这篇帖子是关于如何使用纯原生 PyTorch 加速生成式 AI 模型的系列博客的第一部分。我们很高兴与大家分享一系列新发布的 PyTorch 性能特性,以及如何将这些特性与实际示例相结合,以展示我们可以将 PyTorch 原生性能提升到何种程度。
如在 2023 年 PyTorch 开发者大会上宣布的那样,PyTorch 团队重新编写了 Meta 的 Segment Anything(“SAM”)模型,其代码速度比原始实现快 8 倍,且没有损失精度,全部使用原生 PyTorch 优化。我们利用了 PyTorch 的一系列新特性:
- Torch.compile:PyTorch 模型的编译器
- GPU 量化:通过降低精度操作加速模型
- 扩展点积注意力(SDPA):内存高效的注意力实现
- 半结构化(2:4)稀疏性:GPU 优化的稀疏内存格式
- 嵌套张量:将不同大小的数据批量合并成一个张量,例如不同尺寸的图像。
- 使用 Triton 自定义算子:使用 Triton Python DSL 编写 GPU 操作,并通过自定义算子注册轻松集成到 PyTorch 的各种组件中。
我们鼓励读者复制粘贴我们从 Github 上的 SAM 实现代码,并在 Github 上向我们提问。
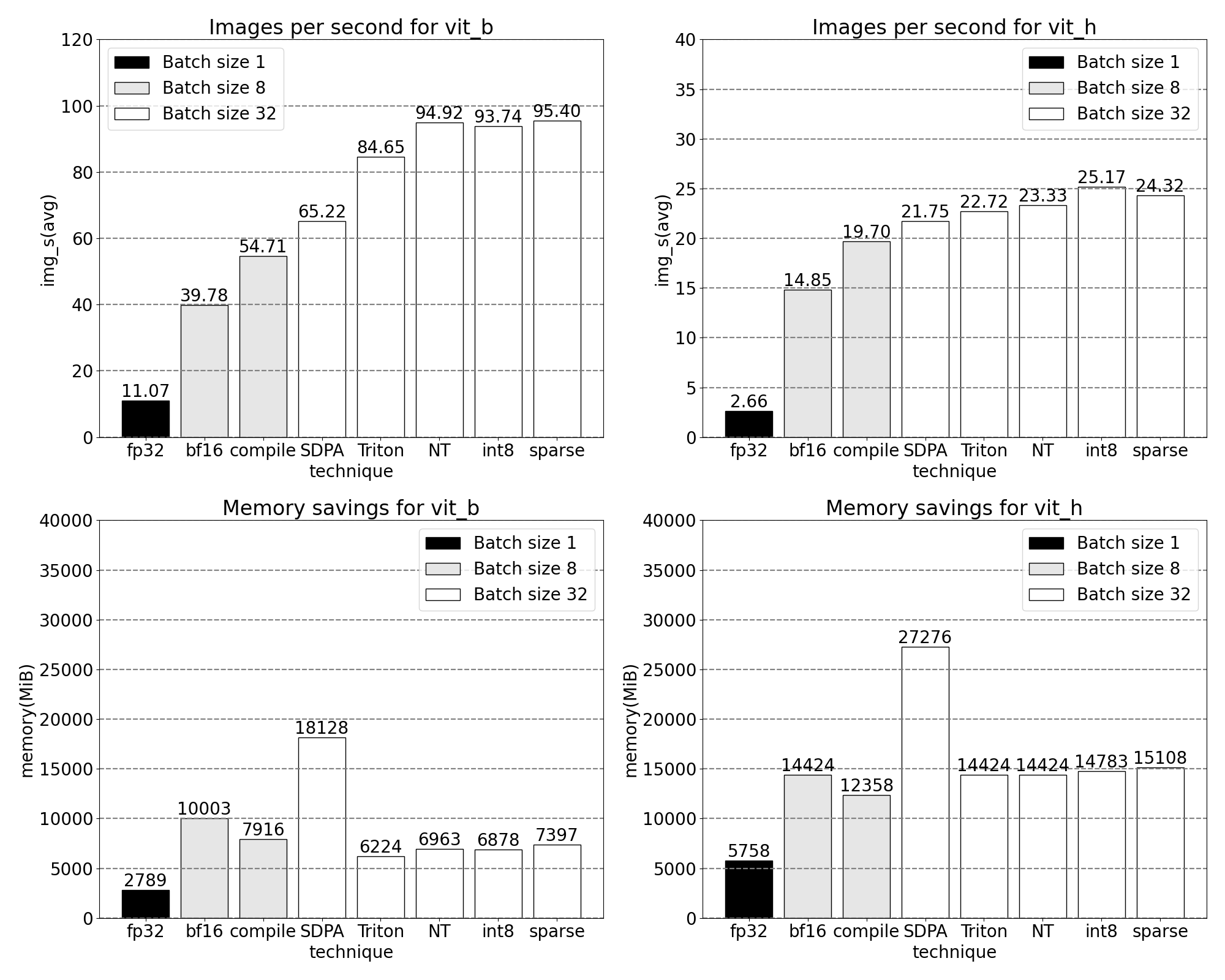
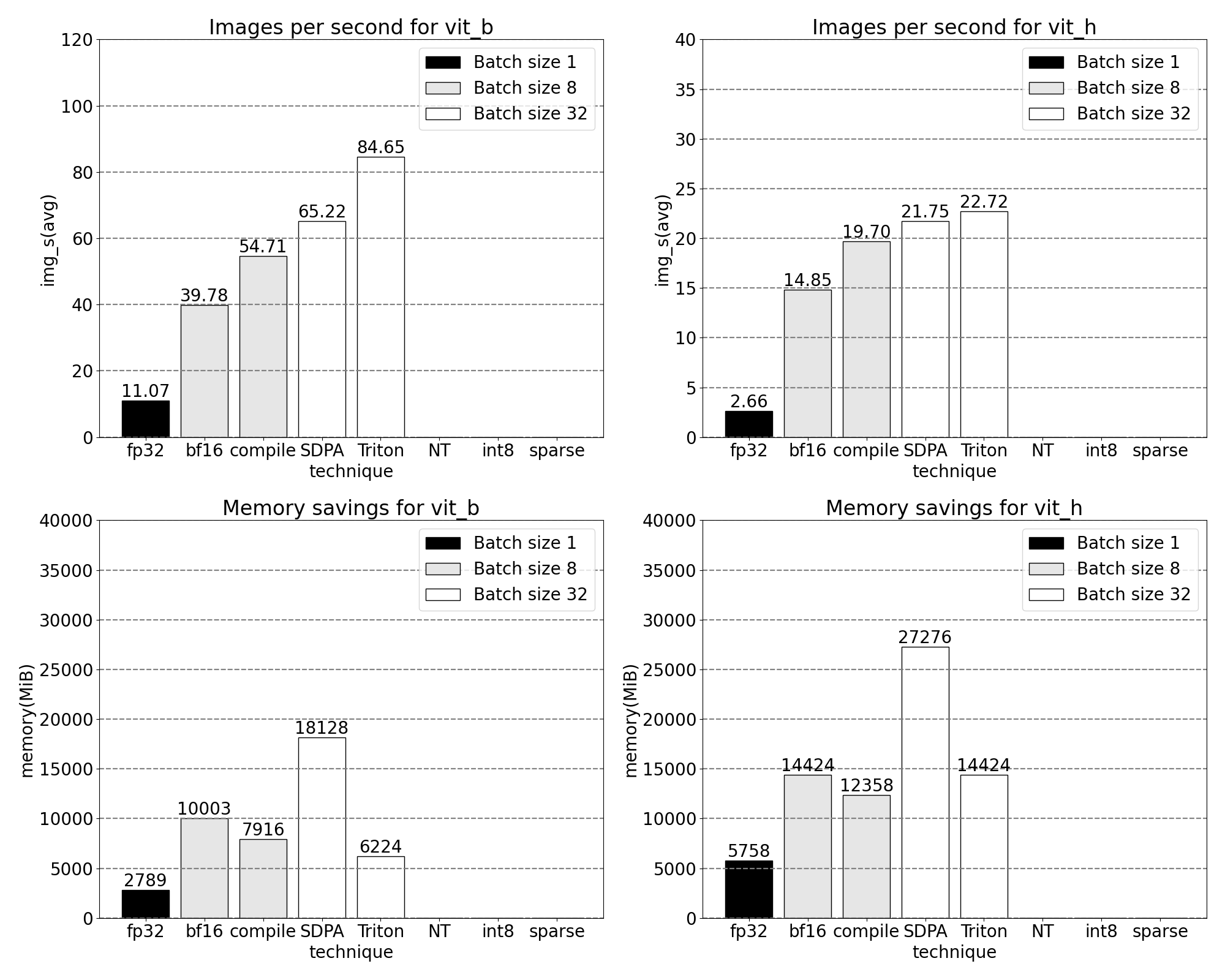
快速了解我们新发布的 PyTorch 原生功能如何提高吞吐量和降低内存开销。基准测试在 p4d.24xlarge 实例(8x A100s)上运行。
SegmentAnything 模型
SAM 是一个零样本视觉模型,用于生成可提示的图像掩码。

SAM 架构[在其论文中描述]包括基于 Transformer 架构的多个提示和图像编码器。其中,我们对最小和最大的视觉 Transformer 主干:ViT-B 和 ViT-H 进行了性能测量。为了简单起见,我们只展示了 ViT-B 模型的追踪信息。
优化
下面我们将讲述优化 SAM 的故事:分析性能、识别瓶颈,并将解决这些问题的功能构建到 PyTorch 中。在整个过程中,我们展示了我们的新 PyTorch 功能:torch.compile、SDPA、Triton 内核、嵌套张量和半结构化稀疏性。以下各节依次构建,最终以现在可在 GitHub 上找到的 SAM-fast 结束。我们使用真实的内核和内存追踪来激励每个功能,使用完全 PyTorch 本地的工具,并使用 Perfetto UI 可视化这些追踪信息。
