本文是关于如何使用纯原生 PyTorch 加速生成式 AI 模型的博客系列第四部分。如需查看代码,请访问我们的 GitHub(seamless_communication, fairseq2)。我们很高兴与大家分享一系列新发布的 PyTorch 性能特性以及实际示例,以展示我们可以将 PyTorch 原生性能提升到何种程度。在第一部分中,我们展示了如何仅使用纯原生 PyTorch 将 Segment Anything 加速 8 倍。在第二部分中,我们展示了如何仅使用原生 PyTorch 优化将 Llama-7B 加速近 10 倍。在第三部分中,我们展示了如何仅使用原生 PyTorch 优化将文本到图像扩散模型加速至 3 倍。
在本博客中,我们将关注如何通过使用 CUDA Graph 和原生 PyTorch 优化来加速 FAIR 的 Seamless M4T-v2 模型,从而实现文本解码模块 2 倍速度提升和声码器模块 30 倍速度提升,最终端到端推理速度提升 2.7 倍,且不损失精度:
引言
无缝 M4T 是 FAIR 开发的开源基础语音/文本翻译和转录技术。无缝 M4T 是一个大规模多语言和多模态机器翻译模型,最新版本(Seamless M4T-v2)于 2023 年 11 月 30 日发布。Seamless M4T-v2 的高级模型架构如图 1 所示。
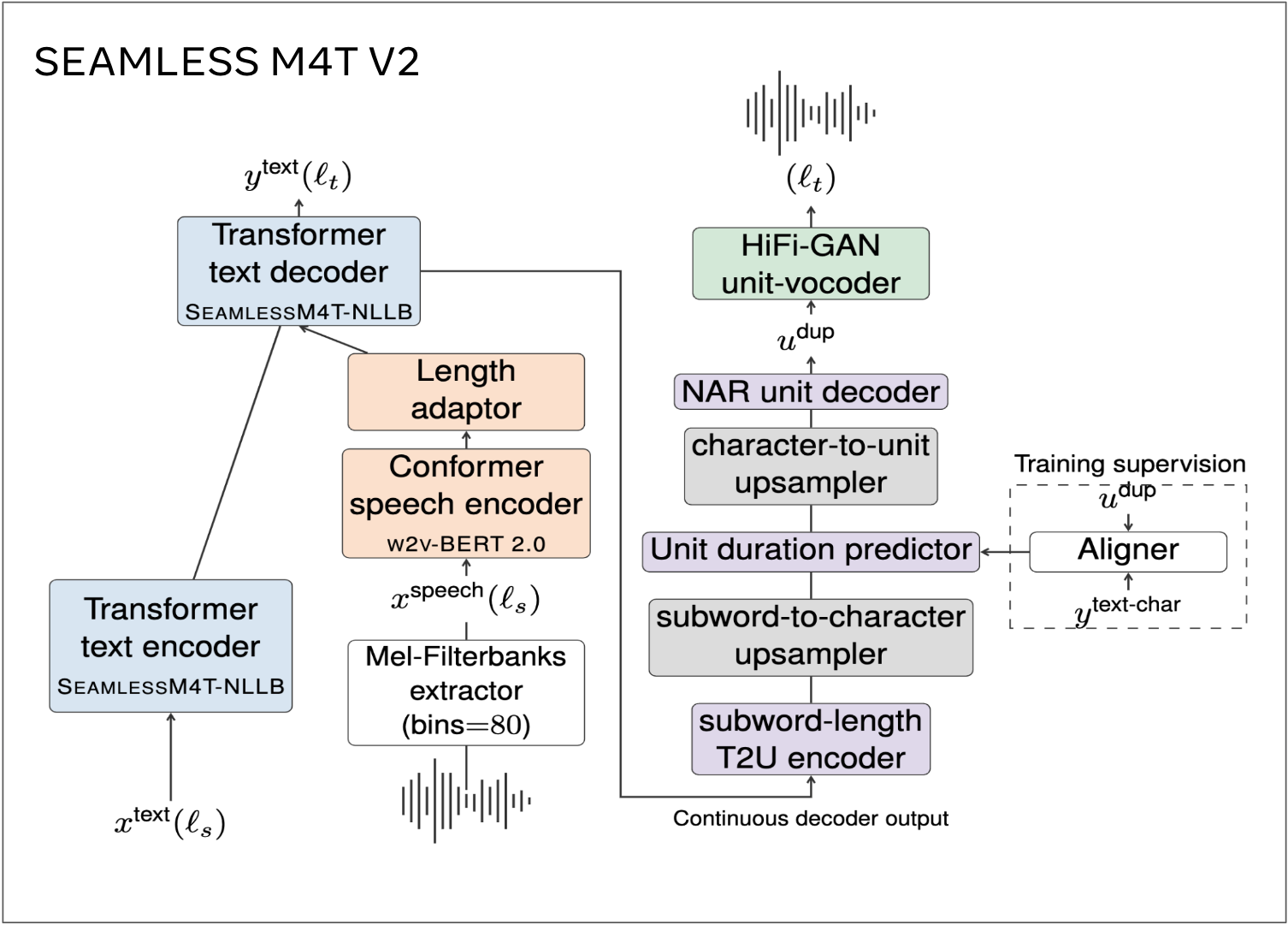
图 1. Seamless M4T-v2 模型架构。
加速推理延迟对于翻译模型来说至关重要,可以通过更快的跨语言通信来提升用户体验。特别是,在聊天机器人、语音翻译和实时字幕等应用中,latency 至关重要,因此我们针对 batch_size=1 的推理性能进行了分析,如图 2 所示,以了解 Amdahl 定律的瓶颈。我们的结果表明,文本解码器和声码器是最耗时的模块,分别占推理时间的 61%和 23%。
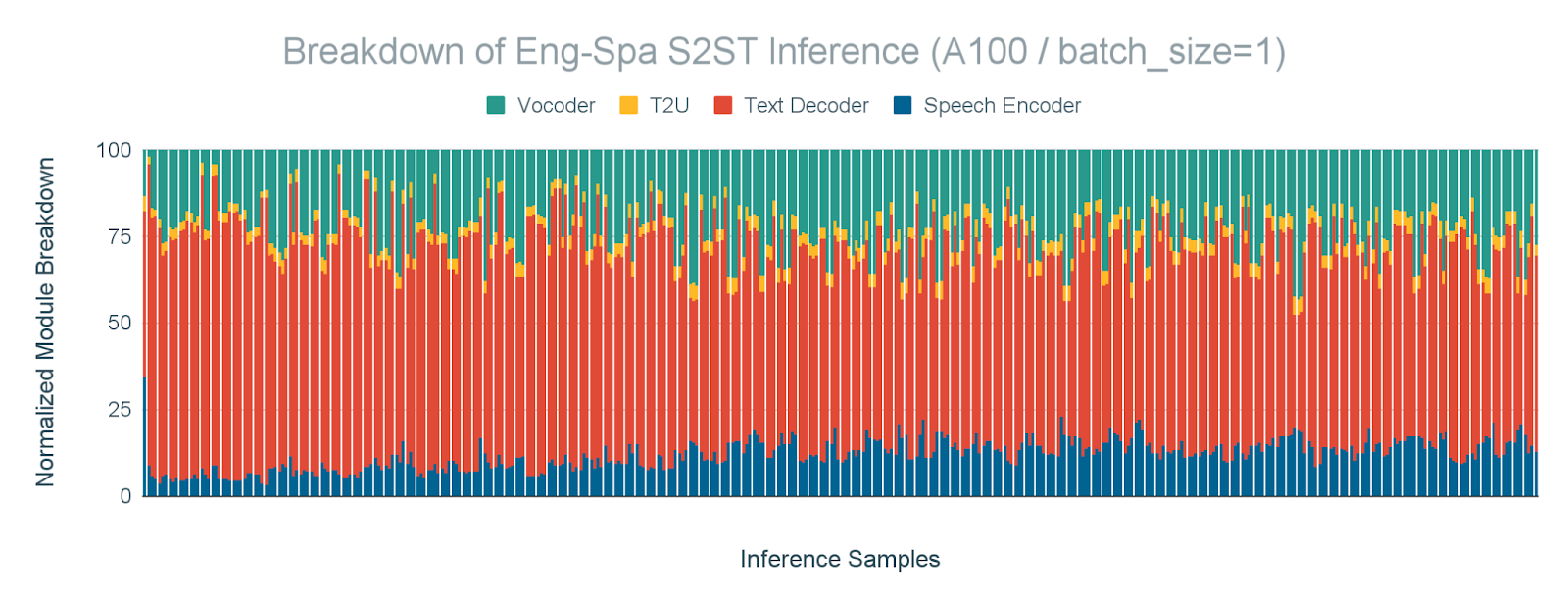
图 2. 文本解码器和声码器是最耗时的模块。在 A100 GPU 上,对于 batch_size=1 的英语-西班牙语 S2ST(语音到语音文本)任务,按模块分解推理时间。
为了更详细地了解文本解码器和声码器的性能瓶颈,我们分析了 FLEURS 数据集中英语-西班牙语翻译示例的第 8 个样本的文本解码器和声码器的 GPU 跟踪信息,如图 3 所示。这揭示了文本解码器和声码器是高度 CPU 密集型的模块。我们观察到由于 CPU 开销导致的显著差距,延迟了 GPU 内核的启动,导致这两个模块的执行时间大幅增加。
