约会 ¶
在 Torch 分布式弹性(Torch Distributed Elastic)的语境中,我们使用“约会”一词来指代一种特定的功能,该功能结合了分布式同步原语与对等发现。
它被 Torch 分布式弹性用于收集训练作业的参与者(即节点),以确保所有节点都同意相同的参与者列表和每个人的角色,并就何时开始/恢复训练做出一致的集体决策。
火炬分布式弹性会合提供了以下关键功能:
障碍:
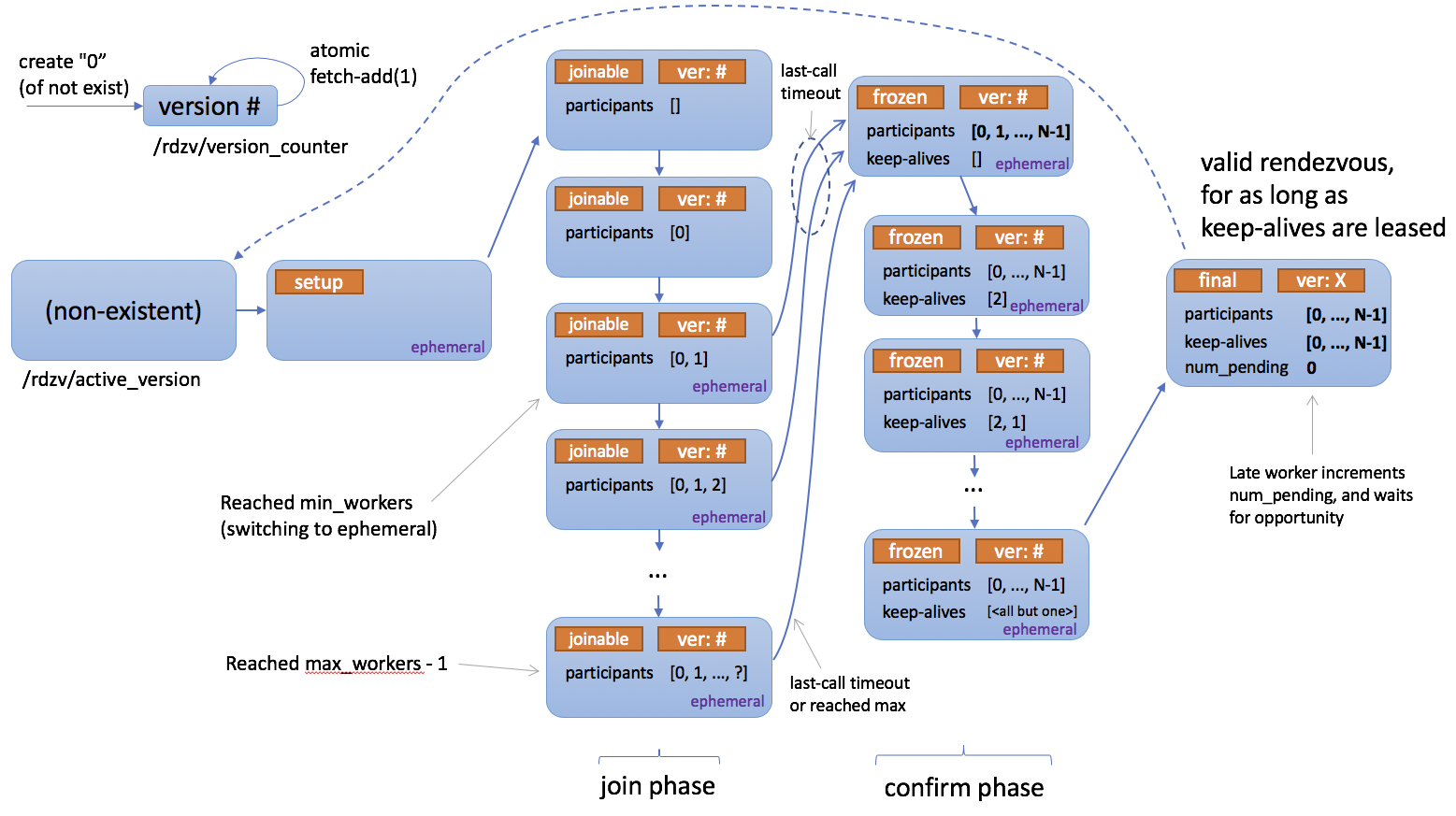
执行会合的节点将全部阻塞,直到会合被认为完成——这发生在至少有 min 个节点加入会合障碍(对于同一作业)时。这也意味着障碍的大小不一定固定。
达到 min 个节点数量后,还有一个额外的短暂等待时间——这是为了确保会合不会“太快”完成(这可能会排除大约同时尝试加入的额外节点)。
如果在屏障处聚集了 max 个节点,则 rendezvous 将立即完成。
同时还有一个整体超时时间,如果在任何时候没有达到 min 个节点,则 rendezvous 将失败 - 这是为了作为一个简单的故障安全机制,以帮助释放部分分配的工作资源,以防资源管理器出现问题,并且不应被视为可重试的。
独占性:
一个简单的分布式屏障是不够的,因为我们还需要确保在任何给定时间(对于给定的工作)只有一个节点组存在。换句话说,新节点(即晚些时候加入)不应能够为同一工作形成并行独立的工人组。
火炬分布式弹性会合确保如果一组节点已经完成了会合(因此可能已经开始训练),那么尝试会合的“迟到”节点只会宣布自己处于等待状态,并且必须等待先前的(已完成的)现有会合被销毁后才能进行。
一致性:
当会合完成后,所有成员将就作业成员资格以及每个人在其中的角色达成一致。这个角色使用一个介于 0 和全局大小之间的整数表示,称为 rank。
注意,rank 不是稳定的,也就是说,同一个节点在下一个(重新)会合中可能会被分配不同的 rank。
容错性:
Torch 分布式弹性 rendezvous 旨在在 rendezvous 过程中容忍节点故障。如果在加入 rendezvous 和完成 rendezvous 之间进程崩溃(或失去网络连接等),则会自动与剩余的健康节点重新 rendezvous。
节点也可能在完成 rendezvous(或被其他节点观察到已完成)之后失败,这种场景将由 Torch 分布式弹性 train_loop 处理(它也会触发重新 rendezvous)。
共享键值存储:
当会合完成时,将创建并返回一个共享的键值存储。此存储实现了 torch.distributed.Store API(参见分布式通信文档)。
此存储仅由完成会合的成员共享。它旨在由 Torch 分布式弹性使用,以交换初始化作业控制和数据平面所需的信息。
等待中的工作者和会合关闭:
Torch 分布式弹性会合处理器对象提供了额外的功能,这些功能在技术上不属于会合过程:
查询有多少工人迟到在关卡,谁可以参加下一次会合。
将会合设置为关闭,以向所有节点发出信号,不要参加下一次会合。
DynamicRendezvousHandler:
Torch 分布式弹性版附带一个 DynamicRendezvousHandler 类,该类实现了上述描述的会合机制。它是一个与后端无关的类型,在构造时需要指定一个特定的 RendezvousBackend 实例。
PyTorch 分布式用户可以选择实现自己的后端类型,或者使用 PyTorch 附带的一些实现之一:
C10dRendezvousBackend: 使用 C10d 存储(默认为TCPStore)作为 rendezvous 后端。使用 C10d 存储的主要优势是它不需要第三方依赖(如 etcd)来建立 rendezvous。EtcdRendezvousBackend: 取代了旧版EtcdRendezvousHandler类。将EtcdRendezvousBackend实例传递给DynamicRendezvousHandler在功能上等同于实例化EtcdRendezvousHandler。store = TCPStore("localhost") backend = C10dRendezvousBackend(store, "my_run_id") rdzv_handler = DynamicRendezvousHandler.from_backend( run_id="my_run_id", store=store, backend=backend, min_nodes=2, max_nodes=4 )
下面是一个描述 rendezvous 工作原理的状态图。
注册表
