2D 块量化 Float8(FP8)有望在提高 Float8 量化的准确性的同时,加速 GEMM 的推理和训练过程。在这篇博客中,我们展示了使用 Triton 在执行块量化 Float8 GEMM 的两个主要阶段中的进展。
对于将 A 和 B 张量从高精度(BFloat16)量化到 Float8 的过程,我们展示了 GridQuant,它采用微型网格步进循环式处理,与当前的 2D 块量化内核相比,速度提高了近 2 倍(99.31%)。
对于 Float8 GEMM,我们展示了 Triton 的三个新进展——Warp 专业化、TMA 和持久内核,以有效地创建合作式内核(Ping-Pong 调度的一种替代方案)。因此,我们实现了相对于去年最佳性能的 SplitK 内核的约 1.2 倍速度提升。
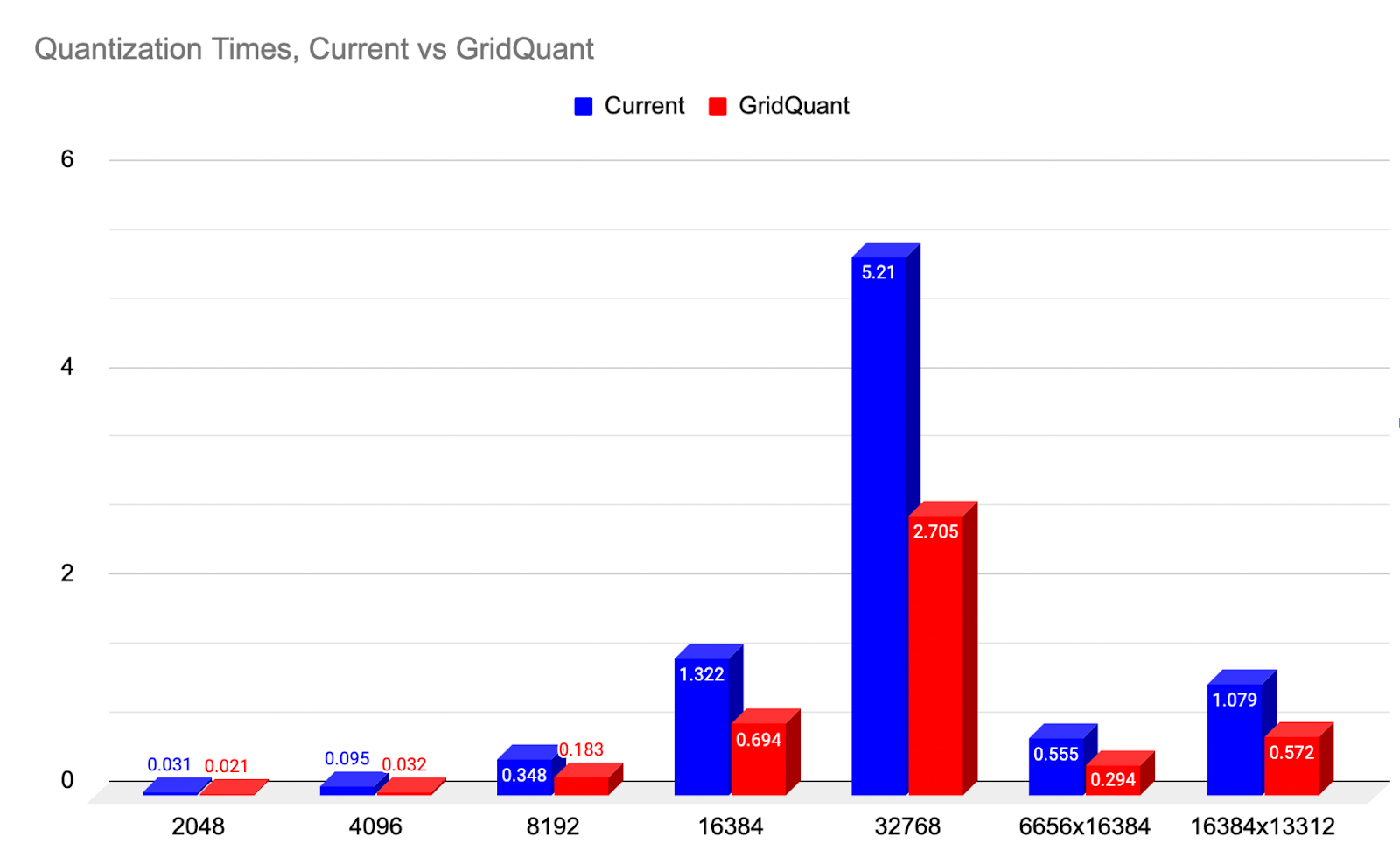
图 1:2D 量化速度提升与当前基线对比,范围涵盖各种尺寸。(越低越好)
为什么需要 2D 分块量化 FP8?