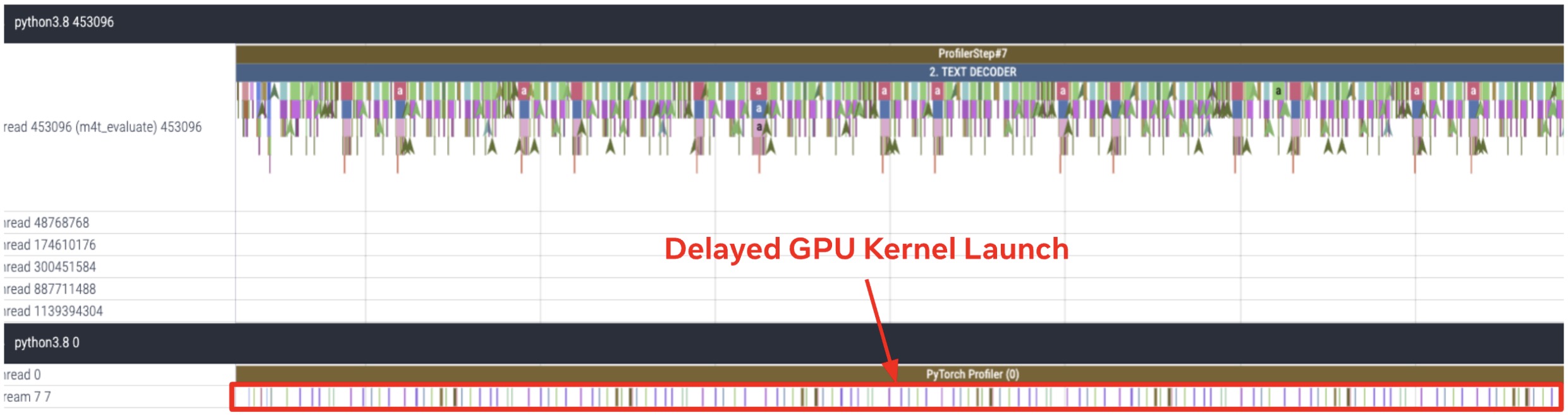
(a) 文本解码器的 CPU 和 GPU 跟踪
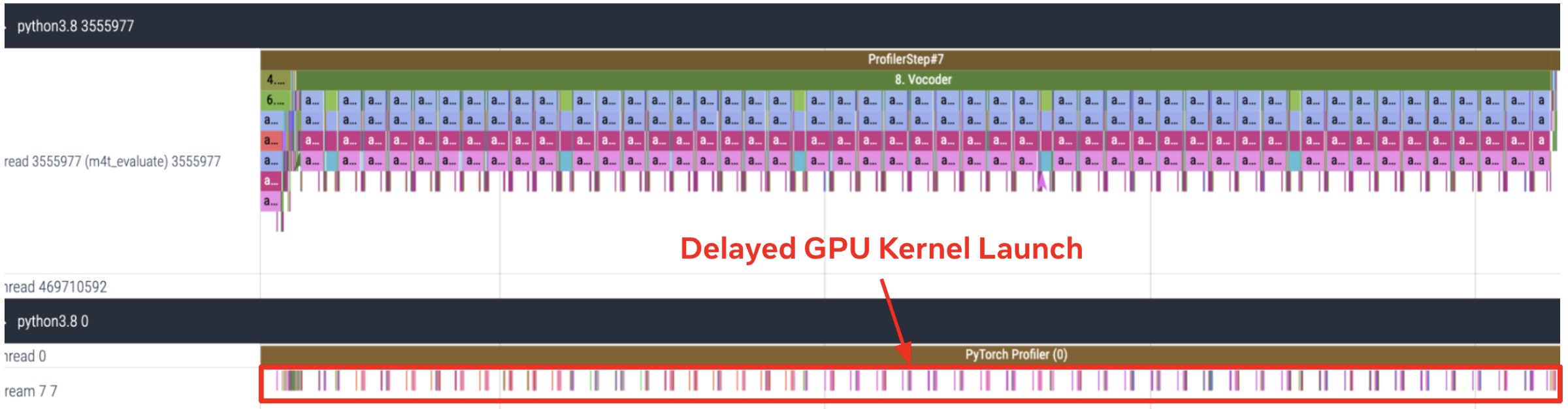
(b) 声码器的 CPU 和 GPU 跟踪
图 3. 文本解码器和声码器是高度 CPU 密集型模块。以 FLEURS 数据集的英语-西班牙语翻译示例中的第 8 个样本为对象,对文本解码器(a)和声码器(b)进行了 CPU 和 GPU 跟踪。跟踪是通过在 A100 GPU 上运行 batch_size=1 的推理获得的。
基于 Seamless M4T-v2 中真实系统性能分析结果,文本解码器和声码器是高度 CPU 密集型模块,我们为这些模块启用了 torch.compile + CUDA Graph。在此文章中,我们分享了为 batch_size=1 推理场景启用 torch.compile + CUDA Graph 所需的修改、CUDA Graph 的讨论以及下一步计划。
Torch.compile with CUDA Graph
torch.compile 是一个 PyTorch API,允许用户将 PyTorch 模型编译成独立的可执行文件或脚本,通常用于通过删除不必要的开销来优化模型性能。
CUDA Graph 是 NVIDIA 提供的一项功能,它允许优化 CUDA 应用程序中的内核启动。它创建了一个 CUDA 内核的执行图,该图可以在执行在 GPU 上之前由驱动程序进行预处理和优化。使用 CUDA Graph 的主要优势是它减少了与启动单个内核相关的开销,因为图可以作为单个单元启动,从而减少了主机和设备之间的 API 调用和数据传输次数。这可以导致显著的性能提升,特别是对于具有大量小型内核或多次重复相同内核集的应用程序。如果您想了解更多关于这方面的信息,请查看这篇强调数据在加速计算中重要作用的论文:数据在哪里?为什么没有我们自己的 Kim Hazelwood 的回答,您就不能辩论 CPU 与 GPU 的性能!这是 NVIDIA 在大力投资通用 GPU(GPGPUs)的时候,以及深度学习革命化计算行业之前!
然而,由于 CUDA Graph 在编译时记录了 1)固定内存指针,2)固定形状的张量,因此我们为 CUDA Graph 引入了以下改进,以便在多个输入大小之间重用,防止每次迭代都生成 CUDA Graph,并让 CUDA Graph 内部的数据在不同运行之间重用,以共享 KV 缓存,从而在多个解码步骤中重用。