基准
我们的 SAM 基准是 Facebook Research 未修改的模型,使用 float32 数据类型和批大小为 1。经过一些初始预热后,我们可以使用 PyTorch Profiler 查看内核追踪信息:
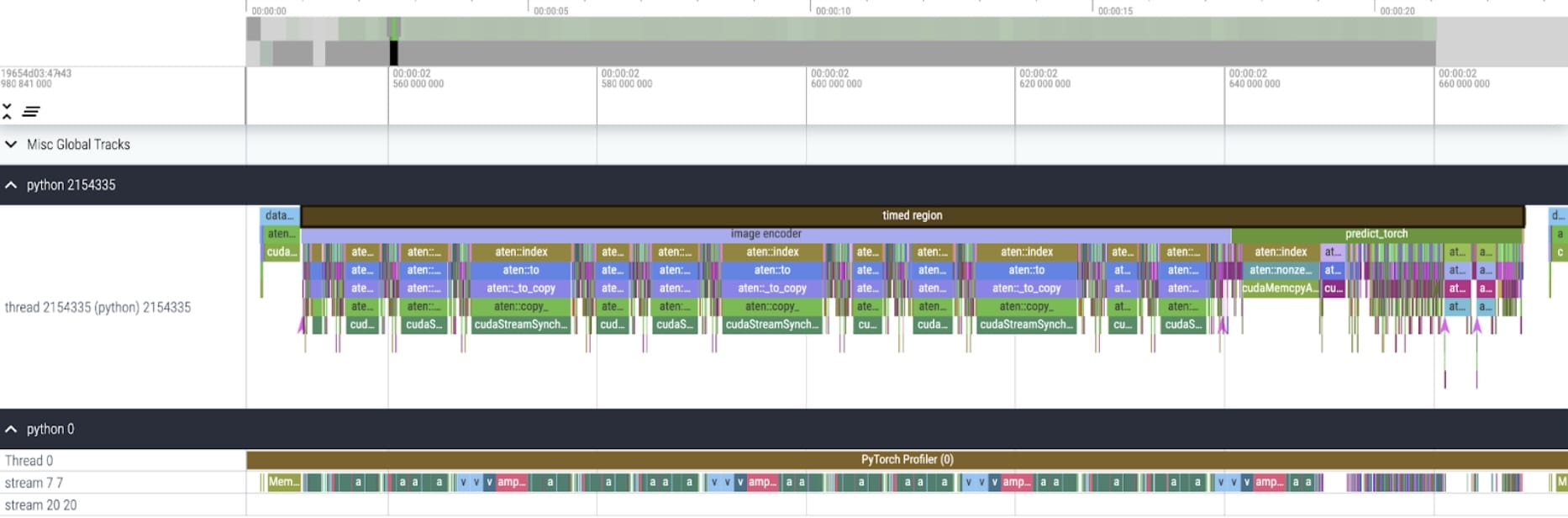
我们注意到有两个优化领域。
第一个是调用 aten::index 的长调用,这是由 Tensor 索引操作(例如 [])产生的底层调用。虽然 aten::index 实际上在 GPU 上的时间相对较低。aten::index 启动了两个内核,并且在它们之间发生了一个阻塞的 cudaStreamSynchronize。这意味着 CPU 正在等待 GPU 完成处理,直到它启动第二个内核。为了优化 SAM,我们应该旨在移除导致空闲时间的阻塞 GPU 同步。
第二个是在 GPU 上花费大量时间进行矩阵乘法(如图中流 7 7 上的深绿色)。这在 Transformer 中很常见。如果我们能减少矩阵乘法在 GPU 上花费的时间,就可以显著加快 SAM 的速度。
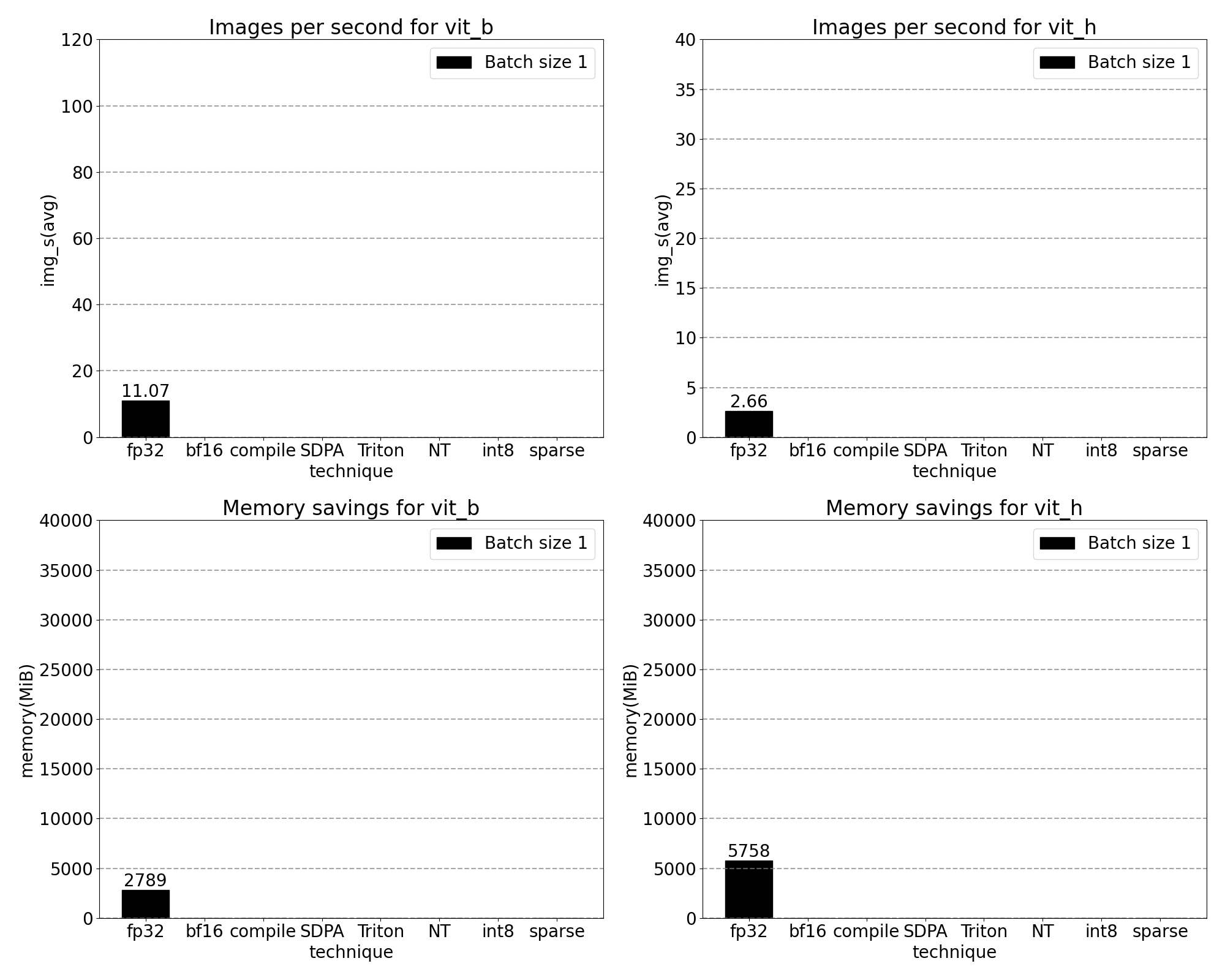
我们可以从出厂的 SAM 中测量吞吐量(img/s)和内存开销(GiB)以建立基准:
Bfloat16 半精度(+GPU 同步和批处理)
为了解决矩阵乘法耗时较少的问题,我们可以转向使用 bfloat16。Bfloat16 是一种常用的半精度类型。通过减少每个参数和激活的精度,我们可以在计算中节省大量时间和内存。在降低参数精度的同时,验证端到端模型精度至关重要。

下面是一个将填充数据类型替换为半精度、bfloat16 的示例。代码在此。
除了简单地设置 model.to(torch.bfloat16) 之外,我们还需要更改一些假设默认数据类型的少量位置。
现在,为了移除 GPU 同步,我们需要审计导致它们发生的操作。我们可以通过在 GPU 跟踪中搜索对 cudaStreamSynchronize 的调用来找到这些代码片段。实际上,我们找到了两个可以重写为无同步的地点。