- class torch.distributed.elastic.rendezvous.RendezvousParameters(backend, endpoint, run_id, min_nodes, max_nodes, local_addr=None, **kwargs)[source][source]¶
保持构建
RendezvousHandler的参数。- 参数:
backend (str) – 使用以处理 rendezvous 的后端名称。
约会端点(字符串)- 约会的端点,通常形式为 <主机名>[:<端口>]。
run_id(字符串)- 约会的 ID。
min_nodes(整数)- 允许加入约会的最小节点数。
max_nodes(整数)- 允许加入约会的最大节点数。
本地地址(可选[str])- 本地节点的地址。
**kwargs - 为指定后端提供的额外参数。
处理器
- class torch.distributed.elastic.rendezvous.RendezvousHandler[source][source]¶
主 rendezvous 接口。
注意
分布式 Torch 用户通常不需要实现自己的
RendezvousHandler。基于 C10d Store 的实现已经提供,并推荐给大多数用户。- 抽象 get_backend()[source][source] ¶
返回 rendezvous 后端的名称。
- 返回类型:
- 获取运行 ID()[来源][来源]
返回 rendezvous 的运行 ID。
运行 ID 是一个用户定义的 ID,用于唯一标识分布式应用程序的一个实例。它通常映射到作业 ID,并用于允许节点加入正确的分布式应用程序。
- 返回类型:
- 抽象 is_closed()[source][source] ¶
检查会合是否已关闭。
关闭的会合意味着在同一个作业中所有未来的重新会合尝试都将失败。
is_closed()和set_closed()具有最终传播的语义,不应用于同步。意图是如果至少有一个节点决定作业已完成,它将关闭会合,其他节点也将很快观察到这一点并停止运行。- 返回类型:
- 下一个 rendezvous() 的抽象 [来源][来源] ¶
进入 rendezvous 障碍的主入口。
阻塞,直到 rendezvous 完成,当前进程被包含在形成的工人组中,或者发生超时,或者 rendezvous 被标记为关闭。
- 返回值:
RendezvousInfo的实例。- 引发:
预约已关闭错误 - 预约已关闭。
预约连接错误 - 连接到 rendezvous 后端失败。
预约状态错误 - 预约状态已损坏。
预约超时错误 - 预约未按时完成。
- 返回类型:
- abstract num_nodes_waiting()[source][source]¶
返回到达集合屏障晚的节点数量,因此这些节点未被包含在当前工作组中。
调用者应定期调用此方法以检查是否有新节点等待加入工作,如果有,则通过调用
next_rendezvous()(重新集合)来接纳它们。- 返回类型:
- 抽象 set_closed()[source][source] ¶
标记会合为已关闭。
- 抽象 shutdown()[source][source] ¶
关闭会合期间所有已打开的资源。
示例:
rdzv_handler = ... try: store, rank, world_size = rdzv_handler.next_rendezvous() finally: rdzv_handler.shutdown()
- 返回类型:
- 属性使用代理存储布尔值
表示由
next_rendezvous()返回的存储引用可以被用户应用程序共享,并在应用程序生命周期内可用。集合处理器实现将作为
RendezvousStoreInfo的实例共享存储详细信息。应用程序按照惯例使用 MASTER_ADDR/MASTER_PORT 环境变量来查找存储。
数据类
- class torch.distributed.elastic.rendezvous.RendezvousInfo(存储, 排名, 世界大小, 引导存储信息)[source][source] ¶
存储关于 rendezvous 的信息。
- class torch.distributed.elastic.rendezvous.api.RendezvousStoreInfo(主地址, 主端口)[source][source] ¶
可用于引导训练器分布式通信的存储地址和端口。
- 静态构建(rank, store)[源代码][源代码] ¶
工厂方法,在 rank0 主机上查找未使用的端口,并获取所有 rank 的地址/端口信息。
如果已知 master_addr/master_port(当共享现有的 tcp store 服务器时很有用)使用构造函数。
