TL;DR:PyTorch 2.0 夜间版通过使用新的 torch.compile() 编译器和与 PyTorch 2 集成的优化 Multihead Attention 实现,为生成式扩散模型提供了开箱即用的性能提升。
引言
生成式 AI 最近取得的很大一部分进展来自去噪扩散模型,这些模型可以从文本提示中生成高质量的图像和视频。这个家族包括 Imagen、DALLE、Latent Diffusion 等。然而,这个家族中的所有模型都存在一个共同的缺点:由于生成是通过产生图像的采样过程的迭代性质,因此生成速度较慢。这使得优化采样循环中运行的代码变得非常重要。
我们以一个流行的文本到图像扩散模型的开源实现作为起点,并利用 PyTorch 2 中的两个优化来加速其生成:编译和快速注意力实现。结合代码中的一些小内存处理改进,这些优化相对于原始的未使用 xFormers 的实现,推理速度提高了 49%,相对于使用原始代码并集成 xFormers 的优化版本(不包括编译时间),推理速度提高了 39%,具体取决于 GPU 架构和批处理大小。重要的是,这种加速无需安装 xFormers 或其他任何额外依赖。
下表显示了原始实现(安装了 xFormers)与我们的优化版本(集成 PyTorch 内存高效注意力[最初在 xFormers 库中开发并发布]和 PyTorch 编译)之间的运行时间改进。编译时间不包括在内。
与原始+xFormers 相比的运行时间改进百分比
请参阅“基准测试设置和结果摘要”部分中的绝对运行时间数字
| GPU | 批处理大小 1 | 批处理大小 2 | 批处理大小 4 |
| P100(无需编译) | -3.8 | 0.44 | 5.47 |
| T4 | 2.12 | 10.51 | 14.2 |
| A10 | -2.34 | 8.99 | 10.57 |
| V100 | 18.63 | 6.39 | 10.43 |
| A100 | 38.5 | 20.33 | 12.17 |
可以注意到以下情况:
- 对于像 A100 和 V100 这样的强大 GPU,改进是显著的。对于这些 GPU,改进在批量大小为 1 时最为明显。