具体来说,我们在 SAM 的图像编码器中看到,存在作为坐标缩放器的变量 q_coords 和 k_coords。这两个变量都在 CPU 上分配和处理。然而,一旦这些变量用于在 rel_pos_resized 中索引,索引操作会自动将这些变量移动到 GPU。这次复制导致了我们观察到的 GPU 同步。我们还注意到 SAM 的提示编码器中有一个索引的第二次调用:我们可以使用 torch.where 将其重写,如上所示。
内核跟踪
应用这些更改后,我们开始看到各个内核调用之间的显著时间间隔。这通常在小型批次大小(这里为 1)时观察到,因为启动内核的 GPU 开销。为了更仔细地查看优化领域,我们可以从对 SAM 推理进行批大小为 8 的配置文件开始:
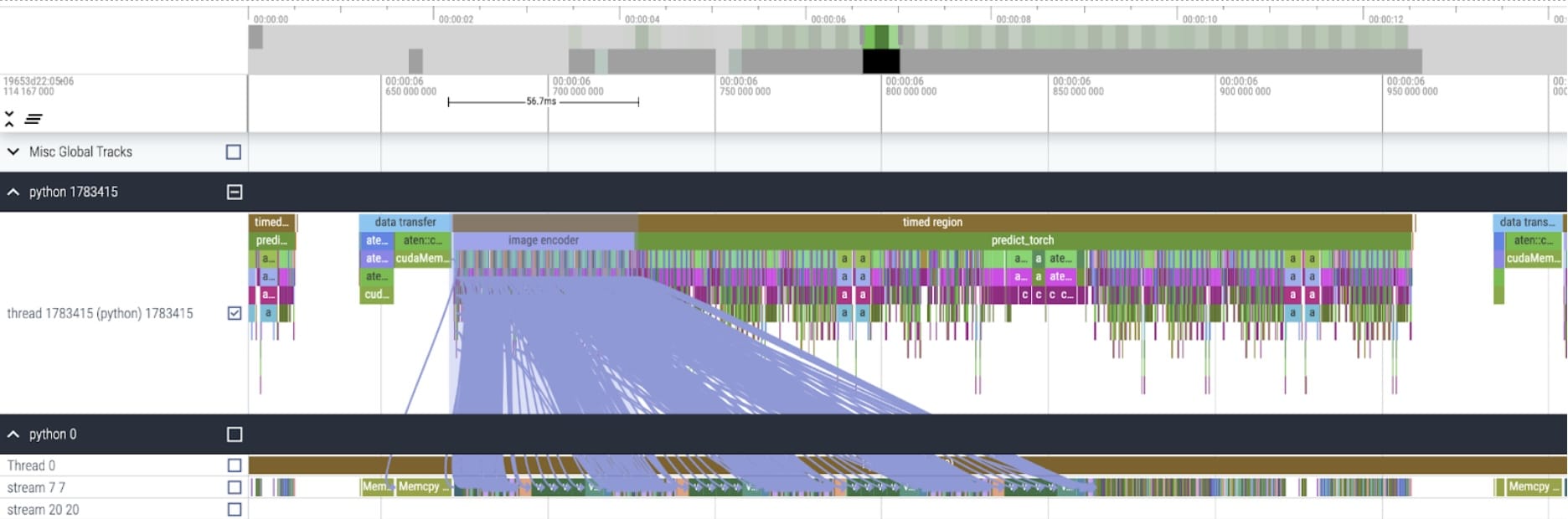
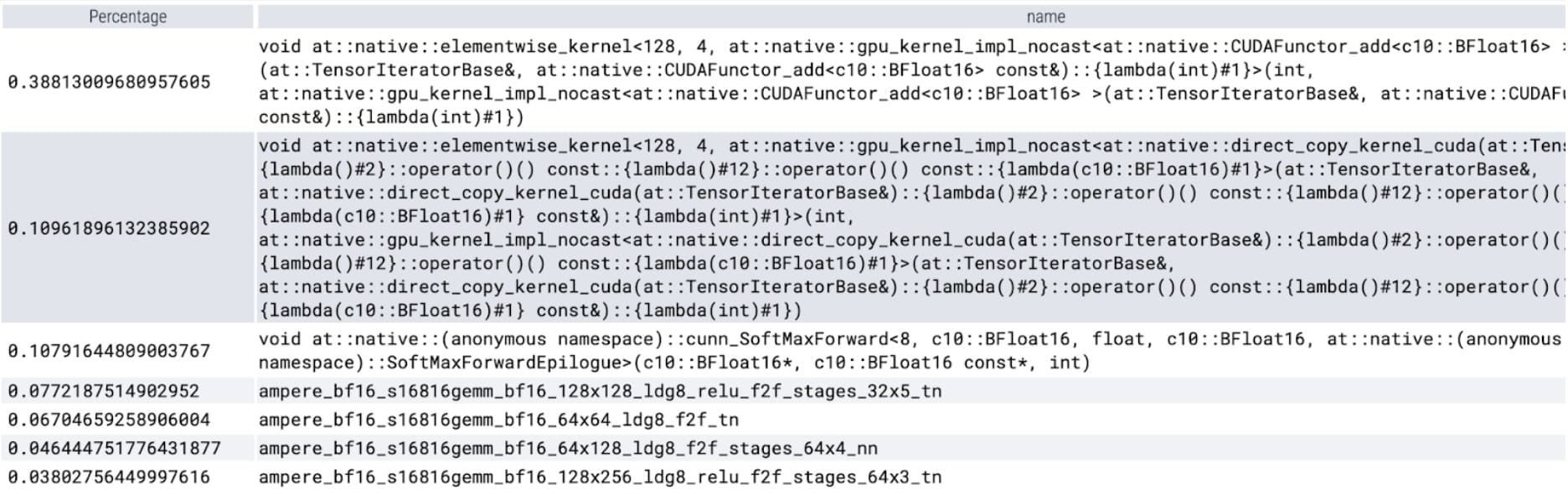
从每个内核花费的时间来看,我们发现 SAM 的大部分 GPU 时间都花在了逐元素内核和 softmax 操作上。因此,我们现在可以看到矩阵乘法已经变成了一个相对较小的开销。
将 GPU 同步和 bfloat16 优化结合起来,我们现在将 SAM 的性能提升了高达 3 倍。
Torch.compile(包括图断点和 CUDA 图)
当观察大量的小操作时,例如上面分析过的逐元素内核,转向编译器融合操作可以带来显著的好处。PyTorch 最近发布的 torch.compile 通过以下方式进行了优化:
- 将 nn.LayerNorm 或 nn.GELU 等操作序列融合成一个单独的 GPU 内核进行调用
- 后缀:将紧接矩阵乘法内核的操作融合,以减少 GPU 内核调用次数
通过这些优化,我们减少了 GPU 全局内存往返次数,从而加快了推理速度。现在我们可以尝试在 SAM 的图像编码器上使用 torch.compile。为了最大化性能,我们使用了一些高级编译技术,例如:
- 使用 torch.compile 的 max-autotune 模式启用 CUDA 图和具有自定义后缀的形状特定内核
- 通过设置 TORCH_LOGS="graph_breaks,recompiles",我们可以手动验证我们没有遇到图断开或重新编译的情况。
- 将输入到编码器的图像批次填充零,确保编译器接受静态形状,从而能够始终使用具有自定义尾部的特定形状优化的内核,而无需重新编译。
predictor.model.image_encoder = \