一般而言,fp8 量化的精度随着从张量级缩放、到行级缩放、再到 2D 分块缩放,最后到列级缩放而提高。这是因为给定标记的特征存储在每个列中,因此该张量中的每一列的缩放更加相似。
为了最小化给定数值集的异常值数量,我们希望找到共性,以便数字以相似的方式进行缩放。对于 Transformer 来说,这可能意味着基于列的量化可能是最优的……然而,由于数据在内存中以行连续的方式排列,列式内存访问效率极低。因此,列式加载将需要涉及大步长的内存访问来提取孤立值,这与高效内存访问的核心原则相悖。
然而,2D 是次优选择,因为它包含了列向量的某些方面,同时在拉取时更加内存高效,因为我们可以使用 2D 向量化来对这些加载进行向量化。因此,我们希望找到提高 2D 块量化速度的方法,这就是我们开发 GridQuant 内核的原因。
在量化过程中,我们需要对高精度 BF16 输入张量(A = 输入激活,B = 权重)进行 2D 块量化,然后使用量化张量和它们的 2D 块缩放值进行 Float8 矩阵乘法,并返回一个 BF16 的输出 C 张量。
GridQuant 是如何提高 2D 块量化效率的?
GridQuant 内核在初始基线量化实现(标准瓦片实现)的基础上有多个改进。GridQuant 内核对整个输入张量进行两次完整的遍历,其工作方式如下:
第 1 阶段 - 确定来自输入高精度张量的每个 256x256 子块的绝对最大值。
1 - 我们将 BF16 张量划分为 256x256 的子块。此量化大小是可配置的,但默认为 256x256,因为它提供了量化精度和处理的平衡。
2 - 每个 256x256 子块被细分为 64 个子块,排列成 8x8 的模式,每个子块处理一个 32x32 的元素块。单个 warp(32 个线程)处理其分配的 32x32 块内的所有元素。