- 对于不太强大的 GPU,我们观察到较小的加速(或在两种情况下略有下降)。这里的批量大小趋势是相反的:对于更大的批量,改进更大。
在以下章节中,我们描述了应用的优化措施,并提供了详细的基准测试数据,比较了具有各种优化功能开启/关闭的生成时间。
具体来说,我们基准测试了 5 种配置,下方的图表比较了它们在不同 GPU 和批处理大小下的绝对性能。有关这些配置的定义,请参阅“基准测试设置和结果”部分。
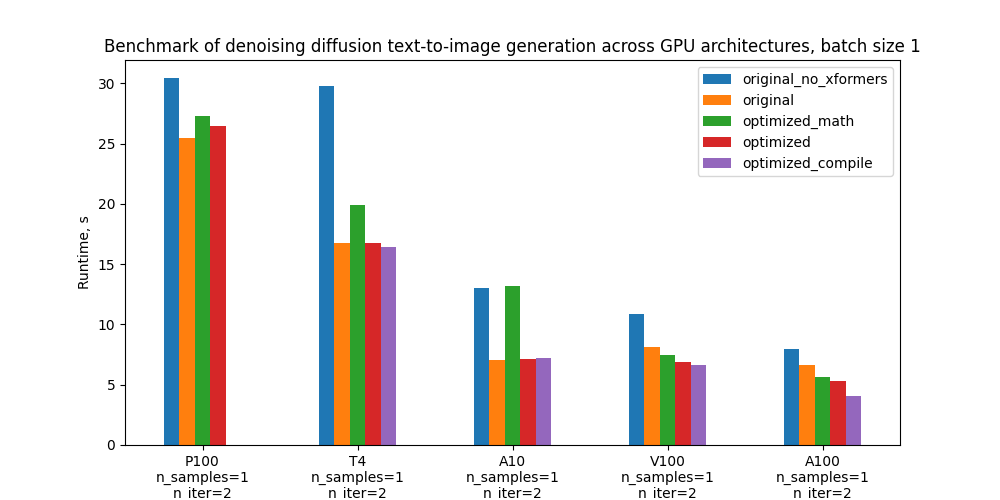
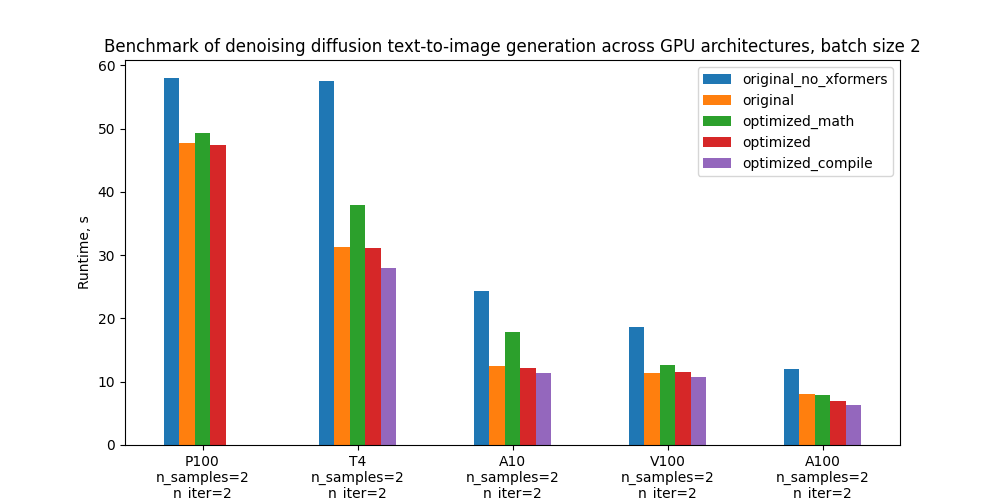
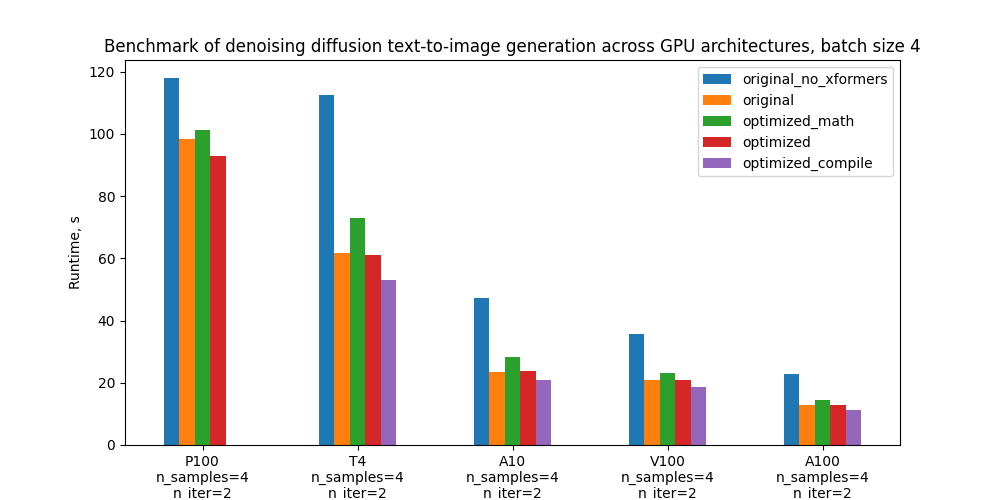
优化
在这里,我们将更详细地介绍引入到模型代码中的优化。这些优化依赖于最近发布的 PyTorch 2.0 的新特性。
优化后的注意力机制
我们优化的代码部分之一是缩放点积注意力。众所周知,注意力是一个耗时的操作:原始实现会生成注意力矩阵,导致时间和内存复杂度与序列长度呈二次方关系。扩散模型通常会在 U-Net 的多个部分使用注意力( CrossAttention )作为 Transformer 块的一部分。由于 U-Net 在每一步采样时都会运行,这成为了一个需要优化的关键点。除了自定义注意力实现,还可以使用 torch.nn.MultiheadAttention, ,在 PyTorch 2 中,已经集成了优化的注意力实现。这种优化在伪代码中的示意图如下:
class CrossAttention(nn.Module):
def __init__(self, ...):
# Create matrices: Q, K, V, out_proj
...
def forward(self, x, context=None, mask=None):
# Compute out = SoftMax(Q*K/sqrt(d))V
# Return out_proj(out)
…
被替换为
class CrossAttention(nn.Module):
def __init__(self, ...):
self.mha = nn.MultiheadAttention(...)