torch.compile(predictor.model.image_encoder, mode=use_compile)
内核跟踪
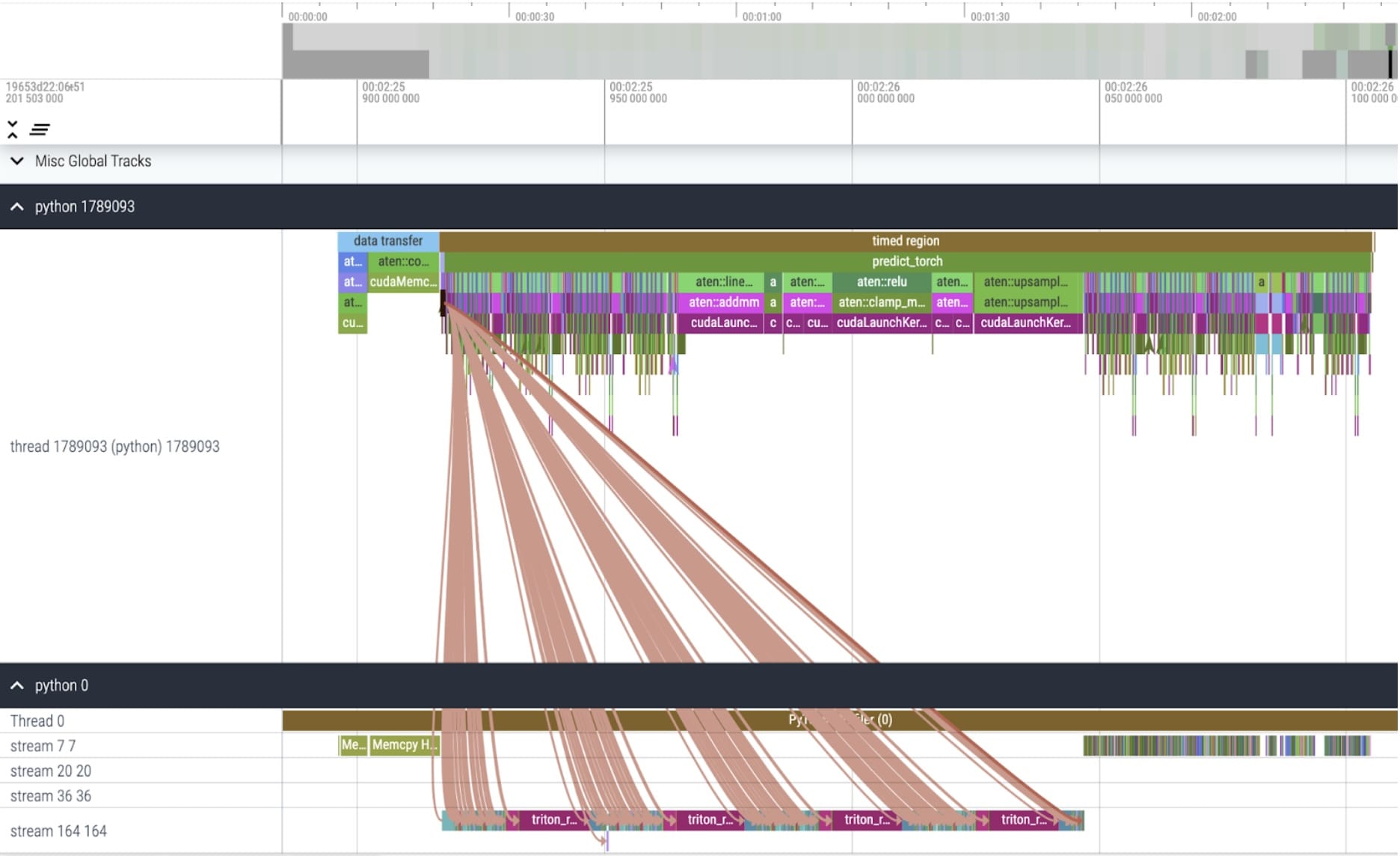
torch.compile 运行得非常好。我们启动一个单独的 CUDA 图,这构成了定时区域内 GPU 时间的很大一部分。让我们再次运行我们的配置文件,并查看在特定内核中花费的 GPU 时间百分比:
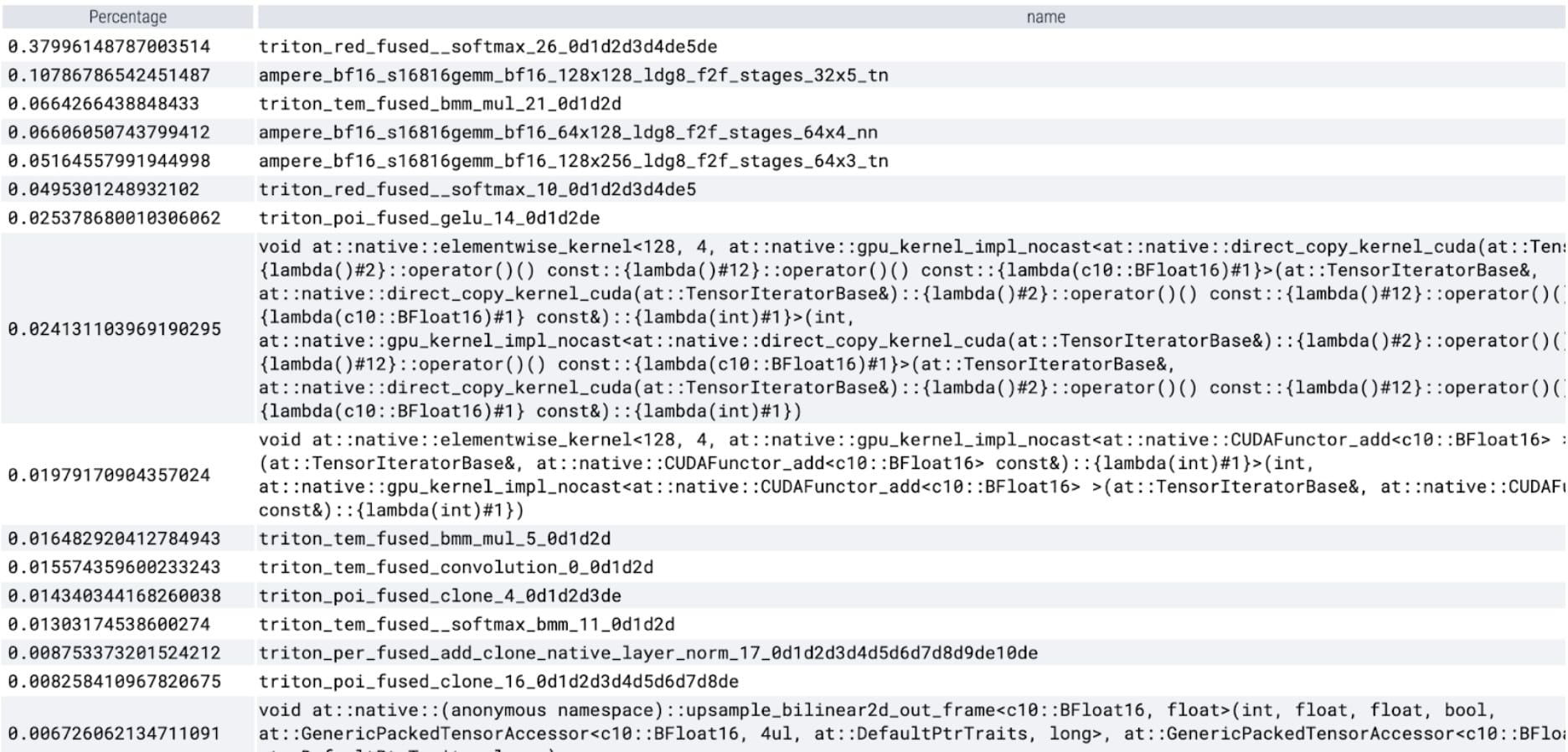
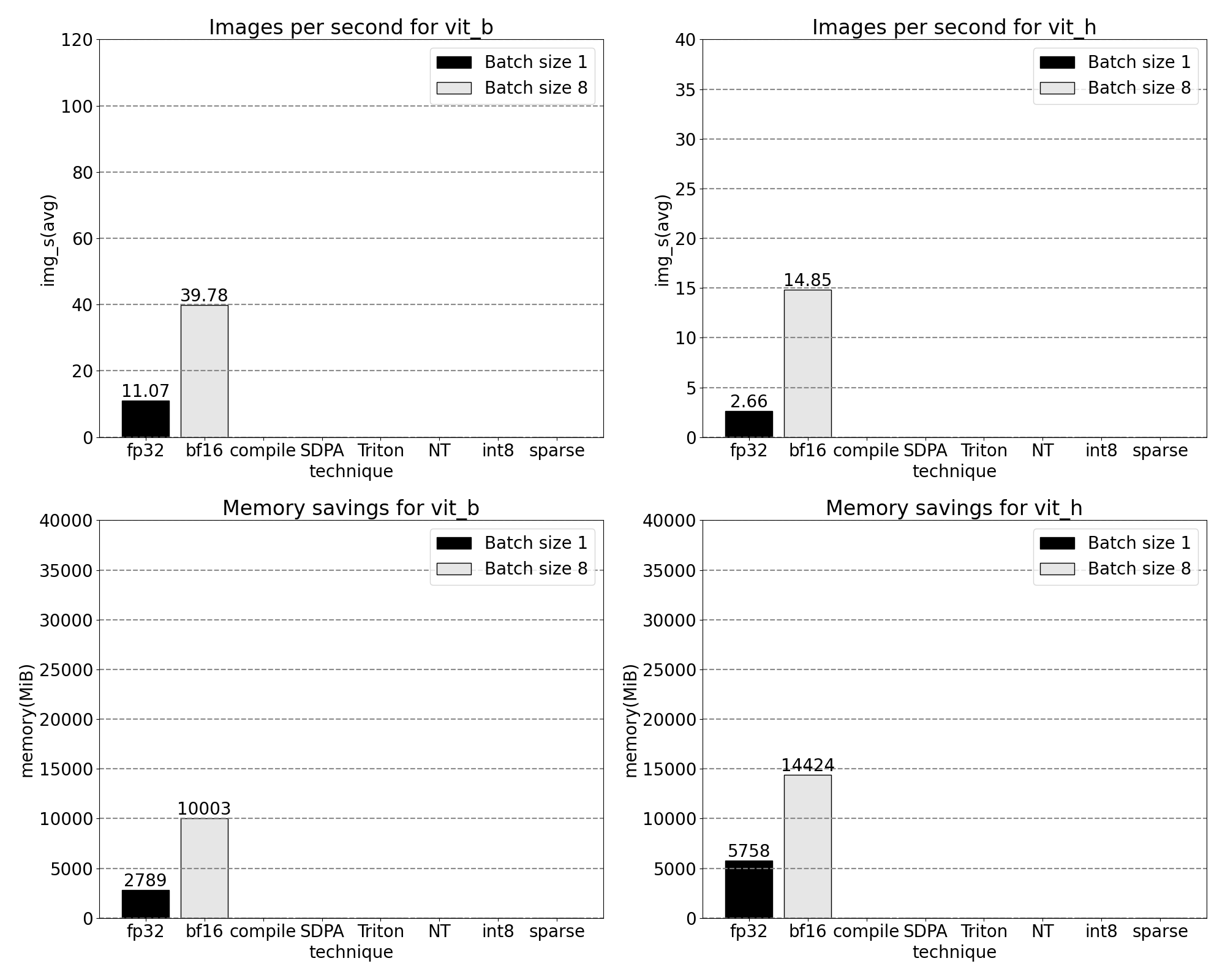
我们现在看到 softmax 占据了相当大的时间比例,其次是各种 GEMM 变体。总的来说,对于批处理大小 8 及以上的变化,我们观察到以下测量结果。
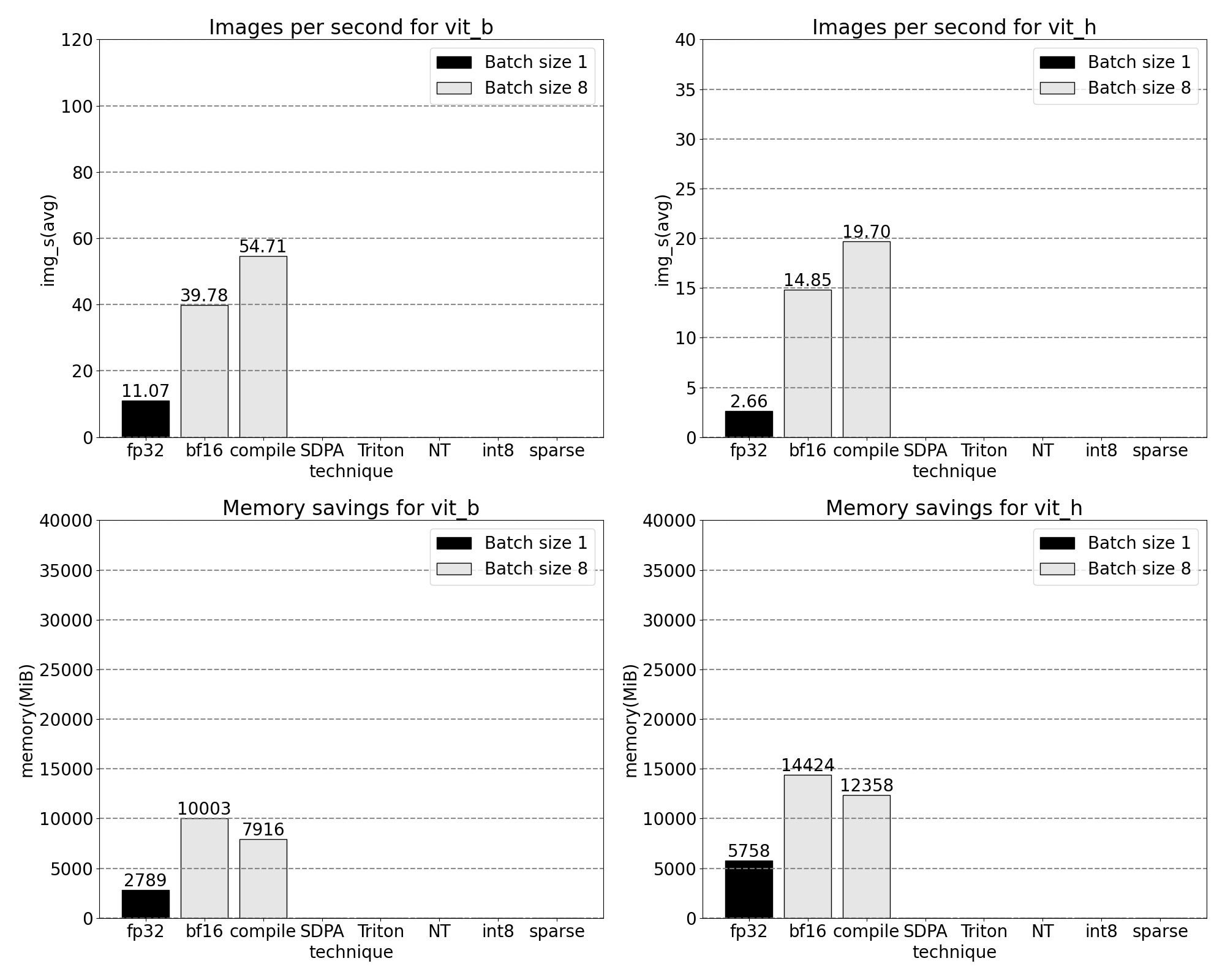
SDPA:缩放点积注意力
接下来,我们可以解决 Transformer 性能开销最常见的一个领域:注意力机制。简单的注意力实现随着序列长度的增加,在时间和内存上呈二次方增长。PyTorch 的基于 Flash Attention、FlashAttentionV2 和 xFormer 内存高效注意力的缩放点积注意力操作可以显著加快 GPU 的注意力处理。结合 torch.compile,这个操作允许我们在 MultiheadAttention 的各种变体中表达和融合一个常见的模式。经过一小系列修改后,我们可以将模型适配为使用缩放点积注意力。
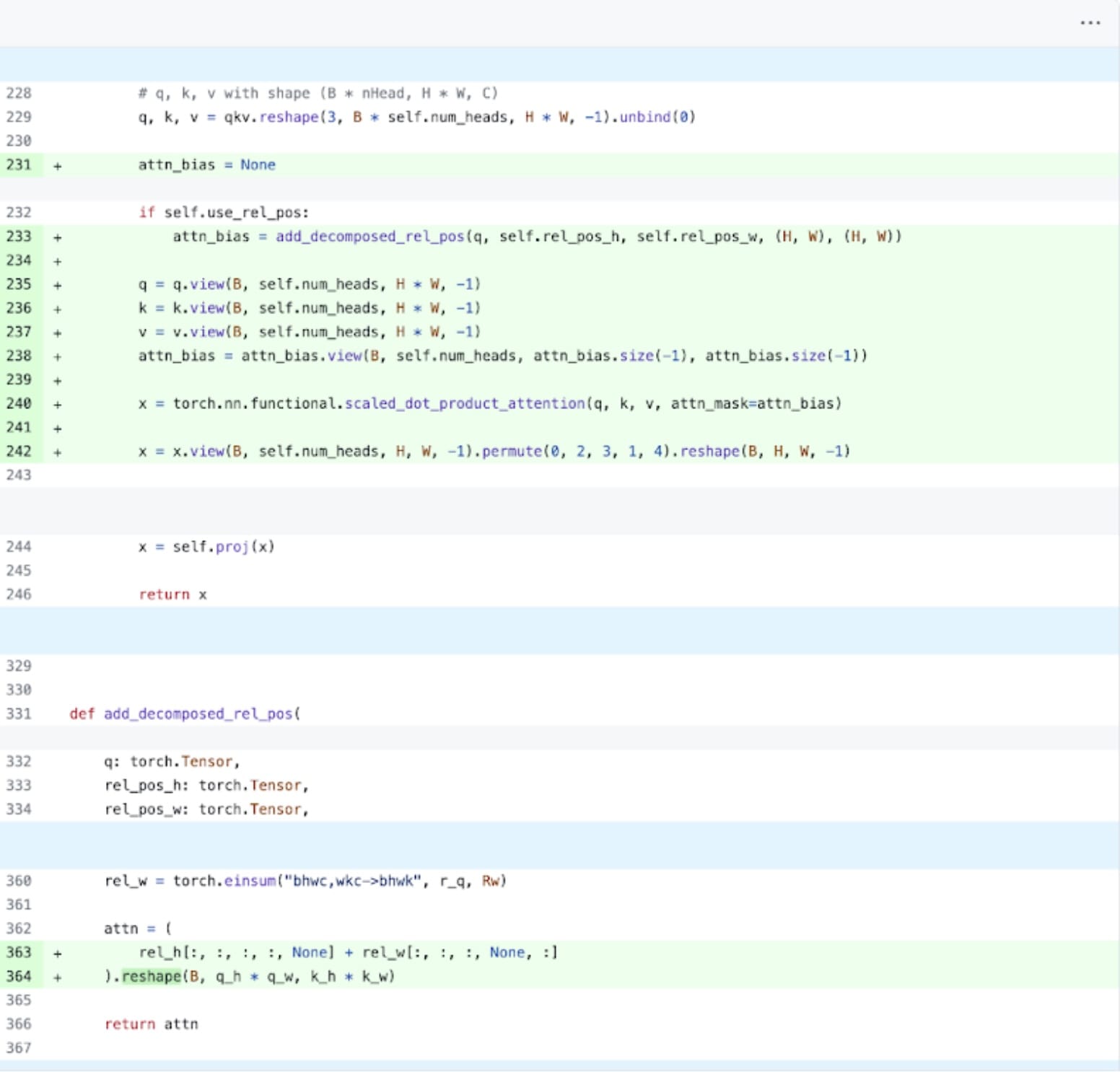
PyTorch 原生注意力实现,请参阅此处代码。
内核跟踪
我们现在可以看到,特别是内存高效的注意力内核在 GPU 上占用了大量的计算时间:
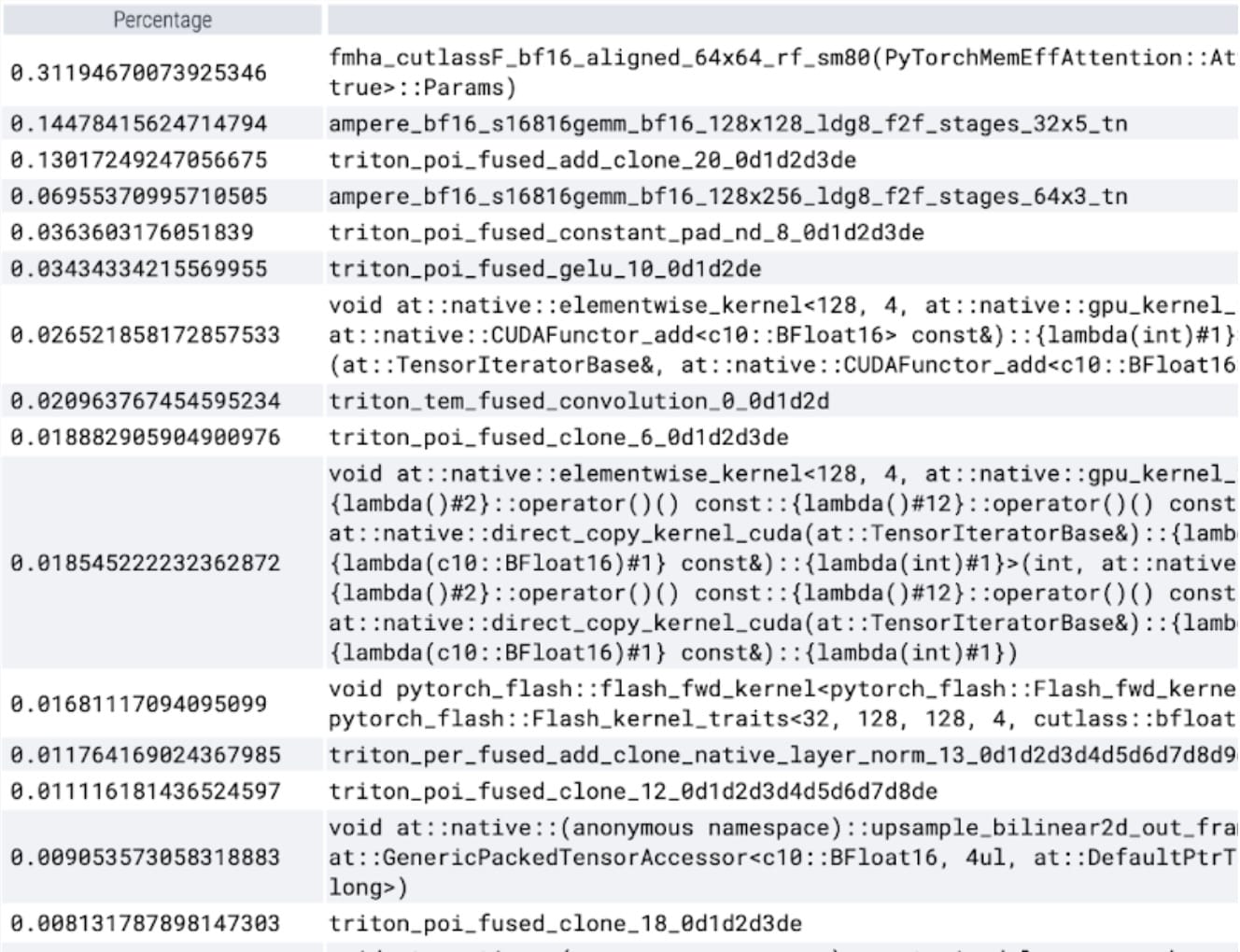
使用 PyTorch 的本地缩放点积注意力,我们可以显著增加批处理大小。现在观察到以下批处理大小为 32 及以上的测量结果:
Triton:针对融合相对位置编码的定制 SDPA
短暂地脱离推理吞吐量,我们开始对整体 SAM 内存进行性能分析。在图像编码器中,我们观察到内存分配出现了显著的峰值:
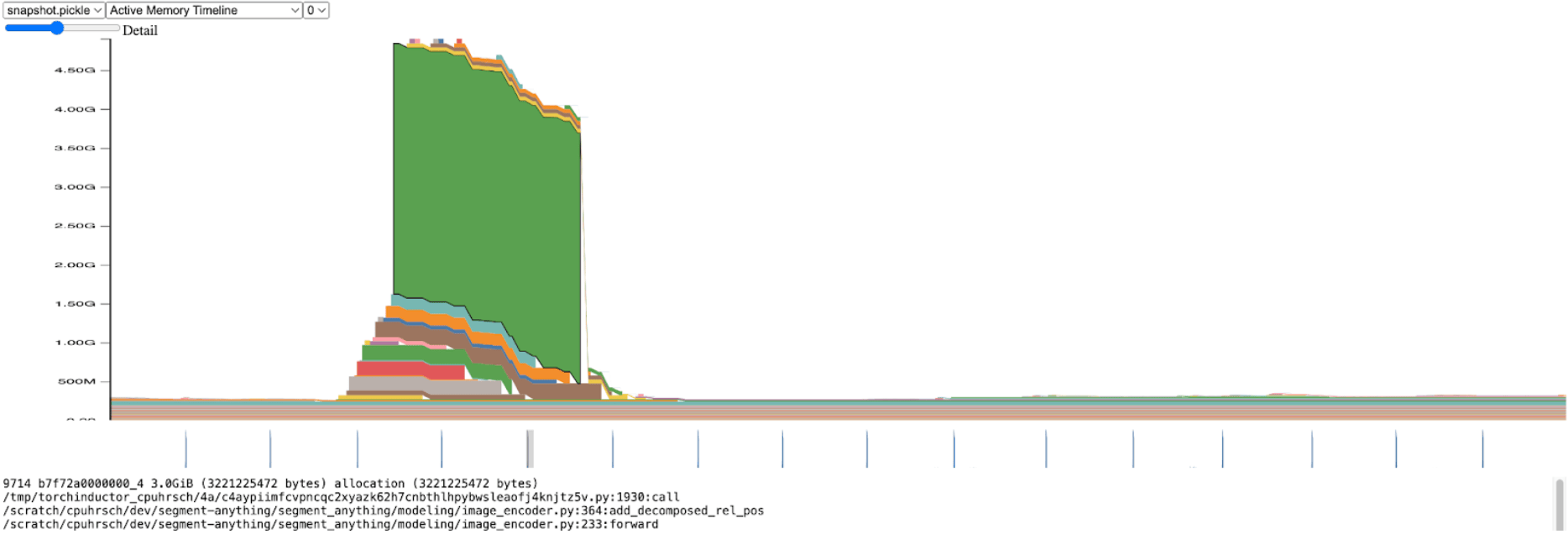