3 - 我们在共享内存中声明一个 32x32 的 max_vals 数组。这个数组将存储 2D 向量块在移动整个 256x256 子块时的当前位置 i,j 的当前最大值。
这是一项重要的改进,因为它意味着我们可以对 max vals 评分系统进行向量化更新,而不是标量更新,从而允许进行更高效的更新。
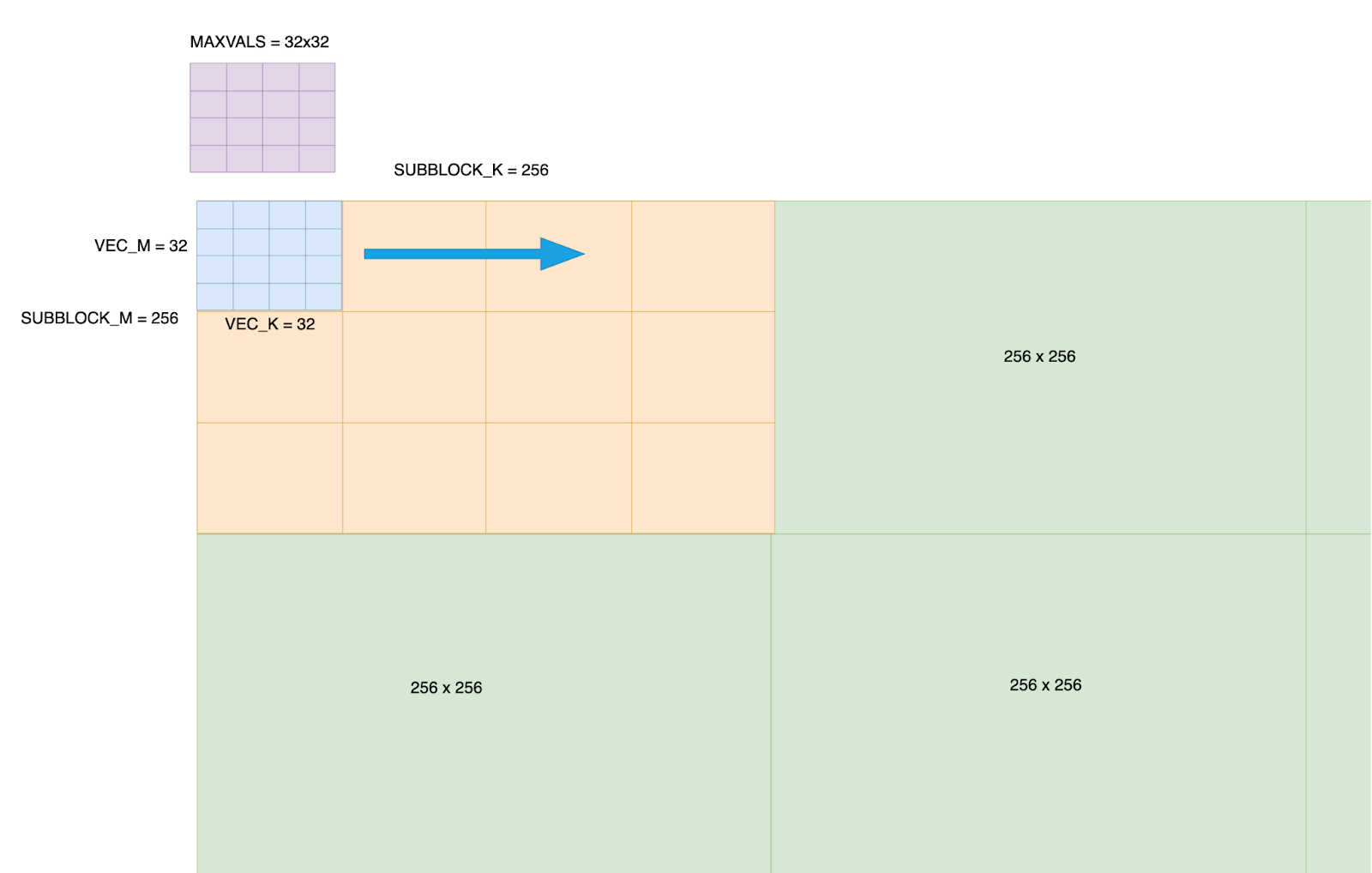
图 2:输入张量的分数化布局——在张量上创建了一个 256x256 的网格,并且在每个 256x256 的块内,它进一步细化成 32x32 的子块。为每个 256x256 的块创建一个 32x32 的 max_vals。
4 - 每个 warp 处理一个 32x32 的块,因为我们使用了 4 个 warp,所以我们确保 Triton 编译器可以在实际处理当前 32x32 块中的 absmax 计算的同时,对下一个 32x32 块进行内存加载的流水线操作。这确保了 warp 调度器能够切换 warp 加载数据和处理数据,使 SM 持续忙碌。
5 - 32x32 的 2D 向量块处理以网格步进的方式在整个 256x256 子块中移动和穿过,每个 warp 更新共享内存中的 32x32 max_vals,以应对其当前的 32x32 子块。因此,随着每个子块的处理,max_vals[i,j]保存了最新的最大值。
完成对 256x256 块网格步长循环后,maxvals 矩阵随后自身缩减,以找到整个 256 块中的绝对最大值。
这为我们提供了这个 2D 256x256 块的最终缩放因子值。