def forward(self, x, context):
return self.mha(x, context, context)
优化后的注意力实现已在 PyTorch 1.13 中提供(见此处),并被广泛采用(例如,HuggingFace transformers 库示例)。特别是,它集成了来自 xFormers 库的内存高效注意力以及来自 https://arxiv.org/abs/2205.14135 的 flash 注意力。PyTorch 2.0 扩展了这一功能,增加了交叉注意力和自定义内核等额外的注意力函数,以进一步加速,使其适用于扩散模型。
突出显示注意力在具有计算能力 SM 7.5 或 SM 8.x 的 GPU 上可用 - 例如,在 T4、A10 和 A100 上,这些都在我们的基准测试中(您可以在此处检查每个 NVIDIA GPU 的计算能力)。然而,在我们的 A100 测试中,由于注意力头数量少和批量大小小,内存高效注意力在扩散模型特定情况下比突出显示注意力表现更好。PyTorch 理解这一点,在这种情况下,当两者都可用时,它会选择内存高效注意力而不是突出显示注意力(请参阅此处逻辑)。为了完全控制注意力后端(内存高效注意力、突出显示注意力、“纯数学”或任何未来的后端),高级用户可以使用 torch.backends.cuda.sdp_kernel 上下文管理器手动启用和禁用它们。
编译
编译是 PyTorch 2.0 的新功能,它通过非常简单的用户体验实现了显著的加速。要调用默认行为,只需将 PyTorch 模块或函数包装在 torch.compile 中即可:
model = torch.compile(model)
PyTorch 编译器将 Python 代码转换为一系列可高效执行的指令,无需 Python 开销。编译过程在代码首次执行时动态发生。默认情况下,在底层 PyTorch 使用 TorchDynamo 编译代码,并使用 TorchInductor 进一步优化。请参阅此教程以获取更多详细信息。
虽然上面的单行代码足以进行编译,但代码中的某些修改可以带来更大的速度提升。特别是,应避免所谓的图断点——PyTorch 无法编译的代码中的位置。与之前的 PyTorch 编译方法(如 TorchScript)不同,PyTorch 2 编译器在这种情况下不会中断。相反,它回退到 eager 执行——因此代码会运行,但性能会降低。我们对该模型代码进行了一些小的修改,以消除图断点。这包括从库中删除不支持编译的函数,例如 inspect.isfunction 和 einops.rearrange 。请参阅此文档了解有关图断点及其消除方法的更多信息。
理论上,可以在整个扩散采样循环上应用 torch.compile 。然而,在实践中,只需要编译 U-Net 即可。原因是 torch.compile 还没有循环分析器,并且会为采样循环的每次迭代重新编译代码。此外,编译后的采样器代码可能会生成图断裂,因此如果想要从编译版本中获得良好的性能,就需要对其进行调整。
注意,编译需要 GPU 计算能力>=SM 7.0 才能以非急切模式运行。这涵盖了我们在基准测试中的所有 GPU - T4、V100、A10、A100,除了 P100(请参阅完整列表)。
其他优化
此外,我们通过消除一些常见陷阱,如直接在 GPU 上创建张量而不是在 CPU 上创建然后移动到 GPU,提高了 GPU 内存操作的效率。需要此类优化的地方是通过行分析以及查看 CPU/GPU 跟踪和火焰图确定的。
基准测试设置和结果总结
我们有两个版本的代码进行比较:原始版本和优化版本。在此基础上,还可以开启/关闭几个优化功能(xFormers、PyTorch 内存高效注意力机制、编译)。总的来说,如引言中所述,我们将对 5 种配置进行基准测试:
- 原始代码,无 xFormers
- 原始代码,带 xFormers
- 使用纯数学注意力后端且无需编译的优化代码
- 使用内存高效的注意力后端且无需编译的优化代码
- 使用内存高效的注意力后端且需要编译的优化代码
与原始版本一样,我们选择了使用 PyTorch 1.12 和自定义注意力实现的代码版本。优化版本使用 nn.MultiheadAttention 在 CrossAttention 中,并使用 PyTorch 2.0.0.dev20230111+cu117。它还在 PyTorch 相关代码中进行了几项其他的小优化。