放大查看,我们发现这种分配发生在 add_decomposed_rel_pos 函数中,在下面的这一行:

这里的 attn 变量是两个较小张量的加和:rel_h 的形状为(B, q_h, q_w, k_h, 1)和 rel_w 的形状为(B, q_h, q_w, 1, k_w)。
当注意力偏差大小超过 3.0GiB 时,内存高效的注意力内核(通过 SDPA 使用)耗时较长,这并不令人意外。如果我们不是分配这个大的 attn 张量,而是将两个较小的 rel_h 和 rel_w 张量线程到 SDPA 中,并且只在需要时构建 attn,我们预计会有显著的性能提升。
很遗憾,这不是一个简单的修改;SDPA 内核高度优化,是用 CUDA 编写的。我们可以转向 Triton,他们有一个易于理解和使用的 FlashAttention 实现教程。经过一番深入的挖掘和与 xFormer 的 Daniel Haziza 的紧密合作,我们发现了一种输入形状,其中实现内核的融合版本相对简单。详细信息已添加到仓库中。令人惊讶的是,这可以在 350 行代码以下完成推理案例。
这是一个用 Triton 代码简单构建的新内核扩展 PyTorch 的绝佳例子。
内核跟踪
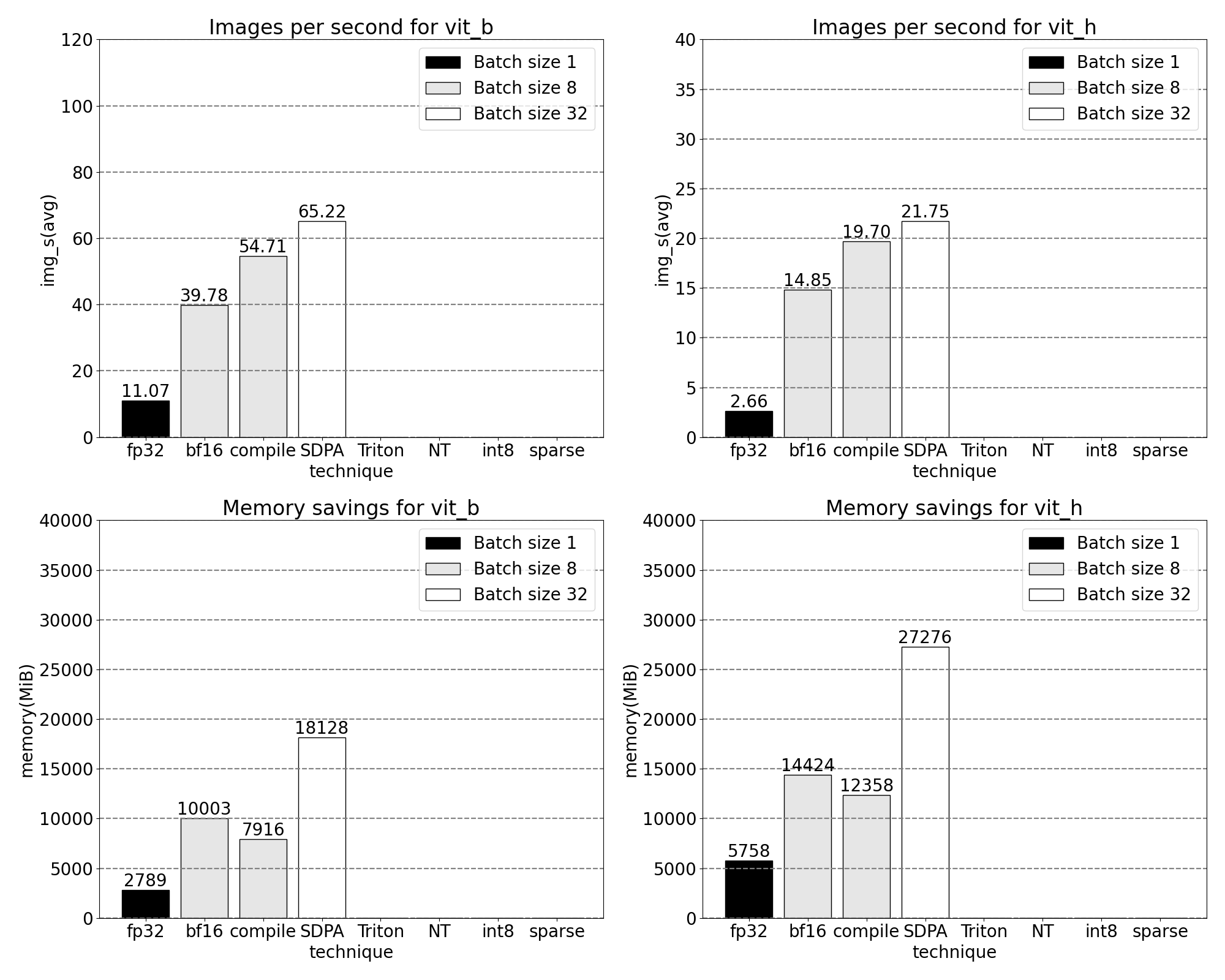
使用我们定制的位置 Triton 内核,我们观察到 32 个批次的以下测量结果。
NT: 嵌套张量与批处理预测_torch
我们在图像编码器上花费了大量的时间。这是有道理的,因为这部分占据了最多的计算时间。然而,到目前为止,它已经相当优化了,而占用最多时间的操作需要大量的额外投资才能改进。
我们在掩码预测管道中发现了有趣的观察:对于每个图像,我们都有一个关联的大小、坐标和 fg_labels 张量。这些张量具有不同的批处理大小。每个图像本身的大小也不同。这种数据表示看起来像交错数据。利用 PyTorch 最近发布的嵌套张量,我们可以将我们的数据管道中的批处理坐标和 fg_labels 张量修改为单个嵌套张量。这可以为随后的图像编码器后的提示编码器和掩码解码器带来显著的性能优势。调用:
torch.nested.nested_tensor(data, dtype=dtype, layout=torch.jagged)
内核跟踪
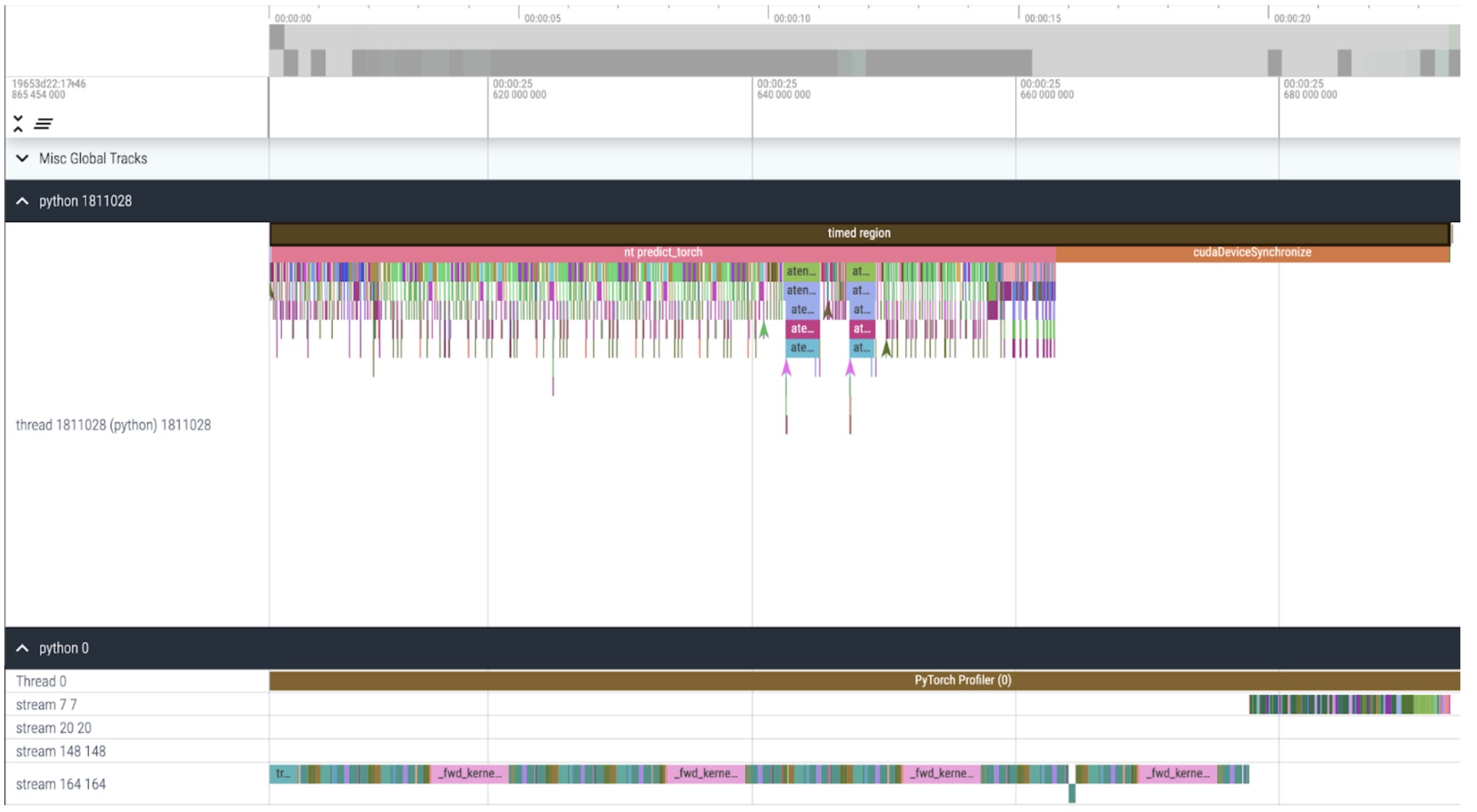