第二阶段 - 使用第一阶段找到的单个最大值缩放因子,将 256x256 块值量化为 Float8。
接下来,我们再次遍历整个 256x256 块,使用第一阶段找到的最大值重新缩放所有数字,将它们转换为 float 8 格式。
因为我们知道需要做两次完整的遍历,在第一阶段负载期间,我们指导 Triton 编译器将这些值以更高的优先级保存在缓存中(驱逐策略=最后)。
这意味着在第二次遍历期间,我们可以从 L2 缓存中获得高命中率,这比直接访问 HBM 提供了更快的内存访问速度。
当所有 256x256 块处理完成后,2D 块量化处理完成,我们可以返回新的 Float8 量化张量及其缩放因子矩阵,这些将在 GEMM 处理的下一阶段使用。这个输入量化也适用于第二个输入张量,这意味着我们最终得到 A_Float 8、A_scaling_matrix、B_Float8 和 B_scaling matrix。
GridQuant - GEMM 内核
网格量化-GEMM 内核接收上述量化的四个输出进行处理。我们高性能的 GEMM 内核具有多个新的 Triton 开发,以实现与LLM解码阶段相关的矩阵形状配置文件的 SOTA 性能。
这些新特性在 Hopper 优化内核中很常见,如 FlashAttention-3 和 Machete,它们使用 CUTLASS 3.x 构建。在这里,我们讨论这些方法,并展示通过在 Triton 中使用它们所能获得的性能优势。
张量内存加速器(TMA)
NVIDIA Hopper GPU 上的 TMA 单元是一个专门用于对多维张量执行加载/存储操作的硬件单元,这些张量在 AI 工作负载中很常见。这具有几个重要的好处。