- 参数:
rank(int)- 当前节点的 rank
存储点(存储点)- 用于会合的存储点
local_addr(可选[str])- 当前节点的地址,如未提供,将根据主机名解析
server_port(可选[int])- TCPStore 服务器的端口号,当 TCPStore 共享时
- 返回类型:
异常
- class torch.distributed.elastic.rendezvous.api.RendezvousError[source][source]
代表 rendezvous 错误的基类型。
- class torch.distributed.elastic.rendezvous.api.RendezvousClosedError[source][source]
当 rendezvous 关闭时引发。
- class torch.distributed.elastic.rendezvous.api.RendezvousTimeoutError[source][source]¶
当 rendezvous 未按时完成时引发。
- class torch.distributed.elastic.rendezvous.api.RendezvousConnectionError[source][source]¶
连接到 rendezvous 后端失败时引发。
- 类 torch.distributed.elastic.rendezvous.api.RendezvousStateError[source][source]
当 rendezvous 状态损坏时引发。
- 类 torch.distributed.elastic.rendezvous.api.RendezvousGracefulExitError[source][source]
节点未包含在 rendezvous 中时触发,并优雅地退出。
异常是一种退出堆栈的机制,但这并不意味着失败。
实现 §
动态 rendezvous §
- torch.distributed.elastic.rendezvous.dynamic_rendezvous.create_handler(store, backend, params)[source][source]¶
根据指定参数创建一个新的
DynamicRendezvousHandler。- 参数:
store (Store) – 返回作为 rendezvous 的一部分的 C10d 存储。
backend (RendezvousBackend) – 用于保持 rendezvous 状态的后端。
- 返回类型:
参数
描述
join_timeout
预期 rendezvous 完成的总时间,单位为秒。默认为 600 秒。
最后调用超时
达到最小节点数后,在完成会合前额外等待的时间(以秒为单位)。默认为 30 秒。
关闭超时
在调用
RendezvousHandler.set_closed()或RendezvousHandler.shutdown()之后,预期在多少秒内关闭会合(以秒为单位)。默认为 30 秒。心跳
在秒内,期望完成心跳保活的超时时间
- class torch.distributed.elastic.rendezvous.dynamic_rendezvous.DynamicRendezvousHandler[source][source]¶
表示一个在节点集合中设置 rendezvous 的处理器。
- from_backend(run_id, store, backend, min_nodes, max_nodes, local_addr=None, timeout=None, keep_alive_interval=5, keep_alive_max_attempt=3)[source][source] ¶
创建一个新的
DynamicRendezvousHandler。- 参数:
run_id (str) – 集合点的运行 ID。
store (Store) – 返回作为 rendezvous 的一部分的 C10d 存储。
backend (RendezvousBackend) – 用于保持 rendezvous 状态的后端。
min_nodes (int) – 允许加入 rendezvous 的最小节点数。
max_nodes (int) – 允许加入 rendezvous 的最大节点数。
local_addr (Optional[str]) – 本地节点地址。
timeout (Optional[RendezvousTimeout]) – rendezvous 的超时配置。
keep_alive_interval (int) – 节点在 rendezvous 中发送心跳以保持活跃之前等待的时间(整数)。