现在我们可以看到,从 CPU 启动内核的速度比 GPU 处理速度快得多,而且它会在我们的计时区域末尾长时间等待 GPU 完成(cudaDeviceSynchronize)。我们也没有在 GPU 上的内核之间看到更多的空闲时间(空白)。
使用嵌套张量,我们观察到以下针对批处理大小为 32 及以上的测量结果。
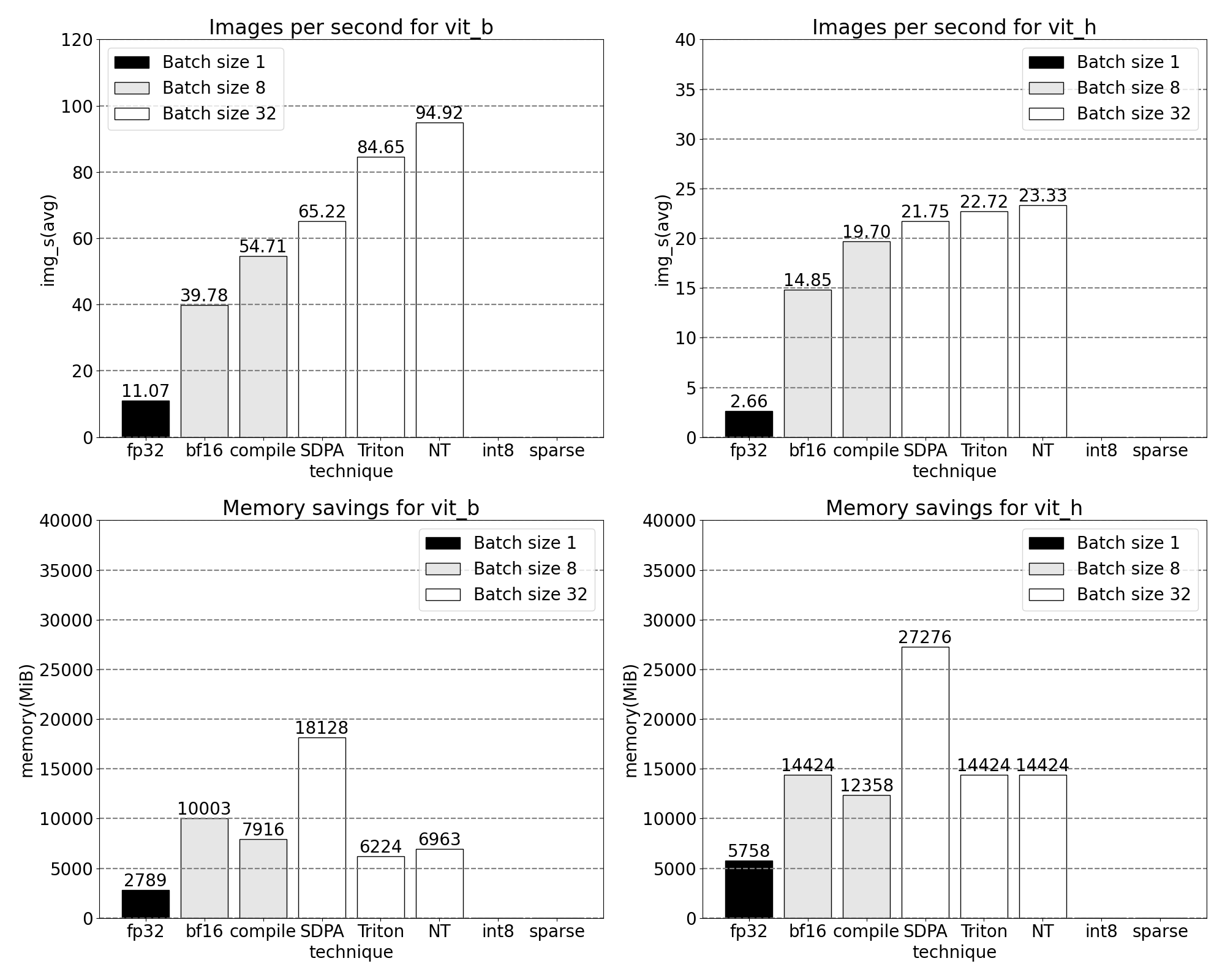
int8:量化以及近似矩阵乘法
我们在上面的跟踪中注意到,现在在 GEMM 内核上花费的时间显著增加。我们已经优化得足够好,现在看到矩阵乘法在推理中占用的时长超过了缩放点积注意力。
基于从 fp32 到 bfloat16 的早期学习,让我们更进一步,通过 int8 量化来模拟更低精度。在量化方法方面,我们专注于动态量化,其中我们的模型观察层的可能输入和权重的范围,并将可表示的 int8 范围细分,以均匀“分散”观察到的值。最终,每个浮点输入将被映射到[-128, 127]范围内的单个整数。更多信息请参阅 PyTorch 的量化教程
降低精度可以立即带来峰值内存节省,但要实现推理速度提升,我们必须充分利用 SAM 的操作来充分利用 int8。这需要构建一个高效的 int8@int8 矩阵乘法内核,以及将逻辑转换为从高精度到低精度的转换(量化)以及从低精度到高精度的反向转换(反量化)。利用 torch.compile 的力量,我们可以编译并融合这些量化和反量化例程,形成高效的单一内核和矩阵乘法的 epilogues。结果实现相当简洁,代码行数不到 250 行。有关 API 和用法信息,请参阅 pytorch-labs/ao。
在推理时量化模型时,通常会出现一些精度下降,但 SAM 对低精度推理的鲁棒性特别强,精度损失最小。添加量化后,我们现在观察到以下测量结果,针对批处理大小为 32 及以上的变化。
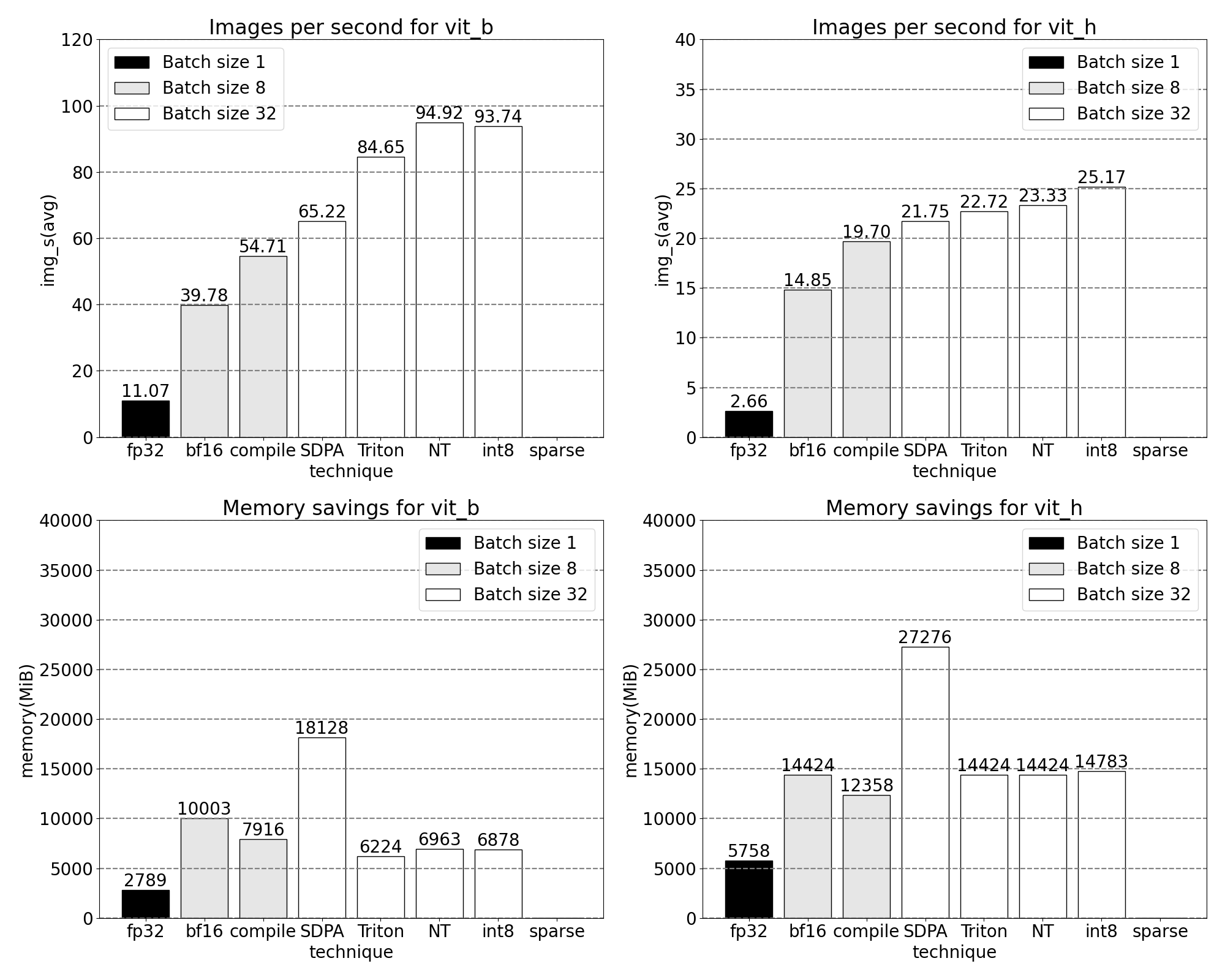
稀疏:半结构化(2:4)稀疏
矩阵乘法仍然是我们的瓶颈。我们可以转向模型加速剧本中的另一种经典方法来近似矩阵乘法:稀疏化。通过稀疏化我们的矩阵(即置零值),理论上我们可以使用更少的位来存储权重和激活张量。决定将张量中的哪些权重设置为零的过程称为剪枝。剪枝背后的想法是,权重张量中的小权重对层的净输出贡献很小,通常是权重与激活的乘积。剪除小权重可以潜在地减少模型大小,而不会导致精度显著下降。