从全局和共享内存中传输数据可以不涉及 GPU SM 上的其他资源,从而释放寄存器和 CUDA 核心。此外,当在 warp 专用内核中使用时,轻量级的 TMA 操作可以被分配给生产者 warp,从而实现内存传输和计算的高度重叠。
关于 TMA 在 Triton 中的使用细节,请参阅我们之前的博客。
Warp-Specialization(协作持久内核设计)
Warp 专用化是一种利用 GPU 上流水线并行性的技术。这个实验性功能通过 tl.async_task API 表达专用线程,使用户能够指定 Triton 程序中操作如何在 warp 之间“分割”。协作的 Triton 内核执行不同类型的计算和加载,这些操作各自在它们自己的专用硬件上执行。为每个专用任务拥有专用硬件,使得对于没有数据依赖的操作能够实现高效的并行性。
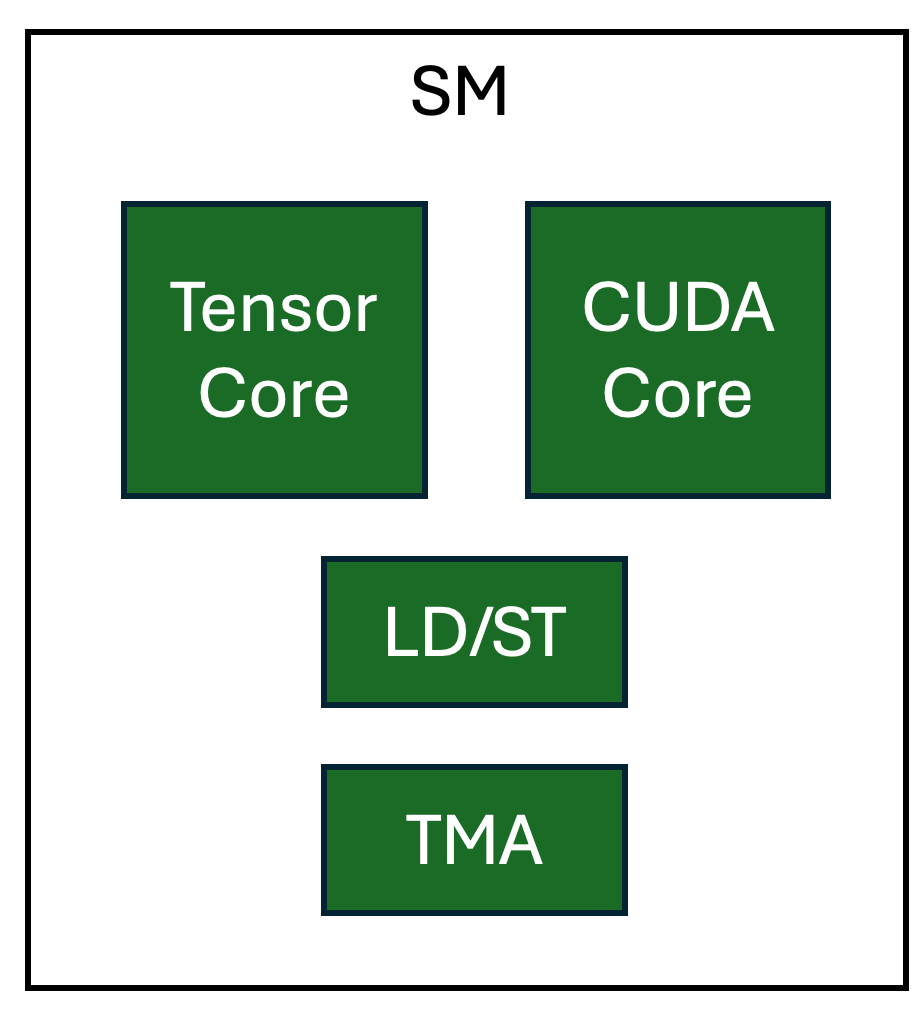
图 3. NVIDIA H100 SM 中专用硬件单元的逻辑视图
我们内核中创建流水线的操作如下:
A - 从 GMEM 将每个块的缩放因子加载到 SMEM 中(cp.async 引擎)
B - 将激活(A)和权重(B)瓦片从 GMEM 加载到 SMEM 中(TMA)
C - 矩阵乘法:A 砖与 B 砖的乘积 = C 砖(Tensor Core)
D - 使用来自 A 的块级缩放和来自 B 的块级缩放缩放 C 砖(CUDA 核心)
这些步骤可以分配给“任务”,由线程块中的专用 warp 组执行。协同策略有三个 warp 组。一个负责向计算单元提供数据的生产者 warp 组和两个执行计算的消费者 warp 组。两个消费者 warp 组各自处理相同输出砖的一半。

图 4. warp 专用持久性协同内核(来源:NVIDIA)