文本解码器
在 Seamless 中,文本解码器是一个从 NLLB [1]转换而来的解码器,执行 T2TT(文本到文本翻译)。此外,该模块是一个 CPU 密集型模型,由于自动回归生成的特性需要按顺序处理标记,因此 GPU 执行时间不足以隐藏 CPU 开销,这限制了在 GPU 上实现的并行度。基于这一观察,我们为文本解码器启用了 torch.compile + CUDA Graph,以减少如图 4 所示的占主导地位的 CPU 开销。
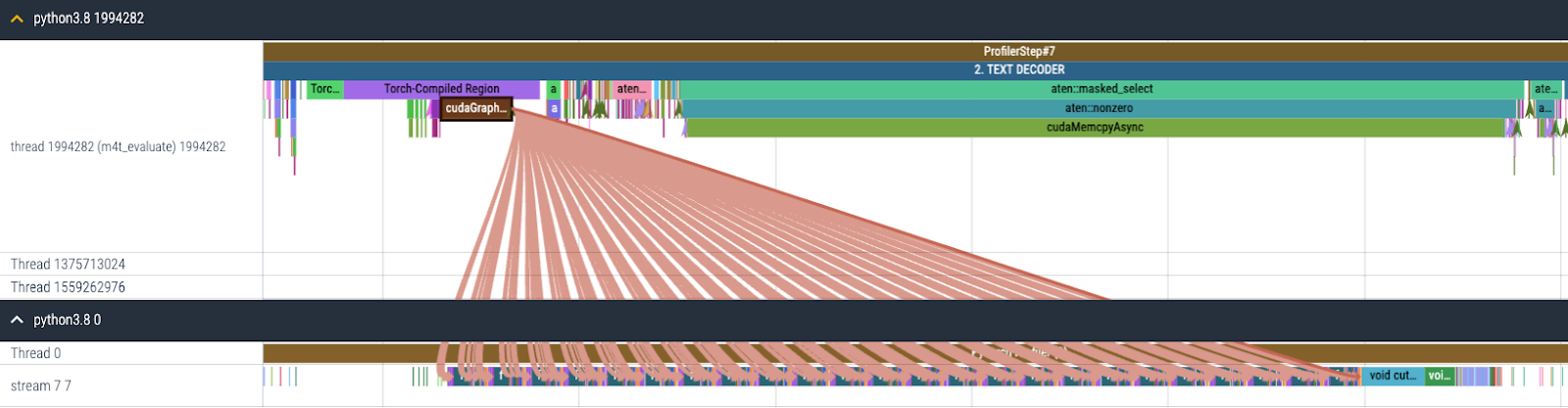
图 4.启用 torch.compile + CUDA Graph 后文本解码器的 CPU 和 GPU 跟踪
1. 更新和检索 KV 缓存
在推理过程中,文本解码器有两个计算阶段:一个预填充阶段,用于处理提示信息,以及一个增量生成阶段,逐个生成输出标记。当批量大小或输入长度足够高时,预填充会并行处理足够多的标记——GPU 性能是瓶颈,而 CPU 开销对性能的影响并不显著。另一方面,增量标记生成始终以序列长度 1 执行,并且通常以较小的批量大小(甚至 1)执行,例如用于交互式用例。因此,增量生成可能受到 CPU 速度的限制,因此是 torch.compile + CUDA Graph 的良好候选者。
然而,在增量标记生成阶段,参与注意力计算的键和值的序列长度维度在每一步都会增加一个,而查询的序列长度始终为 1。具体来说,键/值是通过将新计算的序列长度为 1 的键/值追加到迄今为止存储在 KV 缓存中的键/值来生成的。但如上所述,CUDA Graph 在编译和回放过程中记录了张量的所有形状,因此在此处出色工作的基础上,对这个问题进行的修改很少。
a) 我们修改了 KV 缓存处理,以使用 CUDA Tensor 中写入新值的索引(即, valid_seq_pos )而不是 Python 整数。
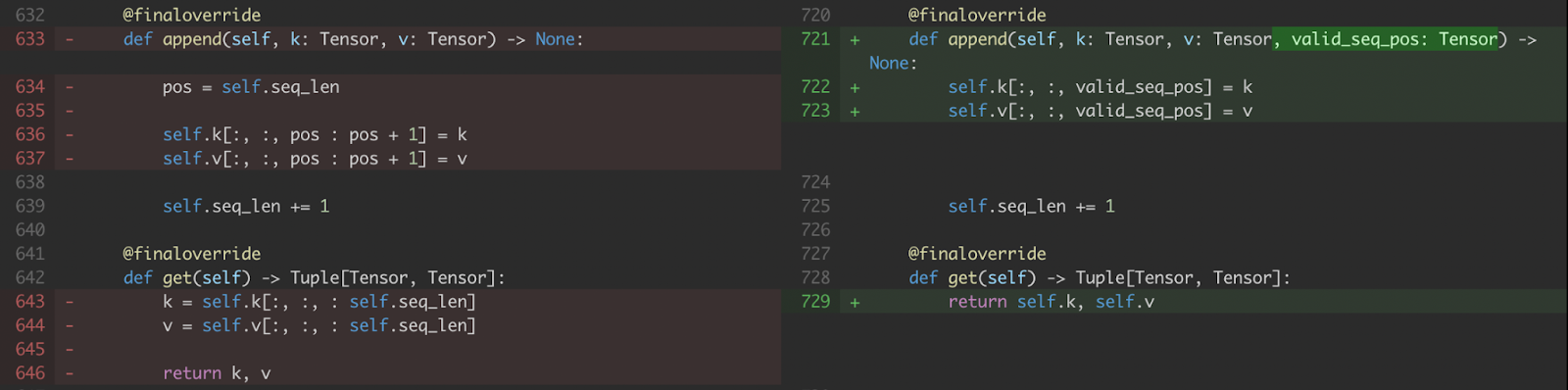
图 5. 对 KV 缓存 append 和 get 的修改
b) 我们还修改了注意力机制,使其能够与固定形状的键和值在 max_seq_length 上工作。我们只对当前解码步骤(即, valid_seq_pos )之前的序列位置进行 softmax 计算。为了屏蔽序列位置 > 当前解码步骤(即, valid_seq_pos) ),我们创建了一个布尔掩码张量(即, mask ),其中序列位置 > valid_seq_pos 被设置为 False。