剪枝方法多种多样,从完全无结构的,其中权重贪婪地剪枝,到高度结构化的,其中一次剪枝大型的子张量。方法的选择并非易事。虽然无结构化剪枝可能在理论上对准确性的影响最小,但 GPU 在乘以大型密集矩阵时也非常高效,在稀疏状态下可能会出现显著的性能下降。PyTorch 支持的一种最近剪枝方法试图寻求平衡,称为半结构化(或 2:4 稀疏)。这种稀疏存储将原始张量减少了显著的 50%,同时产生一个密集的张量输出,可以借助高性能的 2:4 GPU 内核。以下图片展示了说明。
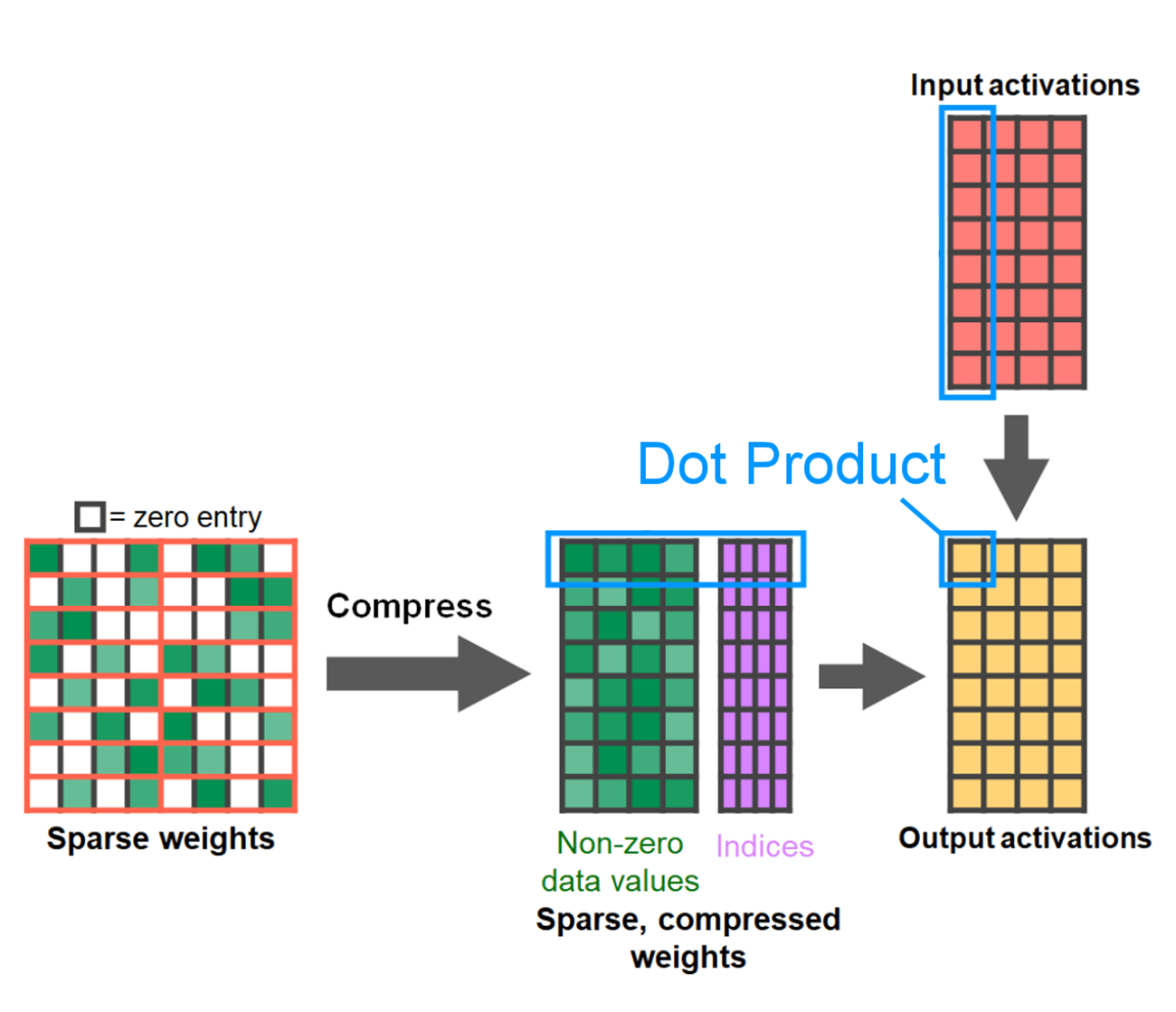
来自 developer.nvidia.com/blog/exploiting-ampere-structured-sparsity-with-cusparselt
为了使用这种稀疏存储格式及其相关的快速内核,我们需要剪枝我们的权重,以确保它们符合该格式的约束。我们在一个 1x4 的区域中选取两个最小的权重进行剪枝,测量性能与准确率的权衡。将权重从其默认的 PyTorch(“步进”)布局更改为这种新的半结构化稀疏布局很容易。要实现 apply_sparse(model) ,我们只需要 32 行 Python 代码:
import torch
from torch.sparse import to_sparse_semi_structured, SparseSemiStructuredTensor
# Sparsity helper functions
def apply_fake_sparsity(model):
"""
This function simulates 2:4 sparsity on all linear layers in a model.
It uses the torch.ao.pruning flow.
"""
# torch.ao.pruning flow
from torch.ao.pruning import WeightNormSparsifier
sparse_config = []
for name, mod in model.named_modules():
if isinstance(mod, torch.nn.Linear):
sparse_config.append({"tensor_fqn": f"{name}.weight"})