keep_alive_max_attempt (int) – 节点在被视为死亡之前,心跳尝试失败的最大次数(整数)。
- class torch.distributed.elastic.rendezvous.dynamic_rendezvous.RendezvousBackend[source][source]¶
表示一个持有 rendezvous 状态的后端。
- 抽象获取状态()[源][源] ¶
获取 rendezvous 状态。
- 返回值:
编码的 rendezvous 状态及其围栏令牌的元组或
None,如果后端未找到状态。- 引发:
RendezvousConnectionError – 与后端连接失败。
遇见状态错误 - 遇见状态已损坏。
- 返回类型:
可选的[字节,任何类型]元组
- 抽象属性名称 str ¶
获取后端名称。
- abstract set_state(state, token=None)[source][source]¶
设置会合状态。
新的会合状态设置条件如下:
如果指定的
token与后端存储的隔离令牌匹配,则状态将被更新。新的状态及其隔离令牌将返回给调用者。如果指定的
token与后端存储的围栏令牌不匹配,则状态不会更新;相反,将返回现有的状态及其围栏令牌给调用者。如果指定的
token是None,则只有在后端没有现有状态的情况下才会设置新状态。将返回新状态或现有状态及其围栏令牌给调用者。
- 参数:
状态(字节)- 编码的会合状态。
令牌(可选[任意])- 由之前的
get_state()或set_state()调用检索的可选围栏令牌。
- 返回值:
序列化的 rendezvous 状态、其 fencing 令牌以及一个布尔值,表示我们的设置尝试是否成功。
- 引发:
RendezvousConnectionError – 与后端连接失败。
RendezvousStateError – rendezvous 状态已损坏。
- 返回类型:
Optional[tuple[bytes, Any, bool]]
- class torch.distributed.elastic.rendezvous.dynamic_rendezvous.RendezvousTimeout(join=None, last_call=None, close=None, heartbeat=None)[source][source]¶
保持 rendezvous 的超时配置。
- 参数:
join(可选[timedelta])- 预期 rendezvous 完成的时限。
last_call(可选[timedelta])- 在 rendezvous 达到所需的最少参与者数量后,完成 rendezvous 之前额外的等待时间。
close(可选[timedelta])- 在调用
RendezvousHandler.set_closed()或RendezvousHandler.shutdown()后,预计 rendezvous 将在多长时间内关闭。heartbeat(可选[timedelta])- 预计保持连接的心跳将在多长时间内完成。
- 属性:心跳时间差 ¶
获取保持连接的心跳超时时间。
- 属性:连接时间差 ¶
获取连接超时时间。
- 最后调用时间差属性 ¶
获取最后调用超时。
C10d 后端 ¶
- torch.distributed.elastic.rendezvous.c10d_rendezvous_backend.create_backend(params)[source][source]¶
从指定参数创建一个新的
C10dRendezvousBackend。参数
描述
store_type
C10d 存储的类型。当前支持的类型是“tcp”和“file”,分别对应
torch.distributed.TCPStore和torch.distributed.FileStore,默认为“tcp”。读取超时
读取超时,以秒为单位,用于存储操作。默认为 60 秒。
注意,此设置仅适用于
torch.distributed.TCPStore。对于torch.distributed.FileStore,它不接受超时作为参数,因此不相关。is_host
一个布尔值,表示此后端实例是否将托管 C10d 存储。如果未指定,将通过匹配此机器的计算机名或 IP 地址与指定的 rendezvous 端点来启发式地推断。默认为
None。注意,此配置选项仅适用于
torch.distributed.TCPStore。在正常情况下,您可以安全地跳过它;唯一需要的时候是如果其值无法正确确定(例如,rendezvous 端点的主机名为 CNAME 或与机器的 FQDN 不匹配)。- 返回类型:
tuple[torch.distributed.elastic.rendezvous.c10d_rendezvous_backend.C10dRendezvousBackend, torch.distributed.distributed_c10d.Store]
- class torch.distributed.elastic.rendezvous.c10d_rendezvous_backend.C10dRendezvousBackend(store, run_id)[source][source]¶
代表基于 C10d 的会合后端。
- 参数:
存储(Store)- 使用该
torch.distributed.Store实例与 C10d 存储进行通信。run_id (str) – 集合点的运行 ID。
- 属性名称 str ¶
请参阅基类。
- set_state(state, token=None)[来源][来源] ¶
查看基类。
- 返回类型:
Optional[tuple[bytes, Any, bool]]
Etcd 后端 ¶
- torch.distributed.elastic.rendezvous.etcd_rendezvous_backend.create_backend(params)[source][source]¶
从指定参数创建一个新的
EtcdRendezvousBackend参数
描述
read_timeout
etcd 操作的读取超时时间,以秒为单位。默认为 60 秒。
协议
用于与 etcd 通信的协议。有效值是“http”和“https”。默认为“http”。
ssl_cert
使用 HTTPS 时,与 SSL 客户端证书一起使用的路径。默认为
None。ssl 证书密钥
使用 HTTPS 时,与 SSL 客户端证书一起使用的私钥路径。默认为
None。ca 证书
根 SSL 授权证书的路径。默认为
None。- 返回类型:
tuple[torch.distributed.elastic.rendezvous.etcd_rendezvous_backend.EtcdRendezvousBackend, torch.distributed.distributed_c10d.Store]
- class torch.distributed.elastic.rendezvous.etcd_rendezvous_backend.EtcdRendezvousBackend(client, run_id, key_prefix=None, ttl=None)[source][source]¶
表示一个基于 etcd 的 rendezvous 后端。
- 参数:
client (Client) – 使用
etcd.Client实例与 etcd 进行通信。run_id (str) – 集合点的运行 ID。
key_prefix(可选[str])- 在 etcd 中存储 rendezvous 状态的路径。
ttl(可选[int])- rendezvous 状态的 TTL。如果未指定,默认为两小时。
- get_state()[source][source]
参见基类。
- 返回类型:
可选[字节,任何类型]
- 属性名称 str ¶
请参阅基类。
- set_state(state, token=None)[来源][来源] ¶
查看基类。
- 返回类型:
可选的[字节,任何,布尔值]元组
Etcd rendezvous(旧版)¶
警告
DynamicRendezvousHandler 类取代了 EtcdRendezvousHandler 类,并推荐给大多数用户。 EtcdRendezvousHandler 处于维护模式,未来将被弃用。
- class torch.distributed.elastic.rendezvous.etcd_rendezvous.EtcdRendezvousHandler(rdzv_impl, local_addr)[source][source]¶
实现了一个由
torch.distributed.elastic.rendezvous.etcd_rendezvous.EtcdRendezvous支持的torch.distributed.elastic.rendezvous.RendezvousHandler接口。EtcdRendezvousHandler使用 URL 来配置要使用的 rendezvous 类型,并将特定实现的配置传递给 rendezvous 模块。基本的 etcd rendezvous 配置 URL 看起来如下etcd://<etcd_address>:<port>/<job_id>?min_workers=<min_workers>&max_workers=<max_workers> # noqa: W605 -- example -- etcd://localhost:2379/1234?min_workers=1&max_workers=3