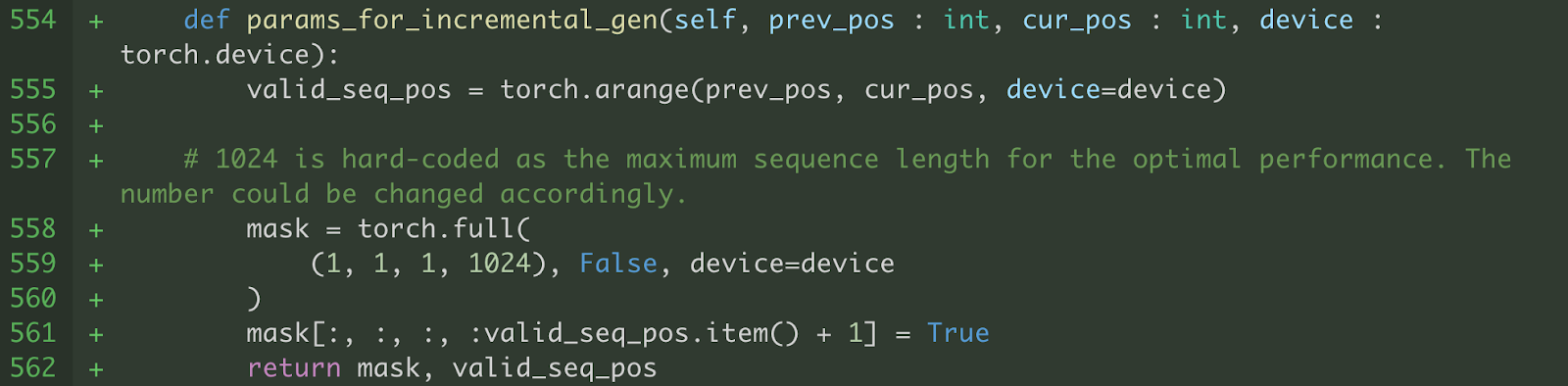
图 6.生成 valid_seq_pos 和 mask 的辅助函数
重要的是要指出,这些修改导致计算量增加,因为我们计算了比必要的更多序列位置上的注意力(多达 max_seq_length )。然而,尽管存在这一缺点,我们的结果表明,torch.compile + CUDA Graph 与标准 PyTorch 代码相比,仍然提供了显著的性能优势。
c) 由于不同的推理样本具有不同的序列长度,因此它还生成了不同形状的输入,这些输入需要投影到键和值以用于交叉注意力层。因此,我们填充输入以具有静态形状,并生成一个填充掩码来屏蔽填充输出。
2. 内存指针管理
CUDA Graph 记录张量的形状和内存指针,因此对不同的推理样本进行正确引用记录的内存指针(例如 KV 缓存)非常重要,以避免为每个推理样本编译 CUDA Graph。然而,Seamless 代码库的一些部分使不同的推理样本引用不同的内存地址,因此我们对内存影响进行了修改。
e) Seamless 采用 beam search 作为文本解码策略。在 beam search 过程中,我们需要对每个增量解码步骤的所有注意力层执行 KV 缓存重排序,以确保每个选定的 beam 都使用相应的 KV 缓存,如下代码片段所示。

图 8. beam search 解码策略的 KV 缓存重排序操作。
上述代码为新内存空间分配并覆盖了 cache_k 和 cache_v 的原内存指针。因此,我们修改了 KV 缓存重排序,使用 copy_操作符保持每个缓存的内存指针,以记录编译时的状态。

图 9. 使用 copy_ 运算符对 KV 缓存进行原地更新
f) 在按照上述方法修改代码后启用 torch.compile 和 CUDA Graph 对文本解码器进行编译,文本解码器的开销转移到 KV 缓存重排,如图 10 所示。KV 缓存重排会重复调用 index_select 96 次(假设有 24 个解码层,每个层包含两种类型的注意力层,并具有键和值的缓存)。
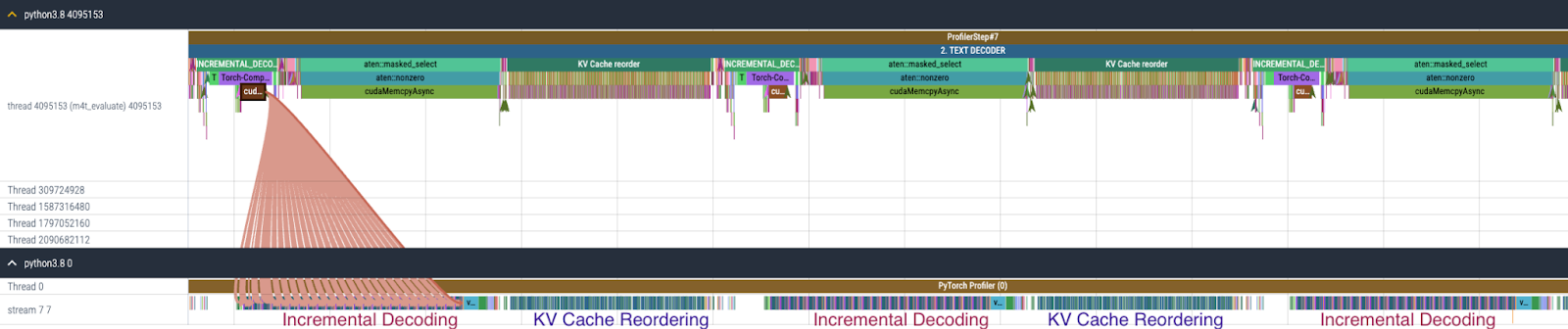
图 10. 启用 torch.compile + CUDA Graph 后文本解码器的 CPU 和 GPU 跟踪