sparsifier = WeightNormSparsifier(sparsity_level=1.0,
sparse_block_shape=(1,4),
zeros_per_block=2)
sparsifier.prepare(model, sparse_config)
sparsifier.step()
sparsifier.step()
sparsifier.squash_mask()
def apply_sparse(model):
apply_fake_sparsity(model)
for name, mod in model.named_modules():
if isinstance(mod, torch.nn.Linear):
mod.weight = torch.nn.Parameter(to_sparse_semi_structured(mod.weight))
在 2:4 稀疏度下,我们在 SAM 上观察到峰值性能,使用 vit_b 和批处理大小 32:
结论
总结来说,我们非常高兴地宣布,我们目前实现了 Segment Anything 的最快版本。我们用纯 PyTorch 重写了 Meta 的原始 SAM,没有损失精度,并使用了大量新发布的特性:
- 使用 PyTorch 的本地 JIT 编译器,提供 PyTorch 操作的快速、自动融合 [教程]
- 使用降低精度操作加速模型 [API]
- 扩放点积注意力(SDPA)——Attention 的新颖、内存高效的实现 [教程]
- 半结构化(2:4)稀疏性,使用更少的位存储权重和激活 [教程]
- 嵌套张量高度优化,用于处理非均匀批量和图像大小的稀疏数组 [教程]
- Triton 内核。通过 Triton 自定义 GPU 操作,易于构建和优化
如需了解如何重现本博客文章中展示的数据的更多细节,请查看 segment-anything-fast 的实验文件夹。如遇到任何技术问题,请随时联系我们或提交问题。
在我们下一篇文章中,我们非常兴奋地分享与 PyTorch 原生编写的类似性能提升 LLM!
致谢
我们想感谢 Meta 的 xFormers 团队,包括 Daniel Haziza 和 Francisco Massa,他们编写了 SDPA 内核,并帮助我们设计了定制的 Triton 内核。