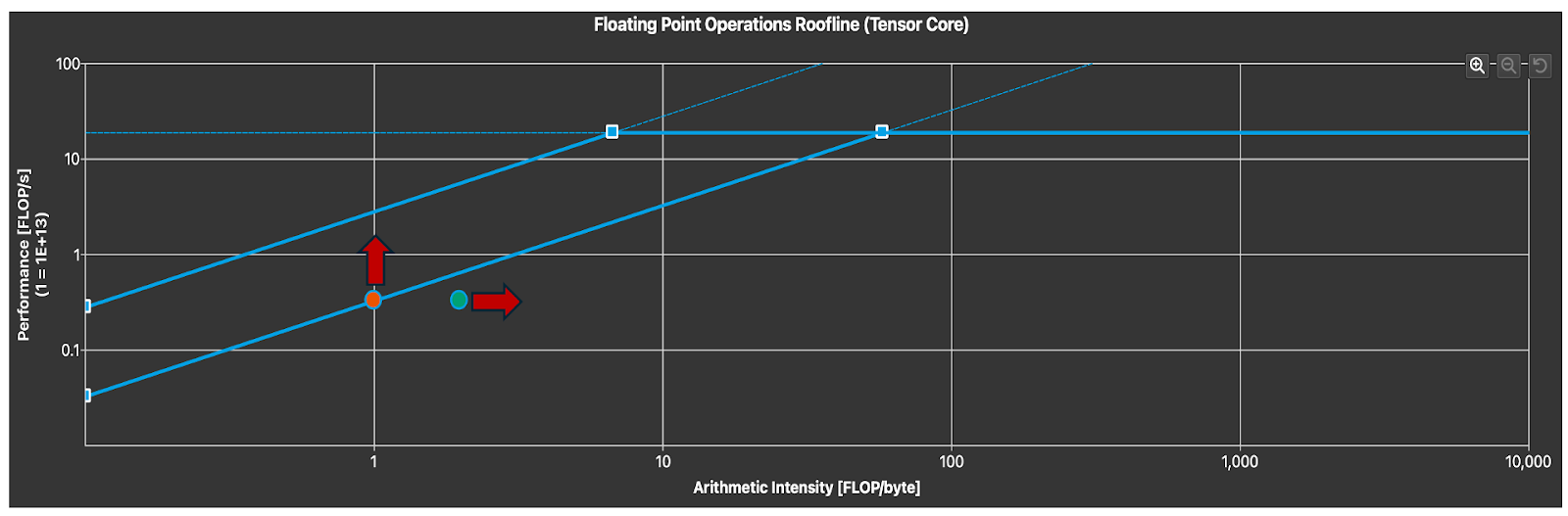
图 10. 张量核心利用率(箭头表示自由度)
为了了解我们如何有效地利用张量核心,我们可以分析屋顶线图。注意,对于小的 M,我们处于预期的内存受限区域。为了提高内核延迟,我们可以通过增加算术强度来提高内核延迟,这可以通过利用数据局部性和其他循环优化或增加内存吞吐量来实现。这需要更优化的并行算法,该算法专门针对 FP8 数据类型以及我们预期在 FP8 推理中看到的问题规模特征。
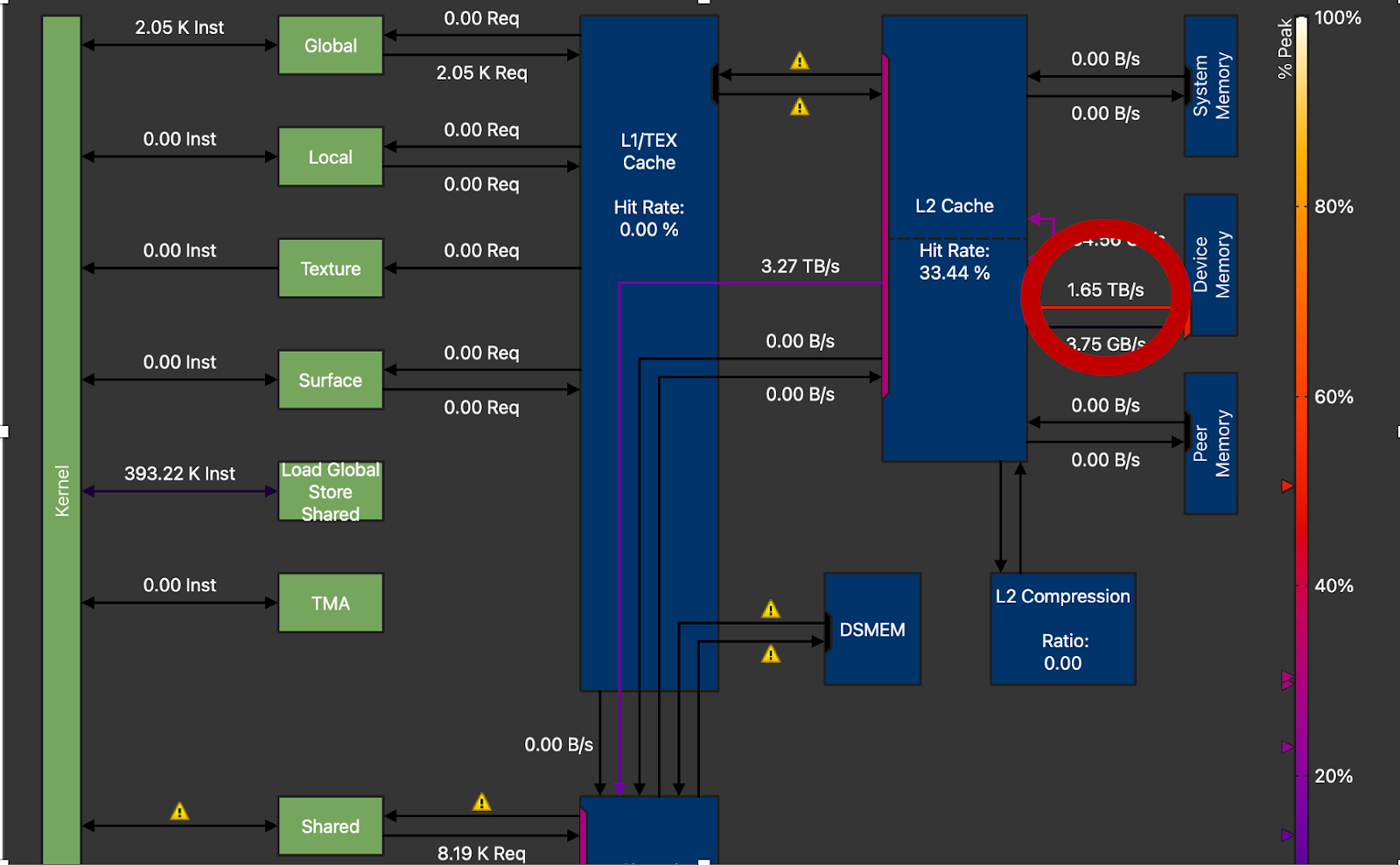
图 11. DRAM 吞吐量圈出,H100 上的 1.65TB/s 峰值与 3.35TB/s 峰值(M=16,N=8192,K=8192)
最后,我们可以看到,我们在 NVIDIA H100 上仅实现了约 50%的 DRAM 峰值吞吐量。高性能 GEMM 内核通常能实现约 70-80%的峰值吞吐量。这意味着仍有很大的提升空间,上述提到的技术(循环展开、优化并行化)需要进一步改进以获得额外收益。
7.0 未来工作
对于未来的研究,我们希望探索 CUTLASS 3.x 和 CuTe,以利用对 Hopper 特性的更直接控制,特别是在获得直接 TMA 控制和探索 pingpong 架构方面,这些架构在 FP8 GEMM 方面已显示出有希望的结果。