作为加速文本解码器的一部分,我们还对 KV 缓存重排应用了 torch.compile,以利用如图 11 所示的内核融合。请注意,在这里不能使用 CUDA Graph( mode='max-autotune' ),因为 copy_ 操作修改了输入,违反了 torch.compile 中 CUDA graph 版本静态输入的要求。
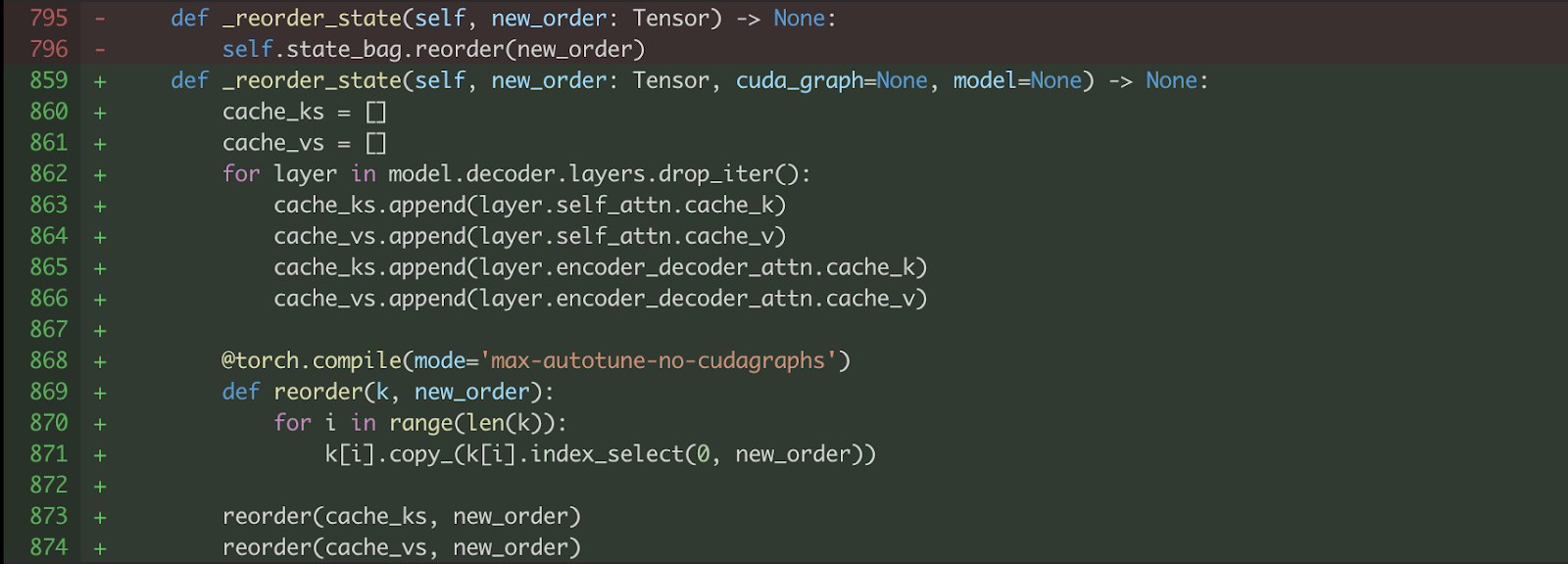
图 11. 应用 torch.compile 到 KV 缓存重排
启用 torch.compile 到 KV 缓存重排后,原本分别启动的 gpu 内核(图 12(a))现在被融合,因此需要启动的 gpu 内核数量大大减少(图 12(b))。
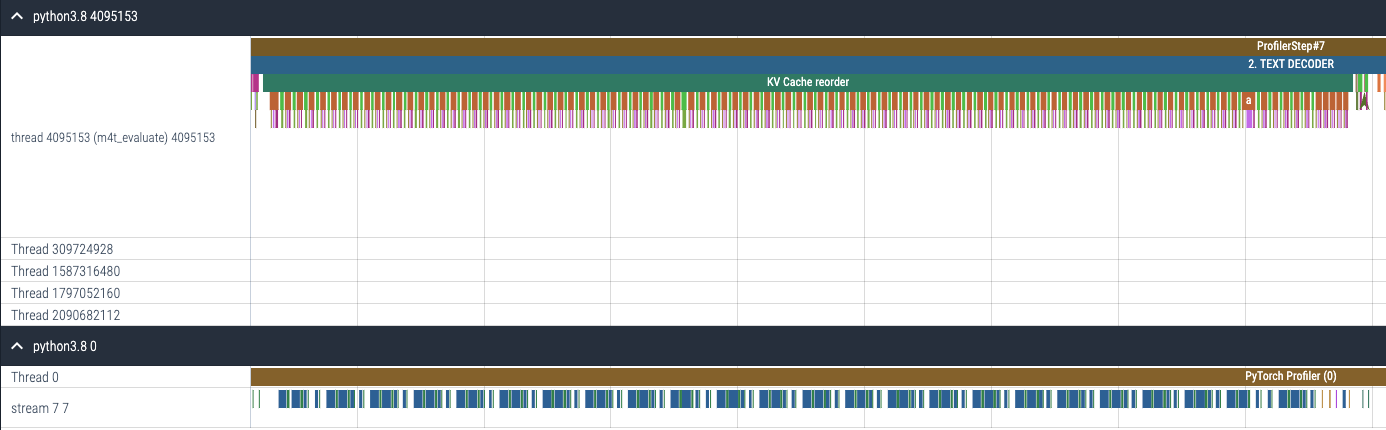
(a) 启用 torch.compile 前 KV 缓存重排的 CPU 和 GPU 追踪
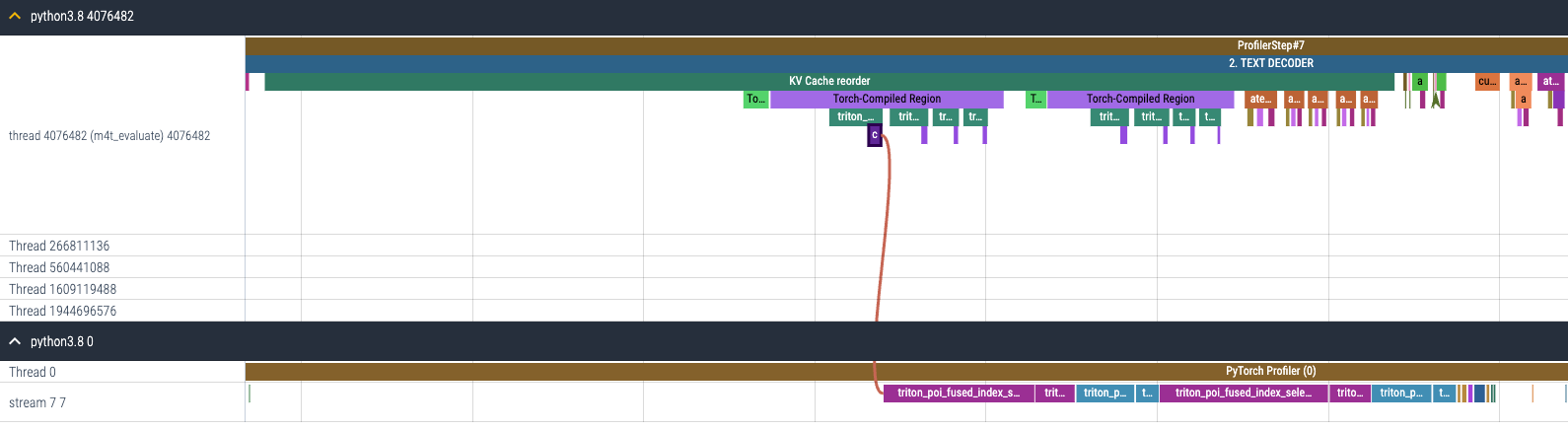
(b) 启用 torch.compile 后 KV 缓存重排的 CPU 和 GPU 追踪
图 12.启用 torch.compile 前后 KV 缓存重排的 CPU 和 GPU 追踪(a)前和(b)后
语音合成器
在 Seamless 中,语音合成器是一个 HiFi-GAN 单元语音合成器,它将生成的单元转换为波形输出,其中单元是语音的一种表示,它结合了不同的方面,如音素和音节,可以用来生成人类可听到的声音。语音合成器是一个相对简单的模块,由 Conv1d 和 ConvTranspose1d 层组成,如图 3 所示,是一个 CPU 密集型模块。基于这一观察,我们决定为语音合成器启用 torch.compile 和 CUDA Graph,以减少如图 10 所示的过大 CPU 开销。但需要进行一些修复。

图 13.启用 torch.compile + CUDA Graph 后语音合成器的 CPU 和 GPU 追踪
a) 语音合成器的输入张量形状在不同推理样本中不同。但是,由于 CUDA Graph 记录张量的形状并回放它们,我们不得不使用零填充将输入填充到固定大小。由于语音合成器只由 Conv1d 层组成,我们不需要额外的填充掩码,使用零填充就足够了。
b) 语音合成器由 conv1d 层包裹着 torch.nn.utils.weight_norm (见此处)。然而,直接将 torch.compile 应用于 Vocoder 会导致图断裂,如下所示,这会导致性能提升不佳。这种图断裂发生在处理 weight_norm 的 PyTorch 代码的钩子部分中。