这与我们在之前的博客中讨论的乒乓调度不同,其中每个消费者 warp 组处理不同的输出瓦片。我们注意到 Tensor Core 操作与尾声计算没有重叠。在计算尾声阶段降低 Tensor Core 管道利用率将减少与乒乓调度相比的消费者 warp 组的寄存器压力,因为乒乓调度总是保持 Tensor Core 处于忙碌状态,从而允许更大的瓦片大小。
最后,我们的内核在网格大小超过 H100 GPU(132)上可用的计算单元数量时设计为持久性。持久内核在 GPU 上保持活跃状态,并在其生命周期内计算多个输出瓦片。我们的内核利用 TMA 异步共享到全局内存存储,同时继续在下一个输出瓦片上工作,而不是承担调度多个线程块的成本。
微基准测试
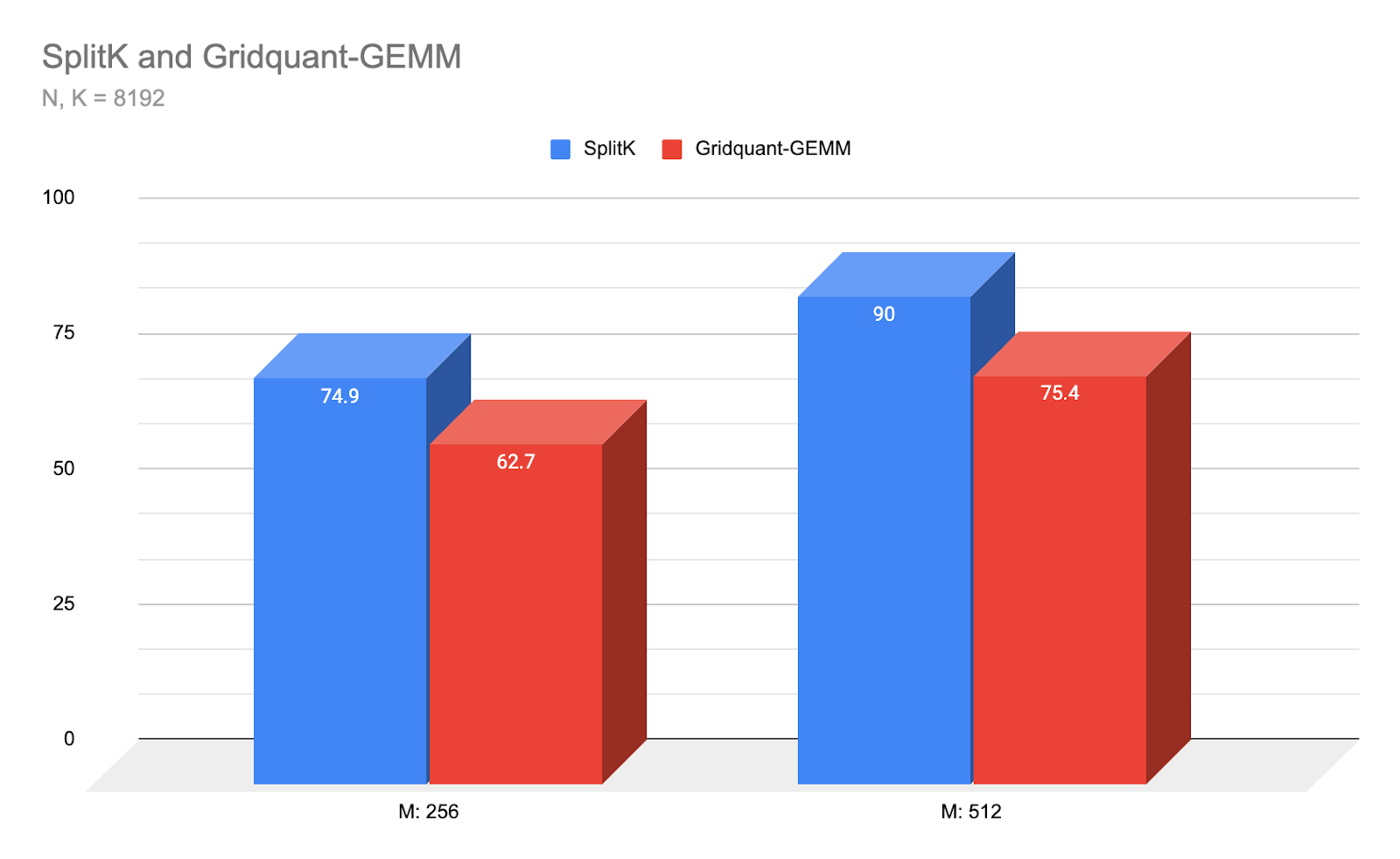
图 5:Gridquant-GEMM 与我们性能最佳的 SplitK 内核在小型批量模式和 Llama3 8192 N,K 尺寸下的延迟比较(越低越好)
Warp-Specialized Triton 内核在上述小 M 和正方形矩阵形状上实现了 SOTA 性能,比之前的最佳策略 SplitK Triton 内核快近 1.2 倍,该策略在此低算术强度领域是 Triton GEMMs 的最佳表现。对于未来的工作,我们计划调整我们的内核性能以适应中等至大型 M 范围和非正方形矩阵。
结论与未来工作
未来工作包括对 gridquant 在端到端工作流程中的基准测试。此外,我们计划对非正方形(矩形)矩阵以及中等至大型 M 尺寸进行更广泛的基准测试。最后,我们计划探索 Triton 中的 ping-pong 风格 warp 特殊化与当前协作实现之间的差异。