下表显示了代码每个版本的运行时间(单位:秒),以及与使用 xFormers 的原始版本相比的百分比提升。编译时间除外。
批处理大小为 1 的运行时间。括号内为相对于“使用 xFormers 的原始版本”行的相对提升。
| 配置 | P100 | T4 | A10 | V100 | A100 |
| 未使用 xFormers 的原始版本 | 30.4 秒(-19.3%) | 29.8 秒(-77.3%) | 13.0 秒(-83.9%) | 10.9 秒(-33.1%) | 8.0 秒(-19.3%) |
| 原版含 xFormers | 25.5 秒(0.0%) | 16.8 秒(0.0%) | 7.1 秒(0.0%) | 8.2 秒(0.0%) | 6.7 秒(0.0%) |
| 使用纯数学注意力优化,无需编译 | 27.3 秒(-7.0%) | 19.9 秒(-18.7%) | 13.2 秒(-87.2%) | 7.5 秒(8.7%) | 5.7 秒(15.1%) |
| 使用内存高效注意力优化,无需编译 | 26.5 秒(-3.8%) | 16.8 秒(0.2%) | 7.1 秒(-0.8%) | 6.9 秒(16.0%) | 5.3 秒(20.6%) |
| 使用内存高效注意力机制和编译优化 | - | 16.4 秒(2.1%) | 7.2 秒(-2.3%) | 6.6 秒(18.6%) | 4.1 秒(38.5%) |
批量大小为 2 的运行时
| 配置 | P100 | T4 | A10 | V100 | A100 |
| 原始(不含 xFormers) | 58.0 秒(-21.6%) | 57.6 秒(-84.0%) | 24.4 秒(-95.2%) | 18.6 秒(-63.0%) | 12.0 秒(-50.6%) |
| 原文带 xFormers | 47.7 秒(0.0%) | 31.3 秒(0.0%) | 12.5 秒(0.0%) | 11.4 秒(0.0%) | 8.0 秒(0.0%) |
| 使用纯数学注意力优化,无需编译 | 49.3 秒(-3.5%) | 37.9 秒(-21.0%) | 17.8 秒(-42.2%) | 12.7 秒(-10.7%) | 7.8 秒(1.8%) |
| 使用内存高效注意力优化,无需编译 | 47.5 秒(0.4%) | 31.2 秒(0.5%) | 12.2 秒(2.6%) | 11.5 秒(-0.7%) | 7.0 秒(12.6%) |
| 使用内存高效注意力机制和编译优化 | - | 28.0 秒(10.5%) | 11.4 秒(9.0%) | 10.7 秒(6.4%) | 6.4 秒(20.3%) |
批处理大小为 4 的运行时间
| 配置 | P100 | T4 | A10 | V100 | A100 |
| 原始(不含 xFormers) | 117.9 秒(-20.0%) | 112.4 秒(-81.8%) | 47.2 秒(-101.7%) | 35.8 秒(-71.9%) | 22.8 秒(-78.9%) |
| 原始带 xFormers | 98.3 秒(0.0%) | 61.8 秒(0.0%) | 23.4 秒(0.0%) | 20.8 秒(0.0%) | 12.7 秒(0.0%) |
| 使用纯数学注意力优化,无需编译 | 101.1 秒(-2.9%) | 73.0 秒(-18.0%) | 28.3 秒(-21.0%) | 23.3 秒(-11.9%) | 14.5 秒(-13.9%) |
| 使用内存高效注意力优化,无需编译 | 92.9 秒(5.5%) | 61.1 秒(1.2%) | 23.9 秒(-1.9%) | 20.8 秒(-0.1%) | 12.8 秒(-0.9%) |
| 使用内存高效注意力机制和编译优化 | - | 53.1 秒(14.2%) | 20.9 秒(10.6%) | 18.6 秒(10.4%) | 11.2 秒(12.2%) |
为了最小化对基准代码性能的波动和外部影响,我们依次运行代码的每个版本,然后重复此序列 10 次:A,B,C,D,E,A,B,……因此,典型运行的输出结果将类似于下面的图片。请注意,不应依赖于不同图表之间绝对运行时间的比较,但得益于我们的基准测试设置,图表内部运行时间的比较相当可靠。