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] Graph break: setattr(UserDefinedObjectVariable) <function Module.__setattr__ at 0x7fac8f483c10> from user code at:
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/mnt/fsx-home/yejinlee/yejinlee/seamless_communication/src/seamless_communication/models/vocoder/vocoder.py", line 49, in forward
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] return self.code_generator(x, dur_prediction) # type: ignore[no-any-return]1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/data/home/yejinlee/mambaforge/envs/fairseq2_12.1/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1520, in _call_impl
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] return forward_call(*args, **kwargs)
[2023-12-13 04:26:16,822] [1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/mnt/fsx-home/yejinlee/yejinlee/seamless_communication/src/seamless_communication/models/vocoder/codehifigan.py", line 101, in forward
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] return super().forward(x)
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/mnt/fsx-home/yejinlee/yejinlee/seamless_communication/src/seamless_communication/models/vocoder/hifigan.py", line 185, in forward
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] x = self.ups[i](x)
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/data/home/yejinlee/mambaforge/envs/fairseq2_12.1/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1550, in _call_impl
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] args_result = hook(self, args)
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/data/home/yejinlee/mambaforge/envs/fairseq2_12.1/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py", line 65, in __call__
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] setattr(module, self.name, self.compute_weight(module))
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG]
由于层权重在推理过程中不会改变,我们不需要权重归一化。因此,我们简单地移除了 Vocoder 的权重归一化,如图 14 所示,通过利用 Seamless 代码库中已提供的 remove_weight_norm 函数(此处)。

图 14. 移除 Vocoder 的 weight_norm
性能评估 + CUDA 图的影响
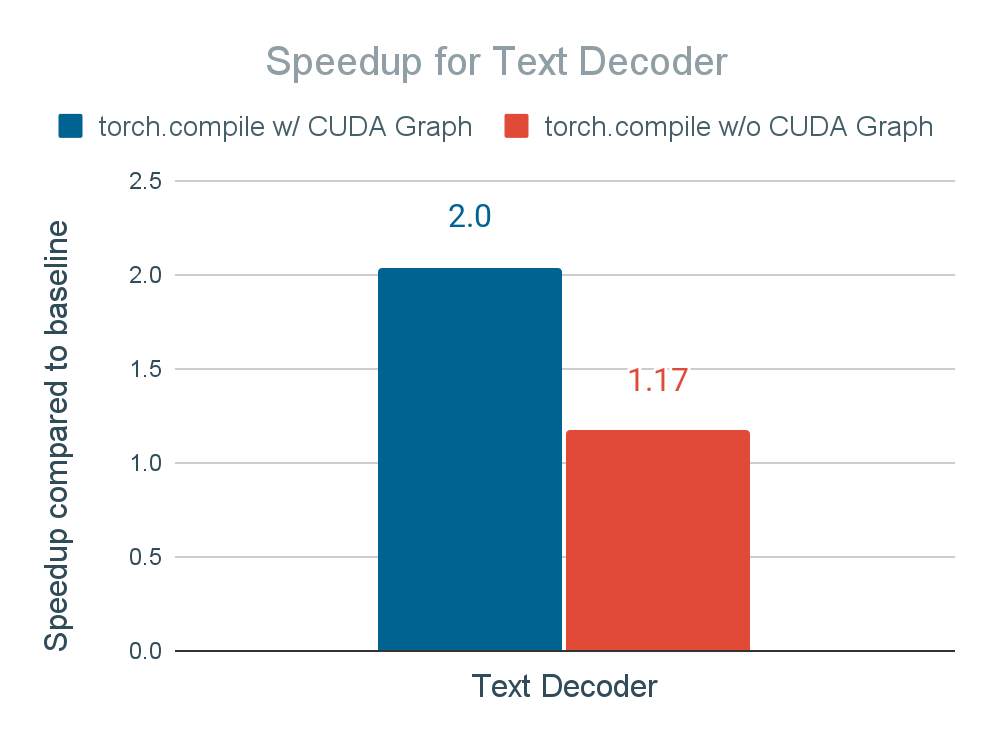