上面的 URL 解释如下:
使用已注册于
etcd方案的 rendezvous 处理器要使用的端点是
etcd和localhost:2379job_id == 1234用作 etcd 的前缀(这允许用户在保证job_ids唯一的前提下,为多个作业共享一个公共的 etcd 服务器)。请注意,作业 ID 可以是任何字符串(例如,不需要是数字),只要它是唯一的即可。min_workers=1和max_workers=3指定成员数量的范围 - 当集群大小大于或等于min_workers时,Torch 分布式弹性开始运行作业,并最多接受max_workers个成员加入集群。
以下是可以向 etcd 集合点传递的所有参数的完整列表:
参数
描述
min_workers
集合点有效所需的最小工作者数量
max_workers
允许的最大工作进程数
超时时间
期望 next_rendezvous 成功的总超时时间(默认 600 秒)
最后一次调用超时时间
达到最小工人数后额外的等待时间(“最后呼叫”)(默认为 30 秒)
etcd 前缀
路径前缀(从 etcd 根开始),在此路径下将创建所有 etcd 节点(默认为
/torchelastic/p2p)
Etcd 存储区
EtcdStore 是当使用 etcd 作为 rendezvous 后端时, next_rendezvous() 返回的 C10d Store 实例类型。
- class torch.distributed.elastic.rendezvous.etcd_store.EtcdStore(etcd_client, etcd_store_prefix, timeout=None)[source][source]¶
通过 piggybacking 在 rendezvous etcd 实例上实现 c10 Store 接口。
这是
EtcdRendezvous返回的存储对象。- add(key, num)[source][source]¶
原子性地通过一个整数值增加一个值。
整数以 10 进制字符串形式表示。如果 key 不存在,则默认值为
0。- 返回值:
新的(增加后的)值
- 返回类型:
- 检查键是否立即存在(无需等待)
检查所有键是否立即存在(无需等待)
- 返回类型:
- 通过键获取值,可能需要进行阻塞等待
通过键获取值,可能需要进行阻塞等待
如果键不在立即存在,将进行最多
timeout持续时间的阻塞等待,或者直到键被发布。- 返回值:
值
(bytes)- 引发:
LookupError - 如果键在超时后仍未发布 –
- 返回类型:
- wait(keys, override_timeout=None)[源代码][源代码] ¶
等待所有键发布,或直到超时。
- 引发:
LookupError - 如果发生超时 -
Etcd 服务器 ¶
EtcdServer 是一个便利类,它使您能够轻松地在子进程中启动和停止 etcd 服务器。这在测试或单节点(多工作员)部署中很有用,在这些部署中,手动设置侧边的 etcd 服务器很麻烦。
警告
对于生产环境和多节点部署,请考虑正确部署高可用性 etcd 服务器,因为这是您分布式作业的单点故障。
- class torch.distributed.elastic.rendezvous.etcd_server.EtcdServer(data_dir=None)[source][source]¶
注意
在 etcd 服务器 v3.4.3 上进行了测试。
在随机空闲端口上启动和停止本地独立 etcd 服务器。对于单节点、多工作进程启动或测试,使用边车 etcd 服务器比单独设置 etcd 服务器更方便。
此类注册了终止处理程序以在退出时关闭 etcd 子进程。此终止处理程序**不是**调用
stop()方法的替代品。以下回退机制用于查找 etcd 二进制文件:
使用环境变量 TORCHELASTIC_ETCD_BINARY_PATH
如果存在,则使用
<this file root>/bin/etcd使用
PATH中的etcd
使用说明
server = EtcdServer("/usr/bin/etcd", 2379, "/tmp/default.etcd") server.start() client = server.get_client() # use client server.stop()
- 参数:
etcd 服务器二进制路径 – etcd 服务器二进制文件路径(见上文以获取备用路径)