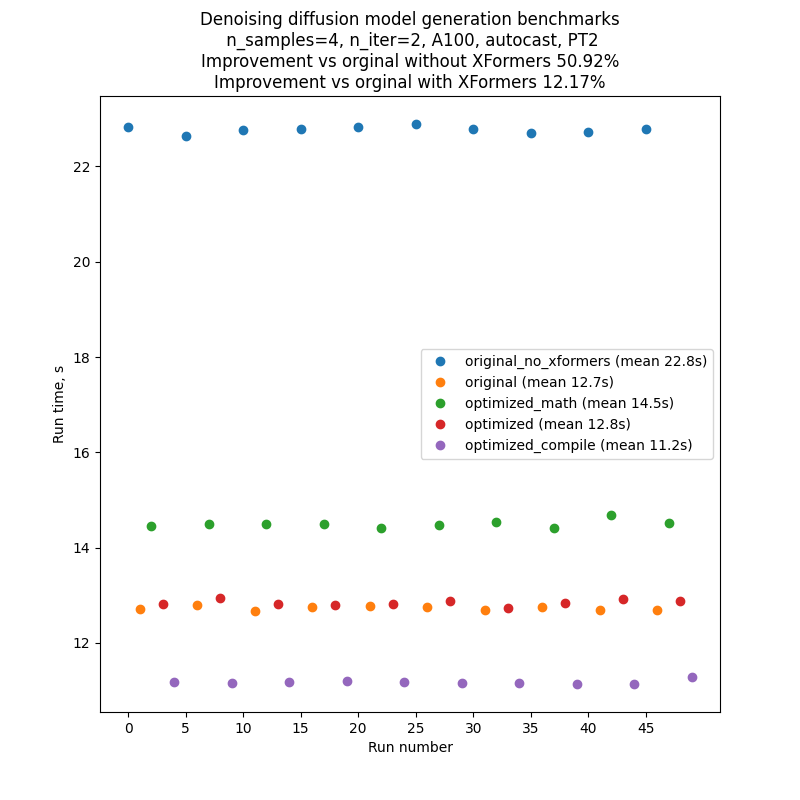
文本到图像生成脚本的每次运行都会产生几个批次,批次的数量由 CLI 参数 --n_iter 调节。在基准测试中我们使用了 n_iter = 2 ,但引入了一个额外的“预热”迭代,这个迭代不会对运行时间产生影响。这对于需要编译的运行是必要的,因为编译发生在代码第一次运行时,因此第一次迭代的运行时间要长于所有后续迭代。为了使比较公平,我们也为所有其他运行引入了这一额外的“预热”迭代。
上表中的数字表示迭代次数 2(加上一个“预热”迭代),提示词为“照片”,种子值为 1,使用 PLMS 采样器,并且启用了自动调整。
基准测试使用了 P100、V100、A100、A10 和 T4 GPU。T4 的基准测试在 Google Colab Pro 上进行。A10 的基准测试在 g5.4xlarge AWS 实例上,每个实例配备 1 个 GPU。
结论和下一步计划
我们已经证明,PyTorch 2 的新特性——编译器和优化的注意力实现——带来了超越或与之前需要安装外部依赖(xFormers)相当的性能提升。PyTorch 通过将其代码库中集成内存高效的注意力机制从 xFormers 中实现这一点。考虑到 xFormers 作为一个最先进的库,在许多情况下需要自定义安装过程和漫长的构建过程,这是一个对用户体验的重大改进。
这项工作可以继续发展的几个自然方向:
- 我们在这里实现并描述的优化目前仅针对文本到图像推理进行了基准测试。很有趣的是,看看它们如何影响训练性能。PyTorch 编译可以直接应用于训练;启用使用 PyTorch 优化的注意力进行训练已在路线图上
- 我们有意最小化了原始模型代码的更改。进一步的剖析和优化可能带来更多改进
- 目前编译仅应用于采样器内的 U-Net 模型。由于 U-Net 之外还有很多事情发生(例如,采样循环中的直接操作),编译整个采样器将是有益的。然而,这需要分析编译过程以避免在每次采样步骤重新编译
- 当前代码仅适用于 PLMS 采样器内的编译,但将其扩展到其他采样器应该是微不足道的
- 除了文本到图像生成,扩散模型还被应用于其他任务——图像到图像和修复。测量它们从 PyTorch 2 优化中性能提升将很有趣
尝试使用我们描述的方法提高开源扩散模型的表现力,并分享结果!
资源
- PyTorch 2.0 概述,其中包含大量关于
torch.compile:https://maskerprc.github.io/get-started/pytorch-2.0/的信息 - PyTorch 编译教程:https://maskerprc.github.io/tutorials/intermediate/torch_compile_tutorial.html
- 通用编译故障排除:https://maskerprc.github.io/docs/stable/torch.compiler_troubleshooting.html
- 图断裂详情:https://maskerprc.github.io/docs/stable/torch.compiler_faq.html#identifying-the-cause-of-a-graph-break
- 守卫详情:https://maskerprc.github.io/docs/stable/torch.compiler_guards_overview.html
- 火炬 Dynamo 深度视频解析 https://www.youtube.com/watch?v=egZB5Uxki0I
- PyTorch 1.12 中优化注意力教程:https://maskerprc.github.io/tutorials/beginner/bettertransformer_tutorial.html
致谢
我们想感谢 Geeta Chauhan、Natalia Gimelshein、Patrick Labatut、Bert Maher、Mark Saroufim、Michael Voznesensky 和 Francisco Massa 对文本提供的宝贵建议和早期反馈。
特别感谢 Yudong Tao 在扩散模型中使用 PyTorch 原生注意力机制的工作启动。