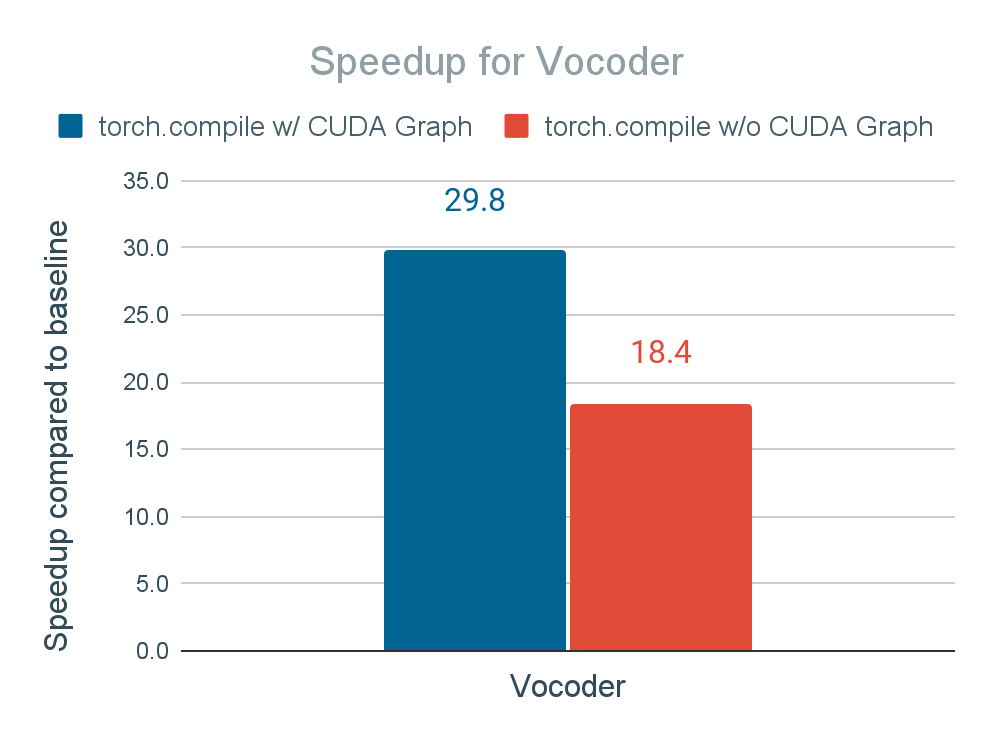
图 15 展示了启用 torch.compile(mode="max-autotune") + CUDA 图在文本解码器和语音合成器上的加速结果。我们实现了文本解码器的 2 倍加速和语音合成器的 30 倍加速,从而将端到端推理时间提高了 2.7 倍。
|
|
图 15. 应用 torch.compile 和 torch.compile + CUDA 图对文本解码器和语音合成器推理时间的加速
我们还报告了使用 torch.compile 但不使用 CUDA 图时文本解码器和语音合成器的加速情况,这由 torch.compile 的 API 支持(即, torch.compile(mode="max-autotune-no-cudagraphs") ),以确定 CUDA 图对性能的影响。没有 CUDA 图,文本解码器和语音合成器的加速降低到 1.17 倍和 18.4 倍。虽然仍然相当显著,但它表明 CUDA 图的重要作用。我们得出结论,Seamless M4T-v2 在许多情况下都暴露于大量的 CUDA 内核启动时间,尤其是在我们使用小批量(例如,1)时,GPU 内核执行时间不足以分摊 GPU 内核启动时间。
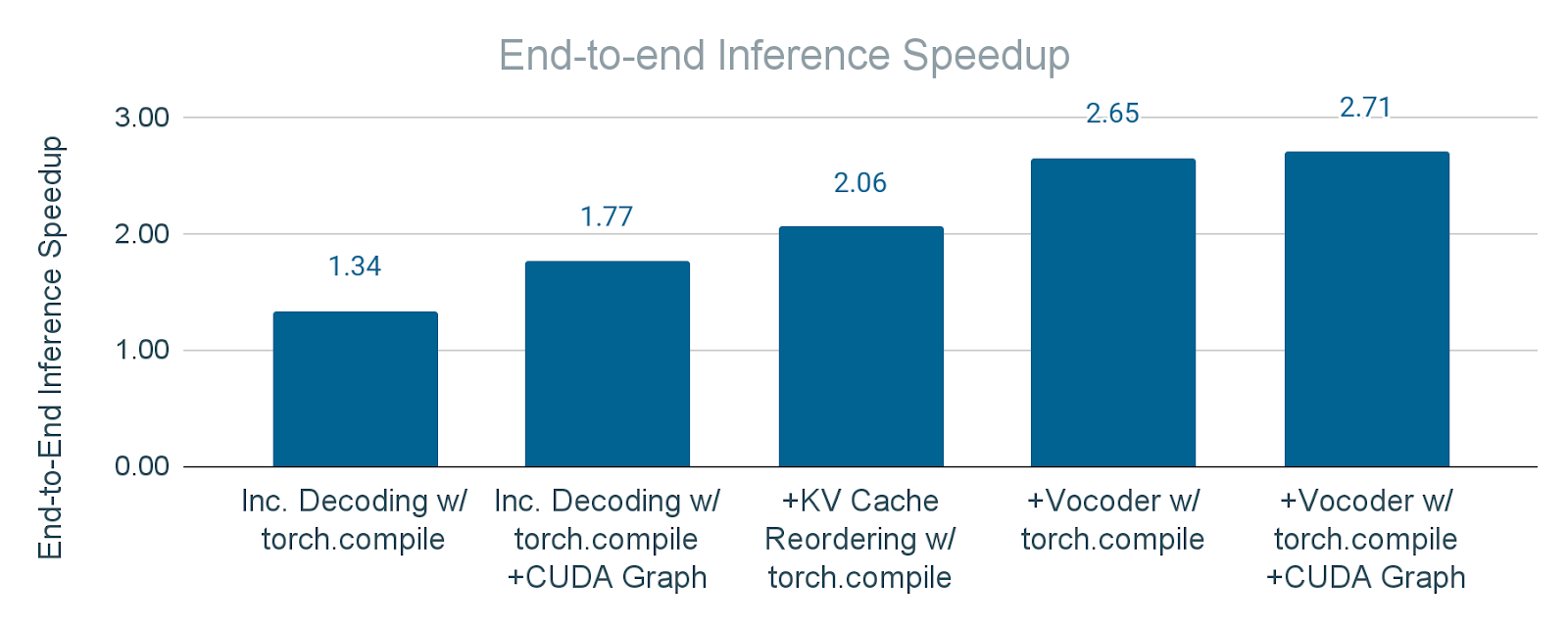
图 16.应用 torch.compile 和 CUDA 图增量方式带来的端到端推理速度提升。a) “增量解码”:仅对文本解码器应用 torch.compile b) “增量解码+CUDA 图”:对文本解码器应用 torch.compile + CUDA 图 c) “+KV 缓存重排”:在 b)的基础上,对 KV 缓存重排操作也应用 torch.compile d) “+Vocoder”:在 c)的基础上,对 Vocoder 也应用 torch.compile e) “+Vocoder+CUDA 图”:在 d)的基础上,对 Vocoder 应用 torch.compile + CUDA 图。
图 16 展示了应用 torch.compile(带 CUDA 图和不带 CUDA 图)对模块的累积影响。结果表明,端到端推理速度提升显著,证明了这些技术在优化整体延迟方面的有效性。因此,对于 batch_size=1 的 Seamless M4T-v2,我们获得了 2.7 倍的端到端推理速度提升。
致谢
我们感谢 PyTorch 团队和 Seamless 团队对我们工作的巨大支持。